帮网站做推广赚钱吗合肥百度竞价推广代理公司
引言
在人工智能与机器学习的领域里,算法犹如智慧的钥匙,开启着数据洞察的大门。决策树作为其中一颗璀璨的明珠,以其独特的非线性处理能力和可解释性备受瞩目。今天,让我们跟随作者的脚步,深入探究如何构建一个用于二元分类的决策树对象,解锁其中的奥秘。
什么是决策树?
一棵树是由什么组成的呢?从最底部开始,我们有树根。然后是树干,上面连接着几根大树枝。每根大树枝又有越来越小的树枝相互连接,最终形成小枝。小枝上长着树叶。我相信大家都已经知道这些知识了。然而,决策树的构建方式与之类似(这就是为什么叫“决策树”啦)。
决策树是一个相互连接的阈值或决策边界框架,人们可以通过它得出两个或更多的结果。请注意,本文将重点关注两个结果。决策树也可用于回归或预测连续变量,但我们会在另一篇文章中讨论。用文字定义很难完全展现决策树的魅力,可视化它会有趣得多!让我们来看一个经典机器学习问题——电子邮件欺诈检测的假设决策树示例。
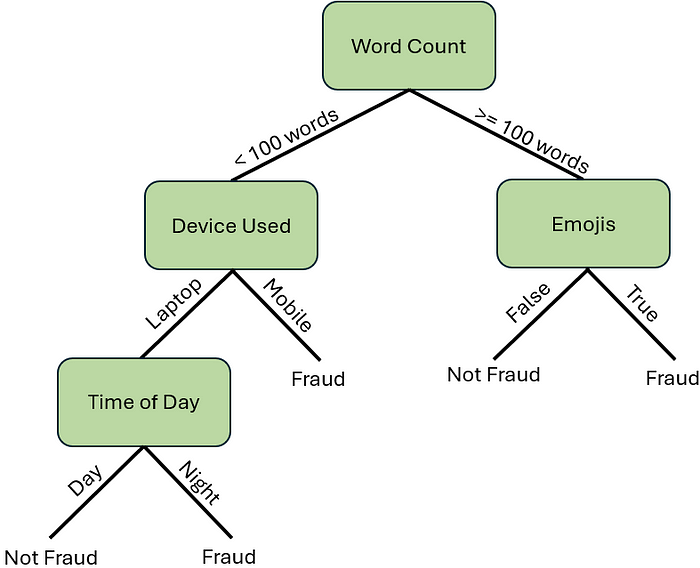
作者提供的图片
决策树有四个关键要素:根节点、决策节点、分支和叶子节点。每个决策树都只有一个根节点。在我们的示例中,根节点代表单词数量。接下来,你会注意到从根节点引出两条线,这些被称为分支。这些特定的分支代表两个阈值:少于 100 个单词 和 100 个单词或更多。这两个分支通向决策节点,分别代表 设备使用情况 和 表情符号。从这里开始就变得有趣了。设备使用情况 决策节点又分支到另一个 时间 决策节点,然而,另一个分支通向一个标记为 欺诈 的叶子节点。另一方面,表情符号 决策节点分支成两个叶子节点,一个标记为 “非欺诈”,另一个标记为 “欺诈”。
这相对来说很简单。决策树从一个根节点开始,使用阈值分支到后续节点,这些节点也使用阈值进行分支,最终通向一个预测结果或标签的叶子节点。
在深入探讨构建决策树的机制之前,让我们先看看它是如何工作的。假设你收到一封电子邮件,想用这个假设模型来判断这封邮件是否是欺诈邮件。以下是这封邮件的特征:
- 85 个单词
- 从笔记本电脑发送的邮件
- 夜间发送的邮件
首先,我们需要检查单词数量。它少于 100 个单词*,所以我们可以从根节点沿着分支到 设备使用情况* 决策节点。由于邮件是从笔记本电脑发送的,我们将遍历到 时间 决策节点。邮件是在夜间发送的,现在我们到达了叶子节点。我们的模型表明这封邮件很可能是欺诈邮件!
