网站后台bootstrap宁波谷歌seo推广公司
目录
补充概念
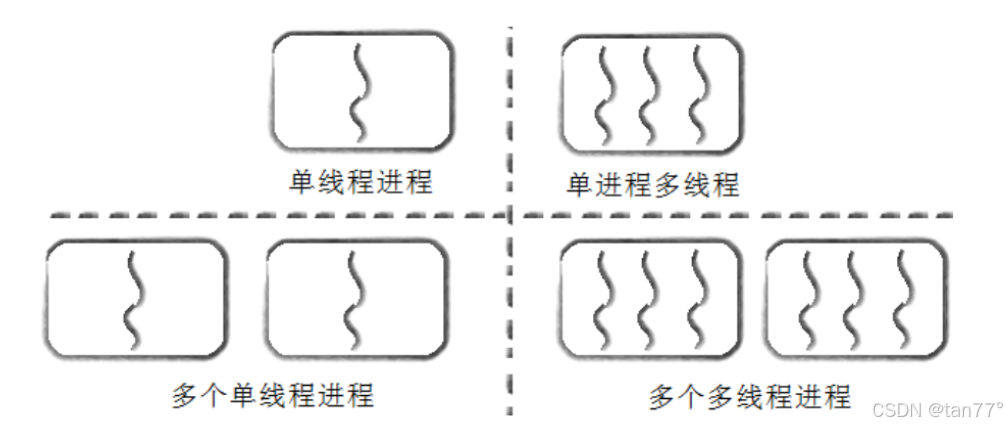
Linux下线程的概念和实现
重谈地址空间,并理解区域划分
虚拟地址空间和页表的由来
内存管理
页表
虚拟地址转换为物理地址
补充知识
线程的优点
线程的缺点
线程异常
线程用途
Linux进程 vs 线程
补充概念
1.进程是一个运行起来的程序。进程=内核数据结构+代码和数据。用户和OS沟通的唯一方式是进程,进程与OS沟通的唯一方式是系统调用。
2.线程是一个执行流,它的执行粒度比进程更细。线程是进程内部的一个执行分支。
更新认识:
- 进程是承担分配系统资源的基本实体
- 线程是OS调度的基本单位
Linux下线程的概念和实现
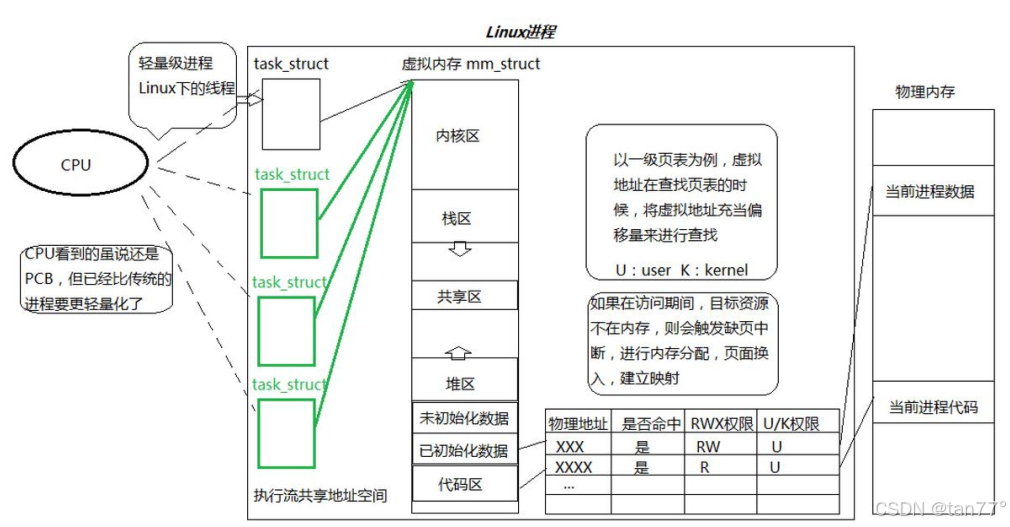
前面说了线程是进程内部的一个执行分支,说明在OS内部线程比进程的数量更多,所以OS必然要对线程进行管理,先描述,再组织。此时可以弄一个结构体来描述线程,如弄一个TCB,然后在task_struct中弄一个TCB的链表,但是这样非常麻烦,因为为了调度线程,还要给线程弄一个调度算法等。并且我们会发现,一个进程中会有多个线程,为了描述线程,线程的TCB中也会有非常多的属性,并且这些属性与task_struct中的属性是高度相似的。所以,我们可以直接使用PCB(task_struct)来描述线程,只是我们在创建一个进程时,会为这个进程创建task_struct,并创建进程地址空间、页表;在创建线程时,同样是创建一个task_struct,只是不创建进程地址空间、页表,并让线程与创建出这个线程的进程共享进程地址空间,并将这个进程地址空间的代码区根据线程的数量划分,每个线程执行自己分配到的区域中的代码。这样,就将一个进程肢解开了,这里的每一个执行分支就称为线程。
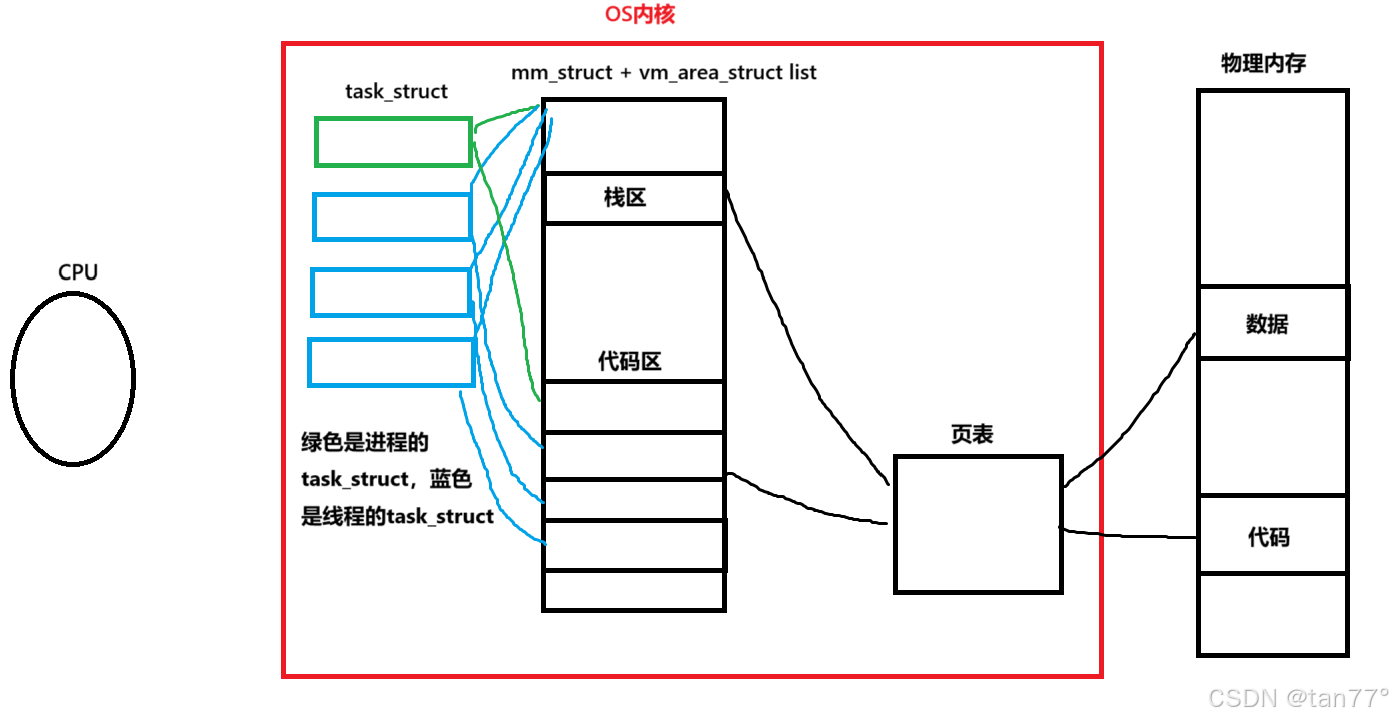
结论:
- Linux的线程是用进程模拟实现的。这样,线程的先描述、再组织都可以复用进程的代码了。这在软件工程中,就是增加了代码的可维护性。
- 线程在进程的内部运行,在Linux中的体现就是线程在进程的地址空间上运行。
有了上面的概念,我们对进程和线程的概念进行一下统一。上面红色框框框起来的部分+代码和数据就是进程,所以一个进程不是一个PCB能够描述的。这与我们之前所说的是一样的,我们一直说的是进程=内核数据结构+代码和数据,并没有说内核数据结构中只能有一个task_struct。一个进程只有一个task_struct,说明只有一个执行分支。所以,我们之前学的进程属于是一种特殊情况。对于任意一个task_struct就是"线程",这个的意思是说,进程是上面的一整套东西,而线程只是一个task_struct。
task_struct能否称为线程?可以,但有前提:
- 如果该task_struct与其他task_struct共享资源(如地址空间),则它就是一个线程
- 如果它独占资源,则是传统意义上的进程
为什么说进程是承担分配系统资源的基本实体?
