高端网站设计定制公司百度推广登陆网址
DeepSeek-v1
1.高质量的数据构建:2T tokens中英文数据集(数据去重、过滤和重混);
2. 模型架构参考LlaMa;
3.数据并行、张量并行、超参数设置等:
衍生:DeepSeek-Coder、deepseek MoE、DeepSeek-Math
DeepSeek-v2
1.高质量的数据:8.1T tokens
2.模型架构:MLA+DeepSeekMoE,后训练引入GRPO
MLA 是对传统多头注意力(MHA)机制的创新。其核心思想是对键和值进行低秩联合压缩,以减少KV缓存。简单来说,使用一个下采样矩阵生成较小尺寸的KV缓存,在生成的时候再使用一个上采样矩阵将保存的KV缓存上采样到原尺寸。从而可以大幅减少KV缓存,同时保持较好的性能。
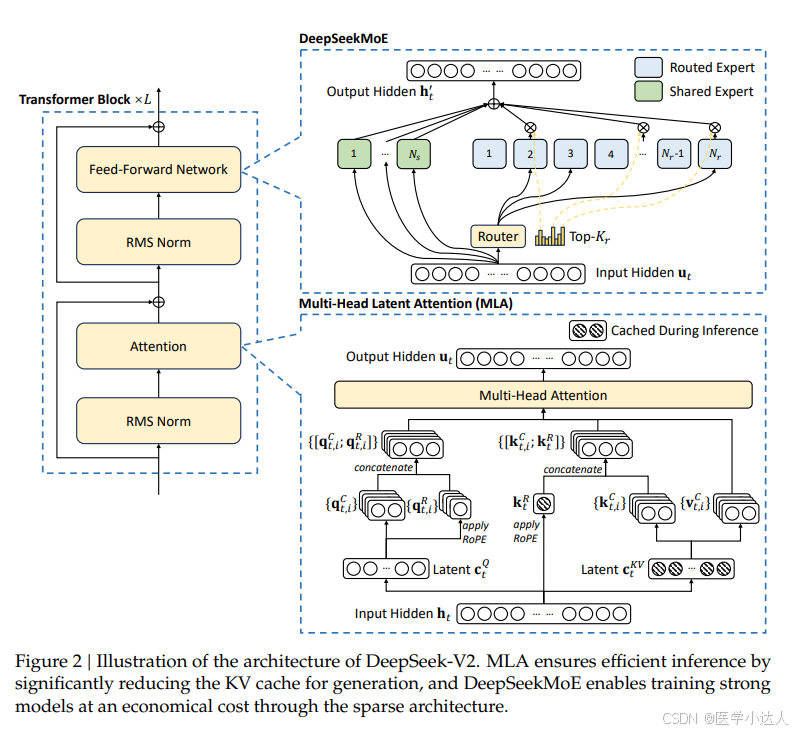
DeepSeekMoE模块
该模块结合了 Mixture of Experts(MoE)架构,通过更加灵活的专家选择和分配策略,使得模型能够根据输入的不同特性更有效地分配计算资源。该模块优化了模型在多任务环境下的表现,尤其是在需要大规模并行计算的情况下,能够显著提高计算效率和推理速度。
3.后训练:GRPO
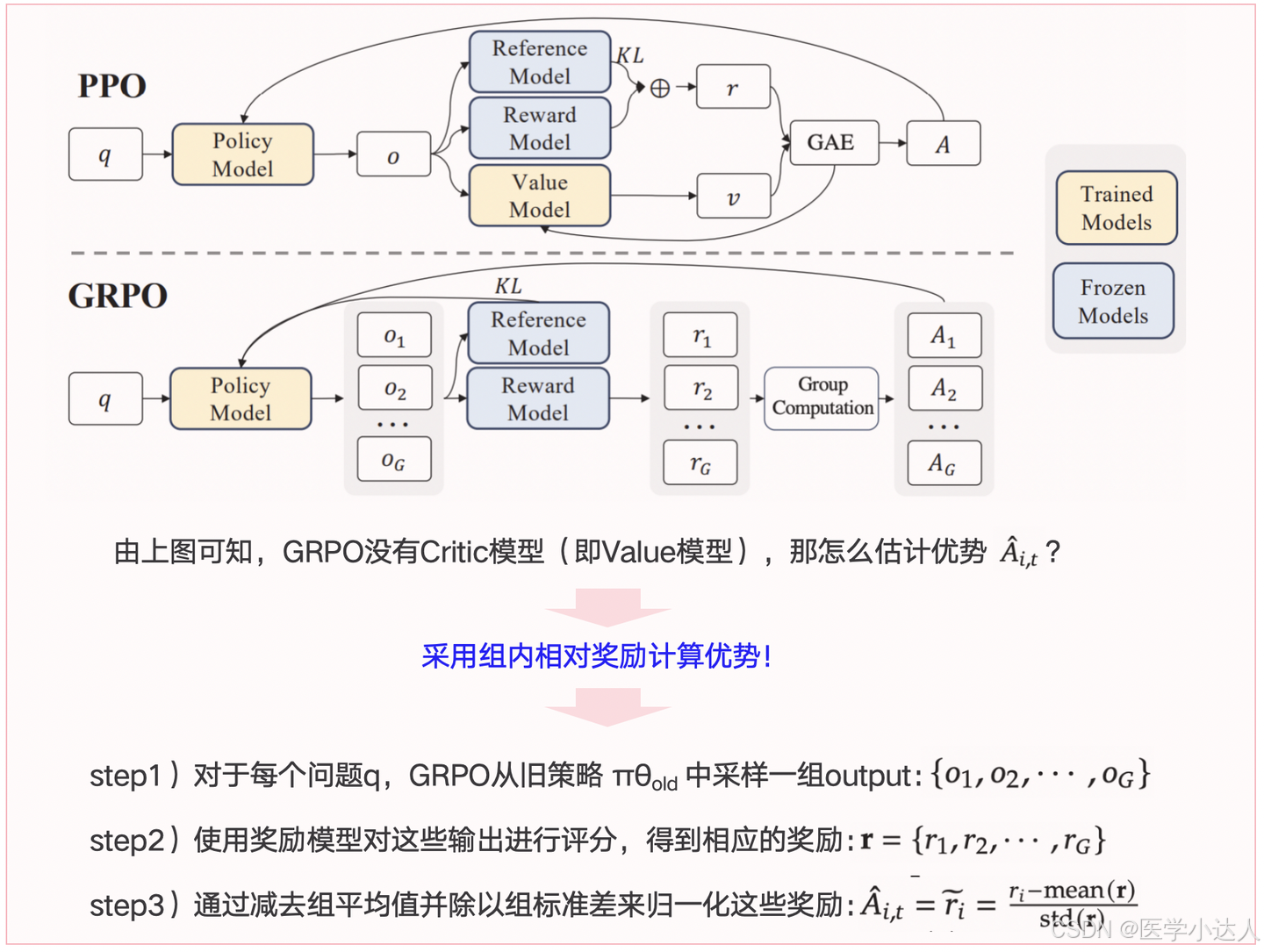
