自然语言处理(18:(第五章3.)LSTM的实现)
系列文章目录
第五章 1:Gated RNN(门控RNN)
第五章 2:梯度消失和LSTM
第五章 3:LSTM的实现
第五章 4:使用LSTM的语言模型
第五章 5:进一步改进RNNLM(以及总结)
文章目录
目录
系列文章目录
文章目录
前言
一、LSTM的代码实现
二、Time LSTM层的实现
前言
下面,我们来实现LSTM。这里将进行单步处理的类实现为LSTM类, 将整体处理T步的类实现为TimeLSTM类。现在我们先来整理一下LSTM中 进行的计算,如下所示:
一、LSTM的代码实现
首先LSTM要进行的计算有:

上述式子中,前四个式子(f, g, i, o)是仿射变换,这里的仿射变换是指xWx+hWh+b这样的式子。虽然通过4个式子可以分别进行仿射变换,但其实也可以整合为通过1个式子进行。如下图所示:

在上图中,4个权重(或偏置)被整合为了1个。如此,原本单独执行4次的仿射变换通过1次计算即可完成,可以加快计算速度。这是因为矩阵库计算“大矩阵”时通常会更快,而且通过将权重整合到一起管理,源代码也会更简洁。
假设Wx、Wh和b分别包含4个权重(或偏置),此时LSTM的计算图如下图所示。(如果看不懂,看看博主前几篇文章,你就会明白)
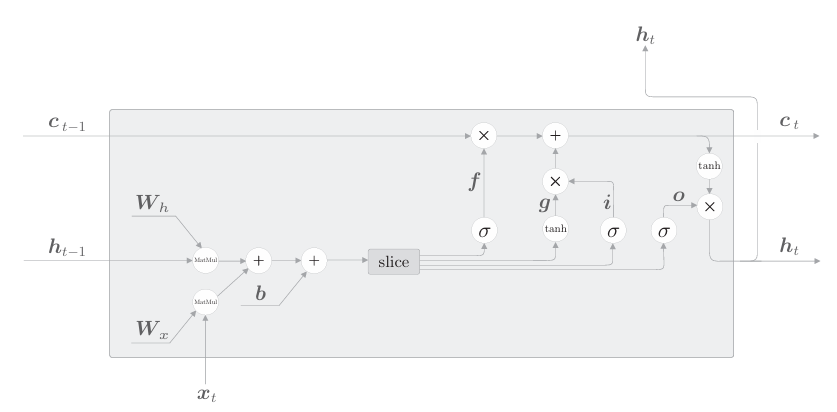
如上计算图所示,先一起执行4个仿射变换。然后,基于slice节点,取出4个结果。这个slice节点很简单,它将仿射变换的结果(矩阵)均等地分成4份,然后取出内容。在slice节点之后,数据流过激活函数(sigmoid 函数或tanh函数),进行上一节介绍的计算。
现在,参考上面计算图,我们来实现LSTM类。首先来看一下LSTM类的初始化代码:
from common.layers import *
from common.functions import softmax, sigmoid
"""
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def softmax(x):
if x.ndim == 2:
x = x - x.max(axis=1, keepdims=True)
x = np.exp(x)
x /= x.sum(axis=1, keepdims=True)
elif x.ndim == 1:
x = x - np.max(x)
x = np.exp(x) / np.sum(np.exp(x))
return x
"""
class LSTM:
def __init__(self, Wx, Wh, b):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.cache = None初始化的参数有权重参数Wx、Wh和偏置b。如前所述,这些权重(或偏 置)整合了4个权重。把这些参数获得的权重参数设定给成员变量params, 并初始化形状与之对应的梯度。另外,成员变量cache保存正向传播的中间 结果,它们将在反向传播的计算中使用.
接下来实现正向传播的forward(x, h_prev, c_prev) 方法。它的参数接 收当前时刻的输入x、上一时刻的隐藏状态h_prev,以及上一时刻的记忆单元c_prev。
def forward(self, x, h_prev, c_prev):
"""
看着计算图一步步填进去,你会明白的!!,相信自己
"""
Wx, Wh, b = self.params
N, H = h_prev.shape
A = np.dot(x, Wx) + np.dot(h_prev, Wh) + b
# slice
f = A[:, :H]
g = A[:, H:2*H]
i = A[:, 2*H:3*H]
o = A[:, 3*H:]
f = sigmoid(f) # sigmoid代码实现在LSTM定义最上面
g = np.tanh(g)
i = sigmoid(i)
o = sigmoid(o)
c_next = f * c_prev + g * i
h_next = o * np.tanh(c_next)
self.cache = (x, h_prev, c_prev, i, f, g, o, c_next)
return h_next, c_next首先进行仿射变换。重复一下,此时的成员变量Wx、Wh和b保存的是4个权重,矩阵的形状将变为如下图所示的样子。

