怎样做软件网站建设网站一键备份
本笔记本演示了如何:
- 将 OpenAI Wikipedia 向量数据集索引到 Elasticsearch 中
- 使用 Streamlit 构建一个简单的 Gen AI 应用程序,该应用程序使用 Elasticsearch 检索上下文并使用 OpenAI 制定答案
安装
安装 Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,那么请参考一下的文章来进行安装:
-
如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
-
Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
在安装的时候,请选择 Elastic Stack 8.x 进行安装。在安装的时候,我们可以看到如下的安装信息:

环境变量
在启动 Jupyter 之前,我们设置如下的环境变量:
export ES_USER="elastic"
export ES_PASSWORD="xnLj56lTrH98Lf_6n76y"
export ES_ENDPOINT="localhost"
export OPENAI_API_KEY="YourOpenAiKey"
请在上面修改相应的变量的值。这个需要在启动 jupyter 之前运行。
拷贝 Elasticsearch 证书
我们把 Elasticsearch 的证书拷贝到当前的目录下:
$ pwd
/Users/liuxg/python/elser
$ cp ~/elastic/elasticsearch-8.12.0/config/certs/http_ca.crt .
$ ls http_ca.crt
http_ca.crt安装 Python 依赖包
python3 -m pip install -qU openai pandas==1.5.3 wget elasticsearch streamlit tqdm load_dotenv准备数据
我们可以使用如下的命令来下载数据:
