广州好的做网站公司要屏蔽一个网站要怎么做
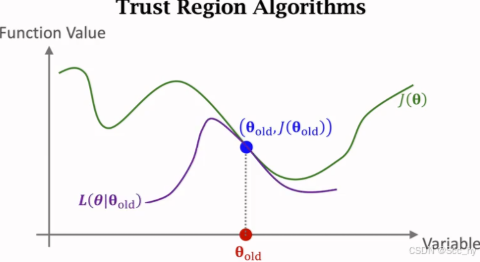
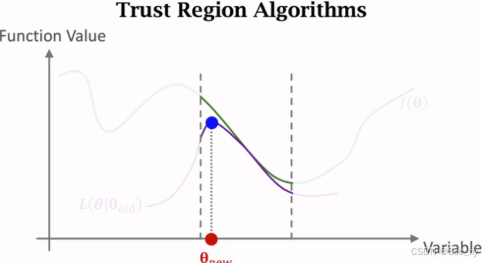
1 置信域算法到TRPO
置信域算法核心:
找到更新参数 θ \theta θ和 θ o l d \theta_{old} θold相关的近似目标函数,邻域 N ( θ o l d ) N(\theta_{old}) N(θold)内寻找最大值
-
近似(approximation): L ( θ ∣ θ o l d ) L(\theta | \theta_{old}) L(θ∣θold)
-
最大化(Maximation): arg max θ ∈ N ( θ o l d ) L ( θ ∣ θ o l d ) \argmax_{\theta \in N(\theta_{old})} L(\theta | \theta_{old}) argmaxθ∈N(θold)L(θ∣θold)
强化学习优化目标:1991 Dyna paper中就提出的agent的任务可以建模成奖励最大化问题(reward maximization)
E π [ τ ( r ) ] = E π [ V π ( S ) ] = ∑ i = 1 A π ( a i ∣ S ; θ ) Q ( S , a i ) E_\pi[\tau(r) ] = E_\pi[V^\pi(S)] = \sum_{i=1}^A\pi(a_i|S;\theta)Q(S, a_i) Eπ[τ(r)]=Eπ[Vπ(S)]=∑i=1Aπ(ai∣S;θ)Q(S,ai)
- 寻找 L ( θ ∣ θ o l d ) L(\theta | \theta_{old}) L(θ∣θold)
- 等价替换 ∑ i = 1 A π ( a i ∣ S ; θ ) Q ( S , a i ) = ∑ i = 1 A π ( a i ∣ S ; θ o l d ) π ( a i ∣ S ; θ ) π ( a i ∣ S ; θ o l d ) Q ( S , a i ) = E a ∼ π ( . ∣ θ o l d ) [ π ( a ∣ S ; θ ) π ( a ∣ S ; θ o l d ) Q ( S , a ) ] \sum_{i=1}^A\pi(a_i|S;\theta)Q(S, a_i)=\sum_{i=1}^A \pi(a_i|S;\theta_{old}) \frac{\pi(a_i|S;\theta)}{\pi(a_i|S;\theta_{old})}Q(S, a_i)=E_{a\sim \pi(.|\theta_{old})}[\frac{\pi(a|S;\theta)}{\pi(a|S;\theta_{old})}Q(S, a)] ∑i=1Aπ(ai∣S;θ)Q(S,ai)=∑i=1Aπ(ai∣S;θold)π(ai∣S;θold)π(ai∣S;θ)Q(S,ai)=Ea∼π(.∣θold)[π(a∣S;θold)π(a∣S;θ)Q(S,a)]
- L ( θ ∣ θ o l d ) = E a ∼ π ( . ∣ θ o l d ) [ π ( a ∣ S ; θ ) π ( a ∣ S ; θ o l d ) Q ( S , a ) ] ≃ E a ∼ π ( . ∣ θ o l d ) [ π ( a ∣ S ; θ ) π ( a ∣ S ; θ o l d ) U t ] L(\theta | \theta_{old})=E_{a\sim \pi(.|\theta_{old})}[\frac{\pi(a|S;\theta)}{\pi(a|S;\theta_{old})}Q(S, a)] \simeq E_{a\sim \pi(.|\theta_{old})}[\frac{\pi(a|S;\theta)}{\pi(a|S;\theta_{old})}U_t] L(θ∣θold)=Ea∼π(.∣θold)[π(a∣S;θold)π(a∣S;θ)Q(S,a)]≃Ea∼π(.∣θold)[π(a∣S;θold)π(a∣S;θ)Ut]
