Adam优化器
2014年12月, Kingma和Lei Ba两位学者提出了Adam优化器,结合AdaGrad和RMSProp两种优化算法的优点。对梯度的一阶矩估计(First Moment Estimation,即梯度的均值)和二阶矩估计(Second Moment Estimation,即梯度的未中心化的方差)进行综合考虑,计算出更新步长。
主要包含以下几个显著的优点:
- 实现简单,计算高效,对内存需求少
- 参数的更新不受梯度的伸缩变换影响
- 超参数具有很好的解释性,且通常无需调整或仅需很少的微调
- 更新的步长能够被限制在大致的范围内(初始学习率)
- 能自然地实现步长退火过程(自动调整学习率)
- 很适合应用于大规模的数据及参数的场景
- 适用于不稳定目标函数
- 适用于梯度稀疏或梯度存在很大噪声的问题
综合Adam在很多情况下算作默认工作性能比较优秀的优化器。
Adam更新规则
计算t时间步的梯度:
![]()
首先,计算梯度的指数移动平均数,m0 初始化为0。
类似于Momentum算法,综合考虑之前时间步的梯度动量。
β1 系数为指数衰减率,控制权重分配(动量与当前梯度),通常取接近于1的值。
默认为0.9
![]()
下图简单展示出时间步1~20时,各个时间步的梯度随着时间的累积占比情况。
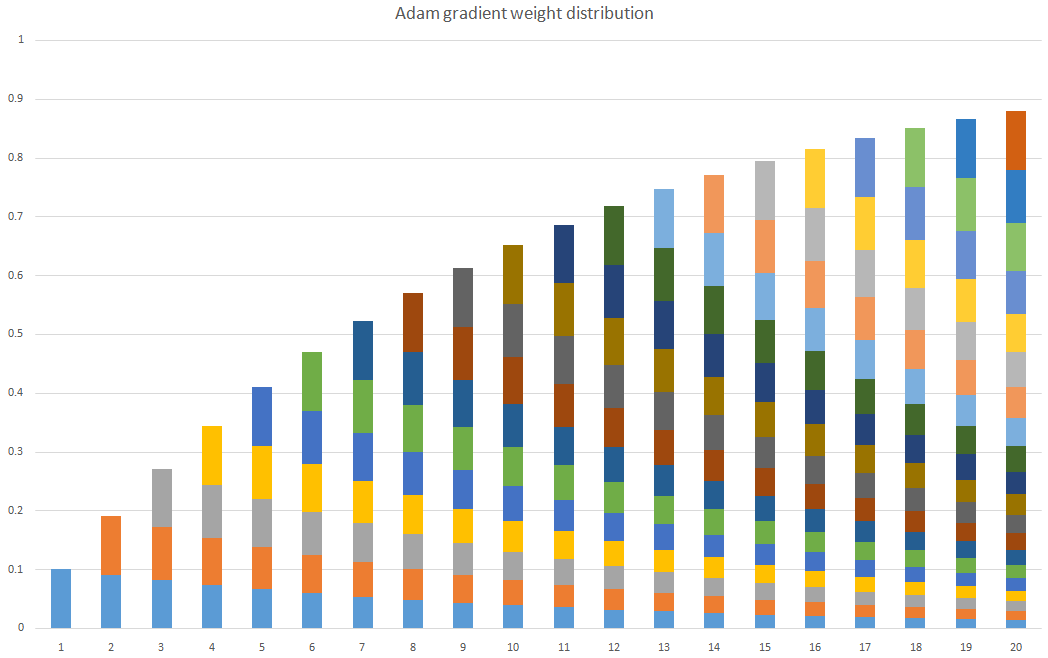
其次,计算梯度平方的指数移动平均数,v0初始化为0。
β2 系数为指数衰减率,控制之前的梯度平方的影响情况。
类似于RMSProp算法,对梯度平方进行加权均值。
默认为0.999
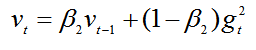
第三,由于m0初始化为0,会导致mt偏向于0,尤其在训练初期阶段。
所以,此处需要对梯度均值mt进行偏差纠正,降低偏差对训练初期的影响。
![]()
第四,与m0 类似,因为v0初始化为0导致训练初始阶段vt 偏向0,对其进行纠正。
![]()
第五,更新参数,初始的学习率α乘以梯度均值 与梯度方差 的平方根之比。
其中默认学习率α=0.001
ε=10^-8,避免除数变为0。
由表达式可以看出,对更新的步长计算,能够从梯度均值及梯度平方两个角度进行自适应地调节,而不是直接由当前梯度决定。
![]()
Adam代码实现
算法思路很清晰,实现比较直观:
class Adam:
def __init__(self, loss, weights, lr=0.001, beta1=0.9, beta2=0.999, epislon=1e-8):
self.loss = loss
self.theta = weights
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.epislon = epislon
self.get_gradient = grad(loss)
self.m = 0
self.v = 0
self.t = 0
def minimize_raw(self):
self.t += 1
g = self.get_gradient(self.theta)
self.m = self.beta1 * self.m + (1 - self.beta1) * g
self.v = self.beta2 * self.v + (1 - self.beta2) * (g * g)
self.m_hat = self.m / (1 - self.beta1 ** self.t)
self.v_hat = self.v / (1 - self.beta2 ** self.t)
self.theta -= self.lr * self.m_hat / (self.v_hat ** 0.5 + self.epislon)
def minimize(self):
self.t += 1
g = self.get_gradient(self.theta)
lr = self.lr * (1 - self.beta2 ** self.t) ** 0.5 / (1 - self.beta1 ** self.t)