wget https://cdn.openai.com/API/examples/data/vector_database_wikipedia_articles_embedded.zip$ pwd
/Users/liuxg/python/elser
$ wget https://cdn.openai.com/API/examples/data/vector_database_wikipedia_articles_embedded.zip
--2024-02-09 12:06:36-- https://cdn.openai.com/API/examples/data/vector_database_wikipedia_articles_embedded.zip
Resolving cdn.openai.com (cdn.openai.com)... 13.107.213.69
Connecting to cdn.openai.com (cdn.openai.com)|13.107.213.69|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 698933052 (667M) [application/zip]
Saving to: ‘vector_database_wikipedia_articles_embedded.zip’vector_database_wikipedi 100%[==================================>] 666.55M 1.73MB/s in 3m 2s 2024-02-09 12:09:40 (3.66 MB/s) - ‘vector_database_wikipedia_articles_embedded.zip’ saved [698933052/698933052]创建应用并展示
我们在当前的目录下打入如下的命令来创建 notebook:
$ pwd
/Users/liuxg/python/elser
$ jupyter notebook导入包及连接到 Elasticsearch
import os
from getpass import getpass
from elasticsearch import Elasticsearch, helpers
import wget, zipfile, pandas as pd, json, openai
import streamlit as st
from tqdm.notebook import tqdm
from dotenv import load_dotenvload_dotenv()openai_api_key=os.getenv('OPENAI_API_KEY')
elastic_user=os.getenv('ES_USER')
elastic_password=os.getenv('ES_PASSWORD')
elastic_endpoint=os.getenv("ES_ENDPOINT")url = f"https://{elastic_user}:{elastic_password}@{elastic_endpoint}:9200"
client = Elasticsearch(url, ca_certs = "./http_ca.crt", verify_certs = True)print(client.info())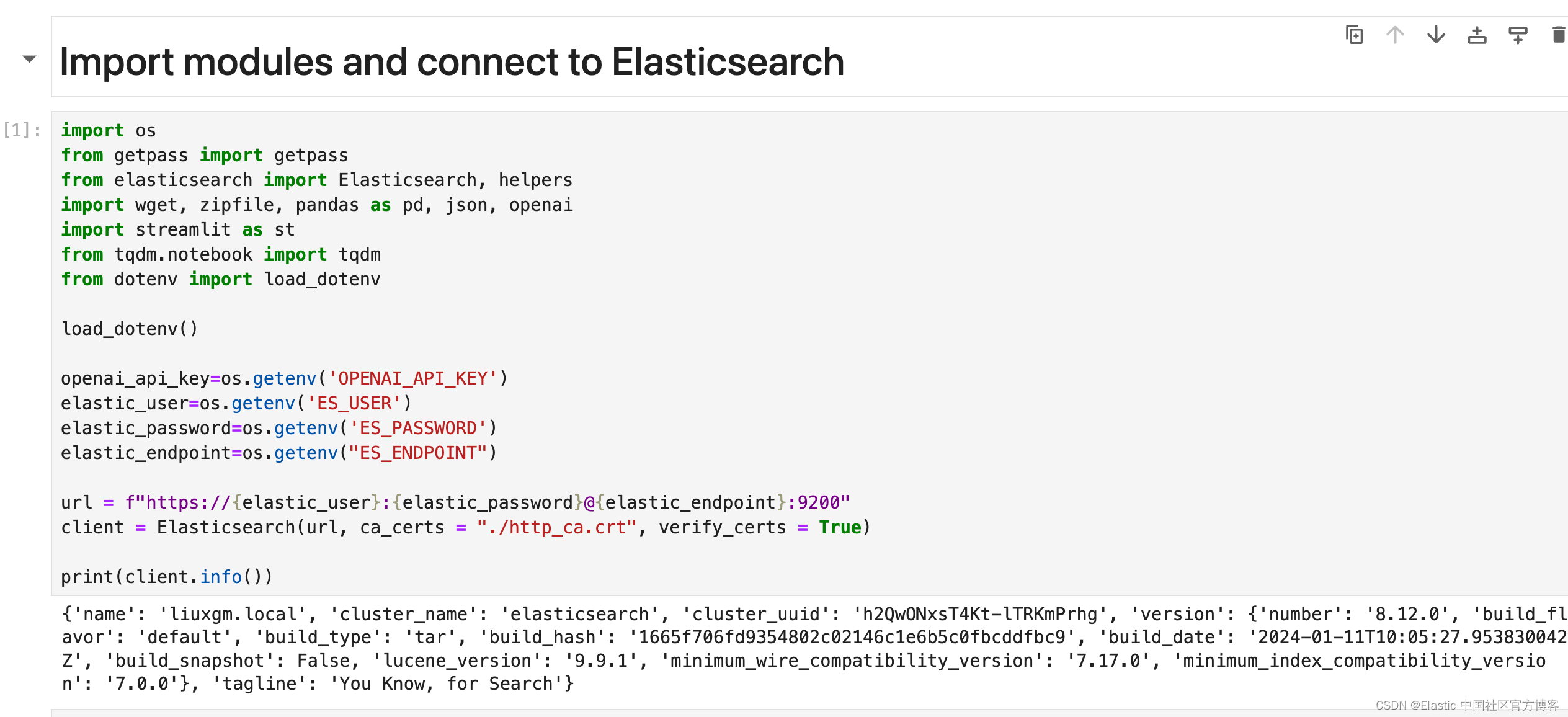
配置 OpenAI 连接
我们的示例将使用 OpenAI 来制定答案,因此请在此处提供有效的 OpenAI Api 密钥。
你可以按照本指南检索你的 API 密钥。然后测试与OpenAI的连接,检查该笔记本使用的型号是否可用。
from openai import OpenAIopenai = OpenAI()
openai.models.retrieve("text-embedding-ada-002")$ pip3 list | grep openai
langchain-openai 0.0.5
openai 1.12.0下载数据集
with zipfile.ZipFile("vector_database_wikipedia_articles_embedded.zip",