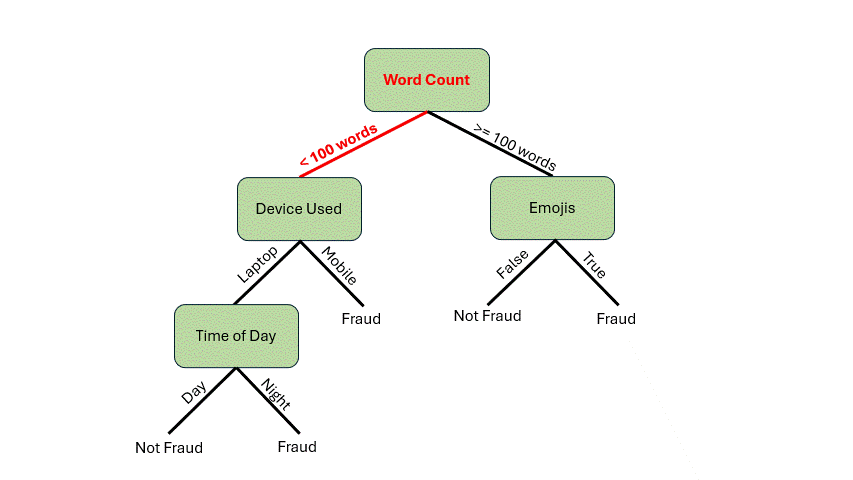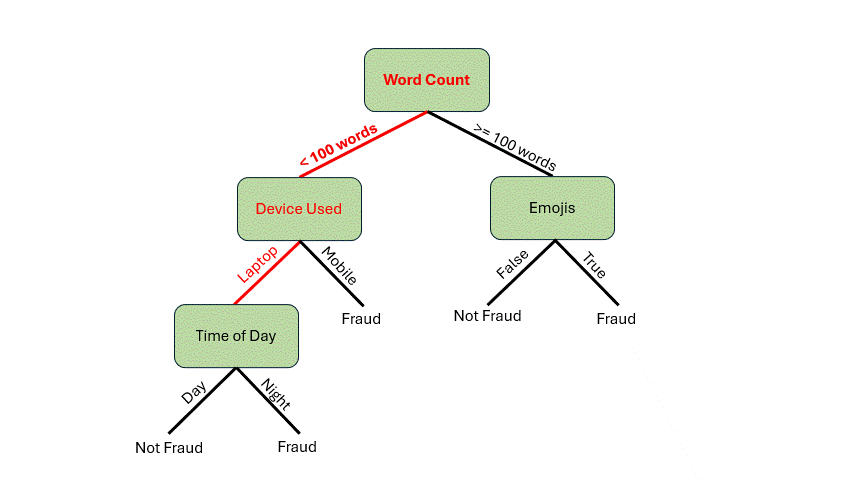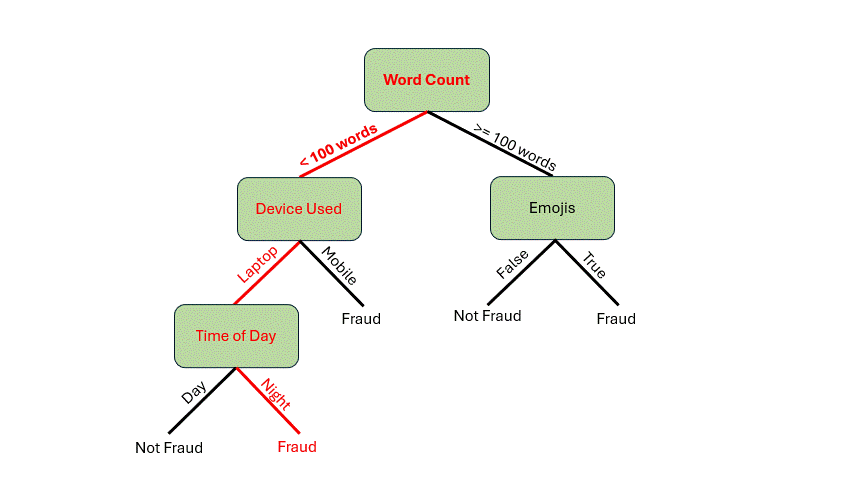
作者提供的动图
构建决策树 —— 基尼不纯度
为什么 单词数量 是根节点呢?为什么 设备使用情况 和 表情符号 是接下来的决策节点呢?我们怎么知道什么时候应该提供叶子节点而不是另一个决策节点呢?我们将在这里回答这些问题。
关键在于找到预测目标类别时歧义最小的特征。例如,假设我们有一个包含红色和蓝色两个类别的特征,以及一个目标变量 1 或 0。如果每个 红色 类别都是 1,每个 蓝色 类别都是 0,那么这个特定的特征将是根节点的完美候选,因为我们可以为目标类别获得最大的预测能力。
