广州市律师网站建设公司江门seo网站推广
目录
1.序列化和反序列化
(1)为什么需要序列化
(2)序列化方案
①json
②json序列化代码模板
③json反序列化代码模板
④将自定义方案和json结合
2.TCP协议(传输控制协议)
(1)为什么支持全双工
(2)管理报文
编辑
(3)面向字节流
3.会话和守护进程
(1)前台进程和后台进程
(2)会话
(3)创建新会话和守护进程
①创建新会话
②Daemon实现
4.常见指令
(1)netstat
(2)telnet
(3)ulimit
1.序列化和反序列化
(1)为什么需要序列化
应用层:用于解决实际问题,满足日常需求的网络程序都在应用层。
在应用层,我们一般都以面向对象的方式管理数据(管理消息需要有名字、时间等属性),即用类管理数据。协议就是双方约定好的结构化的数据和方法(协议定制就是定制双方都能认识的满足通信和业务需求的结构化数据(class、struct))。我们要传输一些结构化的数据怎么办?
一种方法是在recv里面直接传结构体指针,直接将结构体转为二进制,接收端直接接收并按照相应结构体的规则访问。OS的底层就是这样的,因为一台电脑上的OS设计有严格化规定,是统一的。
但在不同主机的应用层看来,大小端、对齐规则、语言版本、32位和64位、结构体里面有指针等都会导致通信出现问题,因此要考虑兼容性问题,在网络中,我们需要将这些数据转换成字符串形式传输,这就是序列化的由来。
