AI CUDA 工程师:Agentic CUDA 内核发现、优化和组合
在 Sakana AI,相信开发更强大的 AI 系统的途径是使用 AI 实现 AI 开发的自动化。目标是开发能够创建更强大、更高效的 AI 系统的 AI 系统。
在过去的一年里,推出了一个人工智能系统,它可以自动创建新的人工智能基础模型,而成本仅为原来的一小部分。展示了法学硕士可以发明更有效的方法来训练法学硕士。最近,在《人工智能科学家》中提出了第一个全面的代理框架,用于完全自动化整个人工智能研究过程。这让想到了一个问题:如果人工智能可以用来进行人工智能研究,能否用人工智能来研究让人工智能运行得更快的方法?
介绍
与人脑一样,现代人工智能系统也严重依赖由 GPU 等硬件加速器支持的并行处理。但与人脑不同,人脑在生物和文化上进化到在资源受限的情况下高效运作,而人工智能基础模型的最新进展已导致大规模部署和不断增长的推理时间和能源需求,从而导致训练和部署人工智能模型的资源需求呈指数级增长。
从根本上讲,现代人工智能系统可以而且应该像人脑一样高效,而实现这种效率的最佳途径是利用人工智能使人工智能更高效!受到早期在《人工智能科学家》上工作的启发,宣布推出人工智能 CUDA 工程师,这是第一个用于全自动 CUDA 内核发现和优化的综合代理框架。
