单页网站设计欣赏网络营销类型有哪些
服务器日志采集是现代IT运维、监控和安全分析的重要环节,市面上也有很多非常成熟的工具和框架,类似Fluentd,Logstash,filebeat等等。当然,日志采集只是第一步,后续还需要对日志进行存储和分析,比较出名的ELK(Elasticsearch + Logstash + Kibana)就是非常成熟的全套方案,适合大规模日志搜索和分析。
Filebeat
官网地址:https://www.elastic.co/cn/beats/filebeat
介绍
- Filebeat 是 Elastic 公司开发的一款轻量级日志数据收集器,属于 Beats 家族。它的核心功能是从各种来源采集日志或文件数据,并将这些数据高效地传输到指定的存储或分析系统(如 Elasticsearch、Logstash、Kafka 等)
Beats家族有不少成员,涉及很多方面的数据采集,比如Packetbeat收集网络流量数据,比如Metricbeat收集系统的CPU和内存使用数据……
Filebeat的重要特性:- 轻量高效:用 Go 编写,无 JVM 开销(相比 Logstash),资源占用低
- 背压感知:如果输出目标(如 Elasticsearch)过载,Filebeat 会自动降低发送速率
- 模块化:通过模块(如
nginx、mysql)快速集成常见服务,无需手动编写解析规则 - 至少一次交付:确保数据至少发送一次(将每个事件的传递状态存储在注册表文件)
官网上写了,Filebeat 的至少一次交付存在限制,涉及日志轮换和旧文件的删除,如果日志文件写入磁盘并轮换的速度快于 Filebeat 处理的速度,或者在输出不可用时删除文件,则可能会丢失数据。在 Linux 上,Filebeat 还可能由于 inode 重用而跳过行
两个核心组件
官网配图:
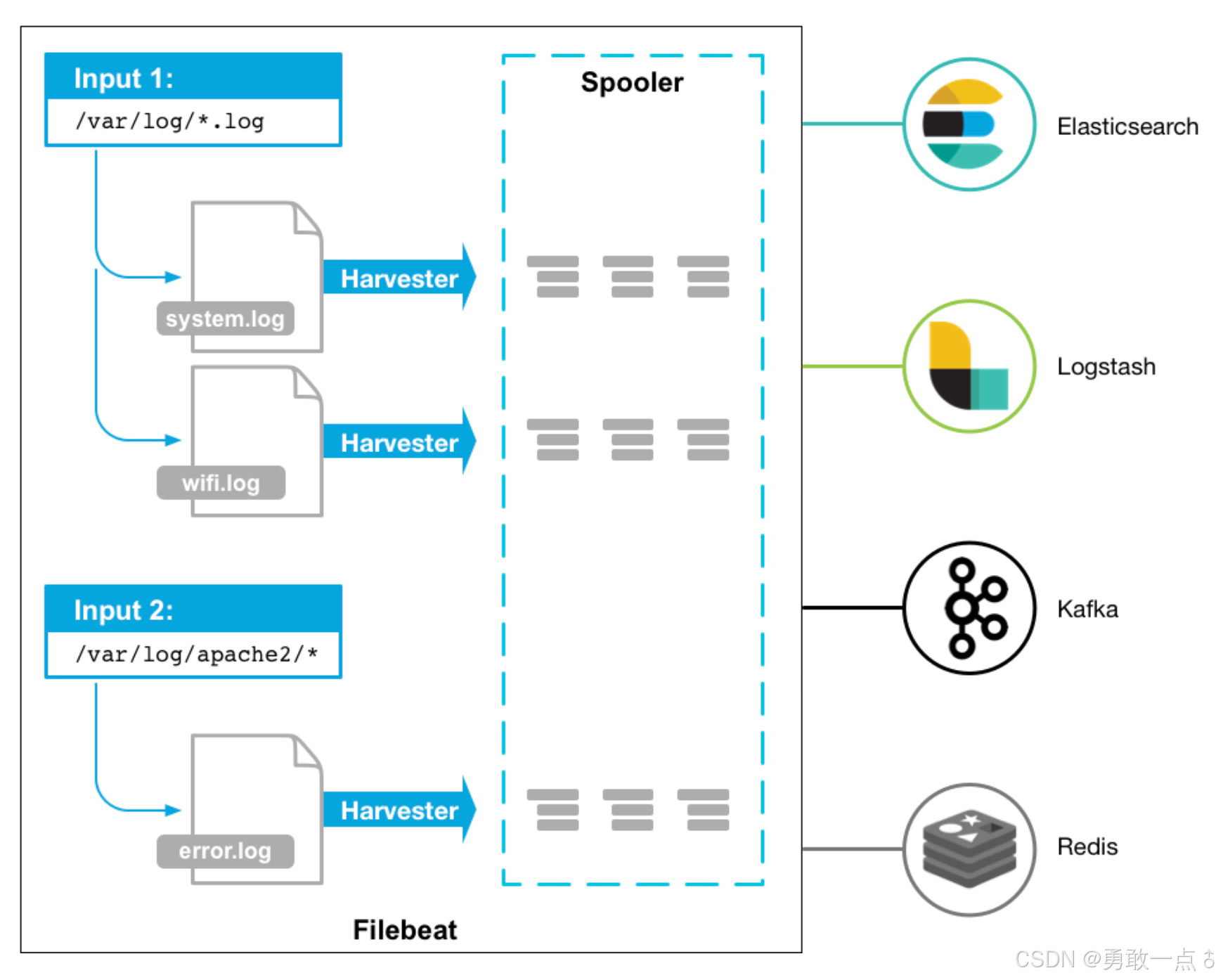
在 Filebeat 中, 有两个核心组件:Inputs(输入) 和 Harvesters(收集器),它们协同工作来完成日志数据的采集
-
Inputs是 Filebeat 中用于 定义和配置数据来源 的组件,负责指定从哪里采集数据 -
Harvesters是 Filebeat 的 实际数据采集工作单元,主要的工作就是读取文件 -
一个
Input可以对应多个Harvesters -
一个文件只会对应一个
Harvesters,如果日志被轮转(如nginx.log→nginx.log.1),Harvester会关闭旧文件,并启动新的Harvester监控新文件 -
每个
Harvester独立运行,Filebeat 可以限制 最大 Harvester 数量(防止打开过多文件),如果不设置,则会尽可能多的的启用
ulimit是Linux系统中用于控制用户进程资源限制的一个机制,它定义了单个用户可以使用的系统资源上限,用ulimit -n可以看到当前用户打开文件数的限制,一般都是65535
步骤原理
+-------------------+ +-------------------+ +-------------------+
| | | | | |
| 日志文件 | → → → | Filebeat | → → → | 输出目标 |
| (如Nginx/App日志) | | | | (Elasticsearch/ |
| | | | | Logstash/Kafka) |
+-------------------+ +---------+---------+ +-------------------+^|+-------+-------+| |+-------v-------+ +-----v-----+| 输入阶段 | | 处理阶段 || (Input) | | (Process) || - 监控文件变化 | | - 字段提取 || - 记录偏移量 | | - 多行合并 |+-------+-------+ +-----+-----+^ || |+-------v---------------+-------+| |+-------v-------+ +-------v-------+| 内存队列 | | 磁盘队列 || (Spooling) | | (可选缓冲) || - 批量聚合事件 | | - 防崩溃持久化 |+-------+-------+ +---------------+|+-------v-------+| 输出阶段 || (Output) || - 负载均衡 || - 加密/重试 |+---------------+