序列化,即将信息多变一,以统一的规则发送,反序列化就是一变多,解析字符串为结构化数据。
(2)序列化方案
①json
json是现成的序列化方案(还有xml、protobuf等),我们可以直接用,会用即可。
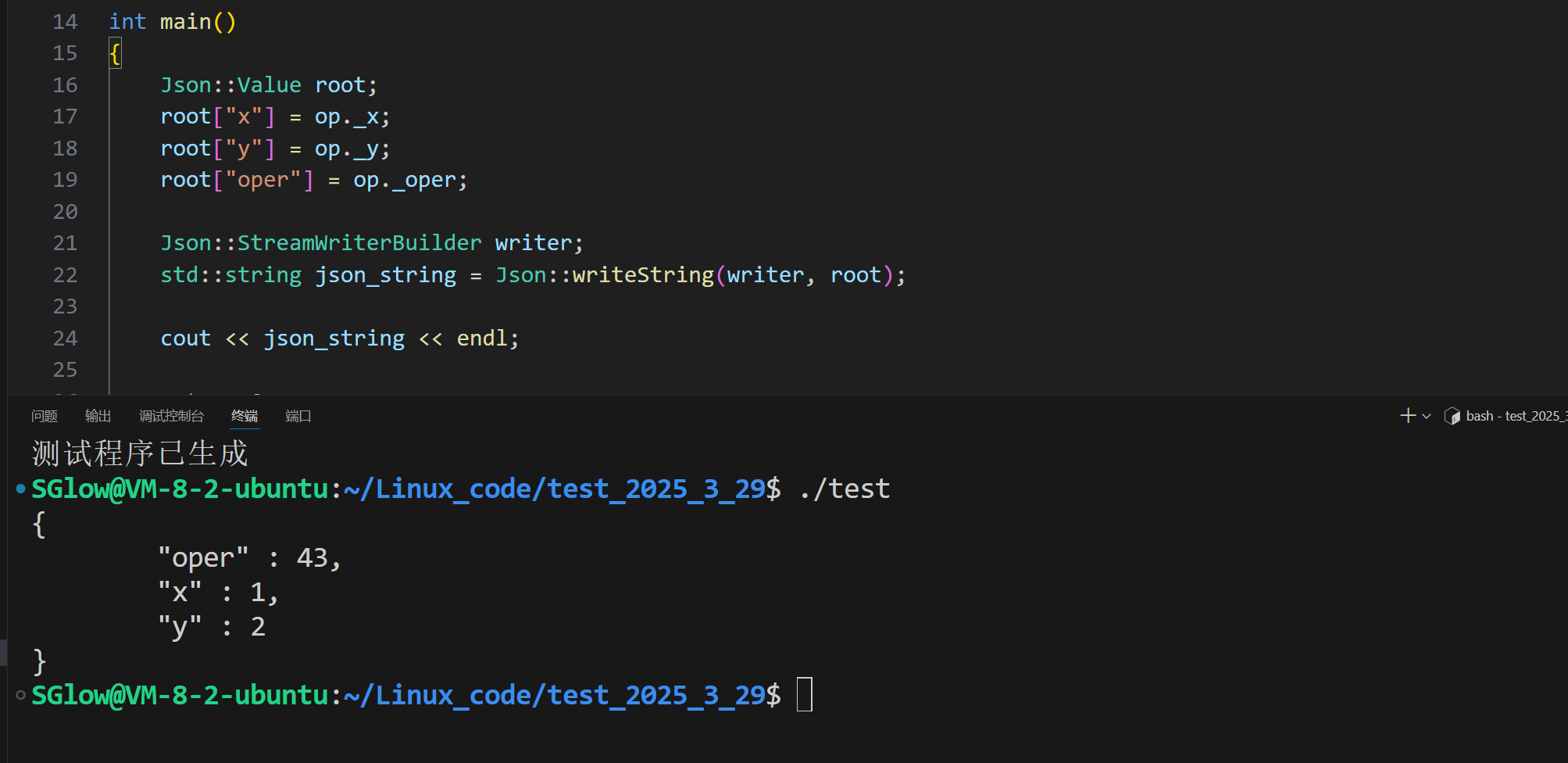
我们发现json会将结构化数据转为KV字符串。同样我们也可以反序列化

使用json需要包含的文件
②json序列化代码模板
// 序列化模板代码Json::Value root;//输入每个想要序列化的对象的成员变量root["x"] = op._x;root["y"] = op._y;root["oper"] = op._oper;//将root接收的要序列化的对象转换为json格式的字符串Json::StreamWriterBuilder writer;std::string json_string = Json::writeString(writer, root);③json反序列化代码模板
// 反序列化模板代码Json::Value root;Json::Reader reader;bool ParsingSuccessful = reader.parse(json_string, root);if (!ParsingSuccessful)return 