门户网站开发的意义几年做啥网站能致富
CrawlSpider是Scrapy框架中一个非常实用的爬虫基类,它继承自Spider
类,主要用于实现基于规则的网页爬取。相较于普通的Spider类,CrawlSpider
可以根据预定义的规则自动跟进页面中的链接,从而实现更高效、更灵活的爬取。
Scrapy 创建CrawlSpider爬虫
目标网址:http://quotes.toscrape.com/
目标:匹配top10标签里面的所有quote
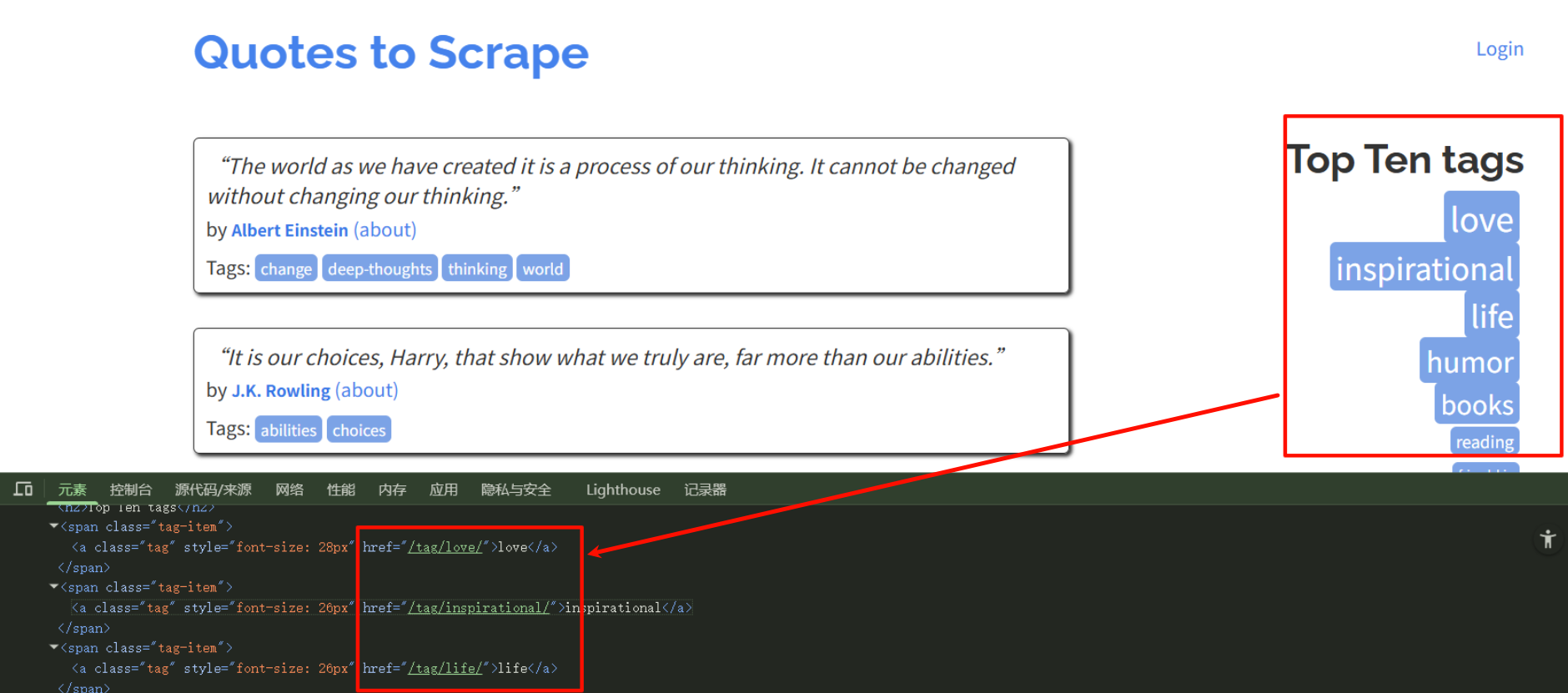
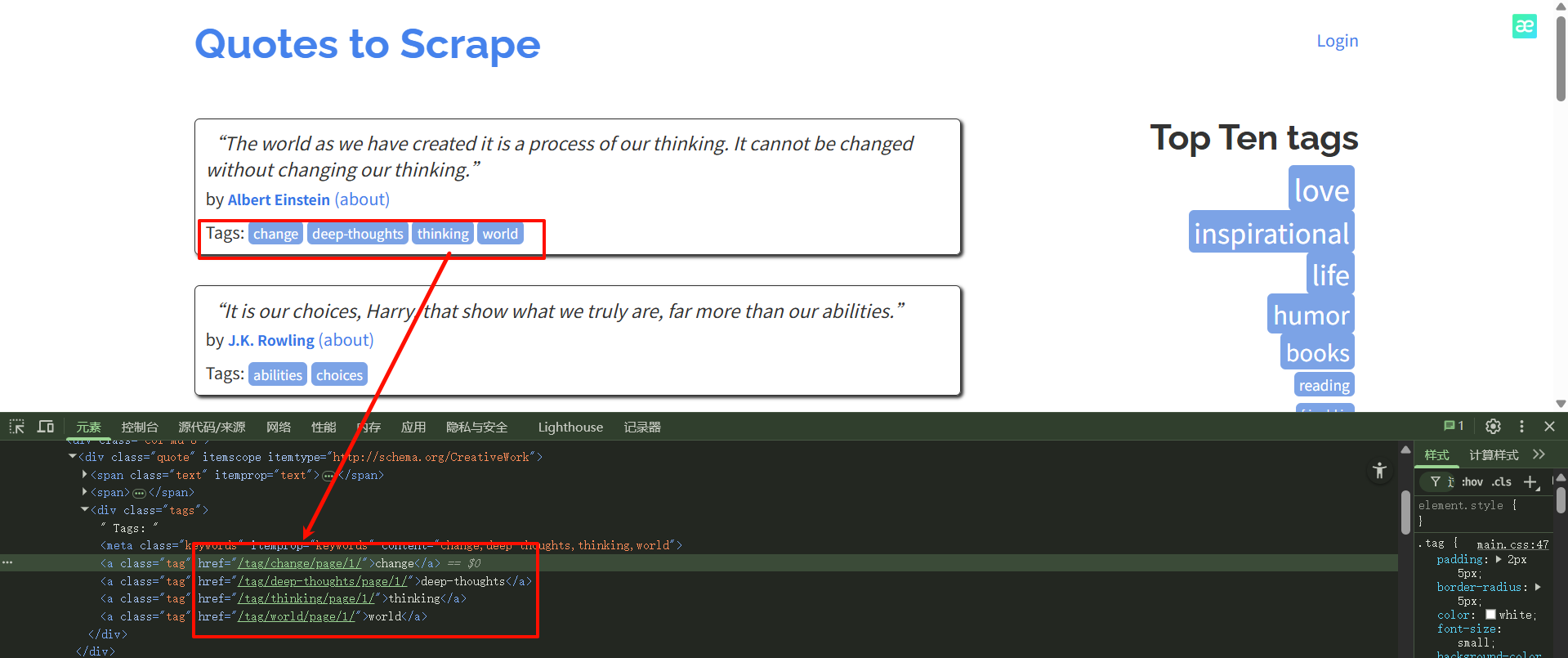
观察其他的URL链接,这些都是干扰,我们只需要匹配top10里面的链接,所有需要编写正则表达式来匹配
1.创建 Scrapy 项目:在命令行输入scrapy startproject myproject,这里的myproject是项目名。
2.进入项目目录:输入cd myproject。
3.创建 CrawlSpider:输入scrapy genspider -t crawl myspider example.com,myspider是爬虫名,example.com是初始爬取的域名。
scrapy genspider -t crawl quotes quotes.toscrape.com
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Ruleclass QuotesSpider(CrawlSpider):name = "quotes"allowed_domains = ["quotes.toscrape.com"]start_urls = ["http://quotes.toscrape.com/"]rules = (Rule(LinkExtractor(allow=r'/tag/[a-z]+/$'), callback='parse_tag', follow=False),)def parse_tag(self, response):tag_url = response.urlprint(f"Extracted tag URL: {tag_url}")
