郑州互助盘网站开发网站注册登录
文章目录
- 1. Python程序改写
- 2. 扣子中的代码配置
- 3. 测试运行情况
1. Python程序改写
这里博主以一个示例“抓取财联社的新闻”为例子:
#!/usr/bin/env Python
# coding=utf-8import pandas as pd
import requestsdef get_url_by_request(url, params=None):"""获取指定URL的响应数据"""headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ""Chrome/114.0.0.0 Safari/537.36"}response = requests.get(url, params=params, headers=headers)if response.status_code == 200:data = response.json()return data['data']def stock_info_global_cls():"""财联社-电报:https://www.cls.cn/telegraph """url = "https://www.cls.cn/nodeapi/telegraphList"data_json = get_url_by_request(url)['roll_data']temp_df = pd.DataFrame(data_json)big_df = temp_df.copy()big_df = big_df[["title", "content", "ctime", "level"]]big_df["ctime"] = pd.to_datetime(big_df["ctime"], unit="s", utc=True).dt.tz_convert("Asia/Shanghai")big_df["content"] = big_df["content"].str.replace(r'【[^】]*】', '', regex=True)big_df.sort_values(["ctime"], inplace=True)big_df.reset_index(inplace=True, drop=True)big_df["release_date"] = big_df["ctime"].dt.datebig_df["release_time"] = big_df["ctime"].dt.timebig_df = big_df[['release_date', "release_time", "title", "content", "level"]]return big_df.to_dict(orient="records")stock_info_global_cls()
得到的数据如下:
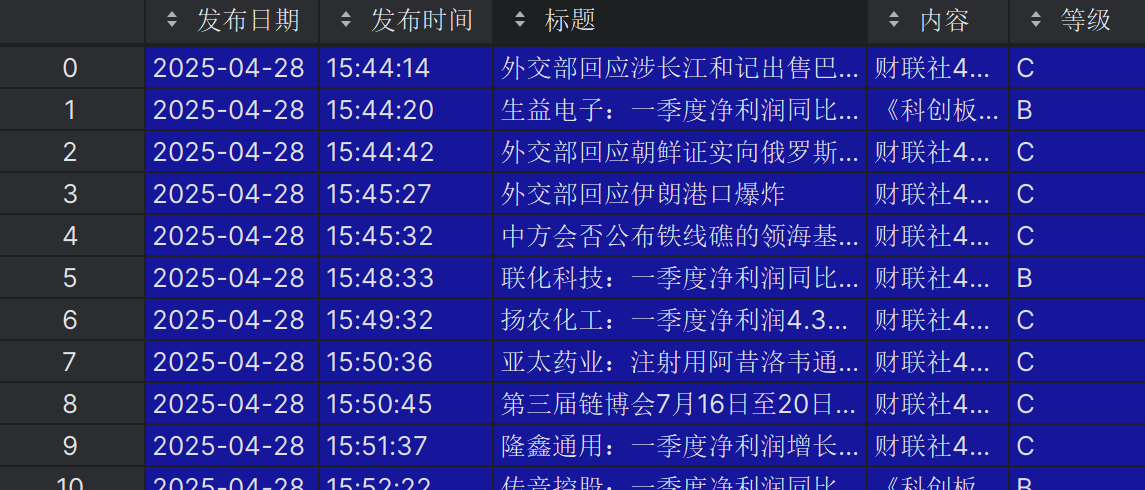
因为扣子的IDE无法debug,功能也不齐全,因此在Pycharm或vscode中将上述代码改写,使用极简必要的模块,返回一个list或dict:
import requests
import time
import redef get_url_by_request(url, params=None):"""获取指定URL的响应数据"""headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ""Chrome/114.0.0.0 