1;//进行错误处理// 接受反序列化结果的结构体对象operation info;info._x = root["x"].asInt(); // 对每个成员进行提取info._y = root["y"].asInt();info._oper = root["oper"].asInt(); // char类型也用asInt()来提取④将自定义方案和json结合
json处理后的数据是有效载荷,我们还可以自己给这个有效载荷做一层包装。因为TCP是面向字节流的,有了这一层包装可以进一步保证资源传输完整性。
格式:head_length(有效载荷的长度)\r\n + 有效载荷(json处理后的数据)+ \r\n
到此为止,我们就实现了一个自己的协议。

对于客户端,它需要将发送的数据通过协议里面的包装函数转换成上述格式的字符串传出去,接收端再按照相应的解包函数逆向还原结构化数据,然后调用将这些数据作为参数调用服务,最后再将结果通过协议返回给客户端。
2.TCP协议(传输控制协议)
(1)为什么支持全双工
TCP会创建发送和接受缓冲区。send、write都是写到发送缓冲区,本质就是拷贝。recv和read同理,而最后何时刷新缓冲区这个决策由OS自主决定。
为什么TCP支持全双工?是因为有缓冲区,两台主机分别有一个发送和接受缓冲区,保证数据能从一方发送缓冲区发到另一方的接受缓冲区。这和系统的文件系统的处理类似,都是用空间换时间的做法。