我提供的例子在现实世界中很少发生,所以我们必须使用一种特定的技术来构建我们的树。我们可以使用几种不同的方法来构建分类决策树,但在本文中,我们将重点关注基尼不纯度指标。看看下面的公式。
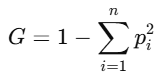
作者提供的图片
使用这个指标,我们可以轻松确定哪些特征在预测目标类别时歧义最小。让我们来看另一个假设的例子,并计算每个特征的基尼不纯度。
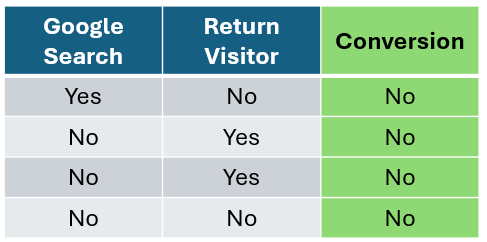
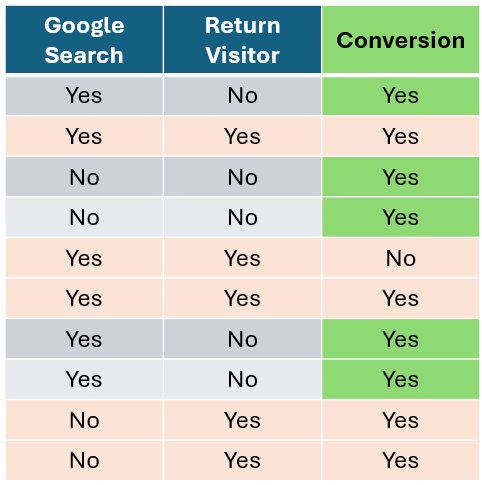