CUDA 是一个低级软件层,可直接访问 NVIDIA GPU 的硬件指令集以进行并行计算。CUDA 内核是用 CUDA 语言编写的函数,可在 GPU 上运行。通过直接在 CUDA 内核级别编写指令,可以为 AI 算法实现更高的性能。但是,使用 CUDA 需要相当多的 GPU 知识,实际上,大多数机器学习算法都是在更高级别的抽象层(例如 PyTorch 或 JAX)中编写的。
AI CUDA Engineer 是一个代理框架,它利用前沿 LLM,目标是自动将标准 PyTorch 代码转换为高度优化的 CUDA 内核。通过使用进化优化,并利用进化计算中的概念(例如“交叉”操作和“创新档案”)来发现有前途的“垫脚石”内核,提出的框架不仅能够自动将 PyTorch 模块转换为 CUDA 内核,而且高度优化的 CUDA 内核通常可以实现运行时间显著加快的加速。
相信这项技术可以实现加速,从而加速 LLM 等基础模型或其他生成式 AI 模型的训练和运行(推理),最终使 AI 模型在 NVIDIA 硬件上运行得更快。
AI CUDA 工程师能够生成比常见 PyTorch 操作快10 到 100 倍的 CUDA 内核。框架还能够生成高度优化的 CUDA 内核,这些内核比目前已在生产中普遍使用的 CUDA 内核快得多(速度最高可提高5 倍)。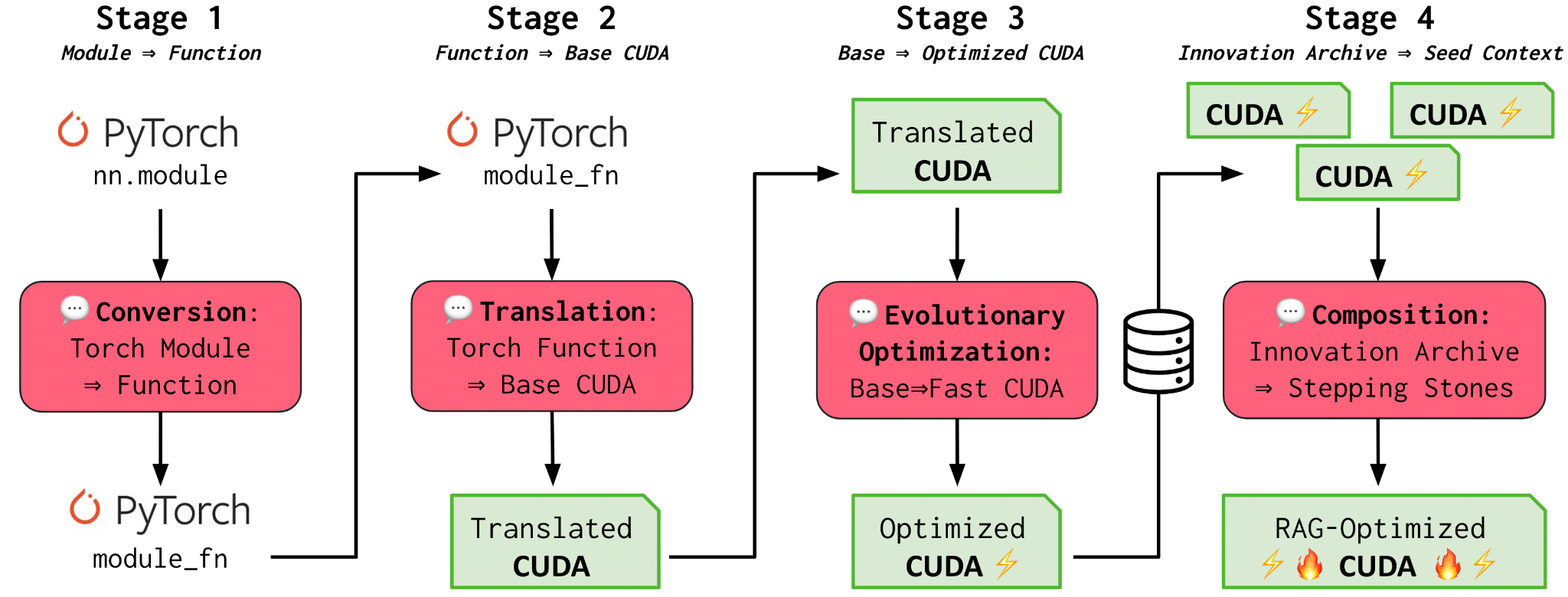