Safari/537.36"}response = requests.get(url, params=params, headers=headers)if response.status_code == 200:data = response.json()return data['data']def get_cls_telegraph():"""财联社-电报:https://www.cls.cn/telegraph """url = "https://www.cls.cn/nodeapi/telegraphList"data_json = get_url_by_request(url)['roll_data']collect_data = []for _data in data_json:_local_time = time.localtime(_data['ctime'])collect_data.append({"release_date": time.strftime("%Y-%m-%d", _local_time),"release_time": time.strftime("%H:%M:%S", _local_time),"title": _data['title'],"content": re.sub(r'【[^】]*】', '', _data['content']),"level": _data['level'],})return collect_data
测试一下,得到如下结果:
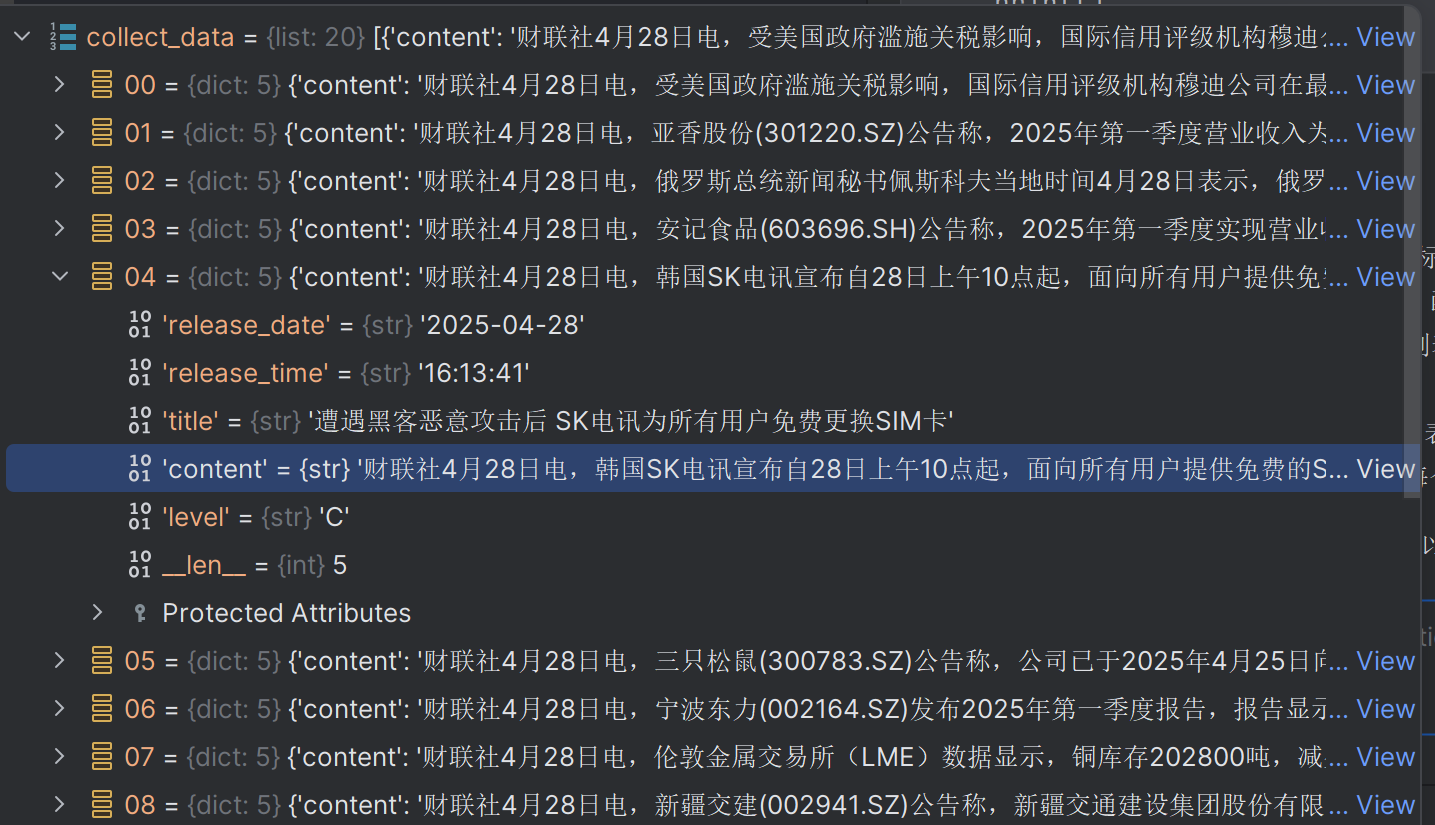
然后就可以将上述代码直接应用于扣子了
2. 扣子中的代码配置