(2)管理报文
OS内部可能会存在大量处于不同状态的报文,需要管理,管理方法依然是先描述、再组织
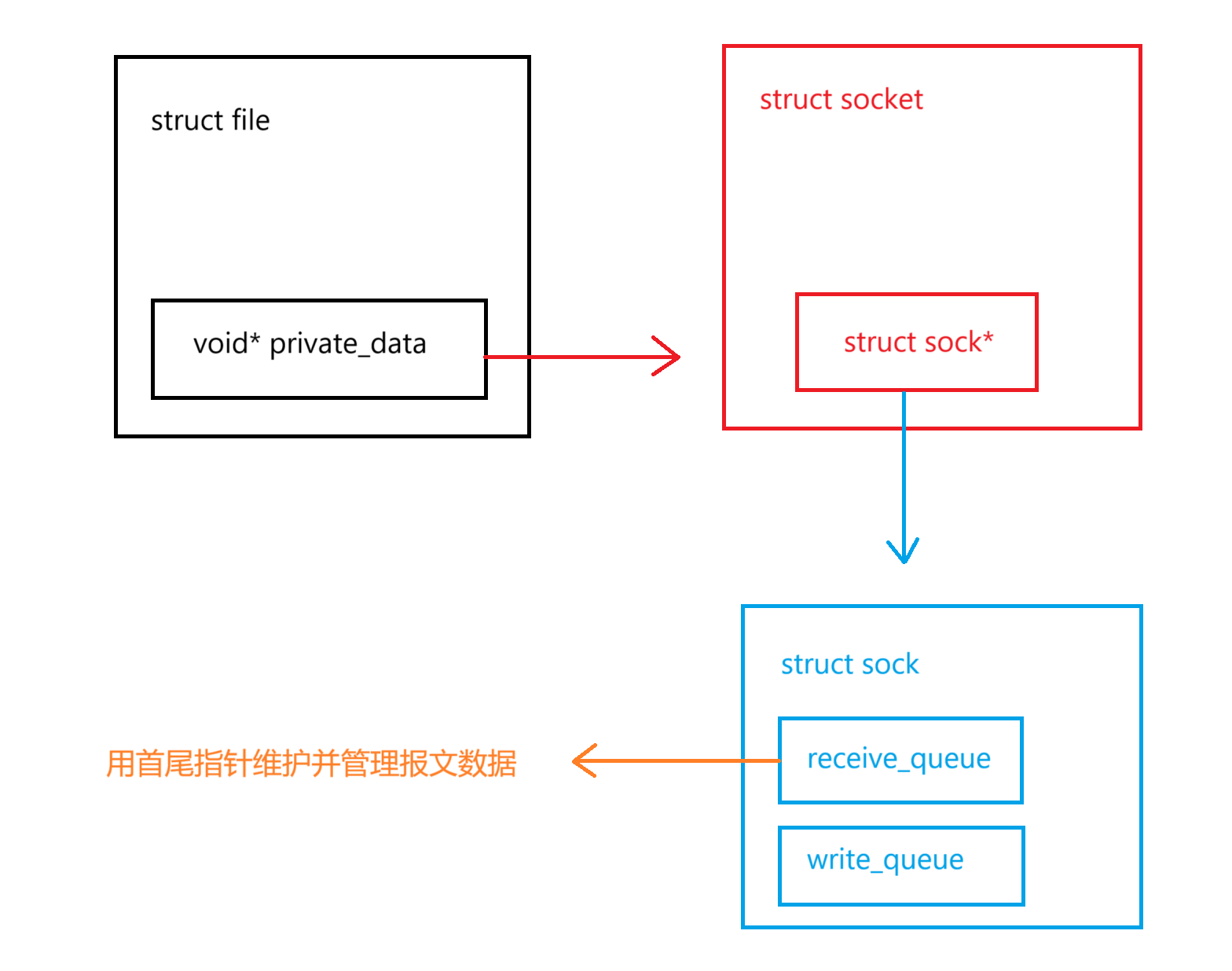
这里面的的receive_queue和write_queue就是我们说的发送和接受缓冲区。我们可以看到这两个缓冲区是socket单独开辟的,和OS层面的文件缓冲区、语言级缓冲区是没有关系的。我们可以理解为创建一个socket之后,对应的文件在file层面和其它文件没什么区别,但实际上是多开辟了缓冲区的。
(3)面向字节流
和面向数据报不同,UDP的数据必须完整打包发过去(快递不能收半个);相比而言,TCP就像自来水管,只负责发水,或多或少,发一个字节也是发数据了。至于数据怎么发,出错了怎么办等都由TCP自主决定,这就是面向字节流。
因此,TCP的完整性应由应用层保证,就是序列化中自定义协议的方案(head_length + json的包装)。
3.会话和守护进程
(1)前台进程和后台进程
使用命令可查看进程的属性
ps ajx | head -1 ; ps ajx | grep sleep | grep -v grep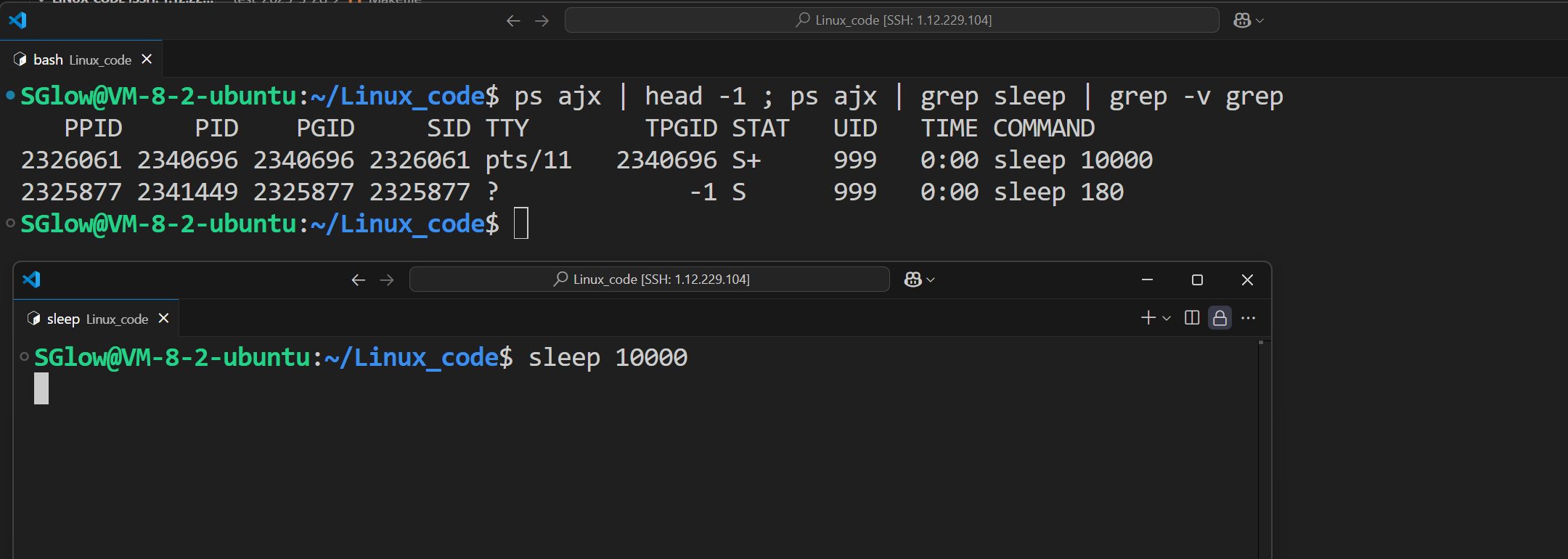
有个多余的sleep 180,我们不管它,只关注需要的部分
前台任务状态有+,S+就是前台的,这意味着可以Ctrl + C杀掉进程