- 输入阶段(Input)
- 文件发现:根据配置的路径(如
/var/log/*.log)扫描文件,记录已发现的文件状态 - 监控日志文件:持续跟踪配置的日志文件(如
/var/log/nginx.log),通过注册表文件(registry)记录每个文件的读取位置(偏移量),之后只读取文件新增的内容(通过文件大小变化) - 处理轮转文件:自动识别日志轮转(如从
nginx.log切换到nginx.log.1),通过 inode 和文件名识别轮转后的新文件
- 文件发现:根据配置的路径(如
- 处理阶段(Process)
- 多行日志合并:如程序报错输出的堆栈信息,通过正则表达式将多行合并为单个事件
- 内置模块:预配置了常见服务(如 Nginx、MySQL、Docker)的解析规则,也可以自动提取字段(如 HTTP 状态码、数据库查询时间)。
- 支持自定义处理:
- 添加字段(可以自己增加一些)。
- 删除敏感字段、过滤无关日志(通过条件判断)。
- 转换数据格式(如 JSON 编码)。
- 队列缓冲(Spooling)
- 内存队列:Filebeat 不会逐条发送日志,而是将数据缓存在内存中(称为
spool),默认固定时间秒或达到 固定事件数时触发一次发送 - 磁盘队列(可选):启用后,数据会持久化到磁盘,防止进程崩溃时丢失。
- 内存队列:Filebeat 不会逐条发送日志,而是将数据缓存在内存中(称为
- 输出阶段(Output)
- 负载均衡:轮询多个目标主机(如 Elasticsearch 集群节点)。
- 重试机制:网络故障时自动重试,确保数据可靠传输。
- 压缩与加密:支持 TLS 加密和 Gzip 压缩。
安装
参考官网:https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-installation-configuration.html
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.17.4-linux-x86_64.tar.gztar xzvf filebeat-8.17.4-linux-x86_64.tar.gz
解压后文件目录是:
.
├── fields.yml
├── filebeat
├── filebeat.reference.yml
├── filebeat.yml
├── kibana
├── LICENSE.txt
├── module
├── modules.d
├── NOTICE.txt
└── README.md
Demo1:开始采集
- 因为是demo,出于方便性,这里直接输出到本地文档,后面的demo都是输出本地文档
- 此处以及后面的demo都包含了笔者自己的想法,一定一定一定要辩证看待
- 新建一个
filebeat-demo1.yml,用下面的配置(原本的配置中有些处理器规则和ES配置,暂时用不到)
filebeat.inputs:
# Filebeat的一种输入类型,适合监控文件变化
- type: filestream
# 唯一标识符,用于区分多个输入源(在多个 filestream 配置时必需)id: my-filestream-id
# 启用此输入配置(如果为 false 则不会采集日志)enabled: true
# 指定要监控的日志文件路径paths:- /home/xxx/dev_logs/adspyhub_api/*.log# 输出配置
output.file:path: "/home/xxx/dev_logs/filebeat" filename: "demo1.log"
# 定义日志格式,string: '%{[message]}' 表示仅输出原始日志内容(不添加元数据)codec.format: string: '%{[message]}'
-
./filebeat -e -c ./filebeat-demo1.yml: 执行,如果指定目录没有看到输出文件,可以多等会,或者多打些日志触发输出! -
这里采集的是全部数据,没做任何处理,等于将log原封不动的存到
