RAG 高效检索利器 打造企业 “规章制度智能体”(ollama + deepseek + langchain + MinerU)
前言
常见的开源知识库用过不少,如:langchain-chatchat、ragflow、dify等,发现还是有些回答不尽人意,搜索了相关技术栈,准备用 ollama + deepseek + langchain + MinerU 打造一个企业内部 ”规章制度智能体“。
一、准备环境
- ollama,用于在本地运行、部署和管理大型语言模型(LLMs)。
- deepseek 模型,本文用的 deepseek-r1:14b。
- langchain,大语言模型应用程序的开发框架,主要 python 实现。
- MinerU,大模型时代的文档提取/转换神器。
MinerU,支持PDF、Word、PPT等多种文档的智能解析并导出为 markdown、json 等格式,可用于机器学习、大模型语料生产、RAG等场景。
Markdown 在大语言模型中广泛应用,主要原因在于其简洁性、结构化能力以及与文本生成任务的天然适配性。因此解析结构化比较清晰的文档,如:合同、规章制度等,使用 markdown 格式更容易让大语言模型理解。
官网:https://mineru.net/
Github:https://github.com/opendatalab/MinerU
安装文档:https://github.com/opendatalab/MinerU/blob/master/README_zh-CN.md
二、开发思路
- 首先使用 MinerU 将 pdf 解析为 markdown 格式,下载客户端或者部署源码解析。
- 然后对其内容进行微调,删除无关内容,并调整标题的层级关系,有表格的尽量也转一下,手动调整成序列。
- 使用 langchain 的 UnstructuredMarkdownLoader 模块加载数据。
- 再用向量库和嵌入模型进行检索,返回用户问题。
三、代码解读
- 加载文档
# 加载文档
loader = UnstructuredMarkdownLoader("knowledge_base/差旅费管理办法.md", mode="elements")
docs = loader.load()
- 分割文档
def create_text_splitter():
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
return MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
# 合并标题内容
merged_text = "\n".join([doc.page_content for doc in docs])
# 分割文档
markdown_splitter = create_text_splitter()
md_header_splits = markdown_splitter.split_text(merged_text)
- 初始化模型和系统提示词
def get_chat_llm(model="deepseek-r1:14b") -> OllamaLLM:
return OllamaLLM(model=model, temperature=0, verbose=False)
def get_answer_prompt() -> ChatPromptTemplate:
system_prompt = """
【指令】
你是一个差旅助手,根据《差旅费管理办法》,简洁和专业的来回答问题。如果无法从中得到答案,请说 “根据《差旅费管理办法》无法回答该问题”,不允许在答案中添加编造成分,答案请使用中文。
【《差旅费管理办法》】
{context}
"""
return ChatPromptTemplate.from_messages([
("system", system_prompt),
("human", "{input}")
])
- 语义检索返回TOP20
# 语义检索返回TOP20
def get_retriever(documents: List[Document]):
embeddings = OllamaEmbeddings(model="quentinz/bge-large-zh-v1.5", base_url="http://127.0.0.1:11434")
vector_store = FAISS.from_documents(documents, embeddings)
return vector_store.as_retriever(search_kwargs={"k": 20})
- 主流程
# 主流程
def start_chat_travel_assistant(query, model):
# 加载文档
loader = UnstructuredMarkdownLoader("knowledge_base/差旅费管理办法.md", mode="elements")
docs = loader.load()
# 合并内容
merged_text = "\n".join([doc.page_content for doc in docs])
# 分割文档
markdown_splitter = create_text_splitter()
md_header_splits = markdown_splitter.split_text(merged_text)
# 初始化llm
llm = get_chat_llm(model)
prompt = get_answer_prompt()