"r") as zip_ref:zip_ref.extractall("data")运行上面的代码后,我们可以在如下地址找到解压缩的文件 vector_database_wikipedia_articles_embedded.csv:
$ pwd
/Users/liuxg/python/elser
$ ls ./data
__MACOSX vector_database_wikipedia_articles_embedded.csv
paul_graham将 CSV 文件读入 Pandas DataFrame
接下来,我们使用 Pandas 库将解压的 CSV 文件读入 DataFrame。 此步骤可以更轻松地将数据批量索引到 Elasticsearch 中。
wikipedia_dataframe = pd.read_csv("data/vector_database_wikipedia_articles_embedded.csv")使用映射创建索引
现在我们需要使用必要的映射创建一个 Elasticsearch 索引。 这将使我们能够将数据索引到 Elasticsearch 中。
我们对 title_vector 和 content_vector 字段使用密集向量字段类型。 这是一种特殊的字段类型,允许我们在 Elasticsearch 中存储密集向量。
稍后,我们需要以密集向量字段为目标进行 kNN 搜索。
index_mapping= {"properties": {"title_vector": {"type": "dense_vector","dims": 1536,"index": "true","similarity": "cosine"},"content_vector": {"type": "dense_vector","dims": 1536,"index": "true","similarity": "cosine"},"text": {"type": "text"},"title": {"type": "text"},"url": { "type": "keyword"},"vector_id": {"type": "long"}}