self.m = self.beta1 * self.m + (1 - self.beta1) * g
self.v = self.beta2 * self.v + (1 - self.beta2) * (g * g)
self.theta -= lr * self.m / (self.v ** 0.5 + self.epislon)Adam 是一种可以替代传统随机梯度下降过程的一阶优化算法,它能基于训练数据迭代地更新神经网络权重。Adam 最开始是由 OpenAI 的 Diederik Kingma 和多伦多大学的 Jimmy Ba 在提交到 2015 年 ICLR 论文(Adam: A Method for Stochastic Optimization)中提出的.该算法名为「Adam」,其并不是首字母缩写,也不是人名。它的名称来源于适应性矩估计(adaptive moment estimation)
Adam(Adaptive Moment Estimation)本质上是带有动量项的RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。它的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。其公式如下:
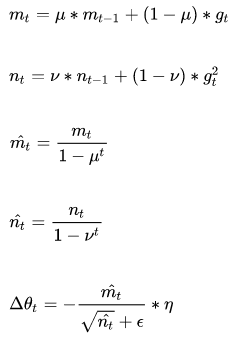
解释:
第一项梯度就是损失函数对求偏导。
第二项为t时刻,梯度在动量形式下的一阶矩估计。
第三项为梯度在动量形式下的二阶矩估计。
第四项为偏差纠正后的一阶矩估计。其中:是贝塔1的t次方,下面同理。
第五项为偏差纠正后的二阶矩估计。
最后一项是更新公式,可以参考RMSProp以及之前的算法。
其中,前两个公式分别是对梯度的一阶矩估计和二阶矩估计,可以看作是对期望E|gt|,E|gt^2|的估计;
公式3,4是对一阶二阶矩估计的校正,这样可以近似为对期望的无偏估计。可以看出,直接对梯度的矩估计对内存没有额外的要求,而且可以根据梯度进行动态调整。最后一项前面部分是对学习率n形成的一个动态约束,而且有明确的范围。
优点:
1、结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点;
2、对内存需求较小;
3、为不同的参数计算不同的自适应学习率;
4、也适用于大多非凸优化-适用于大数据集和高维空间。
Adam算法 (Kingma and Ba, 2014)将所有这些技术汇总到一个高效的学习算法中。 不出预料,作为深度学习中使用的更强大和有效的优化算法之一,它非常受欢迎。 但是它并非没有问题,尤其是 (Reddi et al., 2019)表明,有时Adam算法可能由于方差控制不良而发散。 在完善工作中, (Zaheer et al., 2018)给Adam算法提供了一个称为Yogi的热补丁来解决这些问题。 下面我们了解一下Adam算法。
11.10.1. 算法
Adam算法的关键组成部分之一是:它使用指数加权移动平均值来估算梯度的动量和二次矩,即它使用状态变量
(11.10.1)vt←β1vt−1+(1−β1)gt,st←β2st−1+(1−β2)gt2.
这里β1和β2是非负加权参数。 常将它们设置为β1=0.9和β2=0.999。 也就是说,方差估计的移动远远慢于动量估计的移动。 注意,如果我们初始化v0=s0=0,就会获得一个相当大的初始偏差。 我们可以通过使用∑i=0tβi=1−βt1−β来解决这个问题。 相应地,标准化状态变量由下式获得
(11.10.2)v^t=vt1−β1t and s^t=st1−β2t.
有了正确的估计,我们现在可以写出更新方程。 首先,我们以非常类似于RMSProp算法的方式重新缩放梯度以获得
(11.10.3)gt′=ηv^ts^t+ϵ.
与RMSProp不同,我们的更新使用动量v^t而不是梯度本身。 此外,由于使用1s^t+ϵ而不是1s^t+ϵ进行缩放,两者会略有差异。 前者在实践中效果略好一些,因此与RMSProp算法有所区分。 通常,我们选择ϵ=10−6,这是为了在数值稳定性和逼真度之间取得良好的平衡。
最后,我们简单更新:
(11.10.4)xt←xt−1−gt′.
