13 配置Hadoop集群-测试使用
第一课时
一、导入
前面的课程我们搭建了hadoop集群,并成功启动了它,接下来我们看看如何去使用集群。
测试的内容包括:1.上传文件,2.下载文件,3.运行程序
二、授新
(一)上传小文件
上传文件的时候,我们传一个大一点的(>128M),再传一个小一点的。对于大一点的文件,我们要去看看它是否会按128M为单位去拆分这个大文件,而拆分成大文件之后,我们又怎么才能去还原?
下面我们来看具体操作:
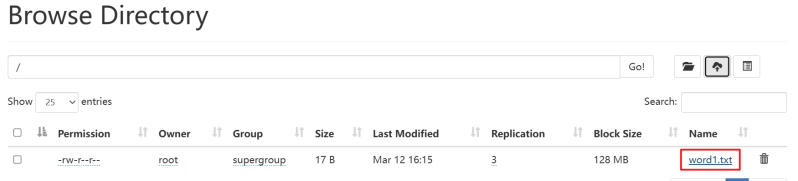
打开hadoop100:9870,点击上传,选择我们需要上传的文件(建议选择一个简单的文本文件),上传之后的结果如下:
命令格式如下:
hadoop fs -put 要上传的文件 目标位置
下面我们上传一个小文件,你可以自己去找一个文本文件,或者自己创建一个都可以。cd
上传小文件(小于128M)
[root@hadoop100 ~]$ hadoop fs -mkdir /input
[root@hadoop100 ~]$ hadoop fs -put $HADOOP_HOME/wcinput/word.txt /input
上传大文件(大于128M)
[root@hadoop100 ~]$ hadoop fs -put /opt/software/jdk-8u212-linux-x64.tar.gz /
(二)查看上传的小文件
上传文件后查看文件存放在什么位置
在我们上一节的hadoop配置中,我们设置了保持文件的目录是/data,所以,我们进入hadoop的按照目录下的data中去看一看。
这个存储的目录特别深,大概类似于:/opt/module/hadoop-3.1.3/data/dfs/data/current/BP-1436128598-192.168.10.102-1610603650062/current/finalized/subdir0/subdir0
文件的名称是blk_xxx。我们可以使用cat命令查看HDFS在磁盘存储文件内容:
[root@hadoop102 subdir0]$ cat blk_1073741825
hadoop yarn
hadoop mapreduce
root
root
(三)上传大文件
前面我们上传了一个小文件,可以看到这个文件太小,hadoop被没有被切分成小块。接下来我们传一个大一点的文件,例如jdk的安装包。(注意,你可以上传一些别的文件,但是务必确保大小是大于128M)

我们把它保存在集群的根目录。
上传完成之后,我们去查看,很明显大文件被分块了,128M一块,一共有两个块。可以通过cat >> 命令把两个块的内容拼接到一起,然后再去解压缩一下。
类似于如下:
-rw-rw-r--. 1 root root 134217728 5月 23 16:01 blk_1073741836
-rw-rw-r--. 1 root root 1048583 5月 23 16:01 blk_1073741836_1012.meta
-rw-rw-r--. 1 root root 63439959 5月 23 16:01 blk_1073741837
-rw-rw-r--. 1 root root 495635 5月 23 16:01 blk_1073741837_1013.meta
[root@hadoop102 subdir0]$ cat blk_1073741836>>tmp.tar.gz
[root@hadoop102 subdir0]$ cat blk_1073741837>>tmp.tar.gz
[root@hadoop102 subdir0]$ tar -zxvf tmp.tar.gz还原成功
(四)集群基本测试-下载
上传的文件我们完成了,那怎么去下载呢? 方法很简单,可以直接在页面上操作。点击对应的下载按钮就可以了。

第二课时
前面我们学习了文件相关的操作,接下来我们看看如何去执行程序,是不是有分布式的效果。我们在前面的课程中使用单机运行模式测试使用了wordcount这个功能,下面我们仍以它为例,来看看如何进行分布式的执行。
(五)执行wordcount程序
具体的操作步骤如下:
- 确保hadoop是正确运行的。hdfs和yarn都正常启动了。
- 在集群根目录下创建wcinput目录,并在它的下面上传两个文本文件word1.txt, word2.txt,其中保存了要测试的单词信息。
- 在任意一台设备中,进入到hadoop的主目录。cd /opt/modele/hadoop-3.1.3
- 运行如下命令:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /wcinput /output
5、在如下网站查看运行的过程和记录http://hadoop101:8088/cluster

6、查看运行结果,在文件系统中查看。

三、课堂小结
通过本堂课的学习,我们学习了hadoop集群配置完成之后的基本组成,测试了上传小文件,大文件和执行程序时的状态。