}
client.indices.create(index="wikipedia_vector_index", mappings=index_mapping)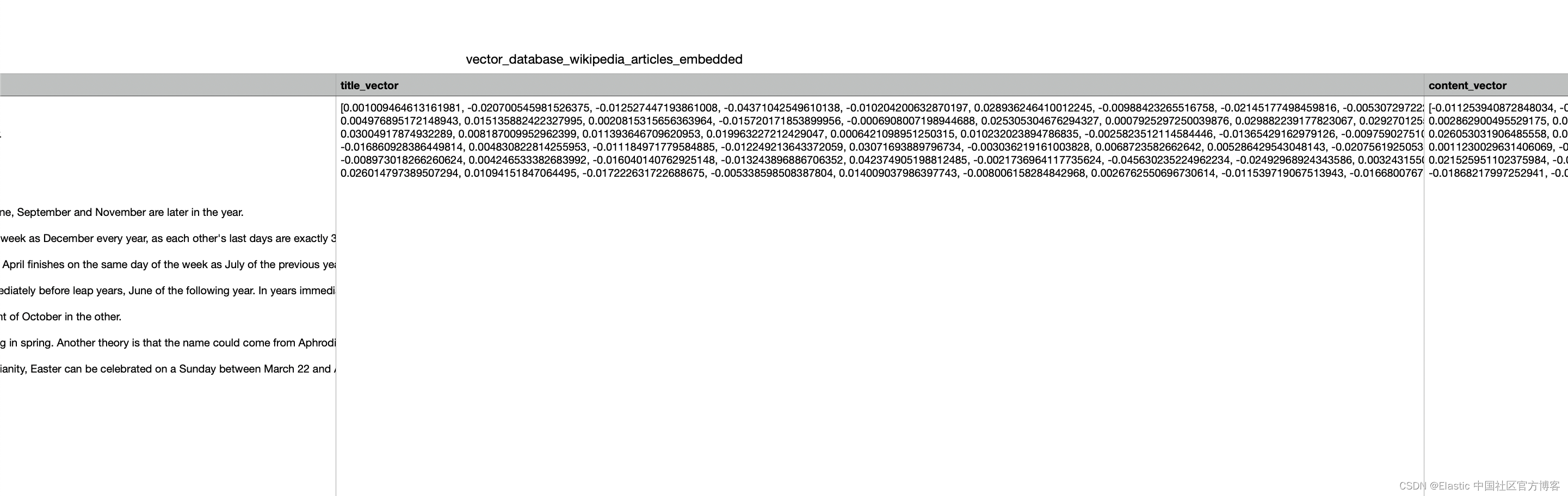
请注意 title_vector 及 content_vector 两个字段已经是以向量的形式来存储的。我们不需要额外的工作来对字段进行向量化。
将数据索引到 Elasticsearch
以下函数生成所需的批量操作,这些操作可以传递到 Elasticsearch 的 bulk API,因此我们可以在单个请求中有效地索引多个文档。
对于 DataFrame 中的每一行,该函数都会生成一个字典,表示要索引的单个文档。
def dataframe_to_bulk_actions(df):for index, row in df.iterrows():yield {"_index": 'wikipedia_vector_index',"_id": row['id'],"_source": {'url' : row["url"],'title' : row["title"],'text' : row["text"],'title_vector' : json.loads(row["title_vector"]),'content_vector' : json.loads(row["content_vector"]),'vector_id' : row["vector_id"]}}由于数据帧很大,我们将以 100 个为一组对数据进行索引。我们使用 Python 客户端的 bulk API 帮助程序将数据索引到 Elasticsearch 中。
total_documents = len(wikipedia_dataframe)progress_bar = tqdm(total=total_documents, unit="documents")