我们创建进程时,会创建一系列的内核数据结构,如task_struct、地址空间、页表等,并加载代码和数据到物理内存中,而上面无论是内核数据结构,还是代码和数据,都是需要分配内存的,所以OS分配资源是以进程为载体进行分配的。线程一旦创建,并不会申请资源,而是划分进程的资源。所以,进程是承担分配系统资源的基本实体。
刚刚是站在进程的角度看待线程的,现在我们站在CPU的角度看待线程。
CPU看到的就是task_struct,这个task_struct可能是进程众多线程中的其中一个,也可能是一个进程。所以,我们将Linux中的执行流统一称为轻量级进程(LWP),也就是将所有的PCB都称为轻量级进程,以前学的进程=轻量级进程+地址空间+页表+代码和数据,并且一个进程内部可以同时存在多个轻量级进程。Linux中没有真正意义上的线程,是用LWP进行模拟实现的!Linux中创建一个线程,就是创建一个轻量级进程!对于上面这句话的理解:OS并没有要求线程要如何实现,只是说线程是一个执行流,它的执行粒度比进程更细。当前的轻量级进程确实比进程执行粒度更细,因为只执行进程的一部分代码;并且轻量级进程确实是进程内部的一个执行流。所以,轻量级进程是符合OS中对于线程的理论和特性的。只是Linux中实现线程的方案是LWP模拟实现的。也就是说,OS并没有规定线程的具体实现,只是规定了线程的理论和特性,而LWP是完全符合线程的理论和特性的,所以Linux中实现线程的方案是LWP模拟实现的。
在Linux上完成一次线程操作。
#include <pthread.h>int pthread_create(pthread_t *thread, const pthread_attr_t *attr,void *(*start_routine) (void *), void *arg);pthread_create是创建线程的。第一个参数是线程的id,实际上就是一个无符号类型的整数,第二个参数是线程属性,我们这里先不管,直接传nullptr,第三个参数是一个返回值、参数都是void*类型的函数指针,称为回调函数,后面介绍,第四个参数是未来传递给回调函数的参数
Makefile
mythread:mythread.ccg++ -o $@ $^ -std=c++11
.PHONY:clean
clean:rm rf mytheradmythread.cc
// 新线程
void* run(void* args)
{while(true){std::cout << "new thread, pid: " << getpid() << std::endl;sleep(1);}return nullptr;
}int main()
{std::cout << "我是一个进程:" << getpid() << std::endl;pthread_t tid;pthread_create(&tid, nullptr, run, (void*)"thread-1");// 主线程while(true){std::cout << "main thread, pid: " << getpid() << std::endl;sleep(1);}return 0;
}这个程序运行起来就会有两个线程,一个线程跑去执行run,一个线程继续从创建线程的地方往下执行。我们上面的代码直接编译就成功了,但是还是推荐在g++后面加上-lpthread,因为pthread_create不是系统调用,而是一个glibc封装的一个原生线程库。上面没有包含也过了,是因为glibc的版本较新。
Makefile
mythread:mythread.ccg++ -o $@ $^ -std=c++11 -lpthread
.PHONY:clean
clean:rm rf mytherad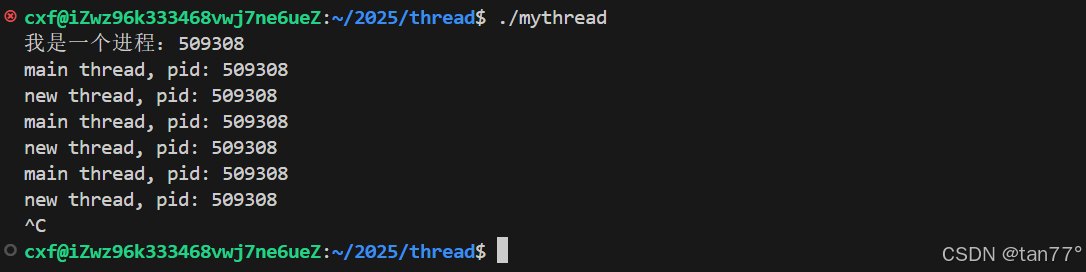
可以看到,此时确实是两个死循环同时执行,有了两个执行流。并且这些线程的task_struct的PID是相同的,因为它们属于同一个进程。
启动上面的程序

ps ajx是查看含有mythread字段的进程;ps-aL是查看系统内的轻量级进程。可以看到,这两个轻量级进程的PID是一样的,但是LWP是不一样的。PID==LWP的就是主线程,其余的都是新线程
所以,OS内部的真实调度,并不是看PID,因为PID相同的task_struct可能有多个,真正看的是LWP。之前讲的也没错,因为之前都是单执行流,PID==LWP。在task_struct中,既有PID,也有LWP。
一个例子:在一个国家中,会有各种各样的资源,如土地、粮食等等,国家里面的人都是可以被调度的,如上学、工作等等,承担分配系统资源的基本实体就是家庭,一个家庭中一般有多个成员,并且每一个成员都在做不一样的事情,虽然这些家庭成员都在做着不一样的事情,但是目的都是为了把日子过好。在这里,家庭就是进程,家庭内部的每一个成员就是线程。
重谈地址空间,并理解区域划分
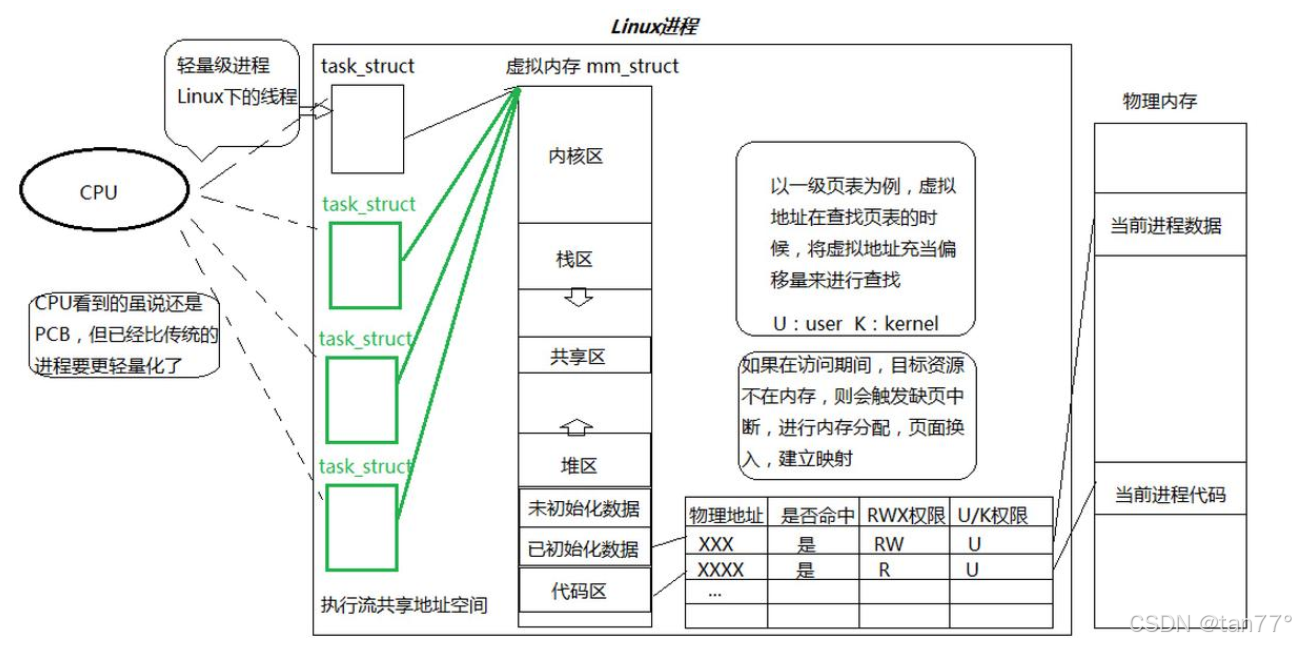
我们前面说了,进程在创建新线程时,会划分一部分代码给线程执行,如何理解进程划分资源给线程?是如何做到的?