sleep 1000 &直接放到后台,成为后台进程
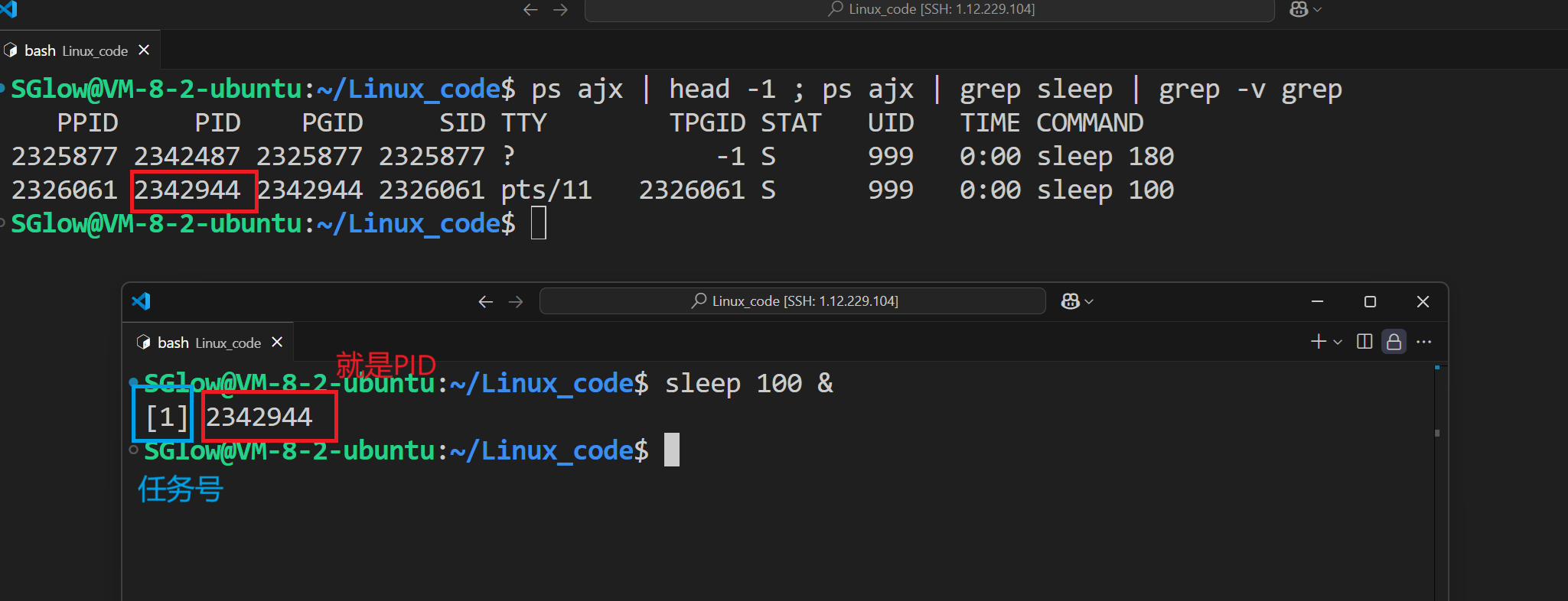
可以用命令fg (任务号)由后台提到前台,我们可以看到状态又重新变为+了。
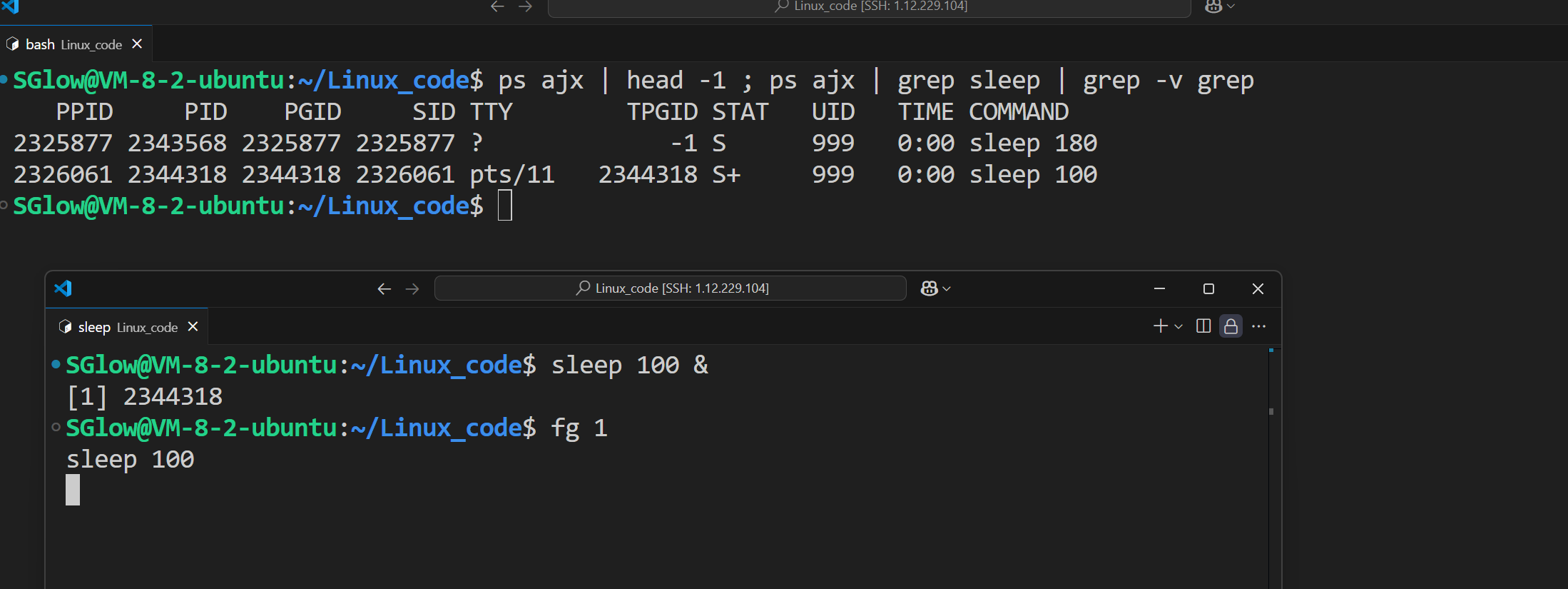
其它相关操作:
前台进程运行时^Z暂停,暂停时会获得一个任务号。
bg 1让它再次后台运行起来,这个时候就是后台的了
(2)会话
我们先来认识ps命令获取的属性
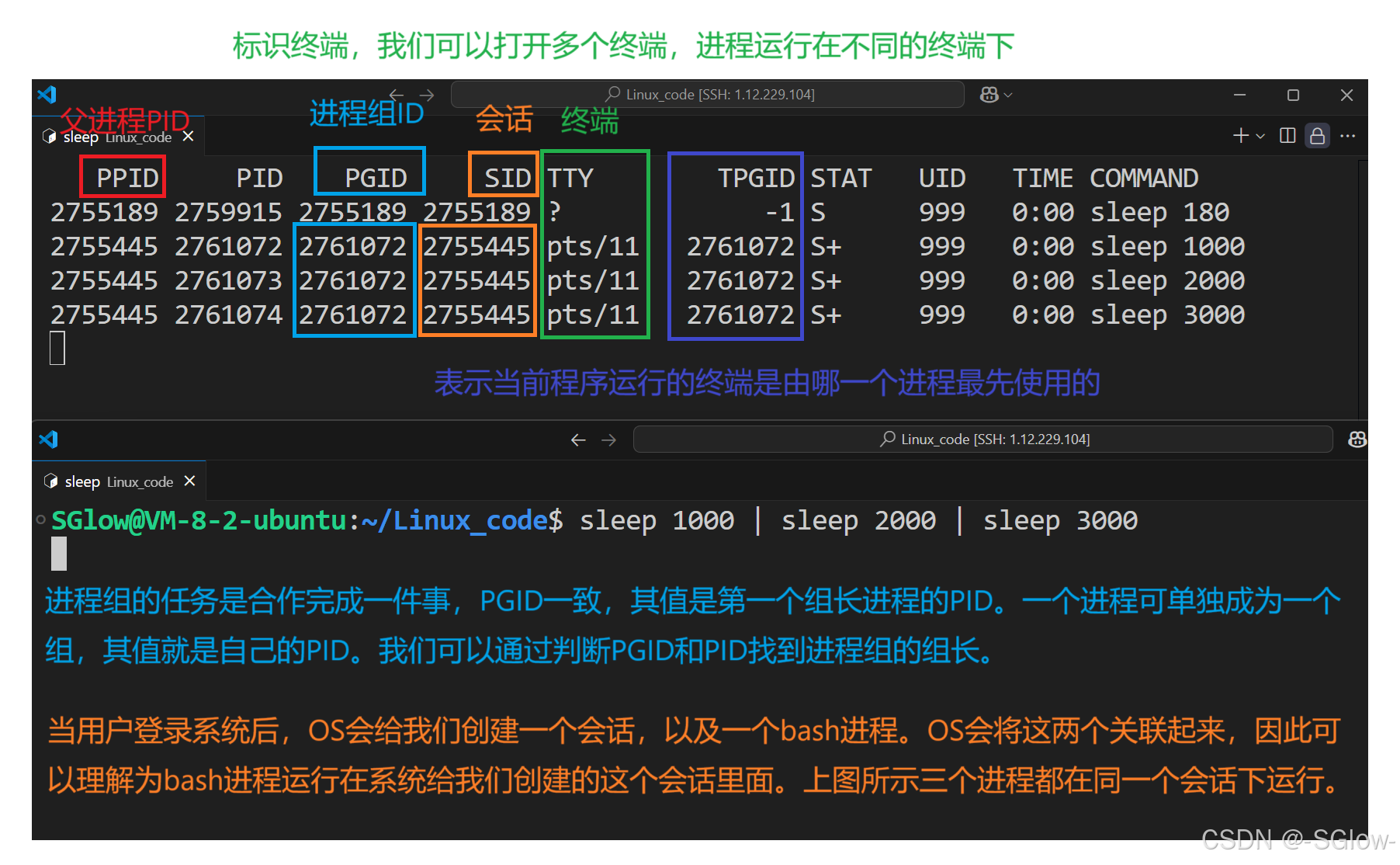
重点要理解会话,它是理解守护进程的必经之路。
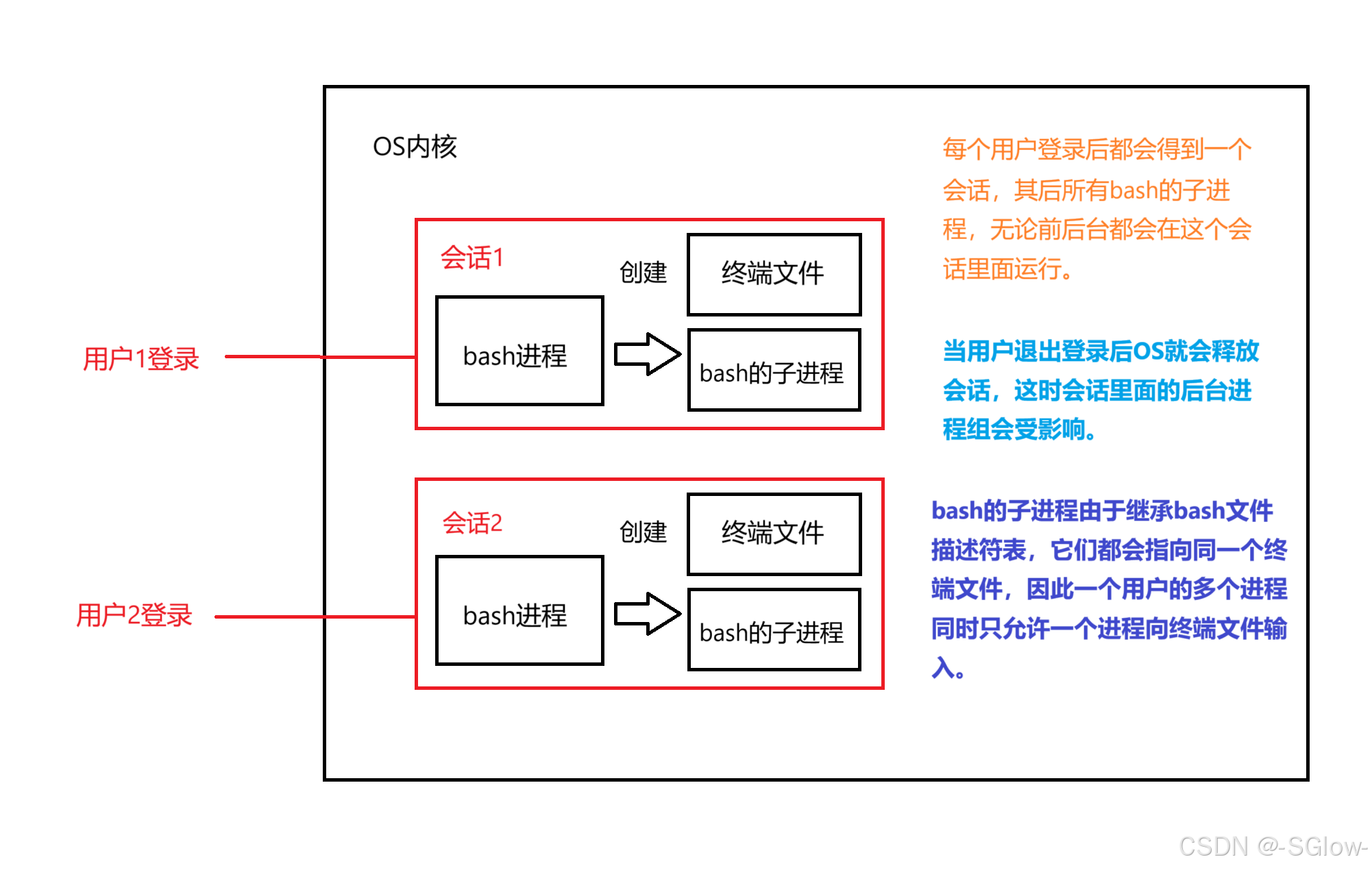
这个会话在Windows里面就是图形化界面,将bash替换成GUI的shell即可,每个用户登录后得到的都是一个系统提供的会话,其下的进程都在同一会话下运行。由于继承了shell的文件描述符表,进程都指向同一个终端文件,因此我们同时只能有一个前台进程来获取用户的输入。
每个用户都有对应的session(会话),session实体也要通过数据结构管理起来,其中session有存储的地址和id等信息,将这些信息和bash的PID关联起来,此时进程就和会话相关了,其它进程同理。我们可以认为进程就是在会话里面运行的。