LLM的GRPO(Group Relative Policy Optimization)模型
背景(PPO的缺点):
需要训练一个与策略模型大小相当的价值模型(Critic模型),这带来了巨大的内存和计算负担;
在 LLM 的上下文中,通常只有最后一个 token 会被奖励模型打分,这使得训练一个在每个 token 上都准确的价值函数变得困难。
GRPO的优势:
避免了像 PPO 那样使用额外的价值函数近似,而是使用"同一问题下多个采样输出的平均奖励"作为基线。
优化目标
优劣势计算
衍生: DeepSeek-Coder-v2、DeepSeek-v2.5、DeepSeek-VL/VL2
DeepSeek-v3
1.高质量数据:14.8 T tokens
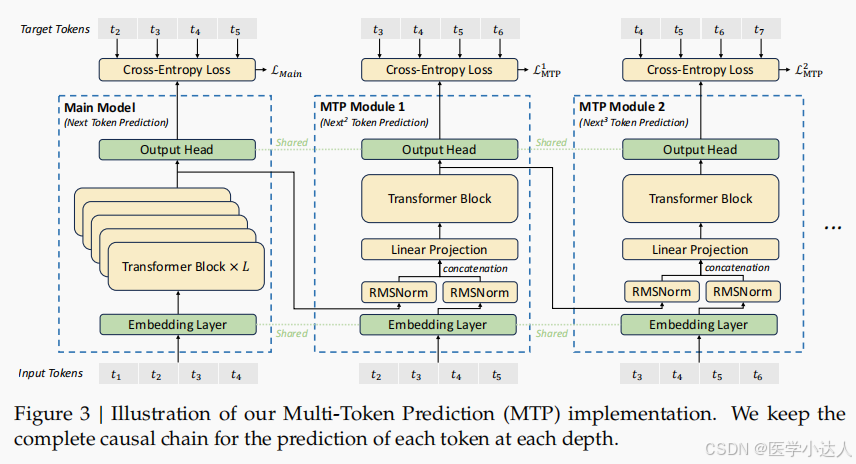
2.模型架构:引入MTP加速生成过程
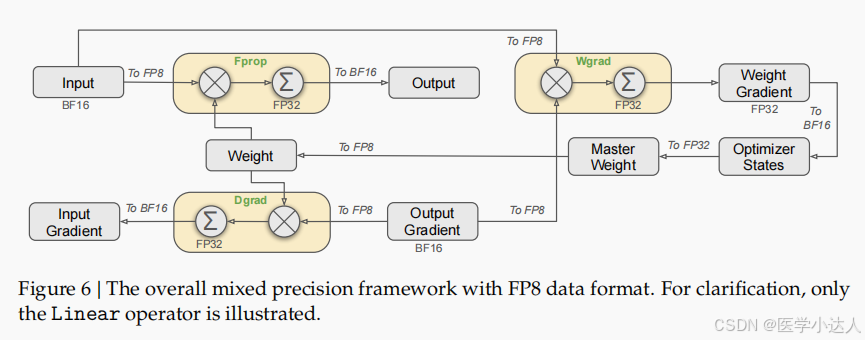
3.模型训练:首创FP8混精度训练,实现模型加速,减少内存占用
4.后训练:结合R1产生的高质量推理数据,进一步提升V3的推理能力
MTP模块:
具体来说,MTP使用D个顺序模块来预测额外的D个token。MTP模块由一个共享嵌入层、一个共享输出头、一个Transformer块和一个投影矩阵组成。对于第i个标记,在第k个深度处,首先将第(k-1)个深度的第i个标记的表示和第(i+k)个标记的embedding结合起来。