假设你有一个电子商务数据集,想用它来预测某人是否会购买你的产品。
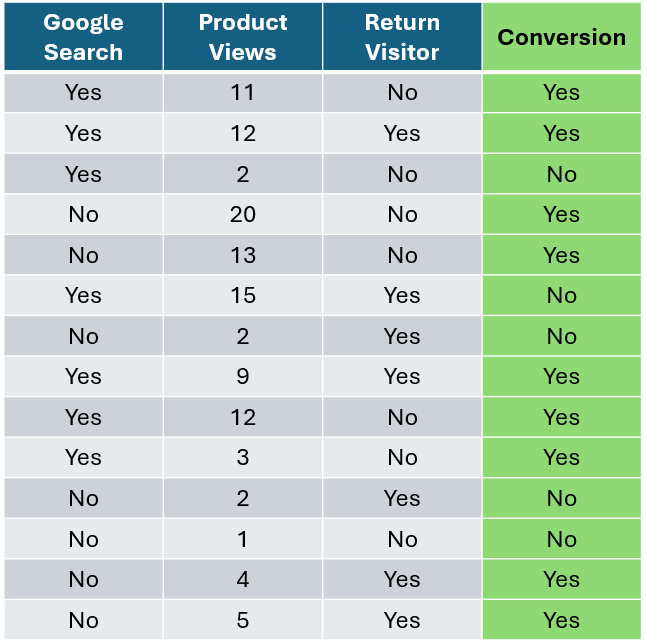
作者提供的图片
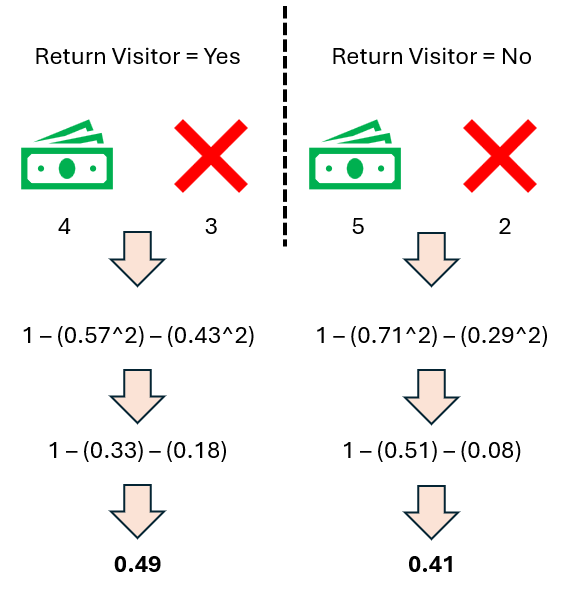
让我们从客户是否通过谷歌搜索访问网站这个特征开始,计算每个特征的基尼不纯度。首先,我们隔离通过谷歌搜索访问的客户,统计购买和未购买的客户数量。对于未通过谷歌搜索访问的客户,我们也做同样的操作。
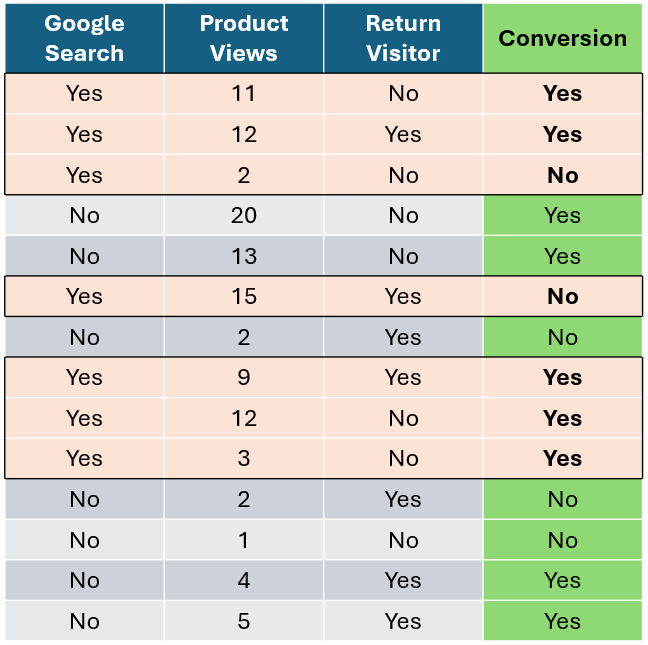
作者提供的图片
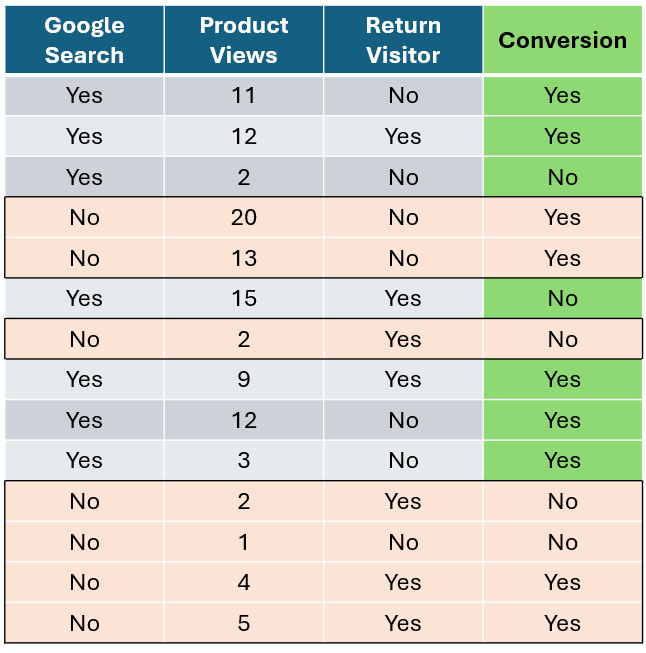
作者提供的图片
现在,来看你见过的最漂亮的数据透视表(开玩笑的啦!)

