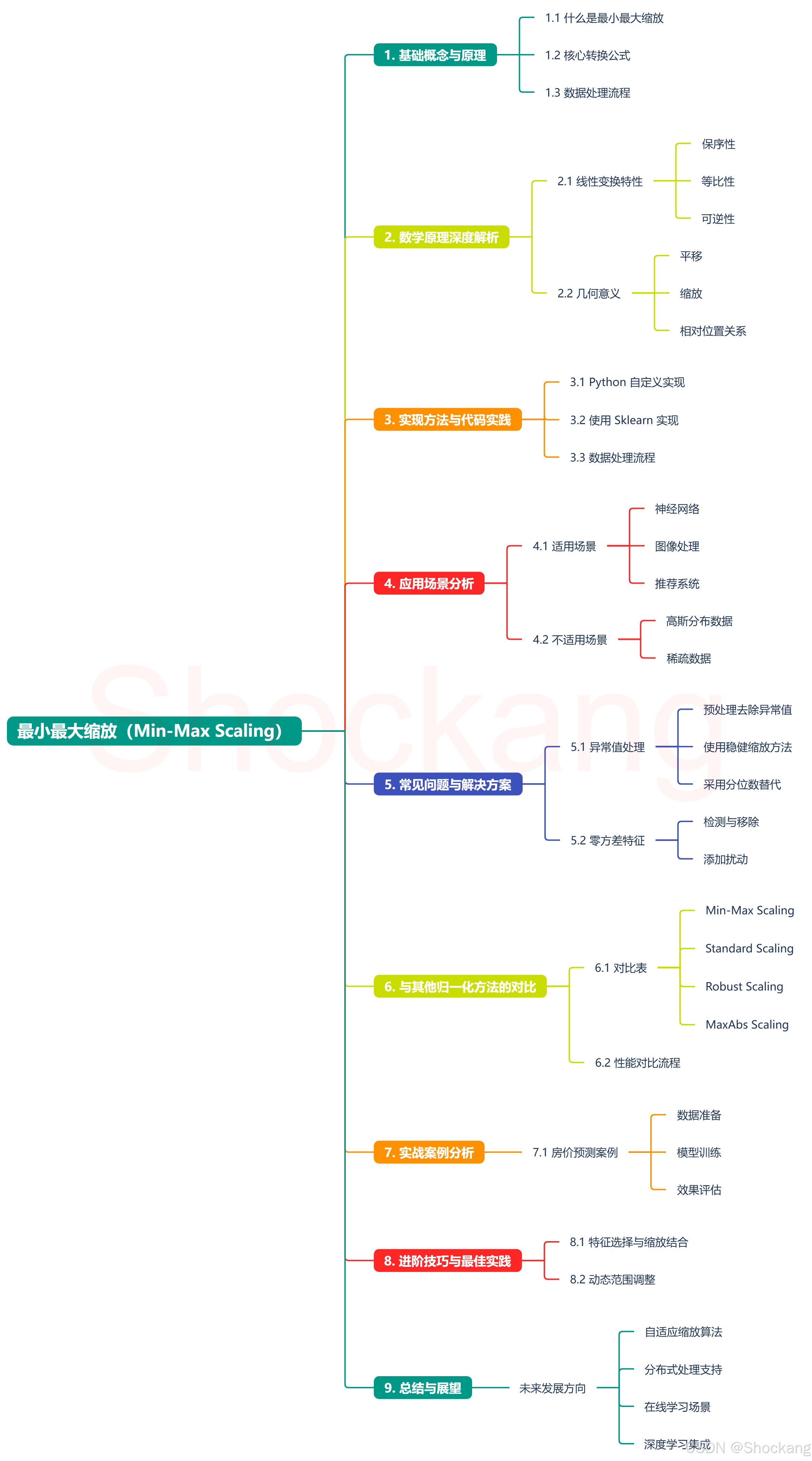
机器学习的一百个概念(6)最小最大缩放
前言
本文隶属于专栏《机器学习的一百个概念》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见[《机器学习的一百个概念》
ima 知识库
知识库广场搜索:
| 知识库 | 创建人 |
|---|---|
| 机器学习 | @Shockang |
| 机器学习数学基础 | @Shockang |
| 深度学习 | @Shockang |
正文
基础概念与原理 🎓
1.1 什么是最小最大缩放?
