Python 机器学习库:Scikit-learn
1、什么是 Scikit-learn?
Scikit-learn (通常缩写为 sklearn)是一个基于 Python 的开源机器学习库。它构建在 NumPy、SciPy 和 Matplotlib 之上,提供了大量用于数据挖掘和数据分析的工具,包括分类、回归、聚类、降维、模型选择、预处理等等。
2、背景与发展历程
-
起源:scikit-learn 最初由 David Cournapeau 在 2007 年作为 Google Summer of Code 项目启动,随后在多个开发者和研究人员的贡献下不断发展壮大。
-
开源与社区:作为一个开源项目,它拥有活跃的社区支持,不断更新和完善。用户可以在 GitHub 上查看代码、报告问题或参与贡献。
3、核心特点:
- 简单高效: Scikit-learn 的设计目标是提供简单且高效的工具,其 API 设计一致且易于使用,即使对于机器学习初学者也很友好。
- 全面的算法库: 它包含了各种常用的机器学习算法,涵盖了监督学习和无监督学习的多个领域。
- 完善的文档: Scikit-learn 拥有非常完善且易于理解的官方文档,包括详细的 API 参考、用户指南和示例。
- 与其他 Python 科学计算库的良好集成: Scikit-learn 可以很好地与 NumPy(用于数值计算)、SciPy(用于科学计算)和 Matplotlib(用于绘图)等其他 Python 库协同工作。
- 开源且商业友好: Scikit-learn 采用 BSD 许可证,这意味着它可以免费用于商业和非商业用途。
- 活跃的社区: Scikit-learn 拥有一个庞大且活跃的社区,用户可以在社区中寻求帮助、分享经验和贡献代码。
- 高效性:基于 NumPy、SciPy 和 matplotlib 构建,底层采用高效的数值计算,适合处理中小规模的数据。
4、核心组件:
Scikit-learn 的主要功能可以归纳为以下几个核心组件:
1.估计器 (Estimators):
- 估计器是 Scikit-learn 中实现学习算法的核心对象。它们用于从数据中学习模型。
- 常见的估计器包括用于分类的
LogisticRegression、SVC(Support Vector Classifier),用于回归的LinearRegression、RandomForestRegressor,以及用于聚类的KMeans等。 - 所有估计器都有一个
fit(X, y)方法用于训练模型(对于监督学习)或fit(X)方法(对于无监督学习)。 - 监督学习的估计器通常还有一个
predict(X)方法用于对新数据进行预测,以及score(X, y)方法用于评估模型性能。
2.转换器 (Transformers):
- 转换器用于对数据进行预处理和特征工程。它们将原始数据转换为更适合机器学习模型处理的形式。
- 常见的转换器包括用于特征缩放的
StandardScaler、MinMaxScaler,用于特征编码的OneHotEncoder,用于降维的PCA(Principal Component Analysis) 等。 - 转换器通常有一个
fit(X)方法用于学习转换规则,以及transform(X)方法用于应用这些规则将数据转换为新的表示形式。 - 有些转换器还提供
fit_transform(X)方法,用于一步完成学习和转换。
3.数据集 (Datasets):
- Scikit-learn 内置了一些常用的数据集,方便用户进行实验和学习。
- 例如,
load_iris()加载鸢尾花数据集,load_digits()加载手写数字数据集,make_classification()和make_regression()可以生成用于分类和回归的合成数据集。
4.模型选择 (Model Selection):
- 这个模块提供了用于评估模型性能和选择最佳模型和超参数的工具。
- 包括用于将数据划分为训练集和测试集的
train_test_split,用于交叉验证的cross_val_score、KFold,以及用于超参数调优的GridSearchCV、RandomizedSearchCV等。
5.评估指标 (Metrics):
- Scikit-learn 提供了各种用于评估模型性能的指标。
- 对于分类任务,常见的指标包括准确率 (accuracy)、精确率 (precision)、召回率 (recall)、F1 分数 (f1-score)、AUC 等。
- 对于回归任务,常见的指标包括均方误差 (mean squared error)、平均绝对误差 (mean absolute error)、R 平方 (r2 score) 等。
6.管道 (Pipelines):
- 管道可以将多个估计器和转换器串联起来,形成一个完整的工作流程。
- 这可以简化模型构建、训练和评估的过程,并有助于避免数据泄露。
5、常用算法介绍
-
分类:如支持向量机(SVM)、决策树、随机森林、朴素贝叶斯、KNN 等。
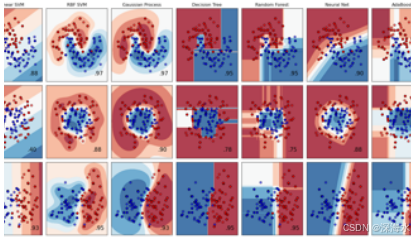
-
回归:如线性回归、岭回归、Lasso 回归、支持向量回归(SVR)等。
-
聚类:包括 K-means、层次聚类、DBSCAN 等。
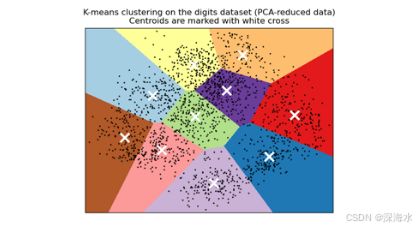
-
降维:如 PCA、t-SNE、因子分析等。
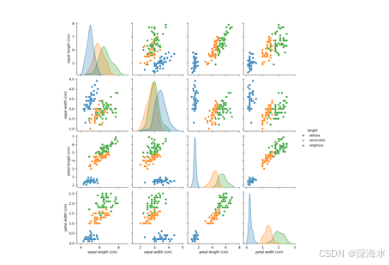
-
模型评估:提供多种评估指标,如准确率、均方误差、ROC 曲线等,用于判断模型效果。