success_count = 0for ok, info in helpers.streaming_bulk(client, actions=dataframe_to_bulk_actions(wikipedia_dataframe), raise_on_error=False, chunk_size=100):if ok:success_count += 1else:print(f"Unable to index {info['index']['_id']}: {info['index']['error']}")progress_bar.update(1)progress_bar.set_postfix(success=success_count)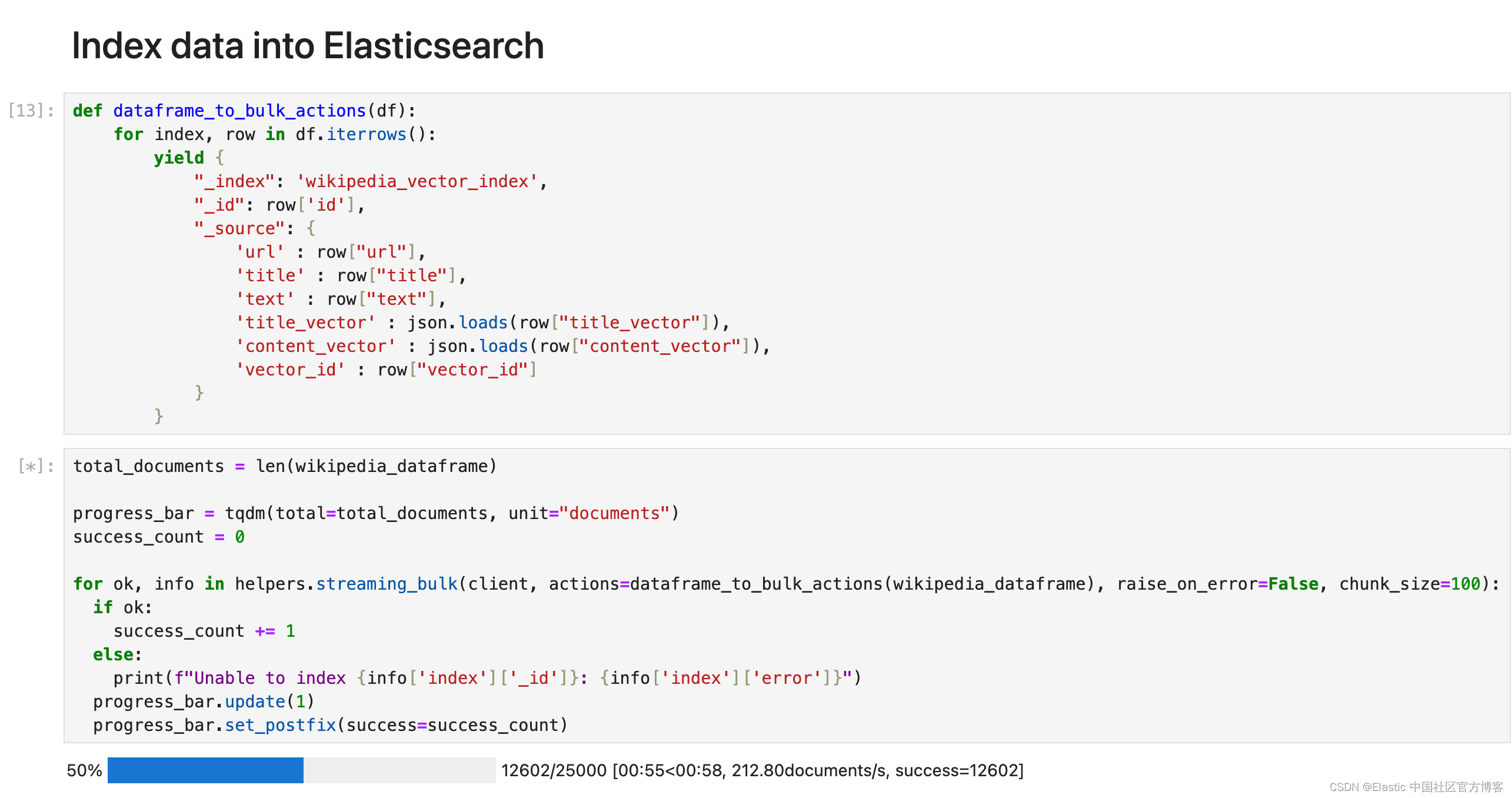
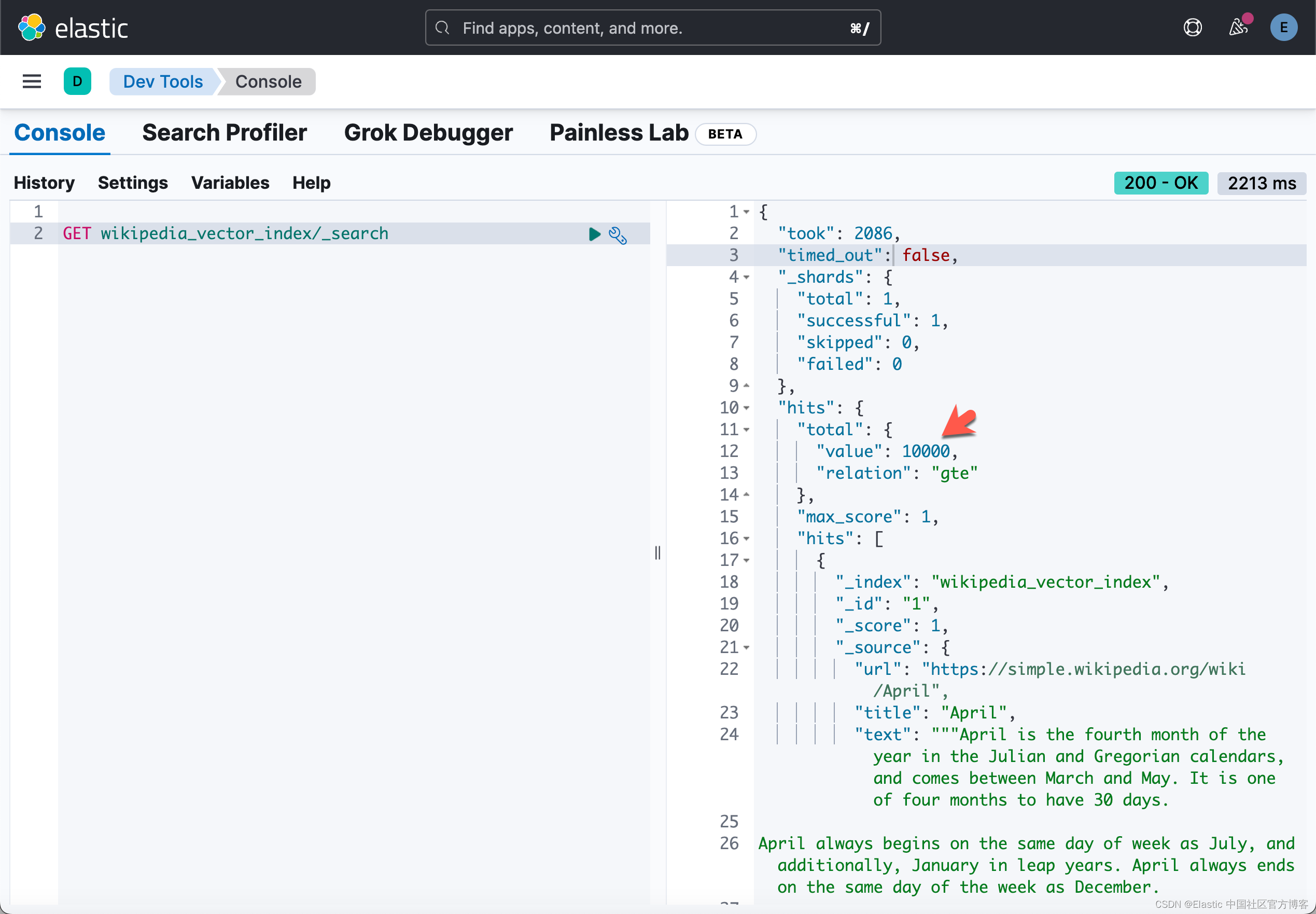
等上面的代码运行完毕后,我们可以在 Kibana 中进行查看:

使用 Streamlit 构建应用程序
在下一节中, 你将使用 Streamlit 构建一个简单的界面。
该应用程序将显示一个简单的搜索栏,用户可以在其中提出问题。 Elasticsearch 用于检索与问题匹配的相关文档(上下文),然后 OpenAI 使用上下文制定答案。
安装依赖项以在运行后访问应用程序。
!npm install localtunnel%%writefile app.pyimport os
import streamlit as st
import openai
from elasticsearch import Elasticsearch
from dotenv import load_dotenvfrom openai import OpenAIopenai = OpenAI()load_dotenv()openai_api_key=os.getenv('OPENAI_API_KEY')
elastic_user=os.getenv('ES_USER')
elastic_password=os.getenv('ES_PASSWORD')