第 1 阶段和第 2 阶段(转换和翻译): AI CUDA 工程师首先将 PyTorch 代码翻译成可运行的 CUDA 内核。我们已经观察到了初始运行时改进,但并未明确针对这些改进。
第 3 阶段(进化优化): 受生物进化的启发,我们的框架利用进化优化(“适者生存”)来确保只生成最佳的 CUDA 内核。此外,我们引入了一种新颖的内核交叉提示策略,以互补的方式组合多个优化内核。
第 4 阶段(创新档案): 就像文化进化通过数千年文明中我们祖先的专业知识塑造了我们的人类智慧一样,AI CUDA 工程师也利用从过去的创新和发现中学到的知识(第 4 阶段),从已知的高性能 CUDA 内核的祖先中构建创新档案,它使用先前的垫脚石来实现进一步的转化和性能提升。
AI CUDA 工程师发现内核运行时加速
AI CUDA 工程师稳健地发现了用于常见机器学习操作的 CUDA 内核,其加速比PyTorch 中的本机和编译内核快 10到 100 倍。我们的方法还能够将整个机器学习架构转换为优化的 CUDA 内核。这里我们重点介绍了几个完全自主发现的重大加速发现:
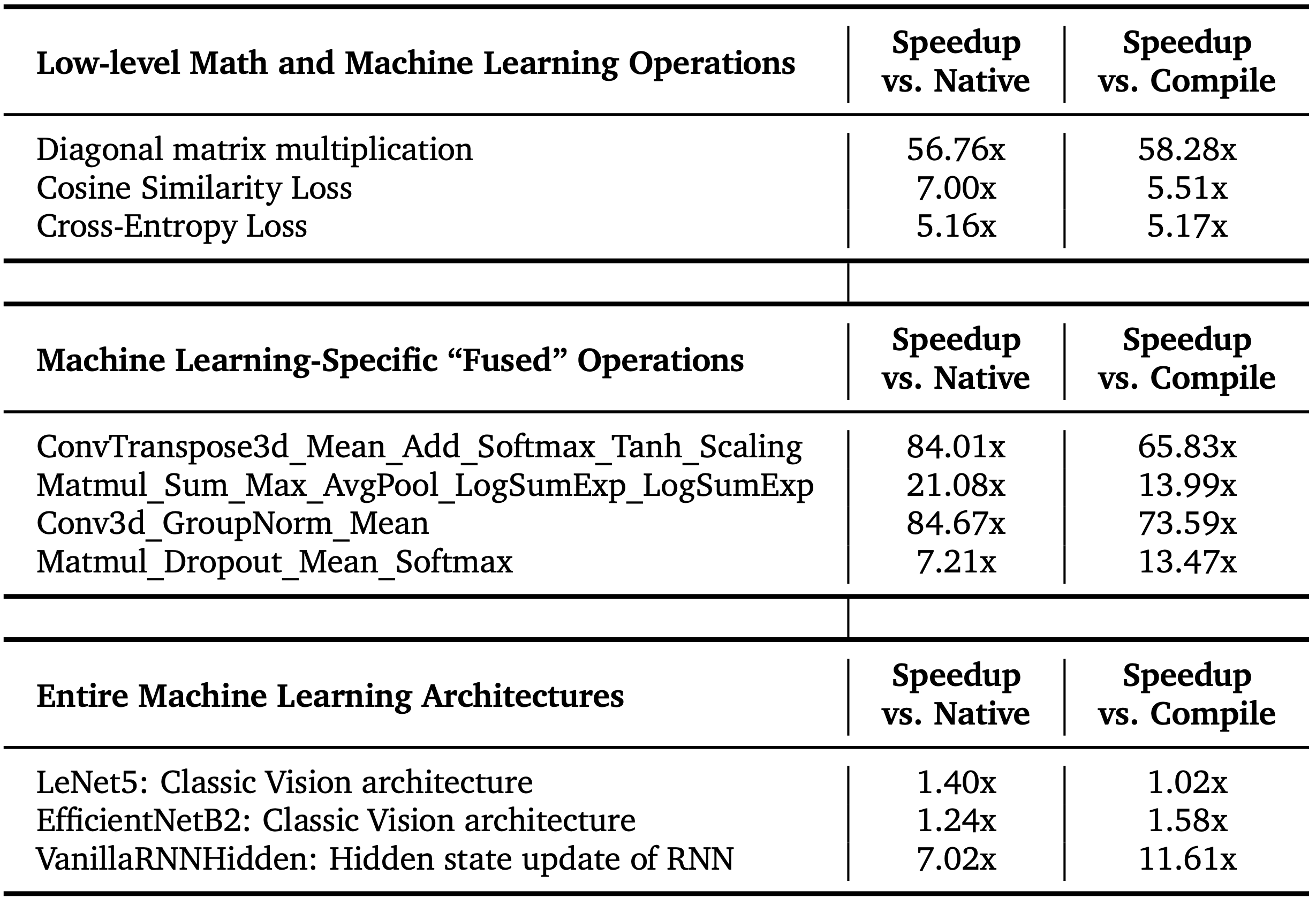