SID的值就是登录用户后bash的ID,其下子进程的SID理应都是该值。但用户一退出,会话下面的后台进程就会受到影响(不一定会被销毁,可能报错),因此要创建守护进程,就是想办法让后台进程在一个新的会话下面运行,而不是和用户的会话强关联。
(3)创建新会话和守护进程
①创建新会话
谁调用pid_t setsid()成功了,谁就创建了一个session并且自己成为了其中组长。调用的进程不能是进程组的组长,我们可以用孤儿进程来保证这一点。
daemon函数就是创建守护进程的函数,可以结合Daemon的实现来理解。
②Daemon实现
#pragma once#include <iostream>
#include <cstdlib>
#include <signal.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/types.h>
#include <sys/stat.h>void myDaemon(bool ischdir, bool isclose)
{// 守护进程屏蔽特定的信号,这里可以按照自己的需要进行修改signal(SIGCHLD, SIG_IGN); // 忽略子进程结束信号,子进程结束后自动释放资源signal(SIGHUP, SIG_IGN); // 忽略挂起信号signal(SIGTSTP, SIG_IGN); // 忽略停止信号signal(SIGPIPE, SIG_IGN); // 忽略管道破裂信号// 进程组的组长不能创建新会话,因此创建子进程,让子进程执行后面的代码if (fork() > 0)exit(0); // 父进程(进程组组长退出)// 从这里开始就是子进程在执行代码了,子进程一定保证不是进程组组长,组长已经销毁了,可以说这里开始子进程就是孤儿进程了// 这一步是必然的,因此我们也可以说守护进程就是孤儿进程setsid(); // 建立新会话,该孤儿进程自动成为新的会话组长,并与原来的会话分离// 每一个进程都有自己的CWDif (ischdir) // 选择是否将当前进程的CWD更改成为 / 根目录,这样守护进程就能独自在根目录运行,而不会受到任何外界的干扰,在守护进程中访问文件就相当于绝对路径了chdir("/");// 选择是否关闭文件描述符,这样守护进程就不需要和终端打交道了if (isclose){close(0);close(1);close(2);}else{// 重定向标准输入、输出、错误到/dev/nullint fd = open("/dev/null", O_WRONLY); // 根目录下的黑洞文件,写的直接丢弃,读也读不到数据if (fd > 0){dup2(fd, 0); // 将标准输入重定向到/dev/null,保证读不到任何输入dup2(fd, 1); // 