- 首先,登录扣子,进入【资源库】,点击右上角【+资源】,选择【云端插件-在Coze IDE中创建】
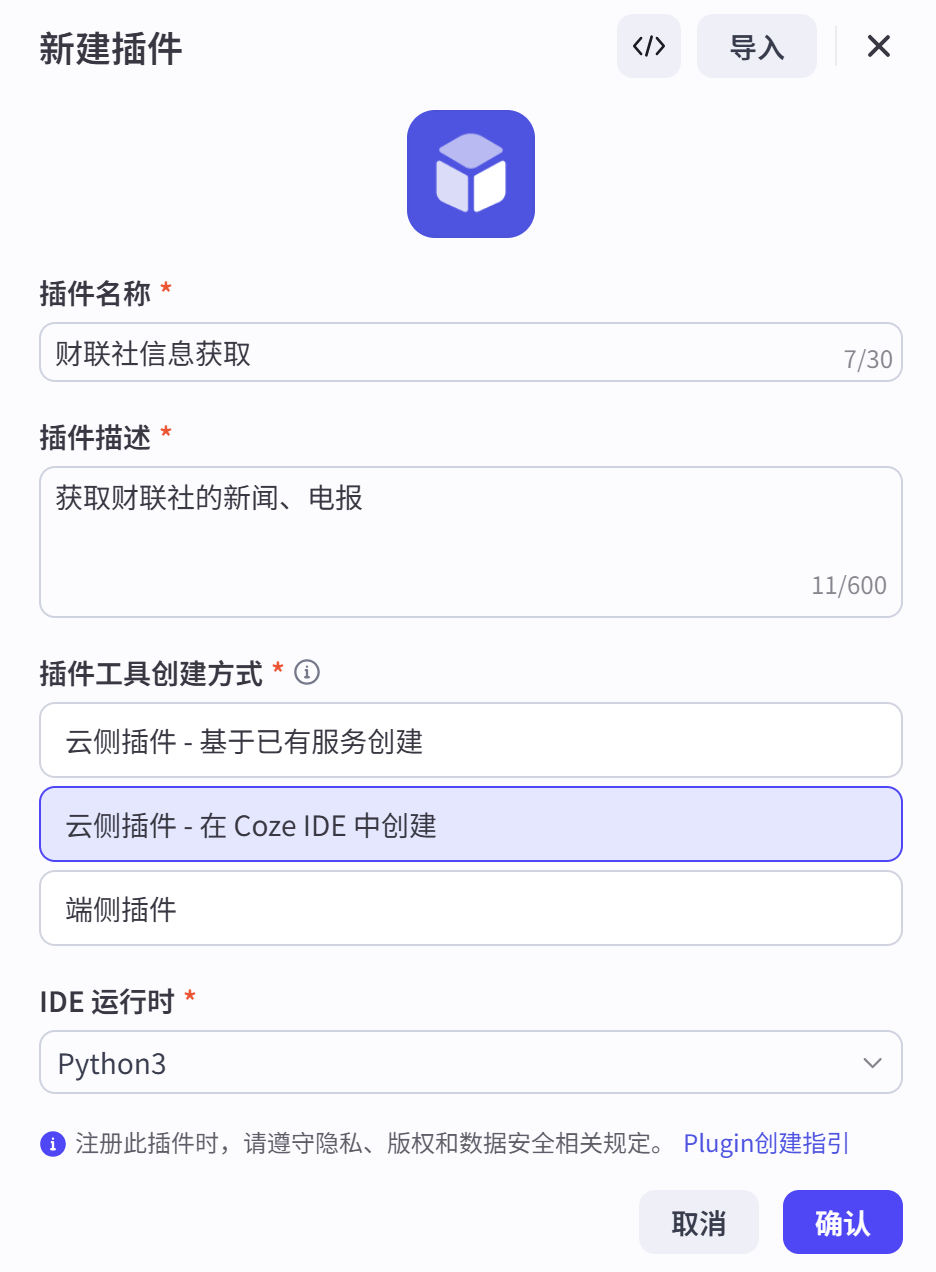
创建成功后,点击右上角【在IDE中创建工具】
- 点击【创建工具】,即可新建一个功能。在右边的代码编辑界面可以看到一个简单的示例:
from runtime import Args
from typings.check.check import Input, Outputdef handler(args: Args[Input])->Output:return {"message": "Hello, world!"}
这个handler为固定的写法,这些不动,我们把代码直接粘进来:
from runtime import Args
from typings.check.check import Input, Output
import requests
import time
import redef get_url_by_request(url, params=None):"""获取指定URL的响应数据"""headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ""Chrome/114.0.0.0 Safari/537.36"}response = requests.get(url, params=params, headers=headers)if response.status_code == 200:data = response.json()return data['data']def get_cls_telegraph():"""财联社-电报:https://www.cls.cn/telegraph """url = "https://www.cls.cn/nodeapi/telegraphList"data_json = get_url_by_request(url)['roll_data']collect_data = []for _data in data_json:_local_time = time.localtime(_data['ctime'])collect_data.append({"release_date": time.strftime("%Y-%m-%d", _local_time),"release_time": time.strftime("%H:%M:%S", _local_time),"title": _data['title'],"content": re.sub(r'【[^】]*】', '', _data['content']),"level": _data['level'],})return collect_datadef handler(args: Args[Input])->Output:return {"telegram_infos":get_cls_telegraph()}
左下角,要引入requests包,点击试运行,即可得到结果,整体的页面信息如下:
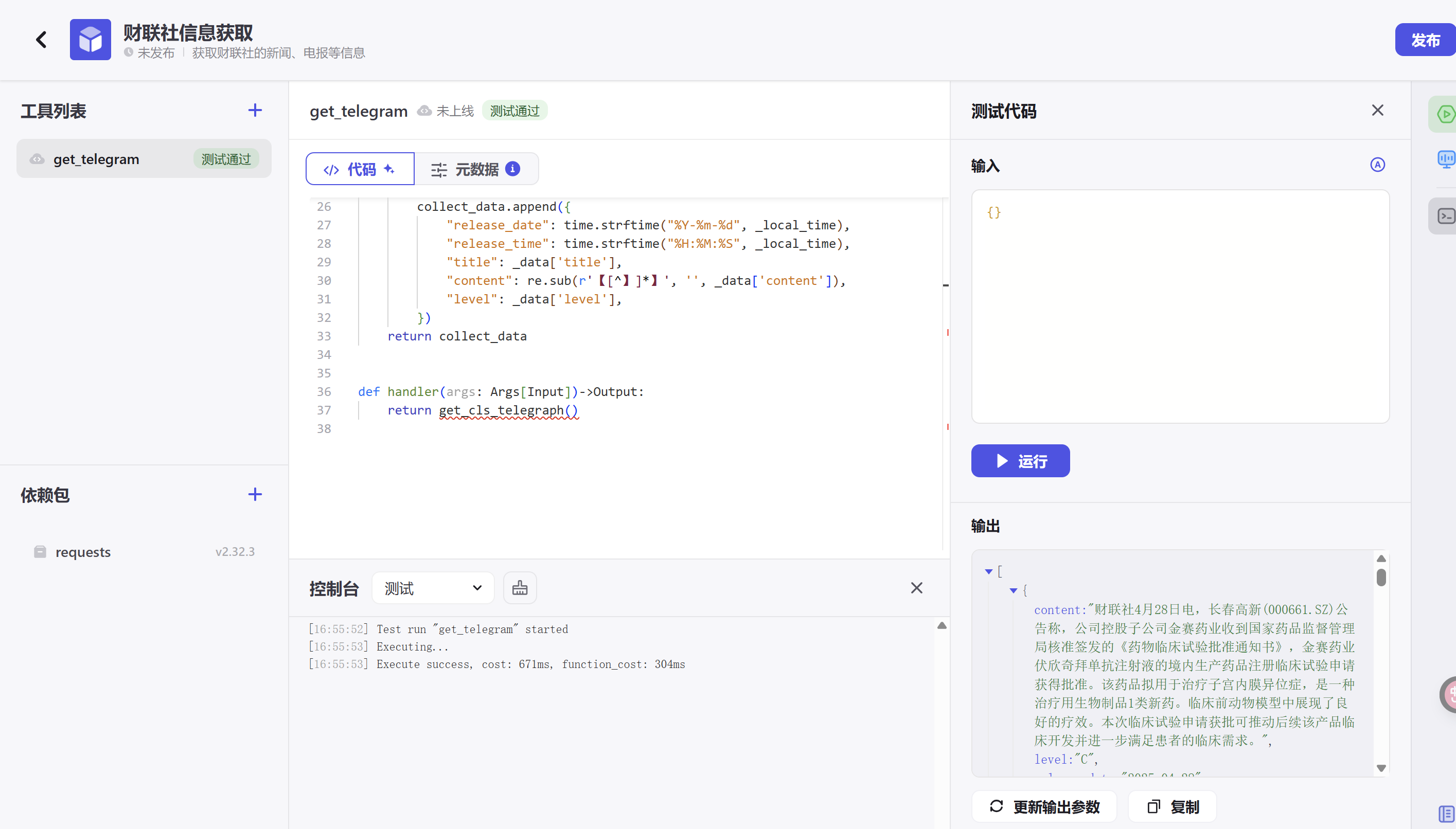
3. 测试通过后,点击右下角【更新输出参数】,自动配置元数据。然后点击【元数据】,补充更多信息,如:
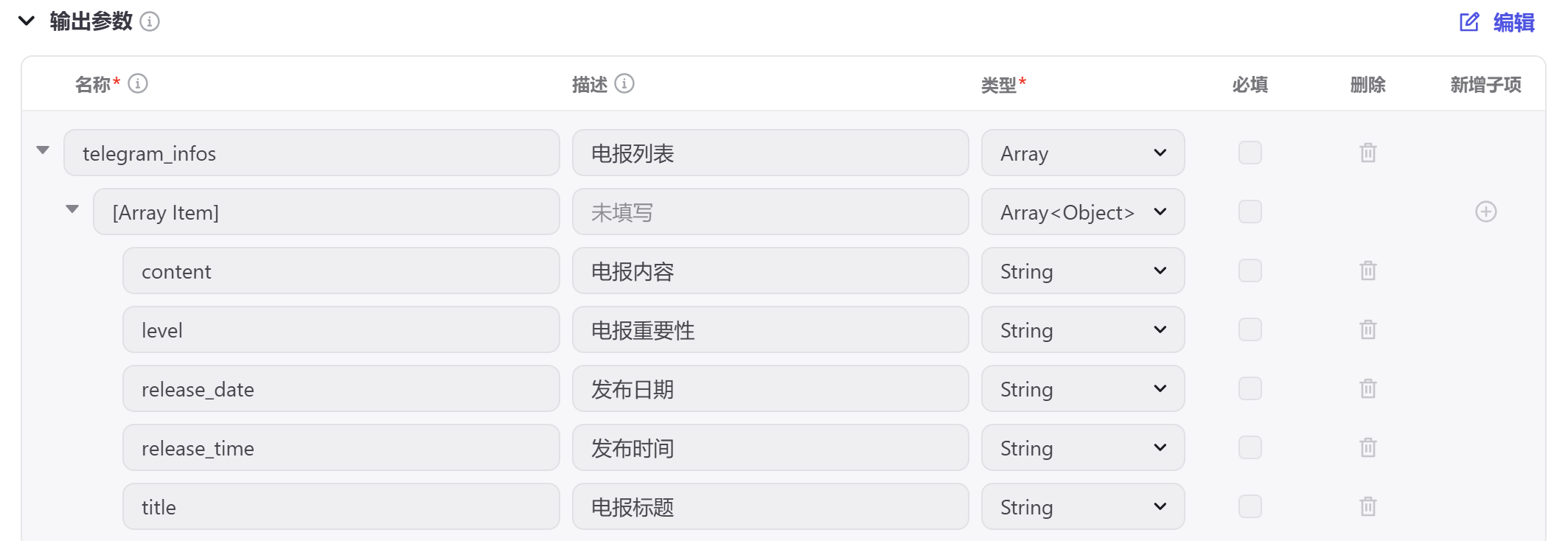
4. 点击右上角【发布】,点击【下一步】,这里就算发布完成!