rules:是一个元组,包含一个或多个Rule对象,每个Rule对象定义了一个爬取规则。LinkExtractor(allow=r'/tag/[a-z]+/$'):创建一个LinkExtractor对象,使用正则表达式r'/tag/[a-z]+/$'来提取符合规则的链接。该正则表达式的含义是:匹配含/tag/的链接,后面跟着一个或多个小写字母,最后以/结尾的链接。callback='parse_tag':当LinkExtractor提取到符合规则的链接并访问该链接对应的页面后,会调用parse_tag方法来处理该页面。follow=False:表示不跟进从当前页面提取的符合规则的链接。也就是说,爬虫只会处理当前页面中符合规则的链接,不会继续深入这些链接对应的页面去提取更多链接。
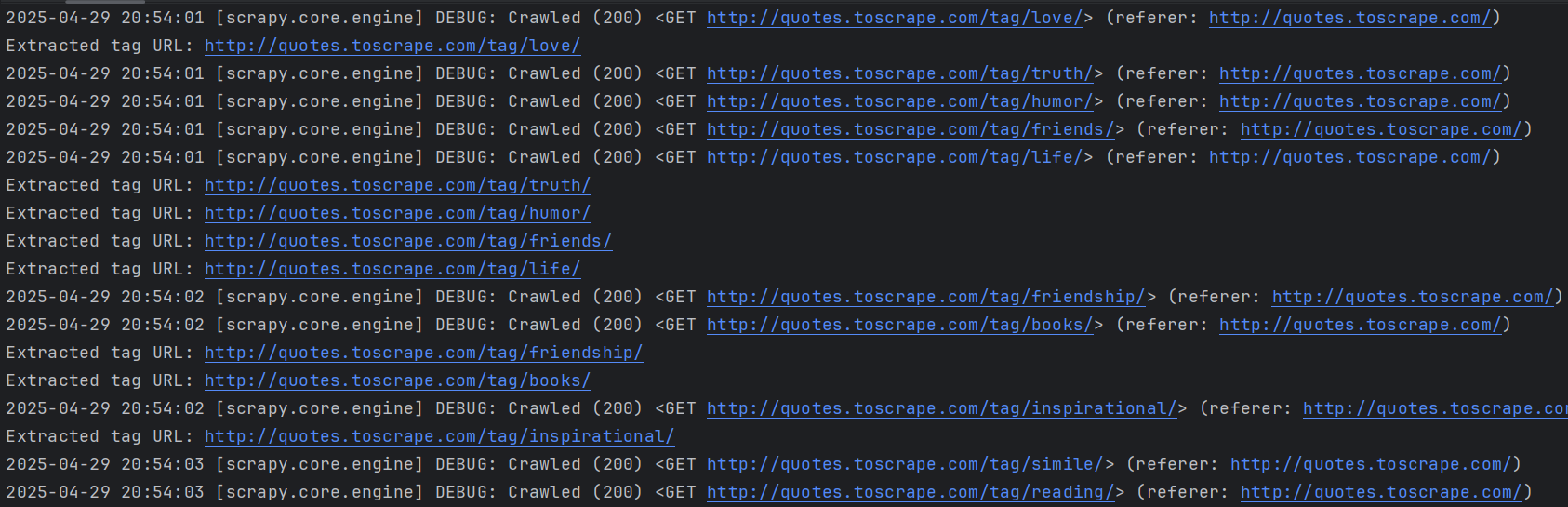
可以看到爬取的就是top10的
相对 URL 和绝对 URL 的差异: Scrapy 的
LinkExtractor在处理链接时,处理的是绝对 URL 而非 HTML 中的相对 URL。要是你的正则表达式是基于相对 URL 来写的,就可能会匹配失败。比如,HTML 里的相对 URL 是/tag/inspirational/,但 Scrapy 处理时会把它变成绝对 URLhttp://quotes.toscrape.com/tag/inspirational/
因此r'^/tag/[a-z]+/$'就无法匹配,因为绝对 URL 是以http://开头的,并非/tag/。
或者改为这样也是可以的r'^http://quotes.toscrape.com/tag/[a-z]+/$'
接下来我们继续跟进,将follow=True。进入这些标签页面进一步爬取详情内容