虚拟地址空间和页表的由来
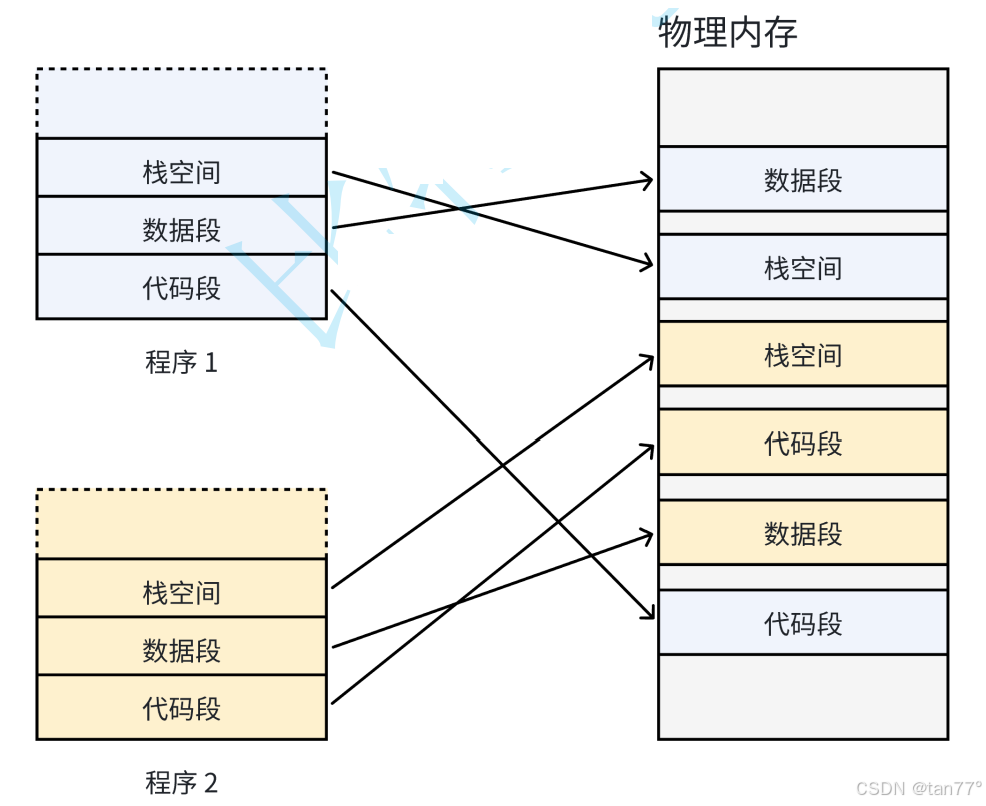
如果没有虚拟地址空间,程序的栈、数据段、代码段等都是直接去物理内存中开辟的,并且OS中会有非常多的进程,物理内存就会被分割成非常非常多的离散的、大小不同的块,经过一段时间的运行,有些进程会退出,那么它们占据的物理内存空间会被回收,导致物理内存是以很多碎片的形式存在。此时我们进程去访问内存时,访问的是不连续的。我们希望OS提供给用户的空间必须是连续的,但是物理上是不是连续的可以不用管。所以,此时就有了虚拟地址和页表。可以将物理内存中不连续的内存块,通过页表映射后,以连续的形式呈现给进程,这样,进程再也不用关心物理内存了,只需要关心虚拟内存,虚拟内存中各个区域是划分好的,并且是连续的,此时用户看到的空间就是连续的。
内存管理
可执行程序加载到内存时,是以一个数据块(大小是4KB)为基本单位将可执行程序加载到内存的。在磁盘上,文件是以4KB的数据块被划分好的,同样,在物理内存中,也是按照4KB划分好的。所以,未来存储文件、加载文件都是以数据块为单位的,并且未来在物理内存中申请、释放等,都是以数据块为基本单位的。
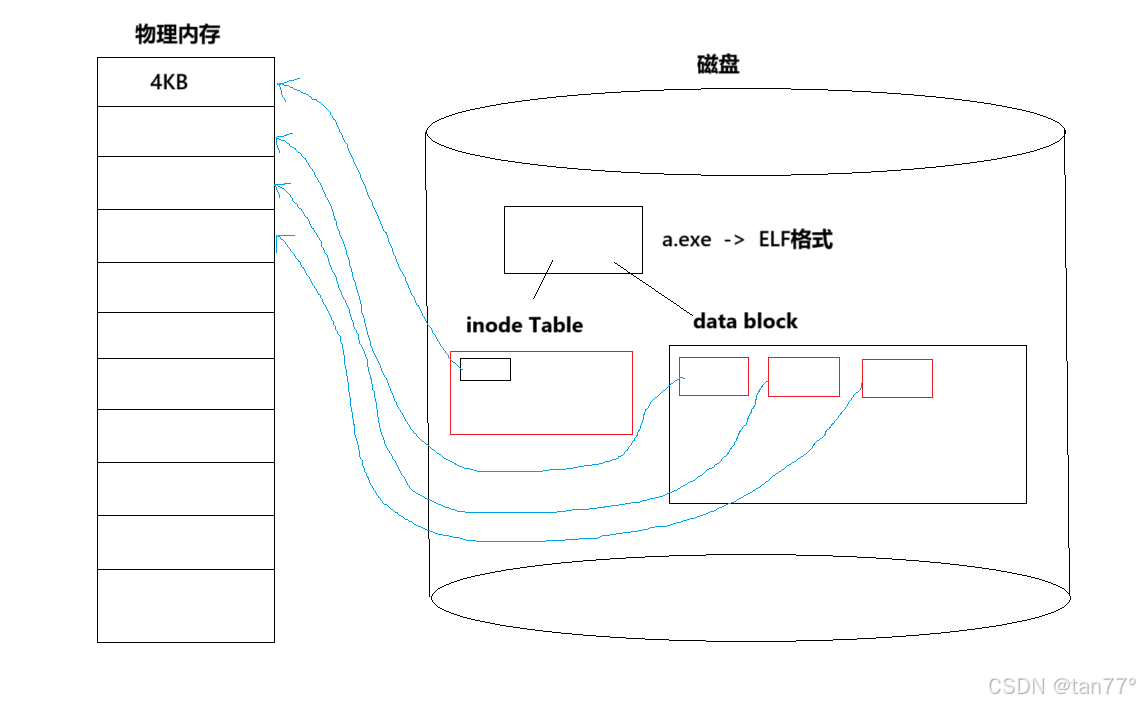
文件在磁盘中是以4KB的数据块的形式进行存储的,图中红色的框框就是4KB,所以当文件加载到物理内存时,直接按块的形式进行加载即可。这样的加载方式可以保证物理内存中不会有太多的碎
片,如果有,也是在块内的碎片,如一个文件大小是3KB,同样需要占用一个4KB的数据块,此时就浪费了1KB的空间,这种碎片叫做内部碎片。
所以,OS并不是让我们随意的使用物理内存,而是将物理内存划分成以4KB为基本单位的数据块,这样内存与磁盘交互时,最多只会浪费一个数据块内部的部分空间,解决了碎片问题。我们将物理内存中划分好的4KB的数据块称为页框。所以,物理内存被划分成了一个一个的页框。物理内存上有这么多的页框,哪一个被使用了,哪一个没有被使用,哪一个是需要刷新到外设的,所以,OS必须要管理内存。OS进行内存管理的方式,同样是先描述,再组织。
struct page {// 标志位和状态管理unsigned long flags; // 原子标志位,如PG_locked, PG_dirty等// 引用计数和映射信息atomic_t _refcount; // 引用计数union {struct {unsigned long _mapcount; // 页表映射计数unsigned int active; // LRU活跃度void *shadow; // 影子页表相关};struct { /* 其他使用方式 */ };};// 内存管理相关union {struct address_space *mapping; // 页缓存所属的地址空间void *s_mem; // slab分配器使用};// 页位置信息pgoff_t index; // 在映射中的偏移量(文件位置或swap)// 私有数据void *private; // 文件系统或设备驱动私有数据// 内存回收相关struct list_head lru; // LRU链表节点// 调试信息void *virtual; // 内核虚拟地址(如果已映射)// 其他架构特定字段// ...