- 蒙特卡洛近似 & u i u_i ui回报用优势 A i A_i Ai确保策略更新的方向是朝着提高预期回报的方向。
- L ( θ ∣ θ o l d ) ≃ 1 n ∑ i = 1 n π ( a i ∣ s i ; θ ) π ( a i ∣ s i ; θ o l d ) A i . . . . . ( T R P O − 1 ) L(\theta | \theta_{old}) \simeq \frac{1}{n}\sum_{i=1}^n\frac{\pi(a_i|s_i;\theta)}{\pi(a_i|s_i;\theta_{old})}A_i \ \ ..... (TRPO-1) L(θ∣θold)≃n1∑i=1nπ(ai∣si;θold)π(ai∣si;θ)Ai .....(TRPO−1)
- arg max θ ∈ N ( θ o l d ) L ( θ ∣ θ o l d ) \argmax_{\theta \in N(\theta_{old})} L(\theta | \theta_{old}) argmaxθ∈N(θold)L(θ∣θold)
- 约束 1 n ∑ i = 1 n D K L [ π ( . ∣ s i ; θ o l d ) ∣ ∣ π ( . ∣ s i ; θ ) ] < Δ . . . . . ( T R P O − 2 ) \frac{1}{n}\sum_{i=1}^nD_{KL}[\pi(.|s_i;\theta_{old}) | | \pi(.|s_i;\theta) ] < \Delta \ \ ..... (TRPO-2) n1∑i=1nDKL[π(.∣si;θold)∣∣π(.∣si;θ)]<Δ .....(TRPO−2)
2 TRPO到PPO
TRPO 使用泰勒展开近似、共轭梯度、线性搜索等方法直接求解。该方法计算量巨大,所以2017PPO paper发布, PPO 的优化目标与 TRPO 相同,但 PPO 用了一些相对简单的方法来求解
PPO-Penalty: 拉格朗日乘数法直接将 KL 散度的限制放进了目标函数中- L ( θ ∣ θ o l d ) = 1 n ∑ i = 1 n [ π ( a i ∣ s i ; θ ) π ( a i ∣ s i ; θ o l d ) A i + β D K L [ π ( . ∣ s i ; θ o l d ) ∣ ∣ π ( . ∣ s i ; θ ) ] ] L(\theta | \theta_{old}) = \frac{1}{n}\sum_{i=1}^n[\frac{\pi(a_i|s_i;\theta)}{\pi(a_i|s_i;\theta_{old})}A_i + \beta D_{KL}[\pi(.|s_i;\theta_{old}) | | \pi(.|s_i;\theta) ]] L(θ∣θold)=n1∑i=1n[π(ai∣si;θold)π(ai∣si;θ)Ai+βDKL[π(.∣si;θold)∣∣π(.∣si;θ)]]
PPO-Clip: 在目标函数中进行限制,以保证新的参数和旧的参数的差距不会太大- L ( θ ∣ θ o l d ) = 1 n ∑ i = 1 n [ m i n ( π ( a i ∣ s i ; θ ) π ( a i ∣ s i ; θ o l d ) A i , c l i p ( π ( a i ∣ s i ; θ ) π ( a i ∣ s i ; θ o l d ) , 1 − ϵ , 1 + ϵ ) A i ) ] L(\theta | \theta_{old}) = \frac{1}{n}\sum_{i=1}^n[min(\frac{\pi(a_i|s_i;\theta)}{\pi(a_i|s_i;\theta_{old})}A_i, clip(\frac{\pi(a_i|s_i;\theta)}{\pi(a_i|s_i;\theta_{old})}, 1-\epsilon, 1+\epsilon )A_i)] L(θ∣θold)=n1∑i=1n[min(π(ai∣si;θold)π(ai∣si;θ)Ai,clip(π(ai∣si;θold)π(ai∣si;θ),1−ϵ,1+ϵ)Ai)]