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Ruleclass QuotesSpider(CrawlSpider):name = "quotes"allowed_domains = ["quotes.toscrape.com"]start_urls = ["http://quotes.toscrape.com/"]rules = (Rule(LinkExtractor(allow=r'/tag/[a-z]+/$'), callback='parse_tag', follow=True),)def parse_tag(self, response):# 打印当前页面的URLtag_url = response.urlprint(f"Extracted tag URL: {tag_url}")# 提取名言和作者quotes = response.css('div.quote')for quote in quotes:text = quote.css('span.text::text').get()author = quote.css('small.author::text').get()print(f"Quote: {text}, Author: {author}")
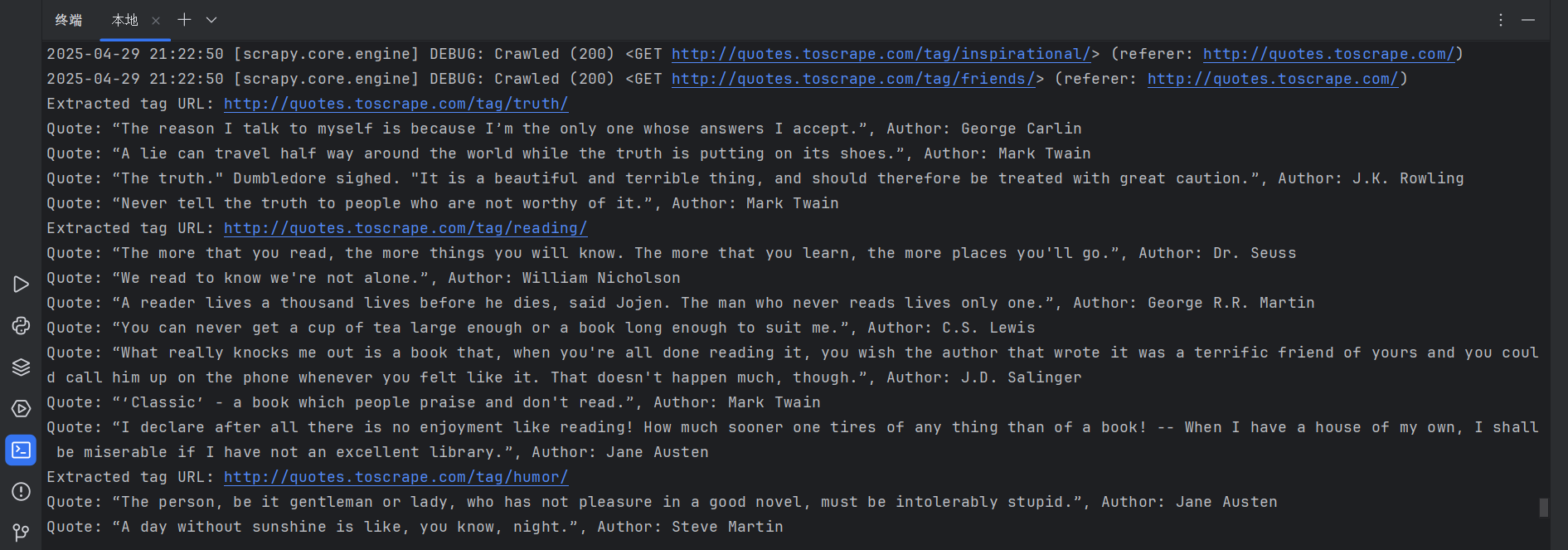
翻页逻辑
有的标签类别不止一页数据,例如
http://quotes.toscrape.com/tag/love/page/2/
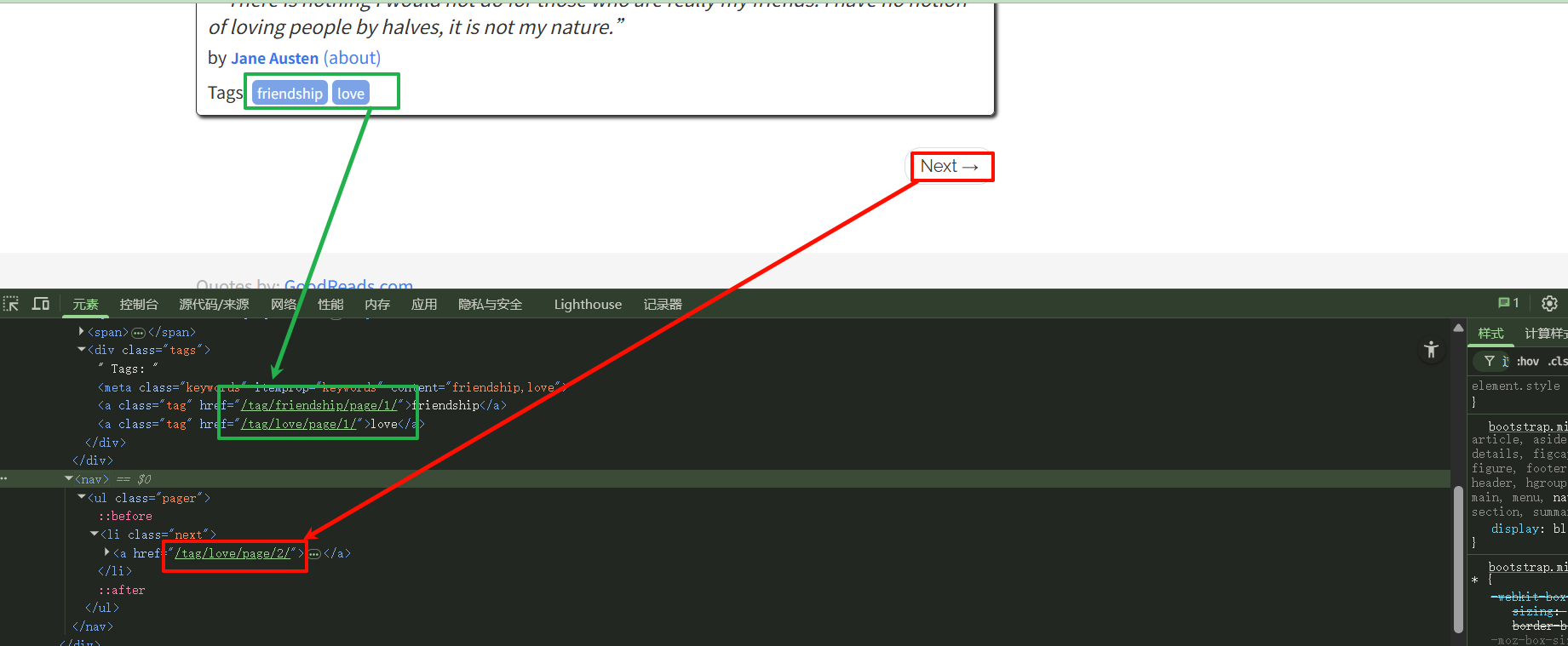
可以看到我们只需要匹配next里面链接,其他的为干扰。我们可以使用更精确的 CSS 选择器来配合 LinkExtractor
