dfs复习
dfs复习:
--1:连通性的探究:
在可以通过dfs找到一个块的所有与之联通的块,

我们从s出发,通过dfs的方式找到出口t,一个最基础的dfs题目

--2:联通块数量问题
就是之前的池子计数问题,同样可以通过dfs解决

没有什么可以解释的,最简单的dfs

---3:回溯类型算法
比如N皇后问题,数独问题等等,需要我们维护一个状态,基于这个状态找到最后符合要求的末状态

一简单的回溯问题,每次我们尝试走的点都标记vis[i][j],搜索完成之后又将这个标记删除,去尝试另外的路径
最后的末尾状态就是我们搜索过的点的数量为n*m


每次dfs我们都考虑当前组中的元素放or不放
所以遍历每一个元素,如果没有放入之前的组,并且可以放入当前组,那么我们考虑放入,搜索完成后,在考虑不放入当前组。
需要注意的是,如果我们发现一次dfs遍历了所有的元素,发现没有任何一个可以放入到当前组,说明需要新开一组

剪枝
在更深入的聊dfs的进阶的一些应用时,插入一些剪枝的内容
我认为需要重点的去掌握以下的内容:
可行性剪枝:当然这个是我们搜索的时候都回去注意的,我们不回去搜索一个不满足要求的一个分支
重复性剪枝:我们不会去搜索一个已经搜索过的状态
最优化剪枝:如果我们记录的当前的搜索的值比我们目前的全局答案差,那我们没必要搜索到叶节点
优化搜索顺序,我们应该先去搜索叶节点更少的方向(也就是说我们要先去处理可能性数量更少的节点)
记忆化搜搜:我们可以利用记忆化搜索去减少重复的搜索

这是一个和上面一个题目差不多的题,在这里我们可以使用可行性剪枝进行优化和优化搜索顺序(先处理重的猫,再处理)


我们可以通过可行性剪枝(如果横,纵,方格不满足数独的条件,就不去搜索)
优化搜索顺序(先去处理比较满的行,列,方格)


更进一步的剪枝:
分别可行性剪枝:
如果当前的长度不是sum的约数,就不去枚举
如果长度为m,存在一个长度为n的木棍,无论如何也找不到可以和他一起组合m的木棍,那么该方案不可行
优化搜索顺序,先从大的木棍开始枚举,同时我们枚举的长度也从max{木棍长度开始}
避免重复的搜索:以组合数的方式枚举,(1,2)和(2,1)是同一个情况,没必要重复枚举


--4:迭代加深算法
本质就是在有限的深度下进行搜索,通过逐步增加搜索的深度限制,重复进行深度优先搜索,直到找到目标节点为止。每次搜索时,只探索深度不超过当前深度限制的节点。这样既避免了深度优先搜索可能陷入无限深度分支的问题,又不像广度优先搜索那样需要大量的内存来存储所有待扩展的节点。
不用担心这样会导致过于高的复杂度,其实认真思考下就会发现如果高度为dep,当我们下次搜第dep+1层的时候,叶子结点的数量的数量级和之前1~dep层加起来差不多,所以这样的优化有时候效果是很突出的