# 创建检索链
retriever = get_retriever(md_header_splits)
# 创建文档链
document_chain = create_stuff_documents_chain(llm, prompt)
retrieval_chain = create_retrieval_chain(retriever, document_chain)
# 对话并返回
return retrieval_chain.stream({"input": query})
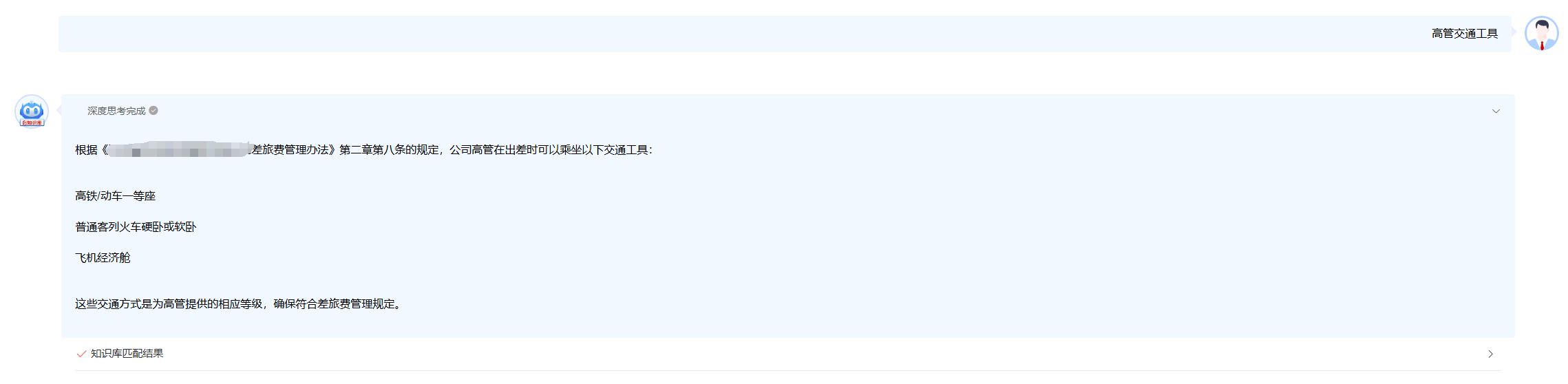
四、测试效果
我已经集成到公司业务系统,效果如下:
五、完整代码
import os
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains.retrieval import create_retrieval_chain
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_community.vectorstores import FAISS
from langchain_core.documents import Document
from langchain_core.prompts import ChatPromptTemplate
from langchain_ollama import OllamaEmbeddings, OllamaLLM
from typing import List
from langchain_text_splitters import MarkdownHeaderTextSplitter
# 设置Ollama的主机和端口
os.environ["OLLAMA_HOST"] = "127.0.0.1"
os.environ["OLLAMA_PORT"] = "11434"
def get_chat_llm(model="deepseek-r1:14b") -> OllamaLLM:
return OllamaLLM(model=model, temperature=0, verbose=False)
def get_answer_prompt() -> ChatPromptTemplate:
system_prompt = """
【指令】
你是一个差旅助手,根据《差旅费管理办法》,简洁和专业的来回答问题。如果无法从中得到答案,请说 “根据《差旅费管理办法》无法回答该问题”,不允许在答案中添加编造成分,答案请使用中文。
【《差旅费管理办法》】
{context}
"""
return ChatPromptTemplate.from_messages([
("system", system_prompt),
("human", "{input}")
])
def create_text_splitter():
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
return MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
# 语义检索返回TOP20
def get_retriever(documents: List[Document]):
embeddings = OllamaEmbeddings(model="quentinz/bge-large-zh-v1.5", base_url="http://127.0.0.1:11434")
vector_store = FAISS.from_documents(documents, embeddings)
return vector_store.as_retriever(search_kwargs={"k": 20})
# 主流程
def start_chat_travel_assistant(query, model):
# 加载文档
loader = UnstructuredMarkdownLoader("knowledge_base/差旅费管理办法.md", mode="elements")
docs = loader.load()
# 合并内容
merged_text = "\n".join([doc.page_content for doc in docs])
# 分割文档
markdown_splitter = create_text_splitter()
md_header_splits = markdown_splitter.split_text(merged_text)
# 初始化llm
llm = get_chat_llm(model)
prompt = get_answer_prompt()
# 创建检索链
retriever = get_retriever(md_header_splits)
# 创建文档链
document_chain = create_stuff_documents_chain(llm, prompt)
retrieval_chain = create_retrieval_chain(retriever, document_chain)
# 对话并返回
return retrieval_chain.stream({"input": query})
六、待完善内容
这里还只是一个基础功能,后续还可以从以下方面完善:
- 集成 MinerU 自动转换成 markdown 格式。
- 并提供可视化界面方便修改转换后的内容。
- 调整各个环节参数,找到最佳值。
- 使用 rerank 重排序,增强召回率。
- 切换大语言模型和嵌入模型。