demo1.log中 -
我们定义的
filename是demo1.log,但实际上看到的输出文件是demo1.log-20250331.ndjson`- Filebeat 的
output.file默认会按 时间或大小 自动轮转日志文件,生成带时间戳的新文件。 .ndjson后缀表示文件内容是 Newline-Delimited JSON(每行一个记录),这是 Filebeat 的默认输出格式。
- Filebeat 的
-
上面命令执行后,控制台能看到一大串输出,是 Filebeat 的 监控日志,记录了 Filebeat 自身的运行状态和性能指标(如果想关闭的话,在配置中设置
monitoring.enabled: false),下面我截取了一部分看看:log.logger: "monitoring":表示这是监控模块的日志。message: "Non-zero metrics in the last 30s":说明这是过去 30 秒的非零指标汇总。(默认每 30 秒输出一次)- CPU 使用率 =
total.time.ms / (30s * 1000) * 100%=20ms / 30000ms * 100% ≈ 0.07%:(极低) - 内存占用 ≈
rss / 1024 / 1024 ≈ 64.4 MB filebeat.events.added: 5: 过去 30 秒新增 5 个日志事件filebeat.events.done: 5:已处理完成 5 个事件(无积压)filebeat.harvester.running: 2:当前有 2 个 Harvester 在运行(每个文件一个)libbeat.output.events.acked: 5:成功发送到输出目标(这里是指定文件)的事件数。(无事件积压,吞吐正常)libbeat.output.write.bytes: 1689:输出的总字节数。libbeat.pipeline.queue.max_events: 3200:内存队列最大容量(事件数)。system.load:这里面记录了系统本身的负载,主机负载较高(这里计算比较复杂,我在附录中介绍),但未影响 Filebeatbeat.info.uptime.ms: 330086:Filebeat 已运行 330 秒(约 5.5 分钟)。registrar.states.current: 0:当前注册的日志文件状态数(无持久化)。
{"log.level": "info","@timestamp": "2025-03-31T16:22:35.304+0800","log.logger": "monitoring","log.origin": {"function": "github.com/elastic/beats/v7/libbeat/monitoring/report/log.(*reporter).logSnapshot","file.name": "log/log.go","file.line": 192},"message": "Non-zero metrics in the last 30s","service.name": "filebeat","monitoring": {"metrics": {"beat": {"cgroup": {"cpuacct": {"total": {"ns": 21628431718}},"memory": {"mem": {"usage": {"bytes": 11737444352}}}},"cpu": {"system": {"ticks": 80,"time": {"ms": 10}},"total": {"ticks": 230,"time": {"ms": 20},"value": 230},"user": {"ticks": 150,"time": {"ms": 10}}},"handles": {"limit": {"hard": 65535,"soft": 65535},"open": 12},"info": {"ephemeral_id": "153b748f-4b14-4e24-8754-93da1b4c2185","uptime": {"ms": 330086},"version": "8.17.4"},"memstats": {"gc_next": 