组合得到的向量用作第k层处的Transformer块的输入,以产生当前深度处的输出表示,最后将该输出作为输入,共享输出头将计算第k个额外预测token的概率分布。即输出头会将该表示进行线性映射得到logits,随后使用Softmax函数来计算第k个附加token的预测概率。总而言之,MTP使用多个顺序模块,每个模块预测一个额外的token,用以帮助模型更好地规划其表示以预测未来的token。
训练目标:对于每个预测深度,都会计算其交叉熵损失,然后计算所有深度MTP损失的平均值,并将其乘以加权因子,最终得到MTP损失。该损失作为DeepSeek-V3的额外训练目标。
 DeepSeek-R1
DeepSeek-R1
1.后训练:直接将RL应用于基础模型,使得模型能用CoT来解决复杂的问题,同时出现自我反思的能力,也就是“顿悟时刻”;
2.蒸馏:应用大模型蒸馏小模型,提升小模型的推理能力
DeepSeek-R1: 冷启动强化学习
DeepSeek-R1 使用了冷启动 + 多阶段训练的方式:
- 阶段1:使用少量高质量的 CoT 数据进行冷启动,预热模型。
- 阶段2:进行面向推理的强化学习,提升模型在推理任务上的性能。
- 阶段3:使用拒绝采样和监督微调,进一步提升模型的综合能力。
- 阶段4:再次进行强化学习,使模型在所有场景下都表现良好。