};OS定义了一个page的结构体,OS每申请了一个页框,就会创建一个page。重点看page里面的flags,flags是一个位图,可以使用这个位图来描述一个page的状态:define未使用1;
define正在使用(1<<1)等等。mapcount是用来进行引用计数的,如父子进程可能同时使用同一个内存块。
上面就完成了先描述,接下来是再组织,OS内核中会有一个struct page* mem_map[N],是一个数组,往后我们想要使用一个page,只需要拿到数组的下标即可。也就是说,我们想要访问物理内存,只需要拿到下标即可。
- 物理地址 = 下标 * 4KB
- 下标 = 物理地址 / 4KB
这样就完成了物理内存和下标、下标和物理内存之间的相互转化。
总结:只要找到了page,page有下标,就等同于找到了物理内存。所以,之前学习的文件的内核级缓冲区,就是page的列表,只要通过structfile找到一个一个的page,就找到了文件缓冲区。
我们说的这个page是一个结构体,大小不到40个字节,我们当成40个字节来计算。假设一个OS的物理内存可用空间是4GB,按照一个页框4KB的大小进行划分,4GB的空间就是4GB/4KB=1048576个页框,1048574*40字节=40MB。也就是说,未来对大小为4GB的物理内存空间进行管理,我们需要使用40MB的空间来保存描述这些页框的结构体。所以,物理内存中大约有干分之一的空间是被page占据的,在这里大约有1000个页框。
假设磁盘上一个文件的大小是15KB,要加载到内存当中,首先就会去查询mem_map,找到4个没有被使用的page,然后对这4个page进行设置,如修改标记位为真正在使用、引用计数++等,然后再将内存块拷贝到物理内存中。将来要关闭文件了,我们是知道物理地址的,通过物理地址找到下标,修改page中的标记位、引用计数等,就代表被释放了。
页表
页表正常来说,应该左侧存虚拟地址,右侧存物理地址。物理地址是按4KB进行划分的,我们可以将虚拟地址也想象成4KB进行划分的,并且虚拟地址是连续的,从0000...0000到FFFF...FFFF。因为虚拟地址是连续的,并且虚拟地址和物理地址一样是按4KB的区间进行划分的,所以页表中可以只存放物理地址(就是存放物理地址中每一个页框的起始地址),然后页表映射时,根据当前的虚拟地址和虚拟起始地址的偏移量/4KB,就能拿到这是虚拟地址中的第几个4KB,然后根据计算出这个值,去页表中索引即可。这里只需要知道页表中存放的是物理地址即可,至于虚拟地址如何转换成物理地址,后面详细说。
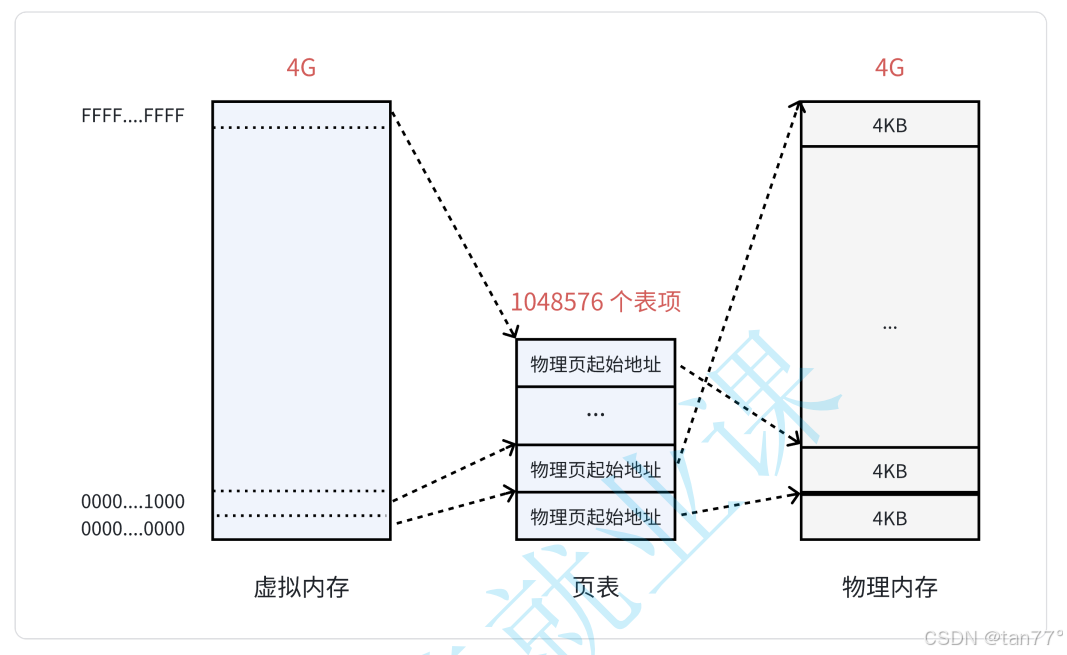
在32位系统下,虚拟内存最大是4GB,当我们将虚拟地址空间按4KB划分成一块一块的,一共会有4GB/4KB=1048576块,每一个块都存放物理地址,一个地址是4字节,所以页表的大小是1048576*4字节=4MB,4MB/4KB=1024,所以保存这个页表就需要使用1024个页框。这会有什么问题呢?