35294704,"memory_alloc": 17763872,"memory_total": 39110464,"rss": 67510272},"runtime": {"goroutines": 34}},"filebeat": {"events": {"active": 0,"added": 5,"done": 5},"harvester": {"closed": 2,"open_files": 2,"running": 2,"started": 2}},"libbeat": {"config": {"module": {"running": 0}},"output": {"events": {"acked": 5,"active": 0,"batches": 1,"total": 5},"write": {"bytes": 1689,"latency": {"histogram": {"count": 5,"max": 0,"mean": 0,"median": 0,"min": 0,"p75": 0,"p95": 0,"p99": 0,"p999": 0,"stddev": 0}}}},"pipeline": {"clients": 2,"events": {"active": 0,"published": 5,"total": 5},"queue": {"acked": 5,"added": {"events": 5},"consumed": {"events": 5},"filled": {"bytes": 0,"events": 0,"pct": 0},"max_bytes": 0,"max_events": 3200,"removed": {"events": 5}}}},"registrar": {"states": {"current": 0}},"system": {"load": {"1": 1.87,"15": 3.75,"5": 2.69,"norm": {"1": 0.935,"15": 1.875,"5": 1.345}}}},"ecs.version": "1.6.0"} }
Demo2:日志改名
之前有想过问题:日志被改名了,Harvester会怎样,还能读取日志吗?
官网上的原话是:Because files can be renamed or moved, the filename and path are not enough to identify a file. For each file, Filebeat stores unique identifiers to detect whether a file was harvested previously.
我在AI和一些博客上面看的的说法是,日志被改名了,Harvester仍然运行,还能继续读取日志,原因是filebeat的注册表通过**inode 和 device_id**:唯一标识文件,不管怎么样,实践下
- 新建一个
filebeat-demo2.yml,用下面的配置
filebeat.inputs:
- type: filestreamid: my-filestream-idenabled: truepaths:- /home/xxx/dev_logs/demo2/test.logfilebeat.config.modules:path: ${path.config}/modules.d/*.ymlreload.enabled: falseoutput.file:path: "/home/xxx/dev_logs/filebeat" filename: "demo2.log" codec.format: string: '%{[message]}'
test.log里面随便初始化点内容,启动:./filebeat -e -c ./filebeat-demo2.yml:- 需要提前记录下iNode:
ls -i test.log,这里输出了13012064 test.log - 用mv命令修改
test.log的名字为test1.log,并随便补充内容(echo "新增的内容" >> test.log,不要用vim,vim保存会删除旧文件,创建新文件),再次观察iNode,仍然是13012064 test1.log - 结果发现日志并没有采集!!!