3. 测试运行情况
退出IDE编辑界面,在插件的主界面,这个功能拉倒右边有个小按钮【运行示例】,点击后得到如下结果:
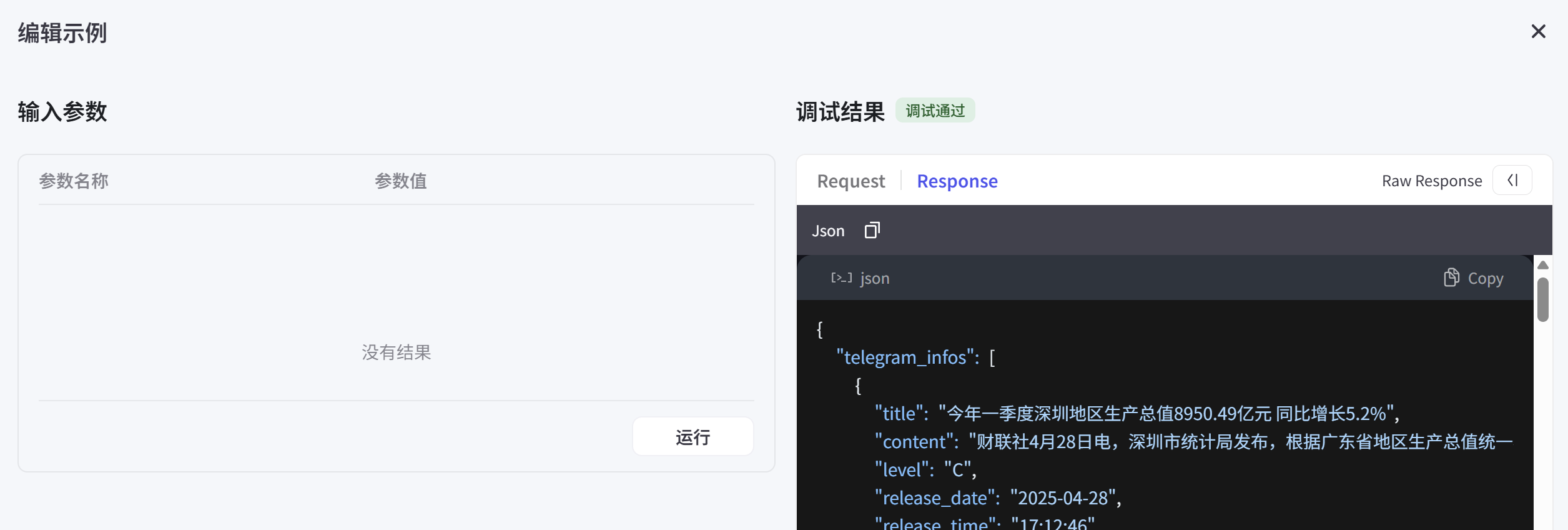
这样就成功啦!