elastic_endpoint=os.getenv("ES_ENDPOINT")url = f"https://{elastic_user}:{elastic_password}@{elastic_endpoint}:9200"
client = Elasticsearch(url, ca_certs = "./http_ca.crt", verify_certs = True)# Define model
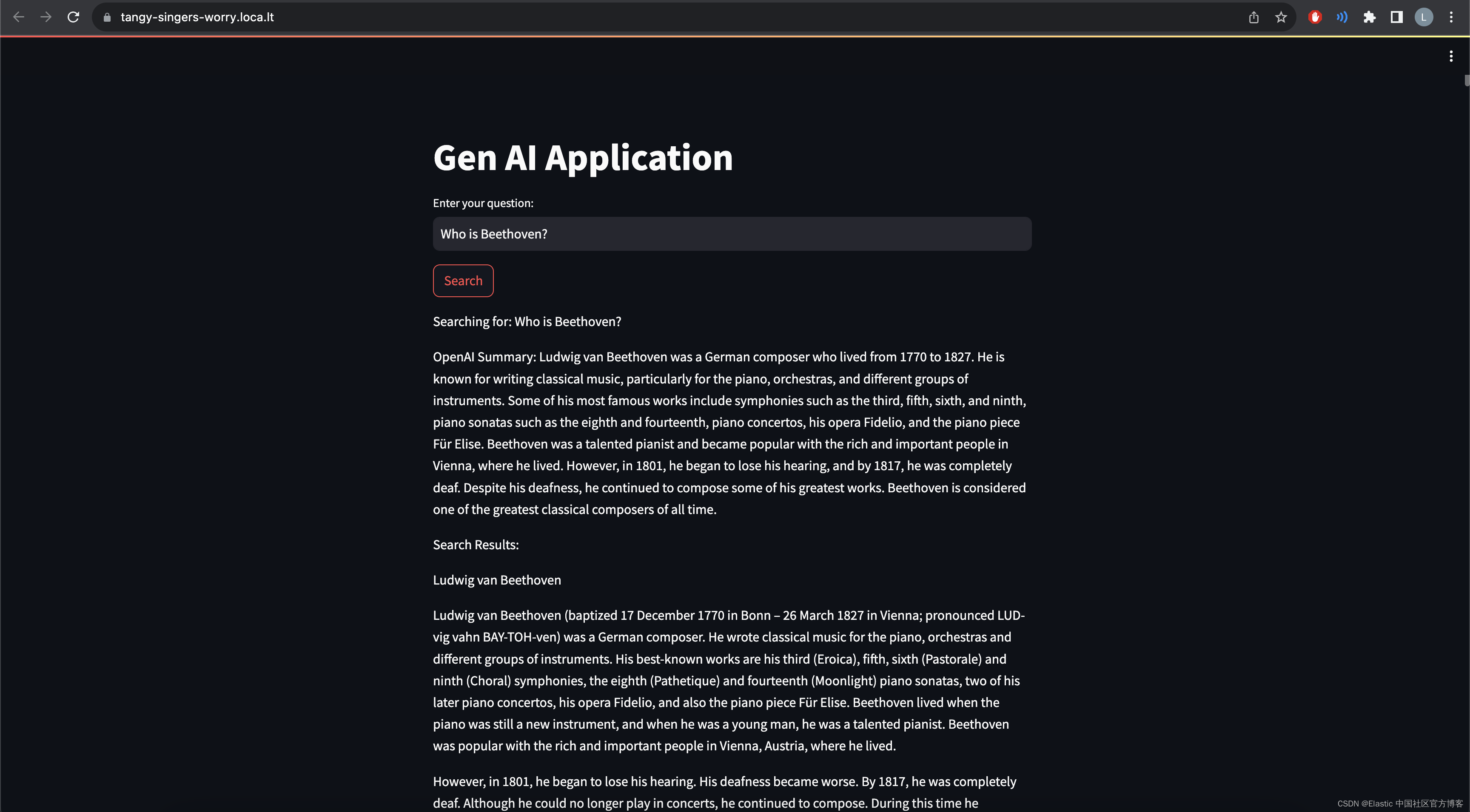
EMBEDDING_MODEL = "text-embedding-ada-002"def openai_summarize(query, response):context = response['hits']['hits'][0]['_source']['text']summary = openai.chat.completions.create(model="gpt-3.5-turbo",messages=[{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "Answer the following question:" + query + "by using the following text: " + context},])print(summary)return summary.choices[0].message.contentdef search_es(query):# Create embeddingquestion_embedding = openai.embeddings.create(input=query, model=EMBEDDING_MODEL)# Define Elasticsearch queryresponse = client.search(index = "wikipedia_vector_index",knn={"field": "content_vector","query_vector": question_embedding.data[0].embedding,"k": 