作者提供的图片
太棒了!现在,我们可以在模型的上下文中计算谷歌搜索的基尼不纯度。让我们代入一些数字,计算通过谷歌搜索和未通过谷歌搜索的基尼不纯度。
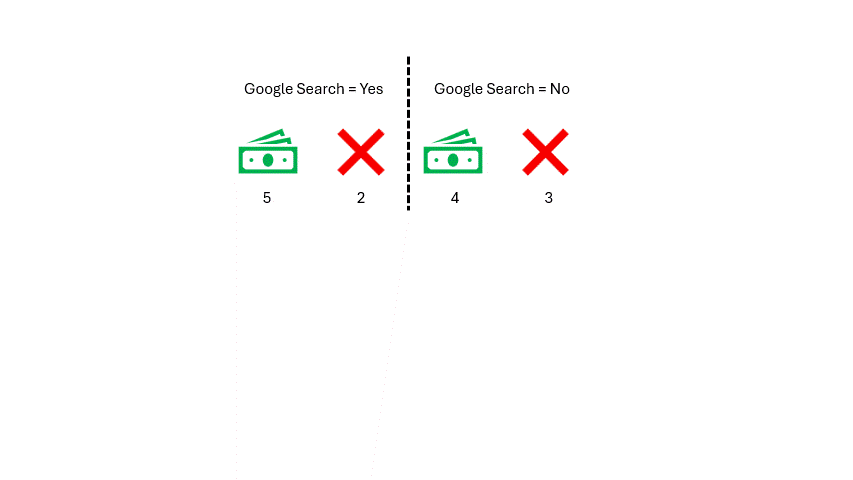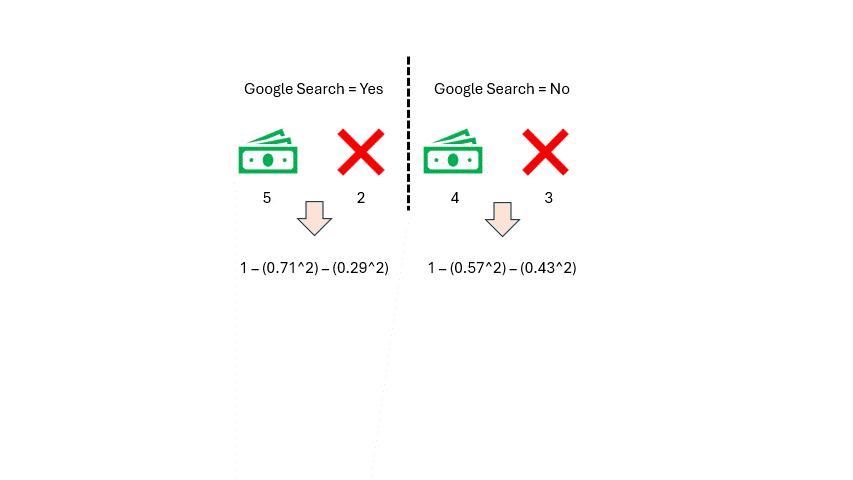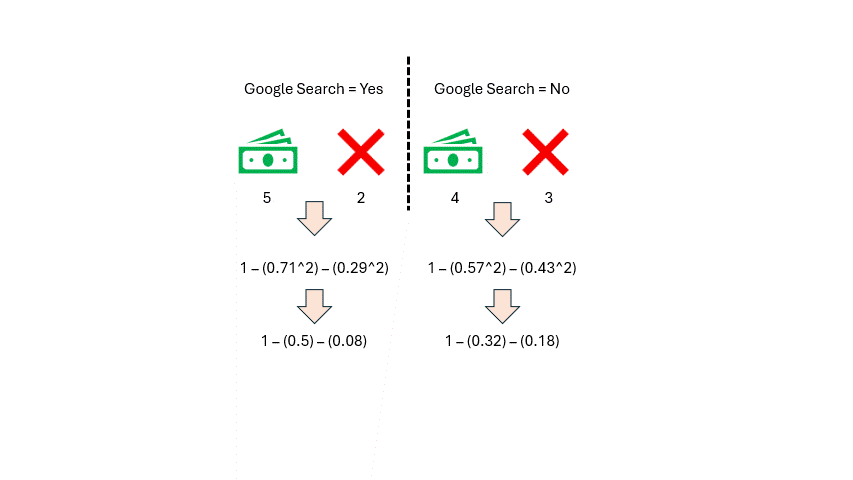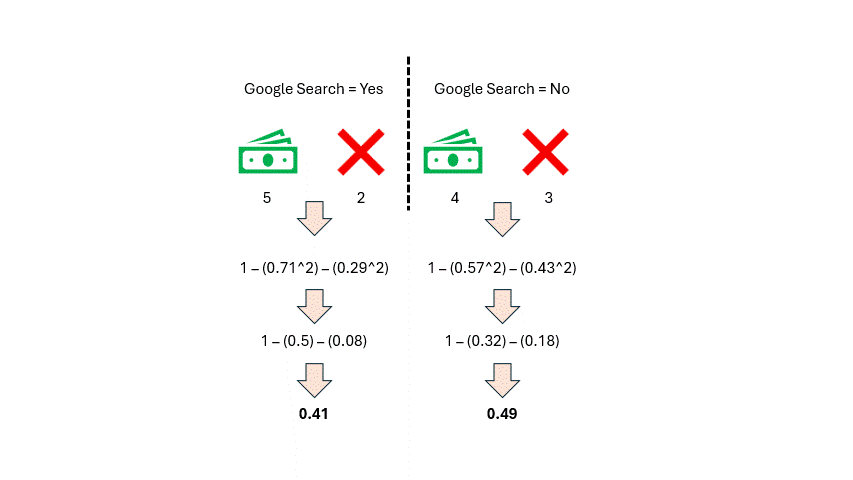
作者提供的图片
如你所见,我们得到了两个基尼不纯度分数,但这个特征我们只需要一个分数。因此,我们将对这两个分数取加权平均值。我们统计特征中每个类别的观测数量(谷歌搜索 = 是 和 谷歌搜索 = 否)。每个类别有七个观测值,所以它们的权重都是 0.5。然后我们按如下方式计算加权平均基尼不纯度:
0.5 * (0.41) + 0.5 * (0.49) = 0.45
现在,计算像我们刚才那样的分类变量的基尼不纯度似乎很简单。但是像 产品浏览量 这样的连续变量呢?这个过程更复杂,但我仍然觉得它很实用。首先,我们将按 产品浏览量 对观测值进行排序,根据每个值设置阈值,然后计算这些阈值的基尼不纯度。让我们直观地分解一下。
首先,让我们按 产品浏览量 对数据进行排序。
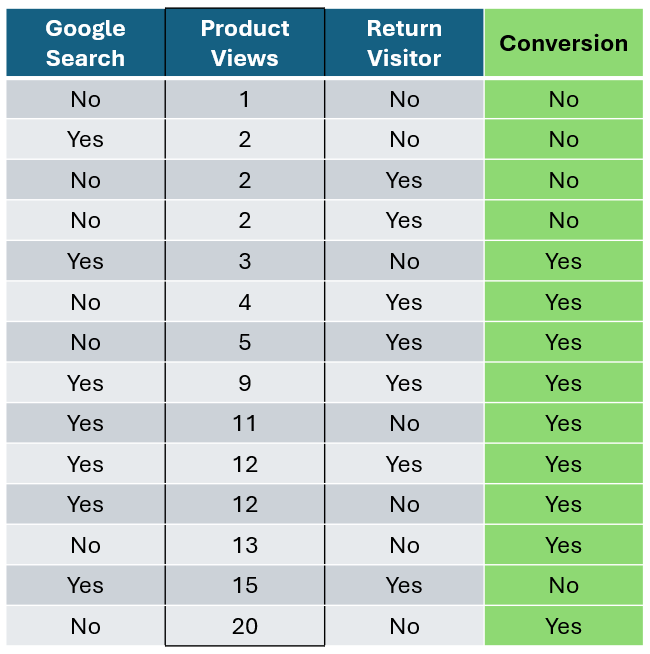
作者提供的图片
接下来,让我们计算后续值之间的阈值。注意,有些值是重复的,所以我们可以跳过,直到遇到一个新的唯一值。
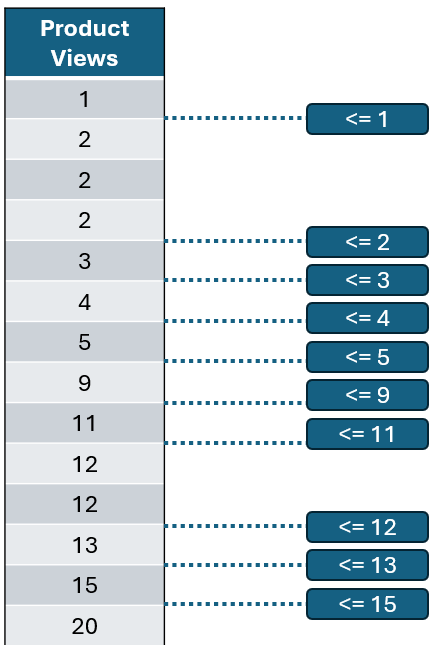
作者提供的图片
接下来是什么呢?基尼不纯度。如你所见,产品浏览量为两个的阈值产生的不纯度分数最低。这就是我们对 产品浏览量 进行分割的地方。
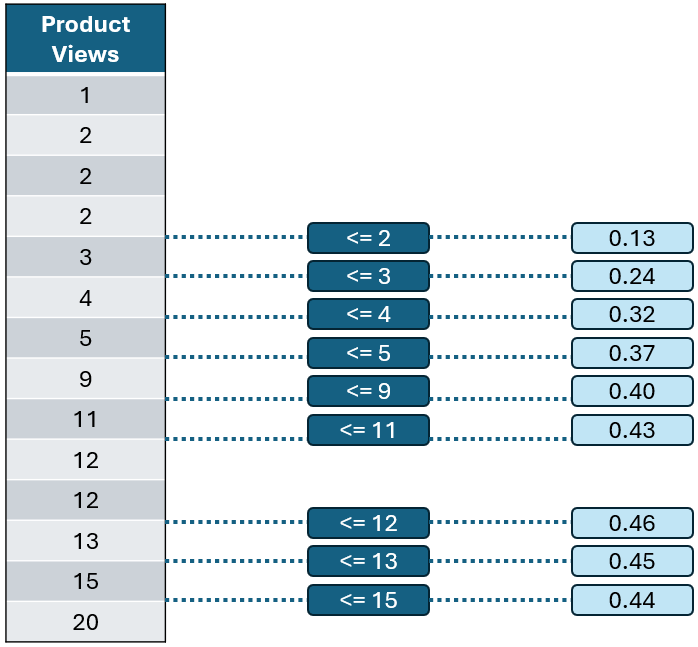
作者提供的图片
最后,让我们计算 回头客 指标的加权基尼不纯度分数,为 0.45。
构建树 —— 从根到叶