- 回想一下,当初为什么使用页表,就是要将进程划分为一个个页可以不用连续的存放在物理内存中,但是此时页表就需要1024个连续的页框,似乎和当时的目标有点背道而驰了
- 此外,根据局部性原理可知,很多时候进程在一段时间内只需要访问某几个页就可以正常运行了。因此也没有必要一次让所有的物理页都常驻内存。
解决需要大容量页表的最好方法是:把页表看成普通的文件,对它进行离散分配,即对页表再分页,由此形成多级页表的思想。
虚拟地址转换为物理地址
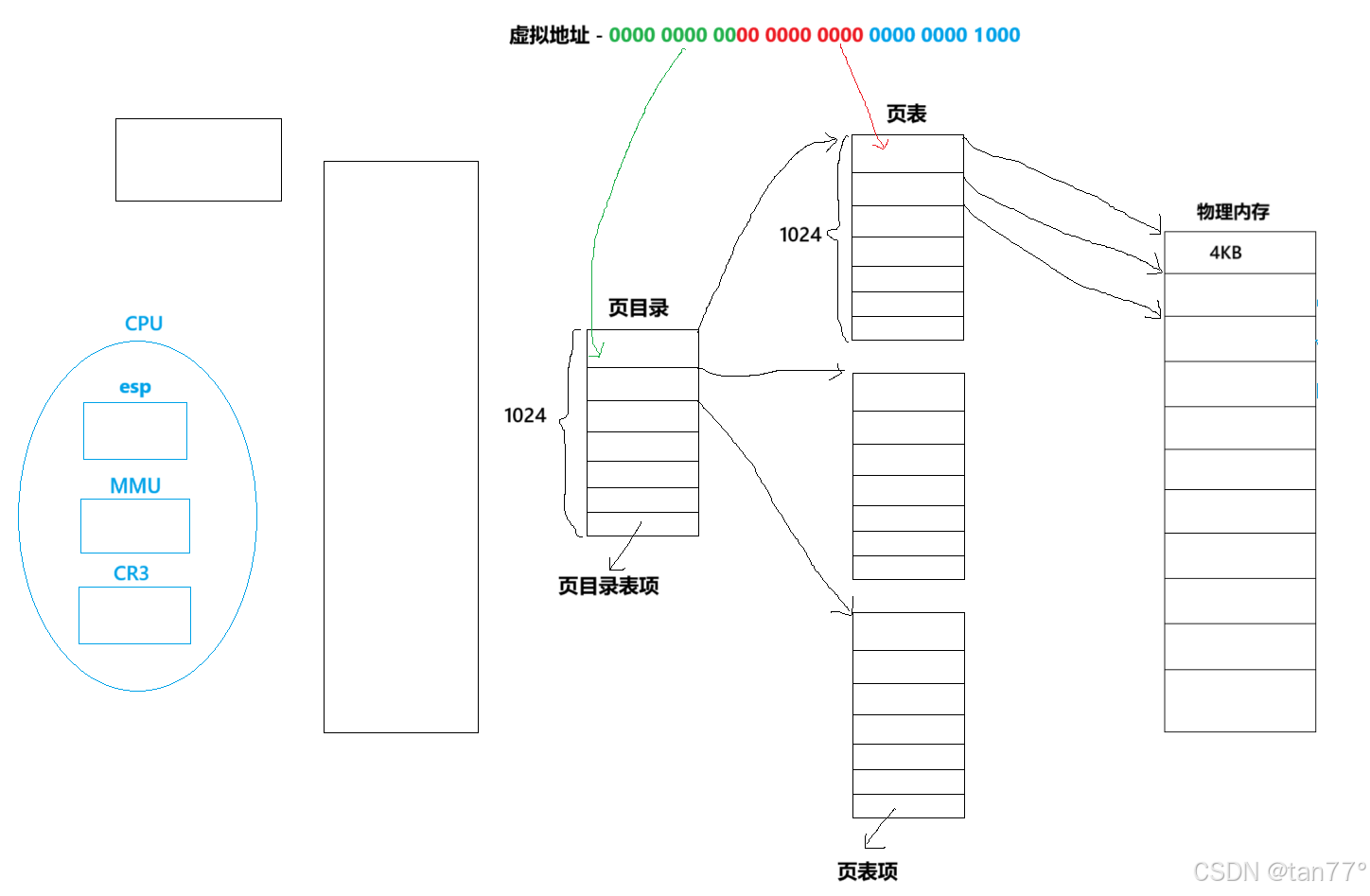
我们先来看一下多级页表的结构,以二级页表为例。二级页表由页目录和页表组成。页目录的内容称为页目录表项,每一个页目录表项指向一张页表,页目录中有1024个页目录表项,页表的内容称为页表项,一张页表有1024个页表项,每一个页表项保存的都是物理内存的每一个4KB的起始物理地址,一个页表项的大小是4字节,这样,整体的大小就是1024*1024*4=4MB。此时会发现页表的大小和之前并没有变化。从总数上看是这样,但是一个应用程序是不可能完全使用全部的4GB空间的,也许只要几十个页表就可以了。例如:一个用户程序的代码段、数据段、栈段,一共就需要10MB的空间,那么使用3个页表就足够了。
多级页表的结构是这样的,那如何将虚拟地址转换成物理地址呢?我们拿到了一个虚拟地址,这个虚拟地址表示的一定是某一个字节的地址,不是块的地址。会先使用虚拟地址的前10个比特位去查页目录,再拿中间的10个比特位去查页表。也就是说,虚拟地址的前10位就是页目录的下标,中间的10位就是页表项的下标。这样,通过虚拟地址的前20位,就能够找到要访问的物理内存的页框的起始地址,因为页表项中填的是页框的起始地址。虚拟地址的后12位,2^12=4096,而4KB=4096字节,所以,虚拟地址的后12位就是找到的这个页框的偏移量,这样,我们就能通过一个虚拟地址找到对应的一个字节的物理地址了,能够拿到一个字节的物理地址,就能拿到从这个字节开始的连续多个字节的地址,此时也就有了类型的概念。所以,OS怎么能知道一个页框是否已经被使用呢,只需要通过页表得到一个页框的起始地址,然后除4KB,就是下标,就可以去查看page了。
现在,我们通过多级页表,已经可以拿到物理内存中所有页框的起始地址,但是一个进程不可能会独自占有一整个物理内存,因为至少会有OS,OS也是会占用一部分物理内存的。这说明,页表一定是不完整的,假设一个进程的代码和数据只有10MB,此时只需要使用3个页表,页表的数量是1024个时,大小是4MB,现在只有3个页表,所以页表的大小是远远小于4MB的。
所以,可执行程序是怎么加载的?怎么运行的?