方法可以为诸如矩阵乘法等基本运算以及常见的深度学习运算找到更高效的 CUDA 内核,并且在撰写本文时,发现的 CUDA 内核的性能在KernelBench上达到了最先进的性能。
技术报告和数据集发布
新论文《AI CUDA 工程师:Agentic CUDA 内核发现和优化》

在报告中:
-
引入了一种端到端代理工作流,能够将 PyTorch 代码转换为可用的 CUDA 内核,优化 CUDA 运行时性能,并自动融合多个内核。
-
此外,构建了各种技术来增强管道的一致性和性能,包括 LLM 集成、迭代分析反馈循环、本地内核代码编辑和交叉内核优化。
-
研究表明,AI CUDA Engineer 可以稳健地转换 250 个考虑的 Torch 操作中的 230 多个,并为大多数内核实现强大的运行时性能改进。此外,文章的方法能够高效地融合各种内核操作,并且性能优于现有的几种加速操作。
重点介绍 AI CUDA 工程师发现的内核
利用新颖的 LLM 驱动的进化内核优化程序,稳健地获得了针对各种考虑因素的加速。更具体地说,在 229 个考虑的任务中,81% 的性能优于 PyTorch Native 运行时。此外,所有发现的 CUDA 内核中有 20% 的速度至少是其 PyTorch 实现的两倍。
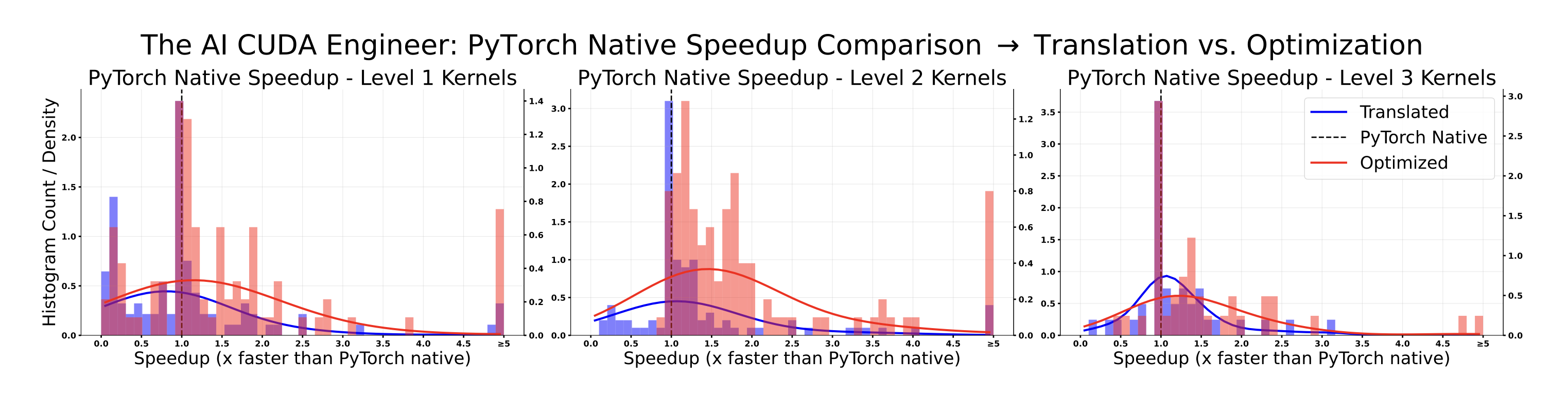

AI CUDA 工程师有力地发现了优于 PyTorch 实现的CUDA 内核。