10,"num_candidates": 100})return responsedef main():st.title("Gen AI Application")# Input for user search queryuser_query = st.text_input("Enter your question:")if st.button("Search"):if user_query:st.write(f"Searching for: {user_query}")result = search_es(user_query)# print(result)openai_summary = openai_summarize(user_query, result)st.write(f"OpenAI Summary: {openai_summary}")# Display search resultsif result['hits']['total']['value'] > 0:st.write("Search Results:")for hit in result['hits']['hits']:st.write(hit['_source']['title'])st.write(hit['_source']['text'])else:st.write("No results found.")if __name__ == "__main__":main()运行应用
运行应用程序并检查您的隧道 IP:
!streamlit run app.py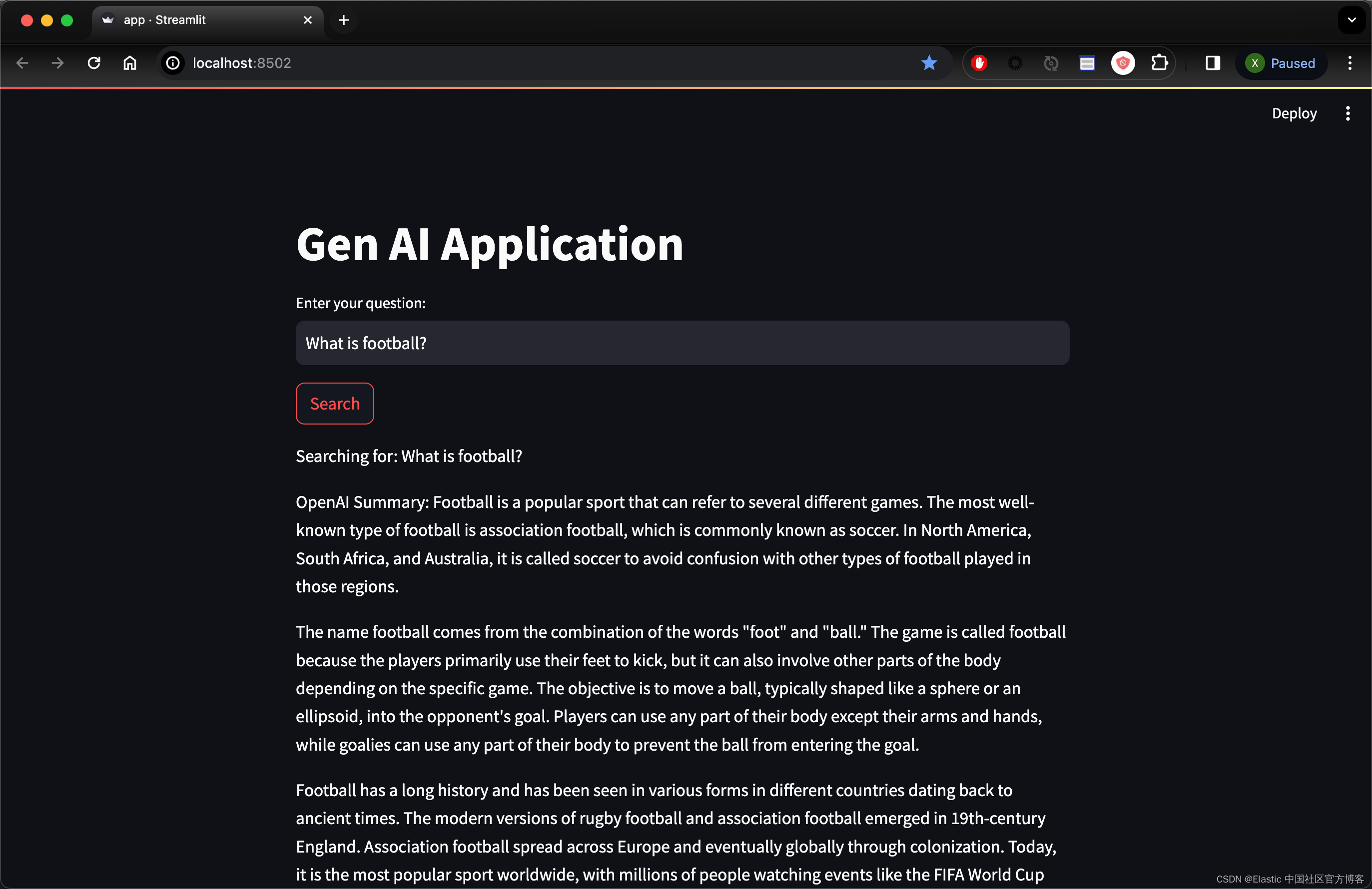
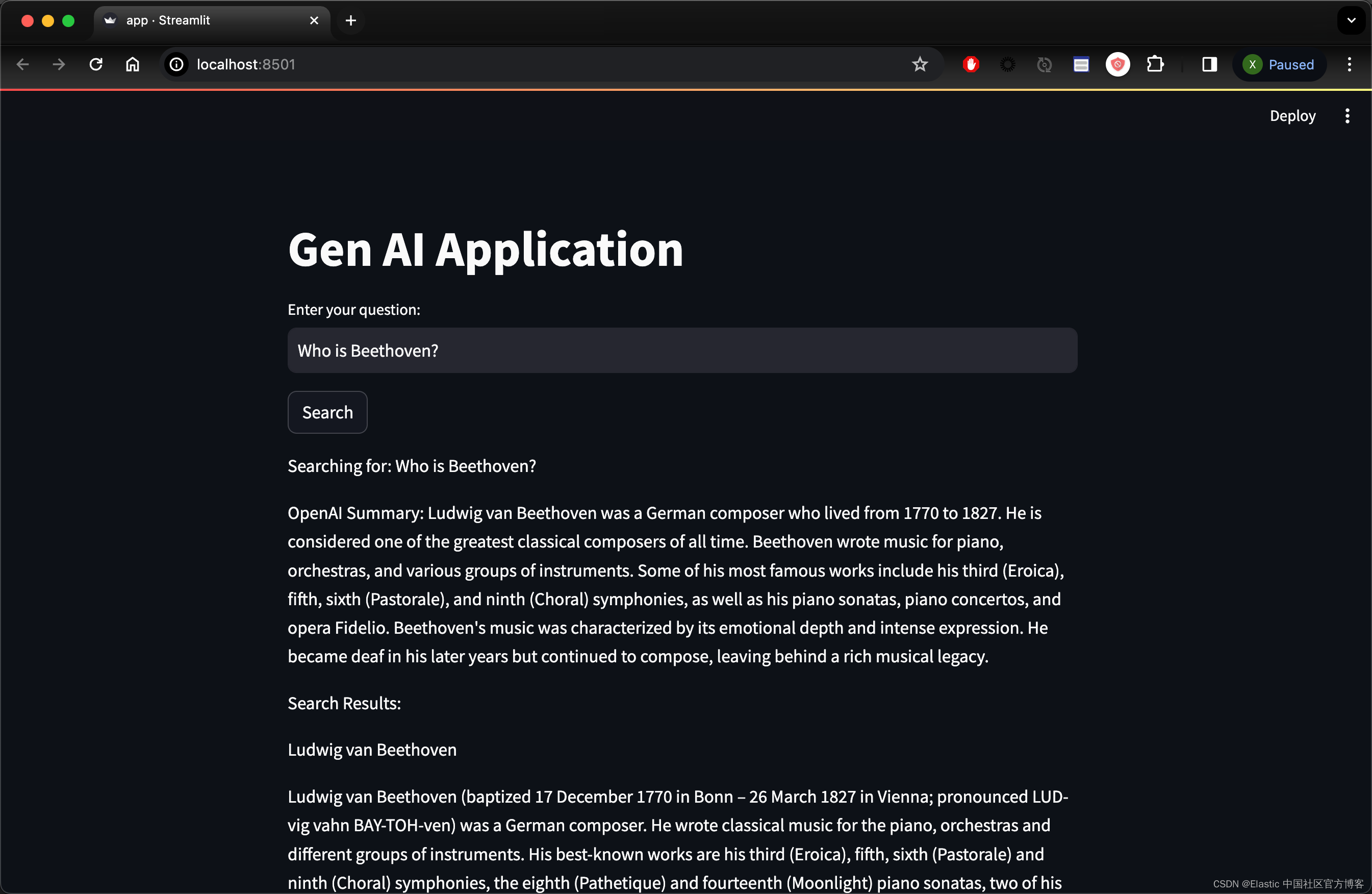
如果你想把网站供全网其它的电脑访问,你可以使用如下的命令:
npx localtunnel --port 8501整个 notebook 的源码可以在地址下载:https://github.com/liu-xiao-guo/semantic_search_es/blob/main/openai_rag_streamlit.ipynb