个人推测:
-
可能是版本原因,老版本是这样的,有条件可以再验证
-
可能是我指定了一个明确的路径,后面可以结合轮转再看看
-
Filebeat 的
filestream输入类型通过 多因素组合 来唯一标识文件,文件路径也是很重要的影响因素,依据如下- 我们打开
data/registry/filebeat/log.json,一般是这个路径,是 Filebeat注册表 的 日志,随便找一行看看,发现source中明显记录了路径
{"k": "filestream::my-filestream-id::native::13012064-64785","v": {"updated": [2062507668637,1743421740],"cursor": {"offset": 37},"meta": {"source": "/home/xxx/dev_logs/demo2/test.log","identifier_name": "native"},"ttl": 0} } - 我们打开
结论:日志改名会影响采集
Demo3: 日志轮转
- filebeat.yml文件配置为:
filebeat.inputs:
- type: filestreamenabled: truepaths:- /home/xxx/dev_logs/demo3/*.log* # 监控所有轮转文件close.on_state_change.inactive: 3m # 1分钟不活跃后关闭文件收集器ignore_older: 2h # 忽略超过2小时的旧文件output.file:path: "/home/xxx/dev_logs/filebeat" filename: "demo3.log" rotate_every_kb: 1024 # 输出文件达到1MB后轮转codec.format: string: '%{[message]}'- python脚本为:
import logging
import time
from logging.handlers import TimedRotatingFileHandler# 配置日志轮转(每分钟)
logger = logging.getLogger("demo_logger")
logger.setLevel(logging.INFO)handler = TimedRotatingFileHandler(filename=f"app.log",when="M", # 每分钟轮转interval=1, # 间隔1分钟backupCount=5, # 保留5个历史文件
)
handler.suffix = "%Y%m%d_%H%M.log" # 轮转文件名格式(如 app.log_20250331_1422.log)
logger.addHandler(handler)# 模拟持续写入日志
count = 0
while True:logger.info(f"This is a test log line {count} (INFO level).")if count % 3 == 0:logger.error(f"Error occurred: something went wrong {count}!")count += 1time.sleep(10) # 每10秒写一条日志(方便观察轮转效果)
-
多等一会,发现生成了多个日志
. ├── app.log ├── app.log.20250331_2037.log ├── app.log.20250331_2038.log ├── app.log.20250331_2039.log ├── app.log.20250331_2040.log ├── app.log.20250331_2041.log ├── app.log.20250331_2042.log └── test.py -
通过监控日志观察harvester,
running数量依次为1,2,3,4,4,而closed的数量依次为0,0,0,0,1 -
日志中有一条记录,如下,大致意思就是
app.log这个文件的harvester关闭了
{"log.level": "info","@timestamp": "2025-03-31T20:42:52.063+0800","log.logger": "input.filestream","log.origin": {"function": "github.com/elastic/beats/v7/filebeat/input/filestream.(*filestream).readFromSource","file.name": "filestream/input.go","file.line": 367},"message": "Reader was closed. Closing. Path='/home/xxx/dev_logs/demo3/app.log'","service.name": "filebeat","id": "198A799FBD3BD5DB","source_file": "filestream::.global::native::13150956-64785","path": "/home/xxx/dev_logs/demo3/app.log","state-id": "native::13150956-64785","ecs.version": "1.6.0"
