在搜狐快站上做网站怎么跳转长沙网站托管优化
开篇
本文整理自《python3 网络爬虫开发实战》的学习笔记。
笔记整理
match
match是一种常用的匹配方法,向它传入要匹配的字符串以及正则表达式,就可以检测这个正则表达式是否和字符串相匹配。
match会尝试从字符串的起始位置开始匹配正则表达式,如果匹配,就返回匹配成功的结果;如果不匹配,就返回None。
示例
import recontent = 'Hello 123 4567 World_This is a Regex Demo'
print(len(content))result = re.match('^Hello\s\d\d\d\s\d{4}\s\w{10}', content)
print(result)
# 匹配目标字符串
print(result.group())
# 匹配目标字符串的位置
print(result.span())

匹配目标
用match方法可以实现匹配,但如果想要从字符串中提取一部分内容,就可以使用括号()将想提取的子字符串括起来。()实际上标记了一个子表达式的开始和结束位置,被标记的每个子表达式依次对应每个分组,调用group方法传入分组的索引即可获取提取结果。
import recontent = "Hello 1234567 World_This is a Regex Demo"
result = re.match('^Hello\s(\d+)\sWorld', content)
print(result)
# 匹配目标字符串
print(result.group())
# 匹配目标字符串的被括号的内容
print(result.group(1))
print(result.span())

通用匹配
刚刚写的正则表达式比较复杂,只要出现空白字符就需要写\s匹配,出现数字就需要写\d匹,这样的工作量未免过大。
这时,便可以使用万能匹配,也就是.*。
它可以匹配除了换行符以外的任意字符,*代表前面的字符无限次,所以它们组合在一起就可以匹配任意字符了。
import recontent = 'Hello 123 4567 World_This is a Regex Demo'
result = re.match('^Hello.*Demo$', content)
print(result)
# 匹配目标字符串
print(result.group())
# 匹配目标字符串的位置
print(result.span())

贪婪与非贪婪
import recontent = 'Hello 1234567 World_This is a Regex Demo'
result = re.match('^He.*(\d+).*Demo$', content)
print(result)
# 匹配目标字符串
print(result.group(1))

问题指明:上面的结果是7,这很明显是不符合期望的。
说明原因:在贪婪匹配下,.*会匹配尽可能多的字符。而在.*后面是\d+,也就是至少一个数字。也就是.*在贪婪匹配的情况下,把123456都给匹配了,最后迫不得已给\d+留下了一个数字,也就是7。
但这样肯定是有问题的,要想取得预期中的1234567,就需要引入非贪婪的用法:
import recontent = 'Hello 1234567 World_This is a Regex Demo'
result = re.match('^He.*?(\d+).*Demo$', content)
print(result)
# 匹配目标字符串
print(result.group(1))
非贪婪的用法便是在.*的后面加一个?,这样便可以得到预期的结果了:

但是这里需要注意的一点是:字符串中间尽量使用非贪婪匹配,但是如果匹配的结果在字符串结尾,那么使用非贪婪模式有可能匹配不到任何内容:
import recontent = 'http://weibo.com/comment/kEraCN'
result1 = re.match('http.*?comment/(.*?)', content)
result2 = re.match('http.*?comment/(.*)', content)print(result1.group(1))
print(result2.group(1))
可以观察到,这里的.*?没有匹配到任何结果:

修饰符
import recontent = '''Hello 1234567 World_This
is a Regex Demo
'''result = re.match('^He.*?(\d+).*?Demo$', content)
print(result.group(1))
问题指明:因为.是匹配除了换行符以外的任意字符,所以遇到换行符时,.?就无法匹配了,导致失败。

这是,如果加一个修饰符,便可以避免这个错误:
import recontent = '''Hello 1234567 World_This
is a Regex Demo
'''result = re.match('^He.*?(\d+).*?Demo$', content, re.S)
print(result.group(1))