回顾Adam算法,它的设计灵感很清楚: 首先,动量和规模在状态变量中清晰可见, 它们相当独特的定义使我们移除偏项(这可以通过稍微不同的初始化和更新条件来修正)。 其次,RMSProp算法中两项的组合都非常简单。 最后,明确的学习率η使我们能够控制步长来解决收敛问题。
11.10.2. 实现
从头开始实现Adam算法并不难。 为方便起见,我们将时间步t存储在hyperparams字典中。 除此之外,一切都很简单。
mxnetpytorchtensorflowpaddle
%matplotlib inline
from mxnet import np, npx
from d2l import mxnet as d2l
npx.set_np()
def init_adam_states(feature_dim):
v_w, v_b = np.zeros((feature_dim, 1)), np.zeros(1)
s_w, s_b = np.zeros((feature_dim, 1)), np.zeros(1)
return ((v_w, s_w), (v_b, s_b))
def adam(params, states, hyperparams):
beta1, beta2, eps = 0.9, 0.999, 1e-6
for p, (v, s) in zip(params, states):
v[:] = beta1 * v + (1 - beta1) * p.grad
s[:] = beta2 * s + (1 - beta2) * np.square(p.grad)
v_bias_corr = v / (1 - beta1 ** hyperparams['t'])
s_bias_corr = s / (1 - beta2 ** hyperparams['t'])
p[:] -= hyperparams['lr'] * v_bias_corr / (np.sqrt(s_bias_corr) + eps)
hyperparams['t'] += 1
现在,我们用以上Adam算法来训练模型,这里我们使用η=0.01的学习率。
mxnetpytorchtensorflowpaddle
data_iter, feature_dim = d2l.get_data_ch11(batch_size=10)
d2l.train_ch11(adam, init_adam_states(feature_dim),
{'lr': 0.01, 't': 1}, data_iter, feature_dim);
loss: 0.244, 0.105 sec/epoch
此外,我们可以用深度学习框架自带算法应用Adam算法,这里我们只需要传递配置参数。
mxnetpytorchtensorflowpaddle
d2l.train_concise_ch11('adam', {'learning_rate': 0.01}, data_iter)
loss: 0.243, 0.050 sec/epoch
11.10.3. Yogi
Adam算法也存在一些问题: 即使在凸环境下,当st的二次矩估计值爆炸时,它可能无法收敛。 (Zaheer et al., 2018)为st提出了的改进更新和参数初始化。 论文中建议我们重写Adam算法更新如下:
(11.10.5)st←st−1+(1−β2)(gt2−st−1).
每当gt2具有值很大的变量或更新很稀疏时,st可能会太快地“忘记”过去的值。 一个有效的解决方法是将gt2−st−1替换为gt2⊙sgn(gt2−st−1)。 这就是Yogi更新,现在更新的规模不再取决于偏差的量。
(11.10.6)st←st−1+(1−β2)gt2⊙sgn(gt2−st−1).
论文中,作者还进一步建议用更大的初始批量来初始化动量,而不仅仅是初始的逐点估计。
mxnetpytorchtensorflowpaddle
def yogi(params, states, hyperparams):
beta1, beta2, eps = 0.9, 0.999, 1e-3
for p, (v, s) in zip(params, states):
v[:] = beta1 * v + (1 - beta1) * p.grad
s[:] = s + (1 - beta2) * np.sign(
np.square(p.grad) - s) * np.square(p.grad)
v_bias_corr = v / (1 - beta1 ** hyperparams['t'])
s_bias_corr = s / (1 - beta2 ** hyperparams['t'])
p[:] -= hyperparams['lr'] * v_bias_corr / (np.sqrt(s_bias_corr) + eps)
hyperparams['t'] += 1
data_iter, feature_dim = d2l.get_data_ch11(batch_size=10)
d2l.train_ch11(yogi, init_adam_states(feature_dim),
{'lr': 0.01, 't': 1}, data_iter, feature_dim);
loss: 0.244, 0.114 sec/epoch
11.10.4. 小结
-
Adam算法将许多优化算法的功能结合到了相当强大的更新规则中。
-
Adam算法在RMSProp算法基础上创建的,还在小批量的随机梯度上使用EWMA。
-
在估计动量和二次矩时,Adam算法使用偏差校正来调整缓慢的启动速度。
-
对于具有显著差异的梯度,我们可能会遇到收敛性问题。我们可以通过使用更大的小批量或者切换到改进的估计值st来修正它们。Yogi提供了这样的替代方案。
关键步骤
- 计算梯度的一阶矩和二阶矩:
对于时间步t,给定梯度gt,对应的一阶矩mt和二阶矩vt分别为:
mt=β1⋅mt−1+(1−β1)⋅gtvt=β2⋅vt−1+(1−β2)⋅gt2
其中β1和β2是超参数,通常接近1。
- 偏置校正:
由于mt和vt都是被初始化为向量,Adam需要对这些矩进行校正,以消除初期估计的偏差:m^t=mt1−β1tv^t=vt1−β2t
- 参数更新:
最后,利用校正过的矩值来更新参数:θt+1=θt−αv^t+ϵm^t其中,θ是待优化参数,α是学习率,ϵ是为了防止除以零而添加的很小的数值(一般为10−8)。
3. Adam的优点
- 自适应学习率:Adam算法通过考虑梯度的一阶和二阶矩来自适应调整每个参数的学习率,有助于更快地收敛。
- 偏置校正:通过偏置校正,Adam算法可以调整初始阶段的矩估计,从而提高算法的稳定性。
- 适用于非稳态目标:有效处理梯度的稀疏性和噪声问题。
- 易于实现:Adam算法的实现相对简单,并且在大多数深度学习框架中都有内置支持,如TensorFlow和PyTorch。