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Ruleclass QuotesSpider(CrawlSpider):name = "quotes"allowed_domains = ["quotes.toscrape.com"]start_urls = ["http://quotes.toscrape.com/"]rules = (# 规则1:提取所有标签链接Rule(LinkExtractor(allow=r'/tag/[a-z]+/$'), callback='parse_tag', follow=True),# 规则2:使用CSS选择器提取<li>标签下的分页链接Rule(LinkExtractor(restrict_css='li.next a'), callback='parse_tag', follow=True),)def parse_tag(self, response):# 打印当前页面的URLtag_url = response.urlprint(f"Extracted tag URL: {tag_url}")# 提取名言和作者quotes = response.css('div.quote')for quote in quotes:text = quote.css('span.text::text').get()author = quote.css('small.author::text').get()print(f"Quote: {text}, Author: {author}")
如果 Rule(LinkExtractor(restrict_css=‘li.next a’), callback=‘parse_tag’,
follow=False)
那么爬虫只会处理当前页面中提取到的分页链接对应的页面,而不会进一步去跟进这些页面中的其他分页链接,所以只能获取到第二页的数据,无法获取到第二页之后的页面数据。
还可以使用 XPath 提取
rules = (# 规则1:提取所有标签链接Rule(LinkExtractor(allow=r'/tag/[a-z]+/$'), callback='parse_tag', follow=True),# 规则2:使用CSS选择器提取<li>标签下的分页链接Rule(LinkExtractor(restrict_css='li.next a'), callback='parse_tag', follow=True),# 规则3:使用XPath提取<li>标签下的分页链接Rule(LinkExtractor(restrict_xpaths='//li[@class="next"]/a'), callback='parse_tag', follow=True),)
Scrapy 内部有一个链接去重机制,默认使用 scrapy.dupefilters.RFPDupeFilter 来过滤重复的请求。当 LinkExtractor 提取到链接后,Scrapy 会先检查这个链接是否已经在请求队列中或者已经被处理过,如果是,就不会再次发起请求。
规则 2 和规则 3 提取的是相同的,由于 Scrapy 的去重机制,相同的链接只会被请求和处理一次,所以不会因为规则 2 和规则 3 提取到相同的链接而导致 parse_tag 方法被重复调用并打印两次数据。
虽然 Scrapy 会对链接进行去重,但如果你的 parse_tag 方法内部存在一些逻辑,可能会导致数据重复处理。例如,如果你在 parse_tag 方法中对数据进行了一些存储操作,并且没有进行去重处理,那么可能会出现数据重复存储的情况
LinkExtractor allow参数
-
字符串列表:
allow=['/tag/love/', '/tag/humor/'],LinkExtractor会提取包含/tag/love/或者/tag/humor/的链接 -
编译好的正则表达式对象:
tag_pattern = re.compile(r'/tag/[a-z]+/$') rules = (Rule(LinkExtractor(allow=tag_pattern), callback='parse_item', follow=True), ) -
空列表或空字符串:如果你传入一个空列表
[]或者空字符串'',LinkExtractor会提取页面中的所有链接。