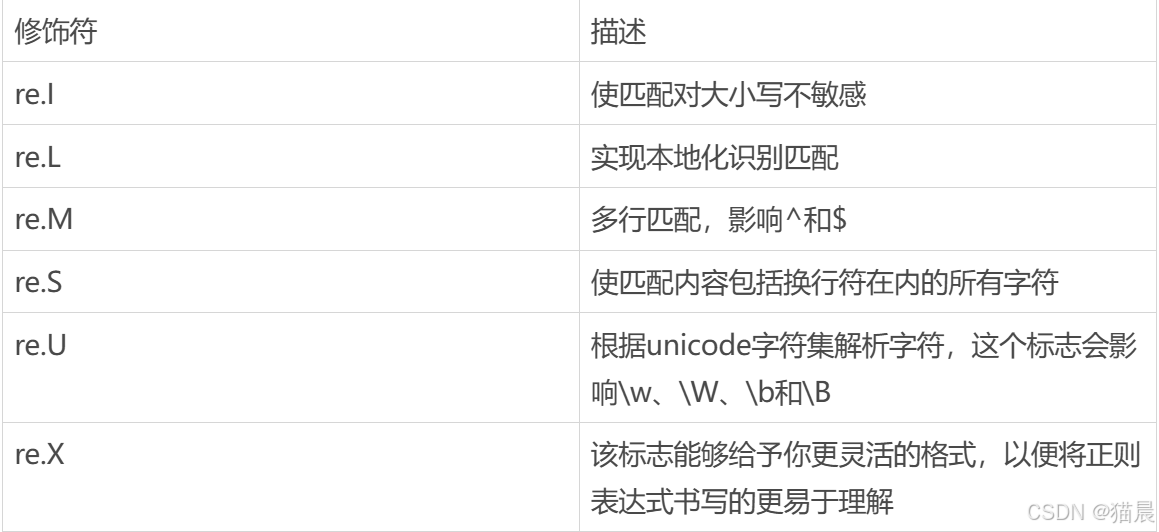
修饰符都有下面这些:
转义匹配
在正则表达式中,如.用于匹配除了换行符以外的任意字符。但如果目标字符串中就包含.这个字符,要怎么做呢?
答案:此处就需要用到转义字符了,也就是“\”。
import recontent = '(百度)www.baidu.com'
result = re.match('\(百度\)www\.baidu\.com', content)
print(result)
# 匹配目标字符串
print(result.group())

search
search方法在匹配时会扫描整个字符串,然后返回第一个匹配成功的结果。也就是说,正则表达式可以是字符串的一部分。
在匹配时,search方法会依次以每个字符作为开头扫描字符串,直到找到第一个符合规则的字符串,然后返回匹配内容;如果扫描完还没有找到符合规则的字符串,就返回None。
import recontent = 'Extra stings Hello 1234567 World_This is a Regex Demo Extra stings'
result = re.search('Hello.*?(\d+).*?Demo', content)
print(result)

findall
如果想要获取与正则表达式相匹配的所有字符串,那么就要借助findall方法了。
import retext = "苹果12个,香蕉20根,橙子15个"
results = re.findall(r'(\d+)', text)
print(results)

sub
除了使用正则表达式提取信息,有时还需要借助它来修改文本。例如,想要把一串文本中的所有数字都去掉,如果只用字符串的replace方法,未免太繁琐了,这时就可以借助sub方法。
import retext = "这个密码是12345,请勿泄露!"
result = re.sub(r'\d+', '******', text)
print(result)

compile
前面所讲的方法都是用来处理字符串的方法,最后再介绍一下compile方法,这个方法可以将正则字符串编译成正则表达式对象,以便在后面的匹配中复用。
import retext = "Hello World! HELLO Python."
pattern = re.compile(r'\bhello\b', re.IGNORECASE)
result = pattern.sub('hi', text)
print(result)
综合案例
import retext = "价格:¥99.5 折扣价:¥66.8"
pattern = re.compile(r'¥(\d+\.\d+)')#提取价格
prices = pattern.findall(text)
print(prices)# 将符号换为美元
new_text = pattern.sub('$\\1', text)
print(new_text)

注
以上便是本次文章的所有笔记整理了,希望对您也能有所帮助!