}
关键点:close.on_state_change.inactive 确保及时释放已轮转文件的句柄。
Processer: 处理器
这里引入了一个新的概念,Processor(处理器), 是用于在日志数据发送到输出目标(如 Elasticsearch、文件等)之前,对数据进行实时转换、过滤或增强的组件。它们构成了 Filebeat 数据处理管道的核心部分,允许用户在数据采集阶段实现灵活的定制化处理。
- 每条日志会被封装为一个 事件(Event) 对象,包含:
- 原始消息(
message) - 元数据(如
@timestamp、host.name) - 自定义字段(通过处理器添加或修改)
- 原始消息(
- Processor 通过修改事件来实现数据处理。
- Processor按配置的 声明顺序 依次执行,每个处理器接收上一个处理器的输出作为输入
官方文档中写的processer非常多,大概有三四十个,覆盖了多种功能
- 字段操作类
add_fields:添加静态字段(如标记数据来源)drop_fields:删除指定字段include_fields:仅保留指定字段(白名单)
- 数据解析类
dissect:通过分隔符提取字段(高性能,适合简单结构化日志)grok:通过正则表达式提取复杂字段(灵活但耗资源)
- 条件判断类
if-then-else:根据条件执行不同处理器
Demo4: 使用dissect解析格式化日志
dissect处理器主要用于处理格式化的日志,属于非常常用的处理器,他有如下几种配置设置
processors:- dissect:tokenizer: %{key1}-%{key2}-%{key3|convert_datatype}field: "message"target_prefix: "parsed"ignore_failure: falseoverwrite_keys: true
tokenizer(必填):定义字段的格式,示例中,日志的不同字段用-隔开,可以使用其|作为分隔符将值转换为指定类型field:要标记化的事件字段。默认值为message,就是原始字段target_prefix:为解析后的字段添加统一前缀,避免命名冲突。ignore_failure:用于控制当标记器无法匹配消息字段时处理器是否返回错误。如果设置为 true,处理器将默默恢复原始事件,从而允许执行后续处理器(如果有)。如果设置为 false(默认),处理器将记录错误,从而阻止执行其他处理器。overwrite_keys:是否覆盖目标字段中已存在的值trim_values:启用对提取的值的修剪。有助于删除前导和/或尾随空格none:(默认)不进行修剪。left:值在左侧被修剪(前导)。right:值在右侧(尾随)被修剪。all:修剪前导和尾随的值。
trim_chars:启用修剪功能时,要从值中修剪的字符集。默认为修剪空格字符 (" ")。要修剪多个字符,只需将其设置为包含要修剪的所有字符的字符串。例如,trim_chars: " \t"将修剪空格和/或制表符。
- 现有日志格式如下,假设需求是,
- INFO日志舍弃
- 其余级别的日志,保留1,2,3,6,7列的信息
- 额外增加my_log_processor的前缀,标记下这是自己的项目
2025-03-31 08:22:01.048 | 16641 | ERROR | other_utils.get_country_from_ip:78 | df139a576db44845bd6b7efaeadcc644 | post | /napi/v1/advanced-analysis | division by zero | -
2025-03-31 08:22:01.056 | 16641 | INFO | user_middleware.dispatch:153 | df139a576db44845bd6b7efaeadcc644 | get | /napi/v1/list | division by zero | -
2025-03-31 08:22:01.057 | 16641 | WARNING | l:wqog_middleware.dispatch:123 | df139a576db44845bd6b7efaeadcc644 | post | /napi/v1/detail | division by zero | -
- filebeat.yml文件配置为:
filebeat.inputs:
- type: filestreamenabled: truepaths:- /home/xxx/dev_logs/demo4/*.logprocessors:# 1. 先添加全局字段(放在最前)- add_fields:target: "" # 添加到事件根级别fields:name: "my_log_processor"# 2. 解析原始日志- dissect:tokenizer: "%{timestamp} | %{thread_id} | %{log_level} | %{module} | %{trace_id} | %{http.method} | %{http.path} | %{error_msg} | %{status}"field: "message"target_prefix: "parsed"# 3. 最后过滤日志(避免影响字段添加)- drop_event:when:equals:parsed.log_level: "INFO"output.file:path: "/home/xxx/dev_logs/filebeat"filename: "demo4.log"codec.format:string: "%{[name]} | %{[parsed.timestamp]} | %{[parsed.thread_id]} | %{[parsed.log_level]} | %{[parsed.http.method]} | %{[parsed.http.path]}"