3 正向 D K L D_{KL} DKL和反向 D K L D_{KL} DKL
参考: 机器学习中的各种熵
我们可以看到上面的近似都是用的正向 D K L ( P ∣ ∣ Q ) D_{KL}(P||Q) DKL(P∣∣Q), P为真实分布,Q为预估分布。
- D K L [ π ( . ∣ s i ; θ o l d ) ∣ ∣ π ( . ∣ s i ; θ ) ] D_{KL}[\pi(.|s_i;\theta_{old}) | | \pi(.|s_i;\theta) ] DKL[π(.∣si;θold)∣∣π(.∣si;θ)], 真实值 P = π ( . ∣ s i ; θ o l d ) P=\pi(.|s_i;\theta_{old}) P=π(.∣si;θold),预估值 Q = π ( . ∣ s i ; θ ) Q=\pi(.|s_i;\theta) Q=π(.∣si;θ)
- 期望预估尽量覆盖真实值
3.1 什么是 D K L D_{KL} DKL
我们先来看下
D K L ( P ∣ ∣ Q ) = P l o g ( P Q ) D_{KL}(P||Q) = Plog(\frac{P}{Q}) DKL(P∣∣Q)=Plog(QP)
表示的是什么。
- 相对熵物理意义:求 p 与 q 之间的对数差 l o g ( p / q ) log(p/q) log(p/q)在 p 上的期望值。
- 是一种相对熵:是
P,Q的交叉熵 H ( P , Q ) = − ∑ p l o g ( q ) H(P, Q)=-\sum plog(q) H(P,Q)=−∑plog(q)与P自身的信息熵 H ( P ) = − ∑ p l o g ( p ) H(P) = -\sum plog(p) H(P)=−∑plog(p)的差异- H ( P , Q ) − H ( P ) = − ∑ p l o g ( q ) + ∑ p l o g ( p ) = ∑ p ( l o g ( p ) − l o g ( q ) ) = ∑ p l o g ( p q ) H(P, Q) - H(P) = -\sum plog(q) + \sum plog(p) = \sum p(log(p)-log(q)) = \sum plog(\frac{p}{q}) H(P,Q)−H(P)=−∑plog(q)+∑plog(p)=∑p(log(p)−log(q))=∑plog(qp)
- 用分布p的最佳信息传递方式来传达分布p,比用分布p自己的最佳信息表达分布p,平均多耗费的信息长度
- 要传达的信息来自于分布 p
- 信息传递的方式由分布 q 决定的。
3.2 正向 D K L D_{KL} DKL和反向 D K L D_{KL} DKL
显然 D K L ( P ∣ ∣ Q ) ≠ D K L ( Q ∣ ∣ P ) D_{KL}(P||Q) \neq D_{KL}(Q||P) DKL(P∣∣Q)=DKL(Q∣∣P)
import numpy as npp = np.array([0.5, 0.3, 0.2]) # 本周访问调查喜欢
q = np.array([0.2, 0.2, 0.6]) # 预估一周后喜欢d_forward_kl = (p * np.log(p/q)).sum()
d_reverse_kl = (q * np.log(q/p)).sum()
print(d_forward_kl, d_reverse_kl)