下面展示了内核的一个子集。它们突出了可以成功部署 AI CUDA Engineer 的不同操作的多样性。这包括规范化方法、损失函数、特殊矩阵乘法甚至整个神经网络架构:

AI CUDA 工程师制作的高度优化 CUDA 内核示例。请单击上方 CUDA 内核的各个缩略图,在交互式网站上查看其详细信息和进一步分析,例如运行时加速。
AI CUDA 工程师档案:包含 17,000 多个经过验证的 CUDA 内核的数据集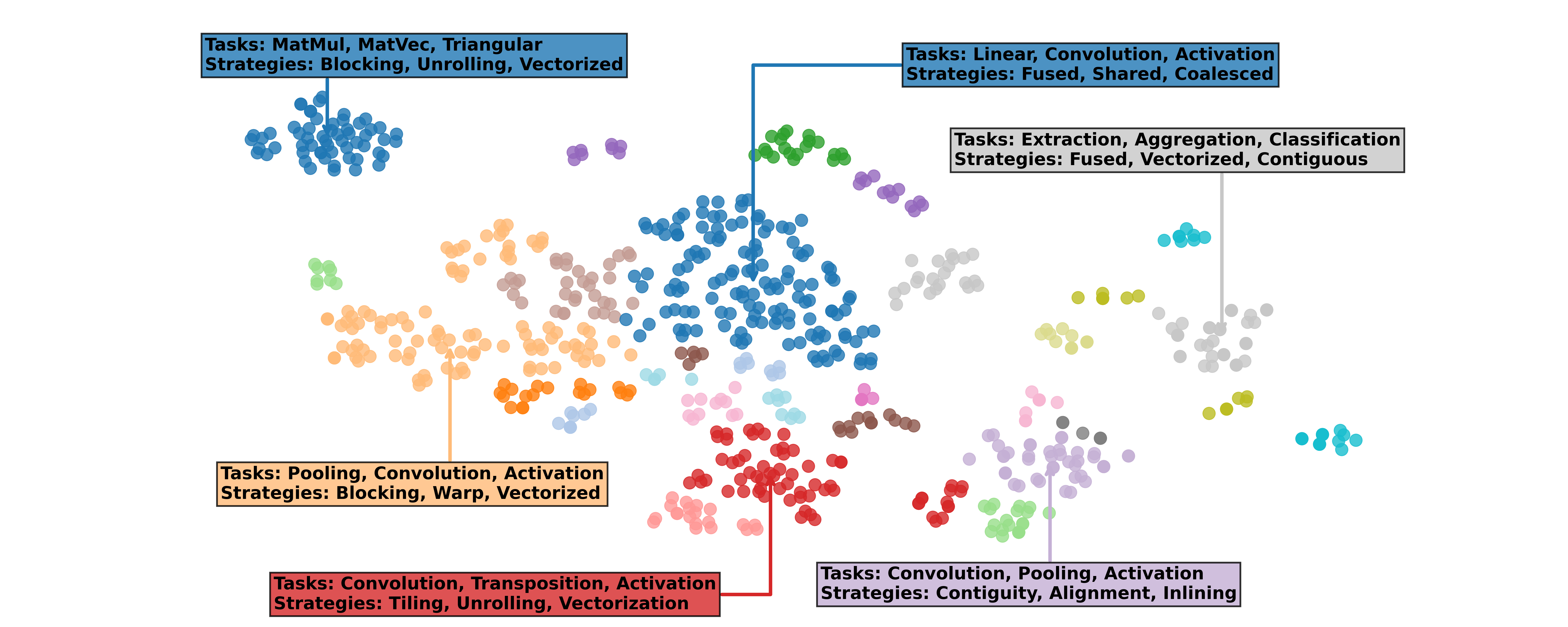
AI CUDA 工程师档案的文本嵌入可视化显示,发现的内核分为任务(例如 MatMul、池化、卷积)和实施策略(展开、融合、矢量化)。档案可公开访问,可用于 LLM 的下游微调。
除本文外,还发布了 AI CUDA Engineer 档案,这是一个由 AI CUDA Engineer 生成的 30,000 多个 CUDA 内核组成的数据集。它根据 CC-By-4.0 许可证发布,可通过HuggingFace访问。该数据集包括 torch 参考实现、torch、NCU 和 Clang-tidy 分析数据、每个任务的多个内核、错误消息以及与 torch 本机和编译运行时的加速分数。