一个构造序列的题,可以通过可行性剪枝:优化搜索数量,因为第i个数一定要满足可以由前面的数表达出来

--5:meet in mid:
我们会对数据集砍半,然后通过一定的方式让第二次的搜索从第一次的搜索找匹配值,做到指数砍半的作用

先去搜索前面N/2个礼物,获得其对应的重量集合,然后对后面的N/2个进行搜索,根据获得的重量在前面的重量集中使用二分查找获得最优值

--6:IDA*算法
一个结合了迭代加深搜索和A*搜索算法的启发式算法
利用迭代加深控制深度,同时根据A*算法进行可行性剪纸

启发函数就是对当前状态能到目标态的最优估值,如果当前代价+最优的估值代价仍小于全局的最优解,则剪枝
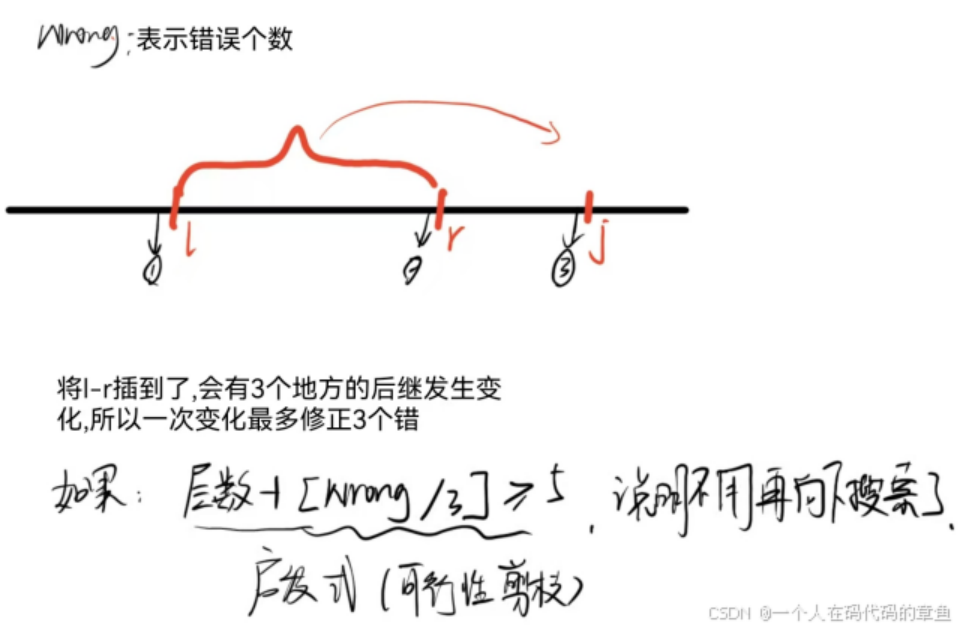

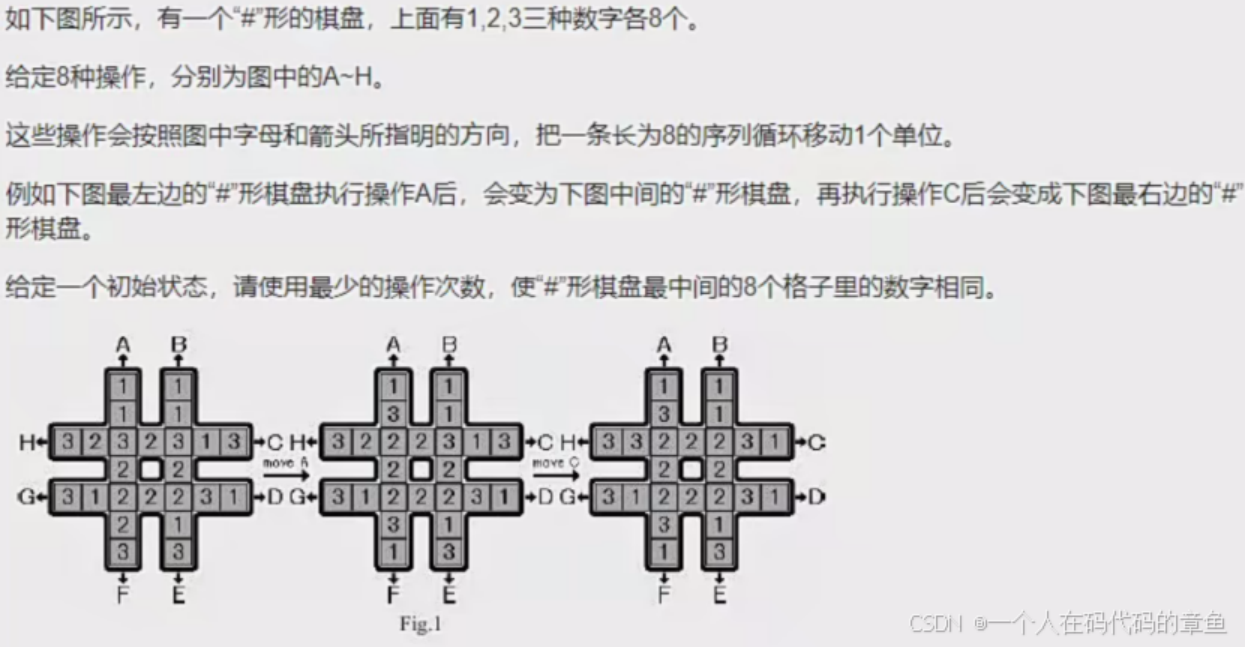
同样是迭代加深+A*,这里的每次的操作最多给我们带来1的改变,所以估价函数就是中间的方格中不符合的数目