编译好的可执行程序就是ELF格式的,是按4KB排列好的,要将代码和数据加载到物理内存时,会查表,然后将数据块加载到物理内存中,然后会构建虚拟地址空间、页表,会根据我们可执行程序的代码和数据加载到物理内存中的页框的起始地址来构建页表(首先创建页目录,然后根据根据
代码和数据的大小构建页表),等到虚拟地址空间和页表构建完成之后,将物理内存中main函数的起始地址(虚拟地址)填到CPU的esp寄存器中,然后CPU会根据MMU进行查表,然后找到函数的物理起始地址,并将这个地址读到CPU中,然后就可以开始执行了。我们之前说CPU的寄存器CR3保存的是页表的起始地址,现在,更准确地说,CR3保存的是页目录的起始地址,并且是物理地址

加载的本质就是将磁盘中的块加载到内存当中,一旦加载到内存当中,起始的物理地址就知道了,假设这个块的物理起始地址是0x123,并且代码内部也有虚拟地址,此时就可以初始化页表,然后在虚拟内存中创建一个vm_area_struct,起始就是0x1060,终止就是这个代码的虚拟内存的结束,此时就构建好了虚拟到物理的转化。然后将程序的虚拟起始地址放到CPU的寄存器当中,并将页表的起始地址放到CR3寄存器当中,这样,CPU就可以调度这个进程了,取指令、分析指令等,拿着虚拟地址,通过CR3找到页表,然后拿到物理地址(进入CPU是虚拟地址,从CPU出去的是物理地址),此时就拿到了物理地址0x123,就可以依次读取所有指令了。所以,虚拟地址到物理地址的转化在加载完成的时候就已经确定了。
现在讨论虚拟地址转换为物理地址时,CPU在做什么
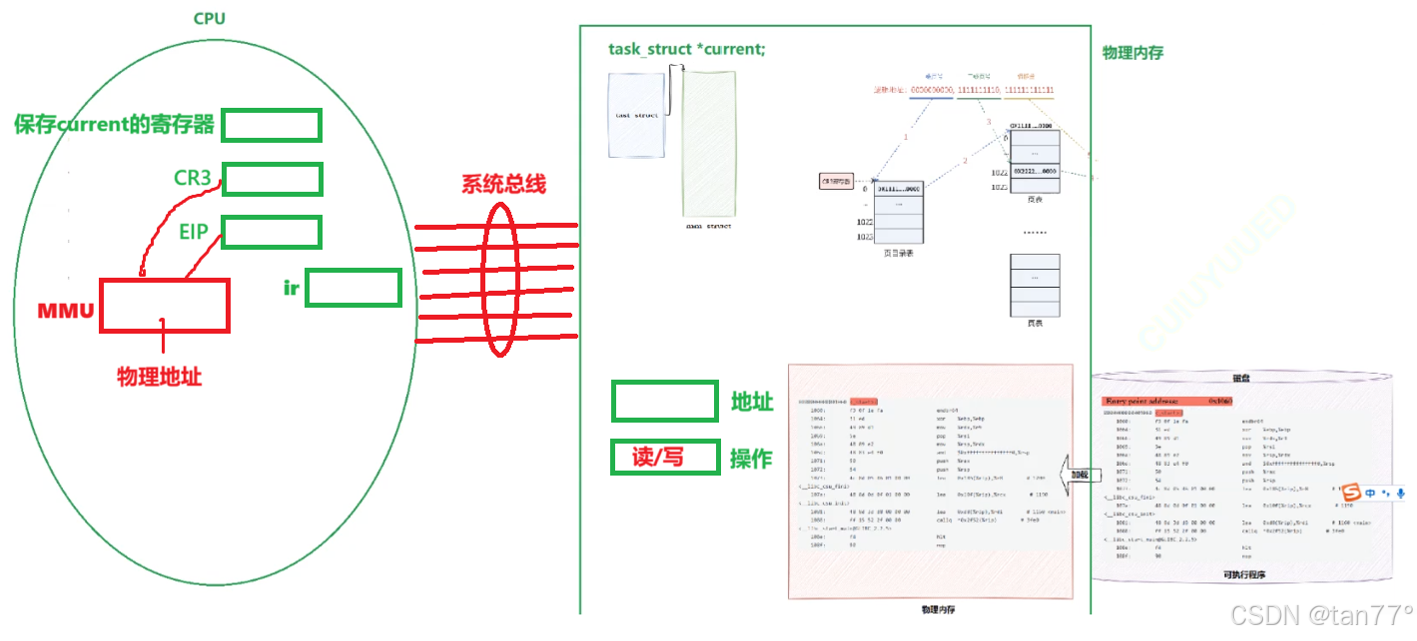
CPU中还有一个ir寄存器,是保存CPU正在执行的这条指令的。在OS内核当中,有一个全局变量current,指向当前正在被cPU调度的进程的task_struct,因为这个进程正在被CPU调度,所以这个指针的内容会被拷贝到CPU的一个寄存器当中,存储当前进程的task_struct的起始地址,当调度的进程被切换时,这个寄存器的内容也会被切换,所以,CPU永远知道自己正在调度的进程的task_struct在哪里。CR3寄存器会保存当前正在调度的进程的页表的起始物理地址,更准确地说,是页目录的起始物理地址。EIP寄存器,也叫pc指针,会存储下一条要执行指令的虚拟地址,可执行程序刚加载时,存储的是当前进程的入口虚拟地址。当进程切换时,这3个寄存器的值都会发生变化。
补充硬件知识:CPU和物理内存都是插在主板上的硬件,前面说的进程切换时,CPU要从物理内
存中读取地址填到寄存器当中,并且若进程中有计算时,CPU也要将计算的结果写回内存中,它
们两个是独立的硬件,要怎么进行交互呢?在硬件上,CPU和物理内存通过系统总线连接CPU中还集成了一个硬件MMU,MMU的工作就是利用CR3中的页目录起始地址,将EIP中的虚拟地址转换成物理地址,就是上面所说的将虚拟地址的前10位。所以,虚拟地址到物理地址的转换是硬件自动完成的。
虚拟地址转化成物理地址的过程,软件不能做吗?为什么要使用硬件来做呢?软件是可以做的,但是软件太慢了。
通过MMU获取物理地址后,就会将物理地址放入系统总线中,将地址交给物理内存,另外,CPU
不仅仅将下一条指令的地址交给物理内存,还会将一个操作交给物理内存,这个操作是要对这个
物理地址进行什么操作,像这里很明显就是读操作,要将物理地址的指令读到CPU中。CPU会分
别使用一个寄存器来保存地址和操作,保存完成后就要进行寻址,通过转过来的物理地址找到物
理内存中的指令,然后根据操作的读将指令从物理内存通过系统总线交给CPU,CPU就会将这条
指令写入到ir寄存器中,EIP寄存器也会根据其内部的值和刚刚从物理内存读到的指令的长度去更
新内部的值,就可以执行下一条指令了,往后读取指令都是如此。所以,进入CPU的是携带虚拟地址的指令,从CPU出去的是物理地址和操作码。
对上面操作读/写的理解
- 像刚刚我们拿到了下一条指令的物理地址,很明显就是要将这条指令读到CPU内部,这是读
- CPU解析指令时,有些指令是要向某个物理内存中进行写入,此时也是通过这种方式,将要写入的物理地址和写的操作码通过系统总线交给物理内存
现在,我们已经知道了页表的真实结构,以及虚拟地址到物理地址的转换,可是这与线程又有什么关系呢?我们当时的问题是如何理解进程划分资源给线程?是如何做到的?
虚拟地址空间被线程共享了,也就是说线程间所有的资源都是共享的。前面说线程的执行粒度比进程更细,至少应该说清楚代码是如何被划分的吧?至于数据是无所谓的,因为是共享的。需要刻意做吗?