最小最大缩放(Min-Max Scaling)是机器学习中最常用的特征缩放方法之一,它通过线性变换将数据映射到指定的范围内,通常是 0 , 1 0, 1 0,1 区间。这种转换保持了原始数据的分布特征,同时使得不同量纲的特征可以进行有效比较。
1.2 核心转换公式
对于特征 X 中的任意值 x,其转换公式为:
x s c a l e d = x − x m i n x m a x − x m i n x_{scaled} = \frac{x - x_{min}}{x_{max} - x_{min}} xscaled=xmax−xminx−xmin
对于自定义范围 a , b a, b a,b,转换公式为:
x s c a l e d = a + ( x − x m i n ) ( b − a ) x m a x − x m i n x_{scaled} = a + \frac{(x - x_{min})(b-a)}{x_{max} - x_{min}} xscaled=a+xmax−xmin(x−xmin)(b−a)
1.3 数据处理流程

数学原理深度解析 📐
2.1 线性变换特性
最小最大缩放本质上是一个线性变换过程,具有以下特性:
- 保序性:如果 x 1 < x 2 x_1 < x_2 x1<x2,那么变换后仍有 x 1 ′ < x 2 ′ x_1' < x_2' x1′<x2′
- 等比性:原始数据中的相对差距在转换后保持不变
- 可逆性:通过逆变换可以还原原始数据
2.2 几何意义
在几何空间中,最小最大缩放相当于:
- 平移:将数据最小值移动到原点
- 缩放:将数据范围调整到目标区间
- 保持相对位置关系不变
实现方法与代码实践 💻
3.1 Python 自定义实现
import numpy as np
class CustomMinMaxScaler:
def __init__(self, feature_range=(0, 1)):
self.feature_range = feature_range
self.min_ = None
self.scale_ = None
def fit(self, X):
X = np.array(X)
self.min_ = X.min(axis=0)
self.scale_ = (X.max(axis=0) - self.min_)
return self
def transform(self, X):
X = np.array(X)
X_std = (X - self.min_) / self.scale_
X_scaled = X_std * (self.feature_range[1] - self.feature_range[0]) + self.feature_range[0]
return X_scaled
def fit_transform(self, X):
return self.fit(X).transform(X)
3.2 使用 Sklearn 实现
from sklearn.preprocessing import MinMaxScaler
import numpy as np
# 创建示例数据
X_train = np.array([[1., -1., 2.],
[2., 0., 0.],
[0., 1., -1.]])
X_test = np.array([[0.5, 0., 1.]])
# 创建并使用 MinMaxScaler
scaler = MinMaxScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
print("原始训练数据:", X_train)
print("缩放后的训练数据:", X_train_scaled)
print("原始测试数据:", X_test)
print("缩放后的测试数据:", X_test_scaled)
3.3 数据处理流程
id: data-process
name: Data Processing Flow
type: mermaid
content: |-
sequenceDiagram
participant D as 原始数据
participant T as 训练集处理
participant V as 验证集处理
participant M as 模型训练
D->>T: 划分训练集
D->>V: 划分验证集
T->>T: 计算min/max
T->>T: 应用转换
T->>V: 传递参数
V->>V: 应用相同转换
T->>M: 训练数据输入
V->>M: 验证数据输入
应用场景分析 🎯
4.1 适用场景
-
神经网络
- 输入层归一化,加速收敛
- 避免梯度消失/爆炸
- 提高模型稳定性
-
图像处理
- 像素值归一化到 [0,1]
- 提高图像处理效率
- 标准化图像表示
-
推荐系统
- 用户特征归一化
- 物品特征标准化
- 相似度计算
4.2 不适用场景
-
高斯分布数据
- 建议使用 Z-score 标准化
- 保持数据分布特性
-
稀疏数据
- 可能破坏稀疏性
- 影响特征表达
常见问题与解决方案 🔧
5.1 异常值处理
问题:异常值会显著影响缩放效果
解决方案:
- 预处理去除异常值
- 使用稳健缩放方法
- 采用分位数替代最大最小值
def robust_minmax_scale(X, quantile_range=(1, 99)):
q_min, q_max = np.percentile(X, quantile_range)
X_scaled = (X - q_min) / (q_max - q_min)
X_scaled = np.clip(X_scaled, 0, 1)
return X_scaled
5.2 零方差特征
问题:特征最大最小值相同导致除零
解决方案:
- 检测并移除零方差特征
- 添加小量扰动
def safe_minmax_scale(X, eps=1e-8):