我们已经拥有了开始构建树所需的一切!让我们从根节点开始。我们怎么知道该指定哪个特征作为根节点呢?这就是基尼不纯度分数发挥作用的地方。这很关键。基尼不纯度分数最低的特征将为我们的目标变量提供最强的预测能力。因此,我们希望决策树从那里开始遍历。在这种情况下,产品浏览量 特征的基尼不纯度分数最低,它将成为我们的根节点。
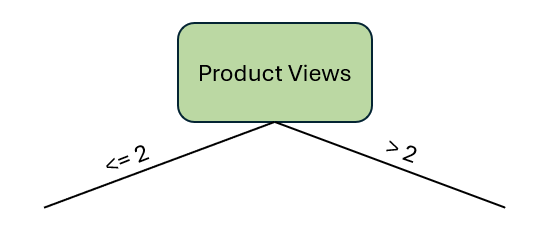
作者提供的图片
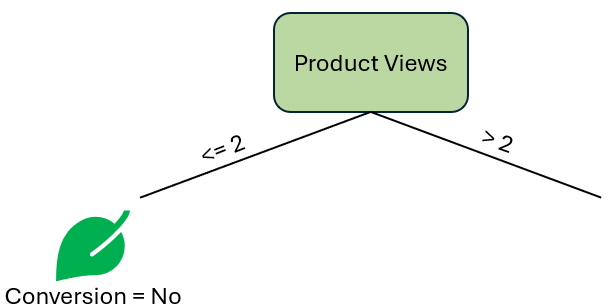
接下来,我们可能需要创建左右决策节点。为什么我说 可能 呢?让我们看看只满足左分支阈值(产品浏览量 ≤ 2)的观测数据。有什么发现吗?我们所有的观测结果都显示转化为 否。因此,继续探索这个节点的进一步分割在逻辑上没有意义。现在,我们有了第一个叶子节点。
作者提供的图片
作者提供的图片
让我们关注右边的决策节点。我们将计算 谷歌搜索 和 回头客 的基尼不纯度分数,分别为 0.17 和 0.16,非常接近。因此,我们的第一个决策节点将是 回头客 特征。
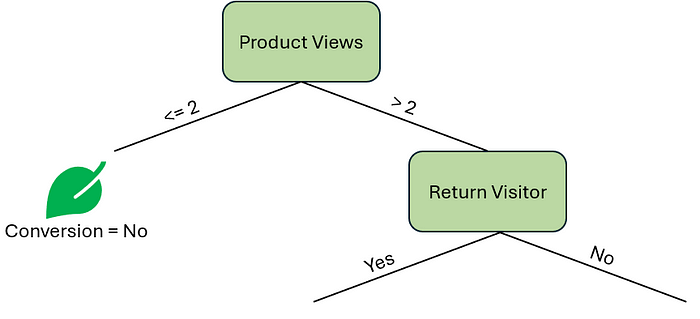
作者提供的图片
让我们在这里暂停一下,考虑一下我们的选择。我们可以通过计算剩余特征 谷歌搜索 的基尼不纯度分数来重复这个过程。另一方面,我们可以通过在分支末端指定叶子节点来结束我们的树。让我们看看剩下的数据。
80% 的回头客最终转化了,而另一方面,100% 的非回头客最终也转化了。再增加一个决策节点会带来更多价值吗?或者,我们应该在这里用一个预测 转化 为 是 的叶子节点来结束我们的树吗?两个叶子节点都会得出 是 的结果,这可能看起来很不寻常,但在构建决策树时这是可能出现的现象。这也让我们思考是否需要 回头客 这个决策节点。
作者提供的图片
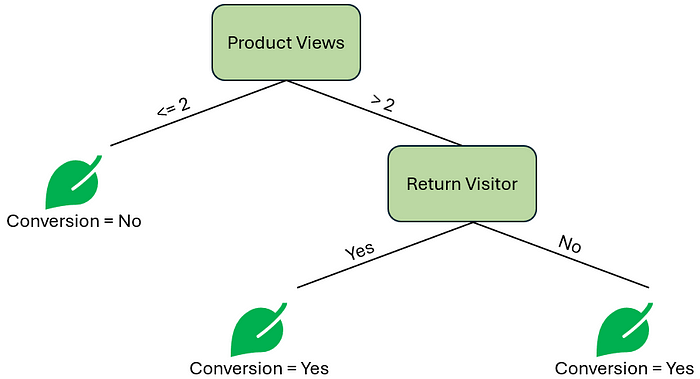
作者提供的图片
在这个阶段,你可能想知道什么时候停止添加决策节点的方法或最佳实践,我们如何确定目标的哪个类别作为叶子节点,以及是否应该有更多的标准来将一个特征作为决策节点。这些和其他超参数可以在模型中进行微调。话说回来,是时候跳进 Python 并构建我们的自定义决策树模块了!请记住,这将涉及几个高级概念。