// 新线程
void* run(void* args)
{while(true){std::cout << "new thread, pid: " << getpid() << std::endl;sleep(1);}return nullptr;
}int main()
{std::cout << "我是一个进程:" << getpid() << std::endl;pthread_t tid;pthread_create(&tid, nullptr, run, (void*)"thread-1");// 主线程while(true){std::cout << "main thread, pid: " << getpid() << std::endl;sleep(1);}return 0;
}在这段代码中,我们创建了一个线程,包括主线程就有两个线程了,我们是让新线程去执行run,若我们未来要创建10个线程,我们也可以创建run1,run2...,run10,让不同的线程去执行不同的函数。而main、run1、run2、.…、run10这些函数将来会被编译成一份代码,对于里面任意一个函数,都是有地址的,并且各自间的地址都不同,所以我们只需要将这个线程要执行的这个函数的起始地址交给这个线程,这个线程就可以拿到这个函数的所有虚拟地址,而这些虚拟地址是在同一个虚拟地址空间上,且各不相同的,这样在查共享的页表时,每个进程查到的都是页表的一部分,资源就这样分开了。所以,并不需要区分那个地址是那个线程的,只需要让它们去执行不同的函数,这些函数都有各自的虚拟内存,天然就分开了.所以,我们创建一个轻量级进程只需要创建一个LWP,并给这个LWP指定一个函数的入口地址即可,CPU就会复用曾经进程的调度算法去调度它
补充知识
硬件
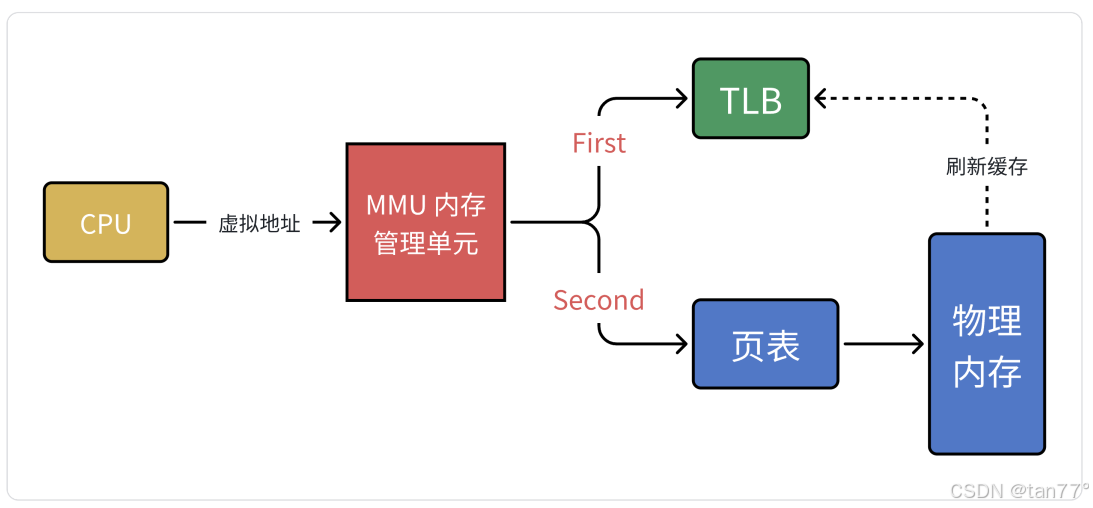
虚拟地址转换为物理地址,每一次都需要使用MMU来转换吗?
MMU虽然是硬件,但是每次转换时也是需要查询页表的,并且还是二级页表,如果是64位甚至是三级页表,而虚拟地址转换位物理地址的频率是非常高的,所以还是比较慢的。所以,MMU引入了TLB,称为快表,学名为转译后备缓冲区,其实就是一个缓存。当CPU给MMU传新虚拟地址之后,MMU先去问TLB那边有没有,如果有就直接拿到物理地址发到总线给内存,齐活。但TLB容量比较小,难免发生CacheMisS(未命中),这时候MMU还有保底的老武器页表,在页表中找到之后MMU除了把地址发到总线传给内存,还把这条映射关系给到TLB,让它记录一下刷新缓存。
可是这个物理地址不是被访问过了吗,缓存它有什么用呢?代码中可能是有循环的,这样是可以加速虚拟地址转换为物理地址的。
软件
我们之前说过页表中不是有标记位吗?
实际上,页表的每一行不仅仅只有一个页框的起始地址,还有一些标记位。
- 是否命中是指这个页框的内容是否在物理内存中,如果没有在,则需要从磁盘中加载到物理内存,然后再进行映射
- RWX权限:对于这个页框内部数据的访问权限,若这个页框内部保存的是代码,则是只读,若这个页框内部保存的是数据,则是可读可写
- U/K权限我们不管
在C/C++中,可以定义一个字符指针,指向一个字符常量,char*msg=“hello",当我们要修改这个字符指针时,*msg=“world",此时是会报错的,为什么会报错呢?
"hello"这个字符常量未来编译时会和代码编译在一起,都在虚拟地址空间的代码区当中,而代码区是只读的,未来我们想修改时,在页表映射时就会因为RWX权限位被拦截下来,此时MMU就报错了,MMU报错就是CPU发生了内部错误,OS就会知道,就会将当前的错误转化成信号,根据CPU内的寄存前正在调度进程task_struct的起始地址),修改比特位,并给它发信号,处理信号时就会根据信号造成崩溃。
我们前面说过,页表的每一项中保存的是一个页框的起始地址,而地址是32个比特位的,但是实际上,我们保存一个地址并不需要使用32个比特位。因为对于一个4GB的物理内存,4GB/4KB=1048576,使用二进制来保存这个数,也就是2^20级别的,所以表示一个地址只需要使用20个比特位即可。所以,究竟什么是页表?
// 页表标记为
#define L_PTE_PRESENT (1 << 0)
#define L_PTE_FILE (1 << 1)
#define L_PTE_YOUNG (1 << 1)
#define L_PTE_BUFFERABLE (1 << 2)
#define L_PTE_CACHEABLE (1 << 3)
#define L_PTE_USER (1 << 4)
#define L_PTE_WRITE (1 << 5)
#define L_PTE_EXEC (1 << 6)
#define L_PTE_DIRTY (1 << 7)
#define L_PTE_COHERENT (1 << 9)
#define L_PTE_SHARED (1 << 10)
#define L_PTE_ASID (1 << 11) typedef struct {unsigned long pte; } pie_t; // 页表项
typedef struct {unsigned long pte; } pgd_t; // 页目录表项可以看到,无论是页目录,还是页表,都是一个unsignedlong类型的数组,unsignedlong有32个比特位。所以,前20个比特位存放页框地址,后12个比特位存放标记位。这些权限在加载时就已经设置好了,因为可执行程序中已经划分好了各个区域。
刚刚我们说了,页表映射时因为RWX权限位被拦截下来,OS会知道,OS是怎么知道的呢?
MMU、TLB都在CPU内,就是CPU出错了,CPU就会转化为软中断。
代码并不一定是一下子全部加载到物理内存中的,不过虚拟内存中是全部加载的,只是会将物理内存中没有加载的部分的是否命中标记位设置为否,当我们要访问的地址的是否命中是否时,就会触发MMU错误,就是CPU出错了,CPU就会转化为软中断。并且这两个软中断的中断号是不同的,可能权限错误的中断号是100,而未加载的中断号是101,中断向量表中101的工作就是进行加载,将磁盘上的内容加载到物理内存中,并重新填写虚拟地址和物理地址,将是否命中由否改为是,然后重新执行刚刚的指令,就可以继续运行程序了,整个过程对CPU完全是透明的。因为没有命中,而要求OS通过软中断执行新加载逻辑,称为缺页中断。
几个问题:
1. 如何理解new和malloc?
new/malloc不是申请物理内存,而是申请虚拟内存,将堆区的vm_area_struct的结束位置扩大一些,然后将页表中的是否命中改为否,当用到时才进行缺页中断。
2. 如何理解我们之前学习的写时拷贝?
父进程刚创建子进程时,代码和数据都是共享的,本质就是虚拟地址空间是共享的,此时只需要将数据区改为只读,当子进程尝试进行写入时,也会发生类似于缺页中断的事情。在这里想重点说的时,写时拷贝是按照4KB为单位的。
3. 申请内存究竟是在干什么?