- 结果:
my_log_processor | 2025-03-31 08:22:01.048 | 16641 | ERROR | post | /napi/v1/advanced-analysis
my_log_processor | 2025-03-31 08:22:01.057 | 16641 | WARNING | post | /napi/v1/detail-
fliebeat处理的行数据实际上会被转换成json格式:
{"@timestamp": "2025-03-31T08:22:01.048Z", // Filebeat 自动添加的时间戳"name": "my_log_processor", // 通过 add_fields 添加的固定字段"message": "原始日志内容...", // 原始日志(未修改)"parsed": { // dissect 解析后的字段"timestamp": "2025-03-31 08:22:01.048","thread_id": "16641","log_level": "ERROR","module": "other_utils.get_country_from_ip:78","trace_id": "df139a576db44845bd6b7efaeadcc644","http.method": "post","http.path": "/napi/v1/advanced-analysis","error_msg": "division by zero","status": "-"} }
浅聊输出
- 日志采集处理算是很专业的领域了,这里只说了采集侧的一点点,后面需要做的还有很多,存储,分析,检索,可视化等等
- Filebeat 支持的输出目标如下,市面上有很多日志存储分析工具,很多工具Filebeat不支持直接输出的,需要用Logstash做转发
| 输出类型 | 适用场景 |
|---|---|
| Elasticsearch | 需要完整 ELK 栈的场景 |
| Logstash | 需要预处理日志的场景 |
| Kafka | 高吞吐量/缓冲场景 |
| Redis | 临时缓存/队列场景 |
| 文件 | 本地调试或备份 |
| console | 本地调试 |
- 最推荐的还是接入ES,FileBeat自带的模块很多,官网上能看到好几十种(类似Nginx,MySQL之类的),和ES的契合度非常高
- ELK是一套很强大的日志采集架构,但资源消耗大,维护成本高,类似promtail+loki+Grafana也是一套很不错的轻量级框架
- 很多时候,filebeat只会作为采集工具,而不是去处理日志内容,想要处理日志内容,更多会用到logstash,功能更多也更全面
- Logstash 是一个开源的服务器端数据处理管道,它可以用于采集,但更多用于转换、过滤、传输日志及其他事件数据。如果日志量很大,PB级别的日志量, 也可以用它来增加层级,接入Kafka的中间件
PS:附录
CPU负载计算:
-
系统负载指标(
load.1、load.5、load.15)是衡量 CPU 和 I/O 压力的关键指标,但判断是否“健康”需要结合 CPU 核心数 和 工作负载类型 综合分析。以下是具体解读方法:
1. 负载指标的含义
指标 说明 load.1过去 1 分钟 的平均负载(最敏感,反映短期压力)。 load.5过去 5 分钟 的平均负载(平衡敏感性和稳定性)。 load.15过去 15 分钟 的平均负载(最稳定,反映长期趋势)。 关键规则:
- 负载值表示 系统中正在使用或等待 CPU/I/O 资源的任务数(包括运行中的进程 + 不可中断的 I/O 等待进程)。
- 负载值 不是百分比,而是绝对数值,需与 CPU 核心数对比。
2. 如何判断是否健康?
步骤 1:获取 CPU 核心数
nproc # 查看逻辑CPU核心数(例如输出为2)步骤 2:计算归一化负载(Norm Load)
- 公式:
归一化负载 = 负载值 / CPU核心数- 示例:若
load.1 = 1.87且 CPU 核心数为 2,则norm_load = 1.87 / 2 = 0.935。
- 示例:若
步骤 3:健康阈值参考
归一化负载范围 健康状态 处理建议 < 0.7 健康,系统空闲或轻度使用。 无需干预。 0.7 ~ 1.0 轻度负载,资源利用率较高,但未过载。 监控趋势,检查是否有异常进程。 > 1.0 过载:任务排队等待资源(CPU 或 I/O 瓶颈)。 需要立即排查高负载原因 持续 > 2.0 严重过载,系统响应可能变慢,甚至卡死。 紧急优化或扩容。 注:
- 如果负载高但 CPU 使用率低(如
top显示%CPU < 50%),可能是 I/O 瓶颈(如磁盘慢、网络阻塞)。 - 数据库、虚拟机等 I/O 密集型服务对负载更敏感。