DIYClassificationDecisionTree 类
让我们从导入库并构建初始化函数开始。这个类有很多属性,让我们深入了解一下。
超参数
我们将在这个对象中使用四个超参数,但也可以包含更多。超参数在任何基于树的模型中都很关键,因为找到这些指标的组合可以帮助我们在避免过拟合数据的同时最大化预测能力。这些是我个人比较喜欢的超参数。我们还将在另一个属性中存储最优超参数集。
max_depth: 我们的树的最大深度,即我们允许在树中创建节点的深度。
min_samples_split: 拆分节点之前所需的最小样本数。这确保了我们为每个可能的预测规则组合保留足够大的样本量。
min_samples_leaf: 类似于 min_samples_split,但这适用于叶子节点。
max_features: 构建树时要考虑的最大特征数量。
其他属性
如果你一直在关注这个系列,你会注意到我喜欢包含一个将数据拆分为训练集和测试集的方法。我也在这里包含了相关的属性。root 属性将存储我们的树。我还为我们的模型包含了各种评估指标,最后,一个空字典用于在微调模型时存储我们的最佳超参数集。
import pandas as pd
import numpy as np
from tqdm import tqdm
import randomclass DIYClassificationDecisionTree:def __init__(self, max_depth=None,min_samples_split=2,min_samples_leaf=0.1,max_features=1.0):## 超参数self.max_depth = max_depthself.min_samples_split = min_samples_splitself.min_samples_leaf = min_samples_leafself.max_features = max_features## 用于存储最终决策树的占位符self.root = None## 训练和测试数据self.X_train = Noneself.y_train = Noneself.X_test = Noneself.y_test = None## 特征名称self.feature_names = None## 评估指标self.confusion_matrix = Noneself.accuracy = Noneself.precision = Noneself.recall = None## 调优后的最佳超参数self.best_hyperparameters = {}
train_test_split 方法
这是我们将数据拆分为训练集和测试集的方法。你会注意到,我也会在这里保存特征名称,以便稍后可视化树时使用。
def train_test_split(self, X, y, test_size=0.2, random_state=None, feature_names=None):if random_state is not None:np.random.seed(random_state)## 打乱索引indices = np.arange(X.shape[0])np.random.shuffle(indices)## 根据测试集大小进行拆分test_count = int(len(X) * test_size)test_indices = indices[:test_count]train_indices = indices[test_count:]## 执行拆分self.X_train = X[train_indices]self.y_train = y[train_indices]self.X_test = X[test_indices]self.y_test = y[test_indices]# 保存特征名称if feature_names is not None:self.feature_names = feature_nameselse:
...
决策树作为机器学习中的强大工具,不仅能处理复杂的非线性数据,还能通过基尼不纯度等方法高效构建模型。本文从理论到实践,详细阐述了决策树的原理、构建方法以及Python实现。希望读者能借此掌握决策树的核心知识,在AI与ML的道路上更进一步,探索更多可能。