- 物理内存中未初始化内存的本质:没有进程的页表指向它的页框,怎么知道没有进程的页表指向页框呢?page中有一个引用计数
- 申请内存的本质就是在申请虚拟地址空间,并且修改、填写页表,至于物理内存并不会立即申请,怎么申请,什么时候申请由OS决定。
这就将进程管理和OS解耦了。进程只需要管好虚拟内存即可,物理内存由OS管理。进程管理和内存管理也解耦了。
4. 如何区分是缺页,还是镇的越界了?
其实当我们越界了,也就是野指针了,并不一定会引起程序崩溃。当我们要访问的页没有命中,或者没有权限,MMU就会报错,从而触发软中断或异常,OS在处理中断或异常时,会先检查我们访问的这个虚拟地址是否在当前进程的虚拟地址空间中,就是是否在vm_area_struct的start和end之间,若不在这之间,则越界了,会触发异常,若在这之间,但是页面并不在,就是缺页中断。
线程的优点
1. 创建一个新线程的代价要比创建一个新进程小得多。同样,删除一个线程的代价也比删除一个进程小得多
2. 与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多
a. 进程切换时,需要将CPU的全部上下文数据先保存,再恢复。线程切换时,CR3寄存器是不需要改变的,其他寄存器是需要变的
b. CPU的TLB中会保存当前进程的虚拟地址和物理地址最高频的映射关系,线程切换时,并不需要重置TLB,因为它们共享虚拟地址空间进程间切换是需要更新TLB的
c.每一个CPU都有一个cache,TLB缓存的是虚拟地址到物理地址的转换,cache缓存的是代码和数据块。当MMU获取物理地址后,并不是直接将物理地址放到系统总线上,而是使用物理地址去查cache,若查到了这个物理地址对应的代码和数据,则直接将这个代码和数据放入到对应的寄存器当中;若没有查到,会通过系统总线到物理内存中获取,并且会将查询的物理地址所在页框的4KB数据通过系统总线弄到CPU,并缓存到cache当中。
![]()
![]()
![]()

可以使用这个指令来查看CPU的信息,说明当前CPU是双核的。这个赫兹决定了时钟中断的频率,可以看到确实是有cache的。
这个cache虽然会缓存,但是不一定会真的用到,所以是基于概率的。如我们当前线程正在访问第77行代码和数据,它可能会将前后几十行都缓存进来,而我们接下来访问77行代码和数据附近的代码和数据的概率是非常大的。所以,我们将这种以较大概率访问正在访问的代码和数据附件的代码和数据的原理称为局部性原理。cache本质是缓存,缓存的本质是预加载。物理内存的本质是CPU和外设的缓存,本质就是预加载。而可以预加载都是依赖于局部性原理有效。线程间切换,cache仍然是有效的,但是进程间切换,cache是一定失效的。
3. 线程占用的资源要比进程少很
4. 能充分利用多处理器的可并行数量
5. 在等待慢速I/O操作结束的同时,程序可执行其他的计算任务
6. 计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现
7. I/O密集型应用,为了提高性能,将I/O操作重叠。线程可以同时等待不同的I/O操作
创建进程执行某种任务时,进程的类型可以分为计算密集型和IO密集型。
像算法题的代码、加密解密等都是计算密集型,计算密集型进程所使用的资源主要是CPU资源。计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现。如果CPU有多个,并且是多核的,现在要对100万条数据加密,此时就能创建多个线程,让每个线程对部分数据进行加密,此时加密任务就可以并发地进行了。但是注意:线程不是越多越好,创建太多会将计算问题转换成调度问题,如有2个CPU,无论创建多少个线程,最多只能有2个线程是并发的,剩下的都在等待被调度,线程的切换也是有成本的。所以,计算密集型的任务并不是线程越多越好,一般建议的创建个数是CPU个数*核数。
像进程的任务是进行下载等就是IO密集型,是可以进行多线程并发式下载的,如现在要下载一个10GB的文件,此时可与创建10个线程,让每个线程下载其中的1GB,因为IO密集型大部分时间都在等,所以线程个数可与比CPU个数*核数多。
实际上后4点既是线程的优势,也是进程的优势,前3点完全是线程的优势。
线程的缺点
1. 性能损失
一个很少被外部事件阻塞的计算密集型线程往往无法与其它线程共享同一个处理器。如果计算密集型线程的数量比可用的处理器多,那么可能会有较大的性能损失,这里的性能损失指的是增加了额外的同步和调度开销,而可用的资源不变。例如:线程过多,切换会带来成本。
2. 健壮性降低
编写多线程需要更全面更深入的考虑,在一个多线程程序里,因时间分配上的细微偏差或者因共享了不该共享的变量而造成不良影响的可能性是很大的,换句话说线程之间是缺乏保护的。其实就是,因为线程的资源是共享的,所以一个线程出问题可能会导致所有线程都出问题。
3. 缺乏访问控制
进程是访问控制的基本粒度,在一个线程中调用某些OS函数会对整个进程造成影响。
4. 编程难度提高
编写与调试一个多线程程序比单线程程序困难得多。因为线程的资源都是共享的,所以需要各种保护机制。多线程调试时也是明显难于单线程的。不过,线程间通信会比进程间通信简单很多。
线程异常
- 单个线程如果出现除零,野指针问题导致线程崩溃,进程也会随着崩溃
- 线程是进程的执行分支,线程出异常,就类似进程出异常,进而触发信号机制,终止进程,进程终止,该进程内的所有线程也就随即退出
在一个多线程程序中,如果一个线程异常了,如出现了野指针,那么整个进程都会退出。因为线程是进程的执行分支,当线程出现了异常操作,就等同于进程出现了异常操作。当出现了野指针等,OS就会知道是哪一个PCB进行的操作,在OS内核中,PCB是以组的形式被维护起来的,一个进程有几个线程这个组中就有几个,当组内一个PCB出现了异常,OS会给这个组内全部的PCB都写入野指针相关的信号。所以,我们之前学的信号叫Linux进程信号,在OS看来,信号发送是以进程为载体的。在task_struct内部还有一个thread_group,连接这个进程内部的所有线程。所以,除了有父子进程、兄弟进程,还有组的概念。
线程用途
- 合理的使用多线程,能提高CPU密集型程序的执行效率
- 合理的使用多线程,能提高IO密集型程序的用户体验(如生活中我们一边写代码一边下载开发工具,就是多线程运行的一种表现)
Linux进程 vs 线程
线程会共享进程的数据,但是也拥有一些独属于自己的数据
线程共享的资源
- 内存空间:代码段、数据段、堆、文件描述符表、环境变量
- 进程级系统资源:进程ID、信号处理、文件系统信息(如当前工作目录等)、用户/组权限
- 同步机制:锁、条件变量、信号量
文件描述符表共享的解释:一个线程打开一个文件的文件描述符是3,下一个线程打开时文件描述符就是4了
线程独立的资源
- 执行上下文:线程ID、寄存器状态、栈
- 线程局部存储
- 信号屏蔽字。虽然这些信号的处理方法是共享的,但是每个线程可以选择屏蔽不同的信号
- 调度策略
- 错误码(errno)
对寄存器状态的解释:每一个线程都会有自己独立的上下文数据,这些数据就保存在线程的PCB中。线程有自己独立的上下文数据,说明线程可以被独立调度了;线程有自己独立的栈结构,说明线程和线程之间运行时可以做到互不影响了,因为它们压栈形成栈帧访问的都是自己的栈。
创建线程时,是让线程去执行某一个函数,这个函数内部也可能会调用函数,而调用函数就会有栈帧,栈帧就会在栈上申请空间,而一个地址空间上只有一个栈,若每个线程都去一个栈上申请空间,那么栈帧结构就全乱了,所以每一个线程都要有自己独立的栈结构。可是地址空间上只有一个栈,如何拥有自己独立的栈结构呢?这个后面说