X_min = X.min(axis=0)
X_max = X.max(axis=0)
denominator = (X_max - X_min)
denominator[denominator == 0] = eps
return (X - X_min) / denominator
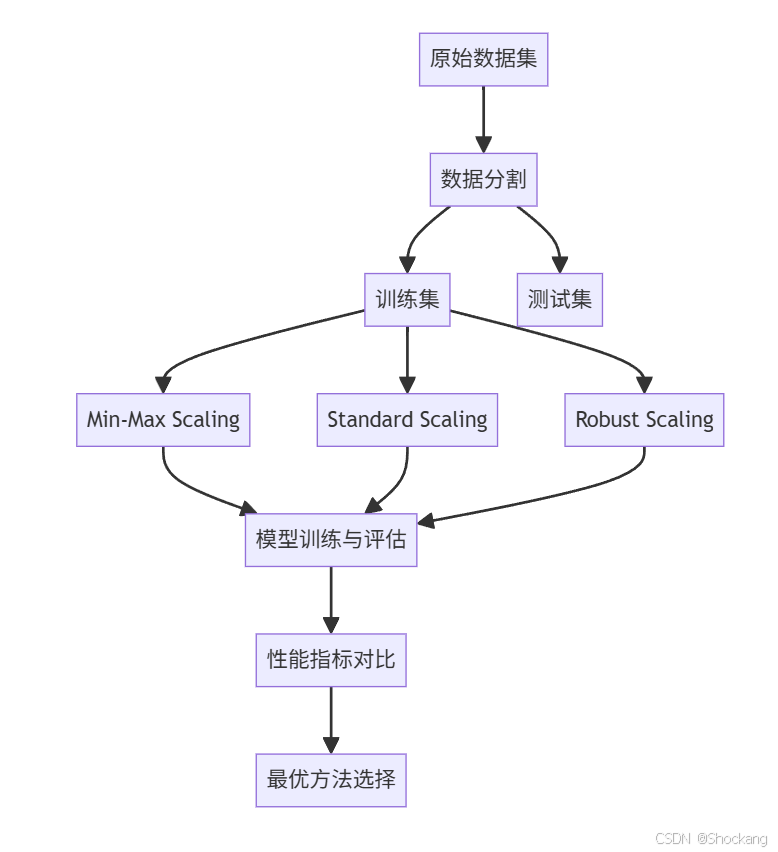
与其他归一化方法的对比 📊
6.1 对比表
| 方法 | 公式 | 特点 | 适用场景 |
|---|---|---|---|
| Min-Max Scaling | x − x m i n x m a x − x m i n \frac{x - x_{min}}{x_{max} - x_{min}} xmax−xminx−xmin | 固定范围,保持零值 | 神经网络、图像处理 |
| Standard Scaling | x − μ σ \frac{x - \mu}{\sigma} σx−μ | 均值为0,标准差为1 | 线性模型、聚类 |
| Robust Scaling | x − Q 1 Q 3 − Q 1 \frac{x - Q_1}{Q_3 - Q_1} Q3−Q1x−Q1 | 对异常值不敏感 | 存在异常值的数据 |
| MaxAbs Scaling | x x m a x \frac{x}{x_{max}} xmaxx | 保持稀疏性 | 稀疏数据 |
6.2 性能对比流程
实战案例分析 💼
7.1 房价预测案例
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import LinearRegression
# 加载数据
data = pd.DataFrame({
'size': [100, 120, 150, 180, 200, 220, 250],
'rooms': [2, 3, 3, 4, 4, 5, 5],
'price': [200000, 250000, 300000, 350000, 380000, 400000, 450000]
})
# 特征和目标变量分离
X = data[['size', 'rooms']]
y = data['price']
# 数据分割
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 特征缩放
scaler = MinMaxScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 模型训练
model = LinearRegression()
model.fit(X_train_scaled, y_train)
# 预测与评估
y_pred = model.predict(X_test_scaled)
mse = mean_squared_error(y_test, y_pred)
print(f"均方误差: {mse:.2f}")
进阶技巧与最佳实践 🚀
8.1 特征选择与缩放结合
from sklearn.feature_selection import SelectKBest
from sklearn.pipeline import Pipeline
# 创建处理流水线
pipeline = Pipeline([
('scaler', MinMaxScaler()),
('feature_selection', SelectKBest(k=5)),
('classifier', RandomForestClassifier())
])
# 使用网格搜索优化参数
param_grid = {
'feature_selection__k': [3, 4, 5],
'classifier__n_estimators': [100, 200]
}
grid_search = GridSearchCV(pipeline, param_grid, cv=5)
grid_search.fit(X_train, y_train)
8.2 动态范围调整
class AdaptiveMinMaxScaler:
def __init__(self, init_range=(0, 1), adaptation_rate=0.1):
self.current_range = init_range
self.adaptation_rate = adaptation_rate
def adapt_range(self, X):
"""动态调整缩放范围"""
X_scaled = self.transform(X)
if X_scaled.min() < 0 or X_scaled.max() > 1:
range_min = min(self.current_range[0], X_scaled.min())
range_max = max(self.current_range[1], X_scaled.max())
self.current_range = (
range_min * self.adaptation_rate + self.current_range[0] * (1-self.adaptation_rate),
range_max * self.adaptation_rate + self.current_range[1] * (1-self.adaptation_rate)
)
总结与展望 🎉
最小最大缩放是机器学习中不可或缺的数据预处理方法,它通过简单的线性变换实现特征的标准化,为模型训练提供了良好的数据基础。在实际应用中,需要根据数据特点和模型需求选择合适的缩放方法,并注意处理异常值和零方差特征等常见问题。
未来发展方向:
- 自适应缩放算法
- 分布式处理支持
- 在线学习场景的动态调整
- 与深度学习的深度集成
希望本文能够帮助读者更好地理解和应用最小最大缩放方法,在实际项目中取得更好的效果。