- 预处理: 特征提取和规范化。转换输入数据(例如文本)以供机器学习算法使用。
6、使用场景与应用案例
-
学术研究:由于其简单易用和丰富的算法库,scikit-learn 被广泛用于学术研究,帮助研究者快速实现原型和实验。
-
工业应用:在商业数据分析、金融风控、推荐系统等领域都有应用,尤其适用于中小规模数据处理和原型验证。
-
教学与入门:由于其直观的 API 和大量实例教程,它成为许多机器学习课程和在线教育平台的首选工具。
Scikit-learn 被广泛应用于各种领域,包括:
- 图像识别
- 自然语言处理
- 推荐系统
- 金融风控
- 医疗诊断
- 欺诈检测
- 客户流失预测
- 市场营销分析
7、典型的工作流程:
使用 Scikit-learn 进行机器学习任务通常遵循以下步骤:
- 导入所需的模块和类: 根据任务需求导入相应的估计器、转换器、模型选择工具和评估指标。
- 加载或创建数据集: 加载内置数据集、从文件中读取数据或生成合成数据。
- 数据预处理: 对数据进行清洗、缺失值处理、特征缩放、特征编码等操作,使用转换器完成。
- 划分数据集: 将数据集划分为训练集和测试集,用于模型训练和评估。
- 选择模型: 根据任务类型(分类、回归、聚类等)选择合适的机器学习模型(估计器)。
- 训练模型: 使用训练数据调用估计器的
fit()方法训练模型。 - 模型评估: 使用测试数据调用估计器的
predict()方法进行预测,并使用评估指标评估模型性能。 - 模型调优 (可选): 使用交叉验证和超参数搜索等技术优化模型性能。
- 部署模型 (可选): 将训练好的模型部署到实际应用中。
8、优点与局限性
1.Scikit-learn 的优势:
- 易用性: API 设计简洁一致,学习曲线平缓。
- 效率: 底层使用 NumPy 和 SciPy 实现,计算效率高。
- 丰富的功能: 涵盖了机器学习的多个方面。
- 良好的文档和社区支持: 方便用户学习和解决问题。
- 与其他 Python 库的兼容性: 可以方便地与其他数据科学工具集成。
2.Scikit-learn 的局限性:
- 主要关注传统机器学习算法: 对于深度学习的支持相对较弱,通常需要与其他深度学习框架(如 TensorFlow、PyTorch)结合使用。
- 不适用于大规模分布式计算: 对于非常大的数据集,可能需要使用专门的分布式机器学习框架。
- 某些高级或最新的研究算法可能没有直接实现。
9、如何开始使用 Scikit-learn:
- 安装: 如果你还没有安装 Scikit-learn,可以使用 pip 进行安装:
或者使用 conda:pip install scikit-learnconda install scikit-learn - 导入: 在 Python 代码中导入 Scikit-learn 模块:
通常会导入特定的子模块和类,例如:import sklearnfrom sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from sklearn.preprocessing import StandardScaler from sklearn.datasets import load_iris
10、学习资源:
- 官方网站和文档: https://scikit-learn.org/stable/ 这是学习 Scikit-learn 最权威的资源。
- 官方教程和示例: 官方文档提供了大量的教程和示例代码,帮助你快速上手。
- 在线课程和书籍: 有很多优秀的在线课程(如 Coursera、edX)和书籍专门介绍 Scikit-learn 和机器学习。
- Stack Overflow 和 GitHub: 在这些平台上可以找到很多关于 Scikit-learn 的问题和解答,以及开源项目。
11、 入门示例
下面是一个简单的使用 scikit-learn 进行手写数字识别的小示例:
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 加载数据集
digits = datasets.load_digits()
X, y = digits.data, digits.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 建立并训练模型
clf = SVC(gamma=0.001)
clf.fit(X_train, y_train)
# 预测并评估
y_pred = clf.predict(X_test)
print("准确率:", accuracy_score(y_test, y_pred))
这个示例的关键步骤包括:
-
数据加载:通过
datasets.load_digits()获取数据。 -
数据分割:使用
train_test_split划分训练集和测试集。 -
模型训练:构建 SVM 模型并调用
fit方法训练。 -
模型评估:利用
accuracy_score计算模型的准确率。
这个示例展示了如何加载数据、划分数据集、训练模型以及评估模型的整个流程,体现了 scikit-learn 在构建机器学习管道方面的便利性。
12、总结
scikit-learn 是一个功能全面、文档完善、易于上手的机器学习库,适用于各种数据分析和机器学习任务,是数据科学和机器学习从业者的必备工具之一。无论你是刚刚入门的数据科学爱好者,还是需要快速构建原型的研究者,它都是一个非常值得使用的工具。希望这个介绍能够帮助你更好地理解和使用 Scikit-learn。