--7:双向搜索
常用于从一个起始态到目标态的一个最优选择的算法,我们会从start和end两个方向向中间搜索

建图,然后从start开始搜索,同时也从end开始搜索,肯定要先处理小的队列,这样我们可以少搜索点,

--8:A*算法:
启发式算法,结合了深度优先搜索(DFS)的高效性和广度优先搜索(BFS)能找到最优解的特性,通过一个评估函数来引导搜索方向.
A*算法的核心是评估函数f(n)=g(n)+h(n) 。其中,g(n)表示从起始节点到当前节点n的实际代价 ,`可以是走过的路径长度、消耗的时间等;h(n) 是启发式函数,用于估计从当前节点n到目标节点的代价。一个好的启发式函数能让 A*算法更高效地找到最优解。
注意:
1估计到终点的距离 h,一定小于等于真实的距离才正确
2 必须有解才能使用A*
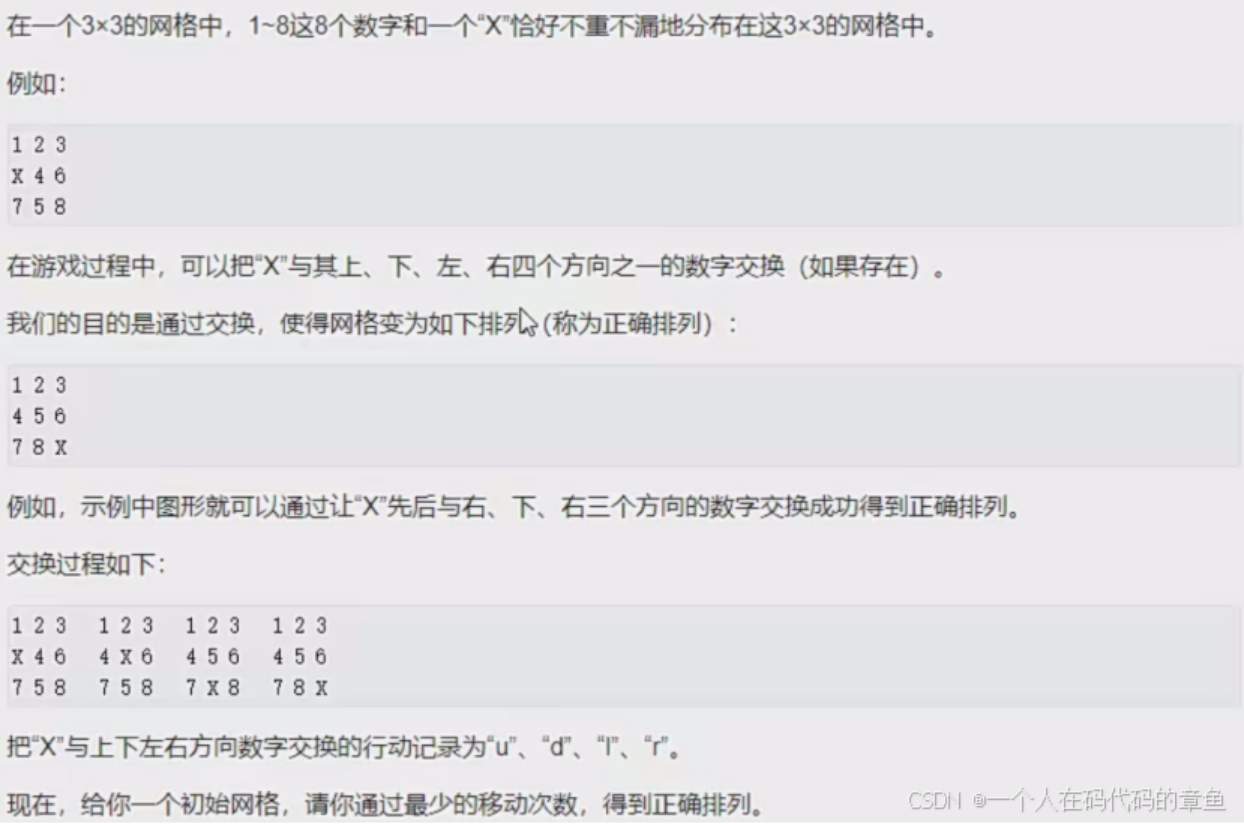
估价函数就是X到目标距离的曼哈顿距离,满足估价值小于等于真实值


这里的估价函数是反跑的dji的dis函数,当我们再次从start开始A*,第k次弹出end就是第k短路