将标准输出重定向到/dev/null,保证输出不显示在屏幕上dup2(fd, 2); // 将标准错误重定向到/dev/null,保证错误不显示在屏幕上close(fd); // fd已经有3份拷贝了,关闭原来的fd}}
}至此,只要程序调用这个函数,它就变成了一个守护进程,独立地运行,不受任何用户登录退出的影响。这个时候我们才可以说创建了一个真正的服务。
我们可以让一个网络服务的程序变成守护进程,一直运行在后台,不断处理用户发送的请求,这就是服务器正在干的事情。
4.常见指令
(1)netstat
-t代表TCP,-u代表UDP
netstat -t 或者 netstat -u
其他选项:
n表示数字显示,a表示所有匹配项,p显示进程,l表示只查看监听状态的TCP。
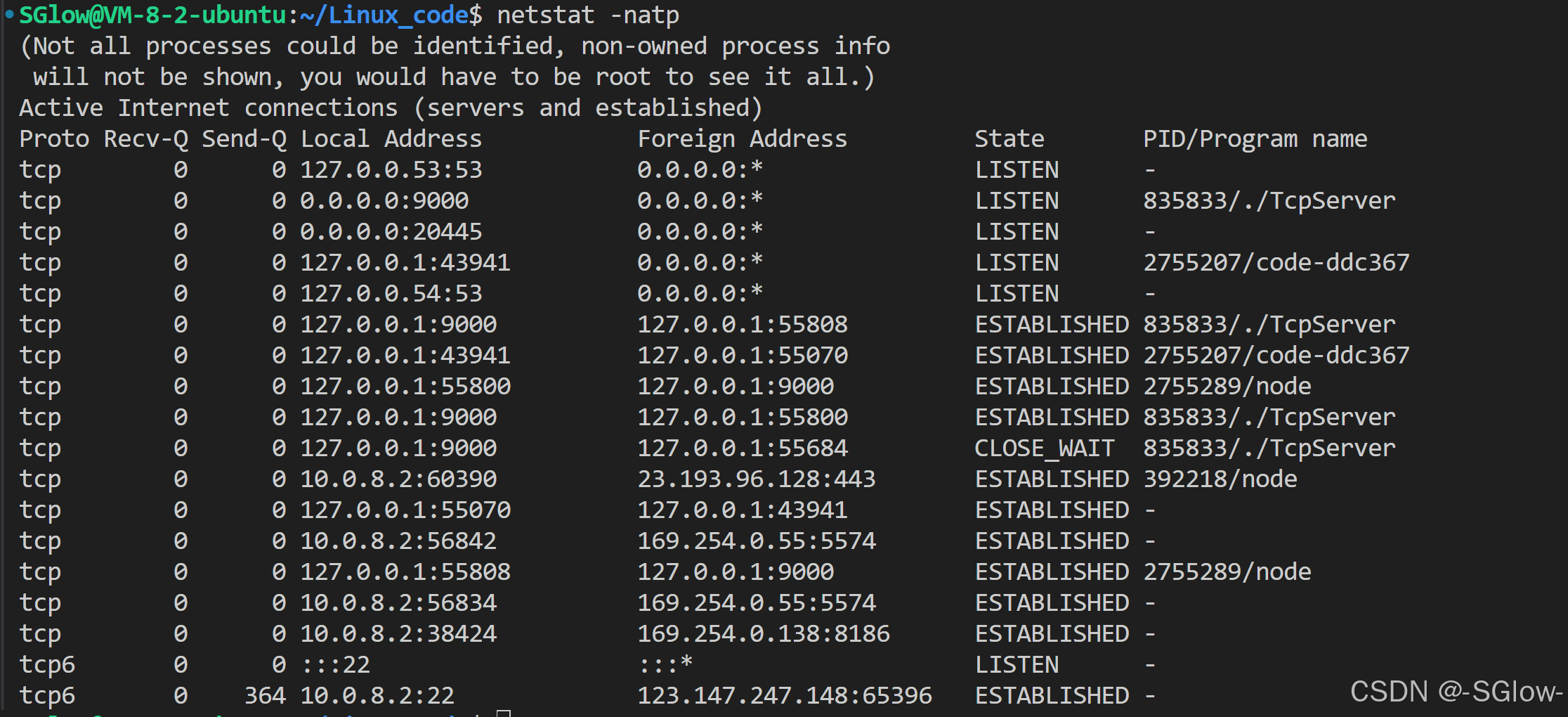
访问网站本质也是TCP(或UDP),我们可以在网站上用IP:Port访问TCP,获取提供服务的fd。
(2)telnet
telnet www.baidu.com 80(端口号)可以访问网站

这个可以配合HTTP使用。
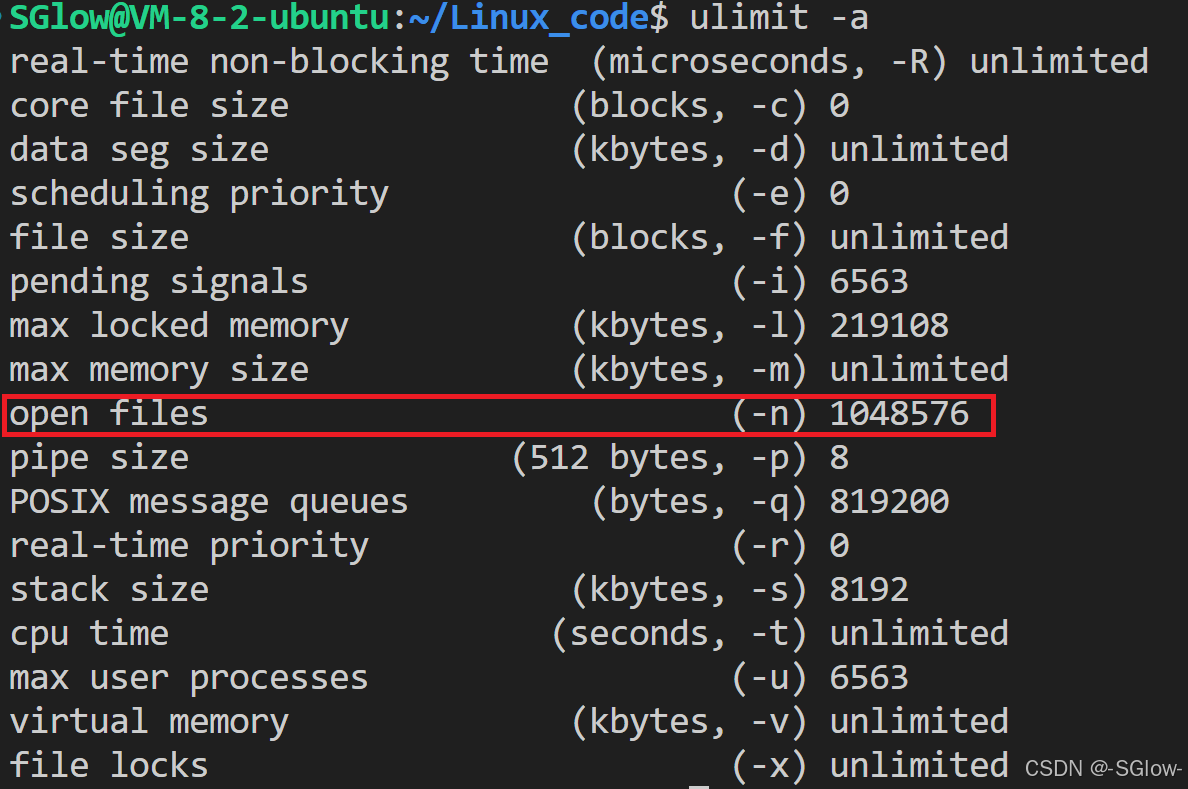
(3)ulimit
fd要close,否则有fd(有限、有价值的资源)泄露问题。Linux支持对文件描述符个数进行扩展的,ulimit -a可看到open files个数