# (0.3600624406359049, 0.39481620520440186)
正向 KL 散度(Forward KL)
即使 D K L ( P ∣ ∣ Q ) D_{KL}(P||Q) DKL(P∣∣Q) 最小,用公式表示为:
q ⋆ = arg min q D K L ( p ∣ ∣ q ) = arg min q ∑ x p ( x ) l o g p ( x ) q ( x ) q^\star = \argmin_{q}D_{KL}(p||q) = \argmin_q \sum_x p(x)log\frac{p(x)}{q(x)} q⋆=qargminDKL(p∣∣q)=qargminx∑p(x)logq(x)p(x)
正向KL散度, 是对数差在真实分布p上的期望。
- p ( x ) = 0 p(x)=0 p(x)=0时,不论对数差是多少KL散度都是0
- p ( x ) > 0 p(x)>0 p(x)>0时,对数差会对KL散度大小产生影响, 此时 q ( x ) q(x) q(x)作为分母,要尽量大一些,才能保证 KL 散度小
- 即在 p ( x ) p(x) p(x) 大的地方,想让KL小, q ( x ) q(x) q(x) 也尽量大; 在 p ( x ) p(x) p(x) 小的地方, q ( x ) q(x) q(x) 对整体影响不大(因为 log 项本身分子很小,又乘了一个非常小的 p ( x ) p(x) p(x))
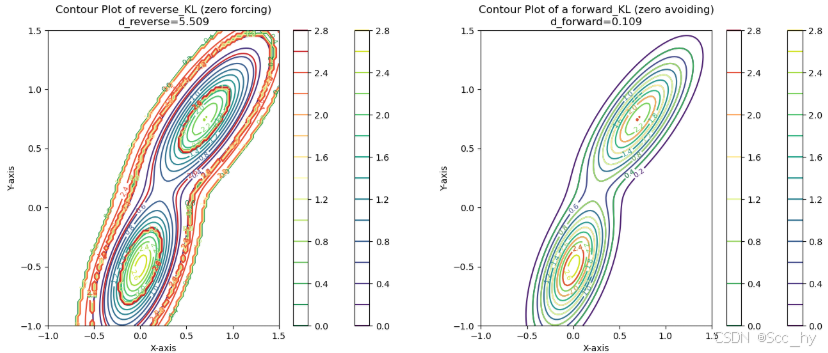
综合上述,想要使得正向 KL 散度(Forward KL)最小,则要求在p不为0的地方,q也尽量不为0,所以正向 KL 散度被称为是 zero avoiding。此时得到的分布 q 是一个比较 宽 的分布。
更在意真实分布 p 中的常见事件
反向 KL 散度(Reverse KL)
即使 D K L ( Q ∣ ∣ P ) D_{KL}(Q||P) DKL(Q∣∣P) 最小,用公式表示为:
q ⋆ = arg min q D K L ( q ∣ ∣ p ) = arg min q ∑ x q ( x ) l o g q ( x ) p ( x ) q^\star = \argmin_{q}D_{KL}(q||p) = \argmin_q \sum_x q(x)log\frac{q(x)}{p(x)} q⋆=qargminDKL(q∣∣p)=qargminx∑q(x)logp(x)q(x)
反向 KL散度, 是对数差在真实分布q上的期望。
- q ( x ) = 0 q(x)=0 q(x)=0时,不论对数差是多少KL散度都是0, 即我们完全可以忽略 p ( x ) p(x) p(x)
- p ( x ) > 0 p(x)>0 p(x)>0时,必须得保证 q ( x ) q(x) q(x) 在 p ( x ) p(x) p(x) 小的地方也尽量小,才能使整体 KL 散度变小。
综合上述,想要使得反向 KL 散度(Reverse KL)最小, p ( x ) p(x) p(x)小的地方, 就需要 q ( x ) q(x) q(x)的值也尽量小;在 p ( x ) p(x) p(x)大的地方,可以适当的忽略。
换一种说法,则要求在 p 为 0 的地方,q 也尽量为 0,所以反向 KL 散度被称为是 zero forcing。此时得到的分布 q 是一个比较 窄 的分布。
更在意真实分布 p 中的罕见事件
3.3 拟合test
Github: test KL Python
- 反向 KL 散度(Reverse KL): D K L ( Q ∣ ∣ P ) D_{KL}(Q||P) DKL(Q∣∣P)更在意真实分布 p 中的罕见事件 (low p(x))
- 正向 KL 散度(Forward KL): D K L ( P ∣ ∣ Q ) D_{KL}(P||Q) DKL(P∣∣Q)更在意真实分布 p 中的常见事件 (high p(x))