怎么样做国际网站生意网站意义
(一)Spark概述
Apache Spark 是一个快速、通用、可扩展的大数据处理分析引擎。它最初由加州大学伯克利分校 AMPLab 开发,后成为 Apache 软件基金会的顶级项目。Spark 以其内存计算的特性而闻名,能够在内存中对数据进行快速处理,相较于传统基于磁盘的计算框架,大大提高了数据处理的速度。
(二)Hadoop概述
Hadoop 是一个由 Apache 基金会开发的开源的分布式系统基础架构,旨在处理大规模数据的存储和处理。它最初由 Doug Cutting 和 Mike Cafarella 开发,灵感来自于 Google 的 MapReduce 和 Google File System(GFS)论文。Hadoop 为大数据处理提供了一个可靠、高效且可扩展的平台,被广泛应用于各种领域,如互联网公司、金融机构、科研单位等,用于处理海量的结构化、半结构化和非结构化数据。
(三)Hadoop 和 Spark 作为大数据处理领域的重要工具,它们之间存在着紧密的联系
- 存储层面:Spark 可以直接使用 Hadoop 分布式文件系统(HDFS)作为其数据存储后端。HDFS 为 Spark 提供了高可靠、可扩展的分布式存储能力,使得 Spark 能够处理存储在 HDFS 上的大规模数据。无论是批处理、流处理还是机器学习任务,Spark 都可以从 HDFS 中读取数据,并将处理结果写回到 HDFS 中。这样,Spark 可以充分利用 HDFS 的优点,如数据冗余、自动容错等,同时专注于数据的计算和处理。
- 计算层面:Spark 的计算模型与 Hadoop 的 MapReduce 有一定的相似性和互补性。虽然 Spark 的核心是基于内存的计算,采用了更先进的 DAG(有向无环图)执行引擎,能够更高效地处理复杂的计算任务,但它也可以借鉴 MapReduce 的一些思想。例如,Spark 中的 RDD(弹性分布式数据集)转换操作类似于 MapReduce 中的 Map 和 Reduce 操作,Spark 可以将一些复杂的计算任务分解为多个类似于 Map 和 Reduce 的阶段,进行分布式并行计算。此外,Spark 还可以与 Hadoop 的 YARN 资源管理器集成,利用 YARN 来管理集群资源,实现任务的调度和分配。这使得 Spark 能够在 Hadoop 集群上运行,充分利用 Hadoop 的资源管理和调度能力,同时发挥自身的计算优势。
- 生态系统层面:Hadoop 拥有庞大的生态系统,包括 Hive、Pig、HBase 等众多组件,而 Spark 也有自己的生态系统,如 Spark SQL、Spark Streaming、MLlib 等。Spark 可以与 Hadoop 生态系统中的其他组件进行无缝集成。例如,Spark SQL 可以与 Hive 集成,使用 Hive 的元数据和 SQL 解析器,实现对 Hive 表的查询和处理;Spark Streaming 可以与 Kafka 等消息队列集成,实现实时流数据的处理。通过这种集成,用户可以在一个统一的大数据平台上,结合 Hadoop 和 Spark 的各种组件,根据不同的业务需求选择合适的工具和技术,构建复杂的大数据处理和分析系统。
(三)Spark与Hadoop的区别
处理速度上
Hadoop:Hadoop MapReduce 基于磁盘进行数据处理,数据在 Map 和 Reduce 阶段会频繁地写入磁盘和读取磁盘,这使得数据处理速度相对较慢,尤其是在处理迭代式算法和交互式查询时,性能会受到较大影响。
Spark:Spark 基于内存进行计算,能将数据缓存在内存中,避免了频繁的磁盘 I/O。这使得 Spark 在处理大规模数据的迭代计算、交互式查询等场景时,速度比 Hadoop 快很多倍。例如,在机器学习和图计算等需要多次迭代的算法中,Spark 可以显著减少计算时间。
编程模型上
Hadoop:Hadoop 的 MapReduce 编程模型相对较为底层和复杂,开发人员需要编写大量的代码来实现数据处理逻辑,尤其是在处理复杂的数据转换和多阶段计算时,代码量会非常庞大,开发和维护成本较高。
Spark:Spark 提供了更加简洁、高层的编程模型,如 RDD(弹性分布式数据集)、DataFrame 和 Dataset 等。这些抽象使得开发人员可以用更简洁的代码来实现复杂的数据处理任务,同时 Spark 还支持多种编程语言,如 Scala、Java、Python 等,方便不同背景的开发人员使用。
实时性处理上
Hadoop:Hadoop 主要用于批处理任务,难以满足实时性要求较高的数据处理场景,如实时监控、实时推荐等。
Spark:Spark Streaming 提供了强大的实时数据处理能力,它可以将实时数据流分割成小的批次进行处理,实现准实时的数据分析。此外,Spark 还支持 Structured Streaming,提供了更高级的、基于 SQL 的实时流处理模型,使得实时数据处理更加容易和高效。
HadoopMR框架,从数据源获取数据,经过分析计算之后,将结果输出到指定位置,核心是一次计算,不适合迭代计算。
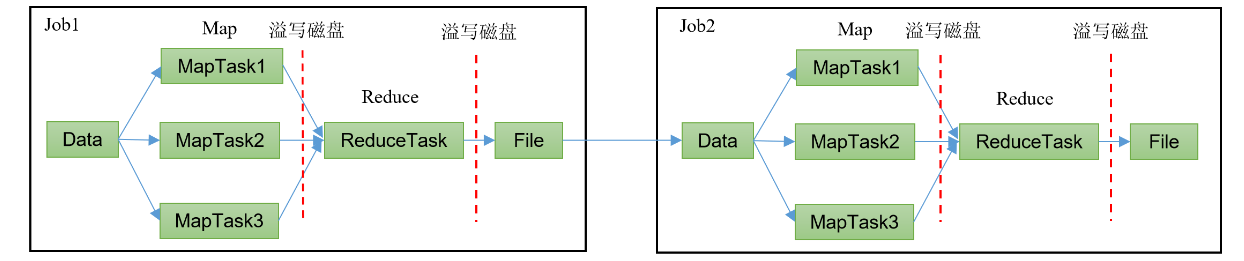
Spark框架,支持迭代式计算,图形计算