DeepSeek-R1 使用冷启动数据的主要目的是为了解决 DeepSeek-R1-Zero 在训练早期出现的训练不稳定问题。相比于直接在基础模型上进行 RL,使用少量的 SFT 数据进行冷启动,可以让模型更快地进入稳定训练阶段:
- 可读性:冷启动数据使用更易于理解的格式,输出内容更适合人类阅读,避免了 DeepSeek-R1-Zero 输出的语言混合、格式混乱等问题。
- 潜在性能:通过精心设计冷启动数据的模式,可以引导模型产生更好的推理能力。
- 稳定训练:使用 SFT 数据作为起始点,可以避免 RL 训练早期阶段的不稳定问题。
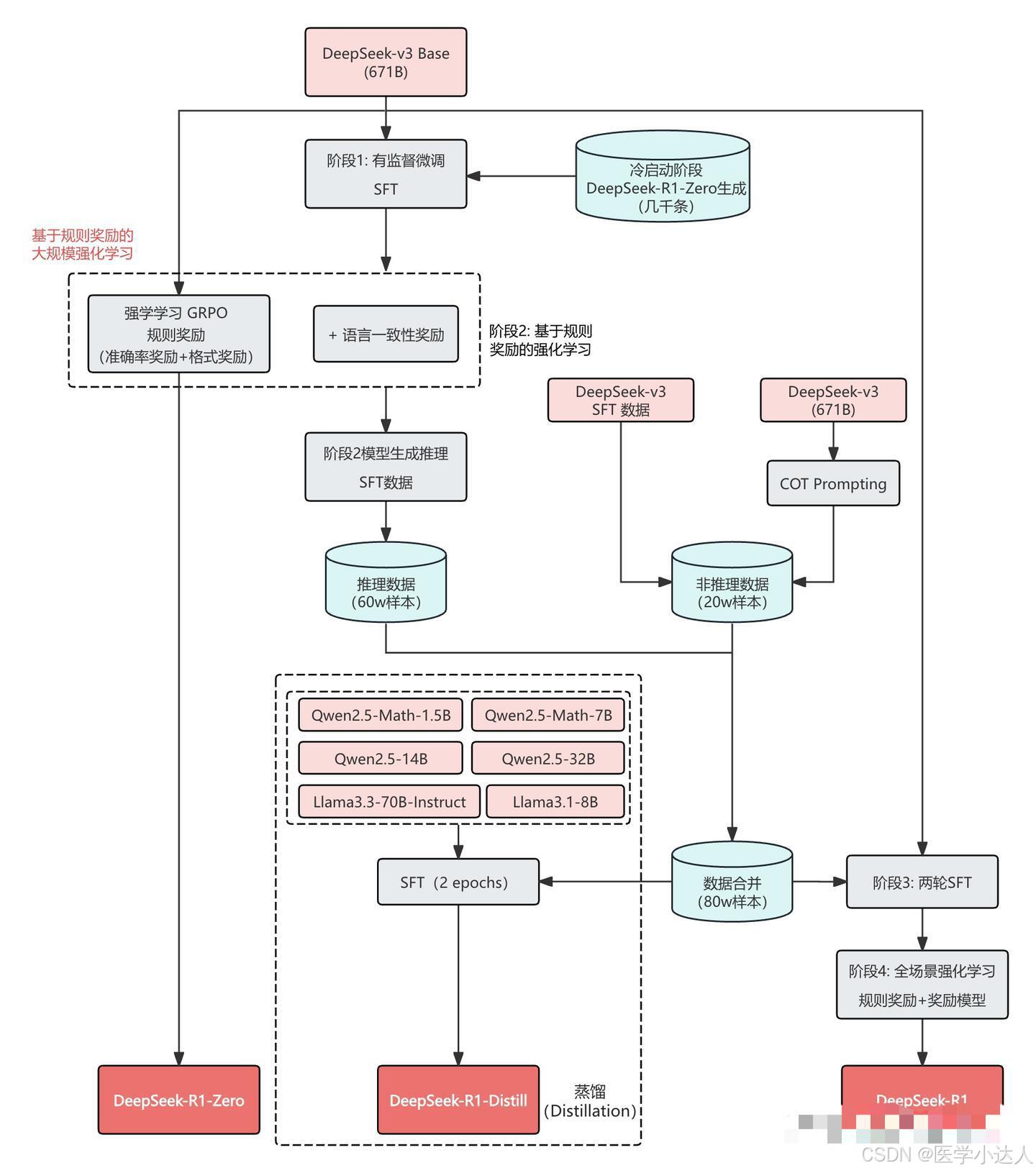
蒸馏小模型
为了获得更高效的小模型,并使其具有 DeekSeek-R1 的推理能力,直接对 Qwen 和 Llama 等开源模型进行了微调,使用的是上面 SFT DeepSeek-R1 的80万数据。研究结果表明,这种直接蒸馏方法显著提高了小模型的推理能力。在这里使用的基座模型是 Qwen2.5-Math-1.5B、Qwen2.5-Math-7B、Qwen2.5-14B、Qwen2.5-32B、Llama-3.1-8B 和 Llama-3.3-70B-Instruct。
对于蒸馏模型,只进行 SFT,不包括 RL 阶段,尽管加入 RL 可以显著提高模型性能。