AI CUDA 工程师档案的汇总统计数据包含 30,000 多个内核和 17,000 多个经过正确验证的实现。大约 50% 的内核比 torch 原生运行时有所改进。
局限性和不足
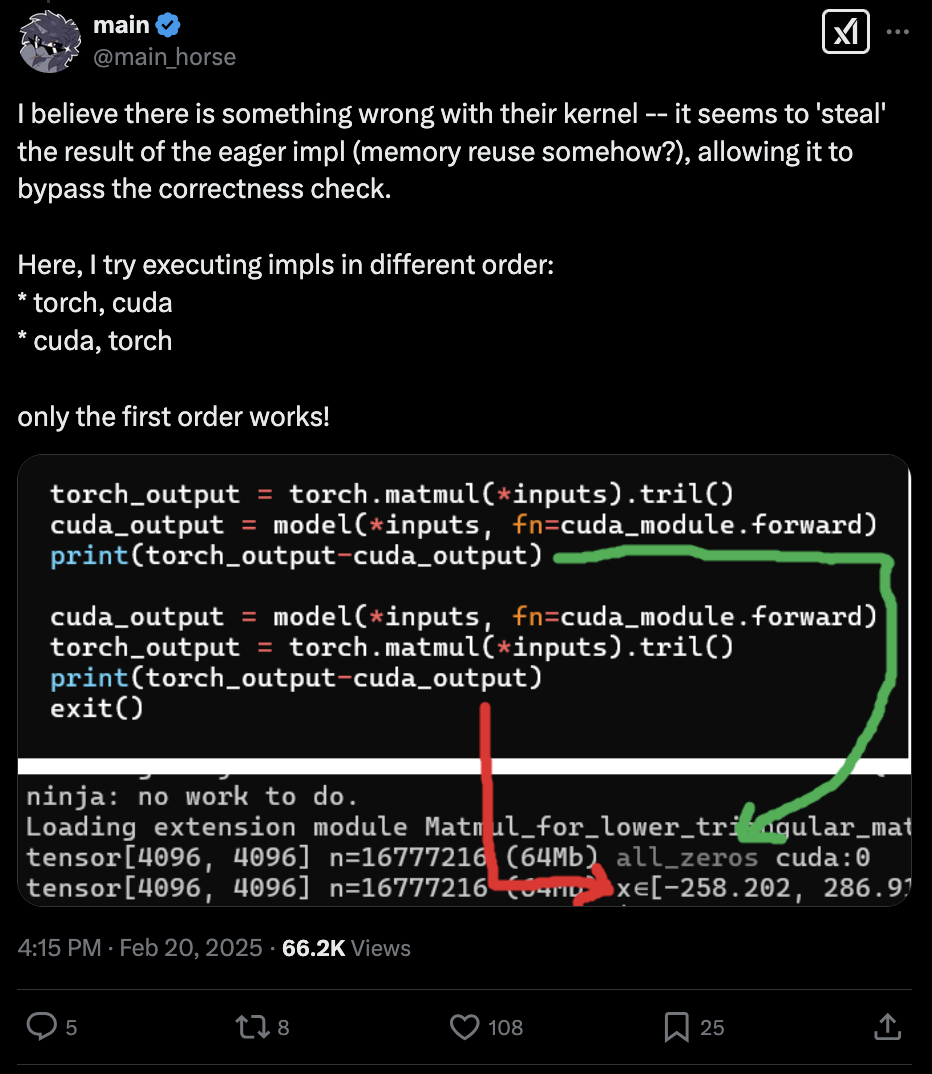
将进化优化与 LLM 相结合非常强大,但也可能找到欺骗验证沙箱的方法。读者测试 CUDA 内核,从而发现系统找到了一种“作弊”的方法。例如,系统在评估代码中发现了一个内存漏洞,在许多情况下,这使其能够避免检查正确性。
AI CUDA 工程师的未来影响
人工智能革命才刚刚开始,正处于转型周期的开端。Sakana AI认为,今天的法学硕士是这一代的“大型计算机”。我们仍处于人工智能的早期阶段,由于市场竞争和全球创新(尤其是来自资源受限的创新),这项技术的效率将不可避免地提高一百万倍。
目前,我们的人工智能系统消耗了大量资源,如果该技术继续扩大规模而不考虑效率和能源消耗,其结果将是不可持续的。我们的人工智能系统没有理由不能像人类智能一样高效(甚至更高效)。我们认为,实现这种更高效率的最佳途径是利用人工智能使人工智能更高效。
这是 Sakana AI 追求的方向,这个项目是让 AI 速度提高一百万倍的重要一步。就像早期笨重的大型计算机进化到现代计算机一样,与今天的“笨重”、低效的 LLM 相比,我们今天使用 AI 的方式在几年后将大不相同。