在上图式子中,批大小是N,输入数据的维数是D,记忆单元和隐藏状态的维数都是H。另外,计算结果A中保存了4个仿射变换的结果。因此,通过A[:, :H]、A[:, H:2*H] 这样的切片取出数据,并分配给之后的运算节点。 参考LSTM的数学式和计算图,剩余的实现应该不难
LSTM的反向传播可以通过将上面的计算图反方向传播而求得。基于前面介绍的知识,这并不困难。不过,因为slide节点是第一次见到,所以我们简要说明一下它的反向传播。slice 节点将矩阵分成了4份,因此它的反向传播需要整合4个梯度,如下图所示。

由上图可知,在slice节点的反向传播中,拼接4个矩阵。图中有4个梯度df、dg、di和do,将它们拼接成dA。如果通过NumPy进行,则可以使用np.hstack()。np.hstack() 在水平方向上将参数中给定的数组拼接起来(垂直方向上的拼接使用np.vstack())。因此,上述处理可以用下面1行代码完成。 dA = np.hstack((df, dg, di, do)) 以上就是对slice节点的反向传播的说明。
二、Time LSTM层的实现
现在我们继续TimeLSTM的实现。Time LSTM层是整体处理T个时序数据的层,由T个LSTM层构成,如下图所示。
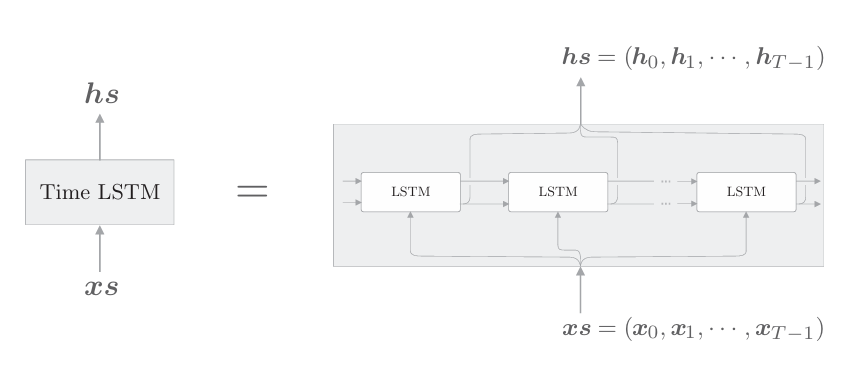
如前所述,RNN中使用Truncated BPTT进行学习。Truncated BPTT以适当的长度截断反向传播的连接,但是需要维持正向传播的数据流。为此,如下图所示,将隐藏状态和记忆单元保存在成员变量中。这样一来,在调用下一个forward()函数时,就可以继承上一时刻的隐藏状态 (和记忆单元)。

我们已经实现了Time RNN层(在自然语言处理(13:RNN的实现)-CSDN博客),这里也以同样的方式实现Time LSTM层。TimeLSTM可以像下面这样实现:
class TimeLSTM:
def __init__(self, Wx, Wh, b, stateful=False):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.layers = None
self.h, self.c = None, None
self.dh = None
self.stateful = stateful
def forward(self, xs):
Wx, Wh, b = self.params
N, T, D = xs.shape
H = Wh.shape[0]
self.layers = []
hs = np.empty((N, T, H), dtype='f')
if not self.stateful or self.h is None:
self.h = np.zeros((N, H), dtype='f')
if not self.stateful or self.c is None:
self.c = np.zeros((N, H), dtype='f')
for t in range(T):
layer = LSTM(*self.params) # 此处实现在上面哦
self.h, self.c = layer.forward(xs[:, t, :], self.h, self.c)
hs[:, t, :] = self.h
self.layers.append(layer)
return hs
def backward(self, dhs):
Wx, Wh, b = self.params
N, T, H = dhs.shape
D = Wx.shape[0]
dxs = np.empty((N, T, D), dtype='f')
dh, dc = 0, 0
grads = [0, 0, 0]
for t in reversed(range(T)):
layer = self.layers[t]
dx, dh, dc = layer.backward(dhs[:, t, :] + dh, dc)
dxs[:, t, :] = dx
for i, grad in enumerate(layer.grads):
grads[i] += grad
for i, grad in enumerate(grads):
self.grads[i][...] = grad
self.dh = dh
return dxs
def set_state(self, h, c=None):
self.h, self.c = h, c
def reset_state(self):
self.h, self.c = None, None
在LSTM中,除了隐藏状态h外,还使用记忆单元c。TimeLSTM类的实现和TimeRNN 类几乎一样。这里仍通过参数stateful指定是否维持状态。接下来,我们使用这个TimeLSTM创建语言模型。