外贸网站高端定做山西做网站的
文章目录
- 前言
- 一、最优模型
- 1、什么是保存最优模型?
- 二、代码实现
- 1、接上篇文章数据代码
- 2.定义CNN模型(前提:先进行数据增强)
- 3、设置训练模式
- 4、设置测试模式并加入最优模型best_acc
- 5、创建交叉熵损失函数以及优化器
- 6、开始训练模型
- 7、结果
- 8、生成最优模型文件
- 总结
前言
在深度学习项目中,特别是在使用卷积神经网络(CNN)处理计算机视觉任务时,模型保存策略是影响最终效果的关键因素。
一、最优模型
1、什么是保存最优模型?
保存最优模型指的是在训练过程中,根据某个指标(如验证集准确率或损失函数值)的表现,选择最好的模型参数并将其保存下来,然后形成一个文件,后缀名为pt\ppt\t7
在深度学习中,模型的训练过程通常是通过迭代优化算法(如梯度下降)来不断调整模型的参数,以最小化目标函数(如损失函数)。在每个训练周期结束后,会使用验证集或测试集对模型进行评估,计算模型在该指标上的性能。
二、代码实现
1、接上篇文章数据代码
链接: link
该篇讲述如何使用数据增强对代码进行优化。
2.定义CNN模型(前提:先进行数据增强)
代码如下(示例):
from torch import nnclass CNN(nn.Module):def __init__(self): # 翰入大小 (3,256,256)super(CNN,self).__init__()self.conv1 = nn.Sequential( # 将多个层组合成一起。nn.Conv2d( # 2d一般用于图像,3d用于视频数据(多一个时间维度),1d一般用于结构化的序in_channels=3, # 图像通道个数,1表示灰度图(确定了卷积核 组中的个数)out_channels=16, # 要得到几多少个特征图,卷积核的个数.kernel_size=5, # 卷积核大小,5*5stride=1, # 步长padding=2, # 一般希望卷积核处理后的结果大小与处理前的数据大小相同,效果会比较好。那p), # 输出的特征图为 (16,256,256)nn.ReLU(),nn.MaxPool2d(kernel_size=2), # 进行池化操作(2x2 区域),输出结果为:(16,128,128))self.conv2 = nn.Sequential(nn.Conv2d(16,32,5,1,2), # 输出(32,128,128)nn.ReLU(),nn.MaxPool2d(2) # 输出)self.conv3 = nn.Sequential(nn.Conv2d(32,128,5,1,2),nn.ReLU(),)self.out = nn.Linear(128*64*64,20) # 全连接def forward(self,x): # 前向传播x = self.conv1(x)x = self.conv2(x)x = self.conv3(x) # 输出(64,128,64,64)x = x.view(x.size(0),-1)output = self.out(x)return output # 返回输出结果model = CNN().to(device) # 将卷积神经网络模型传入GPU
print(model) # 打印当前模型的构造
打印结果:
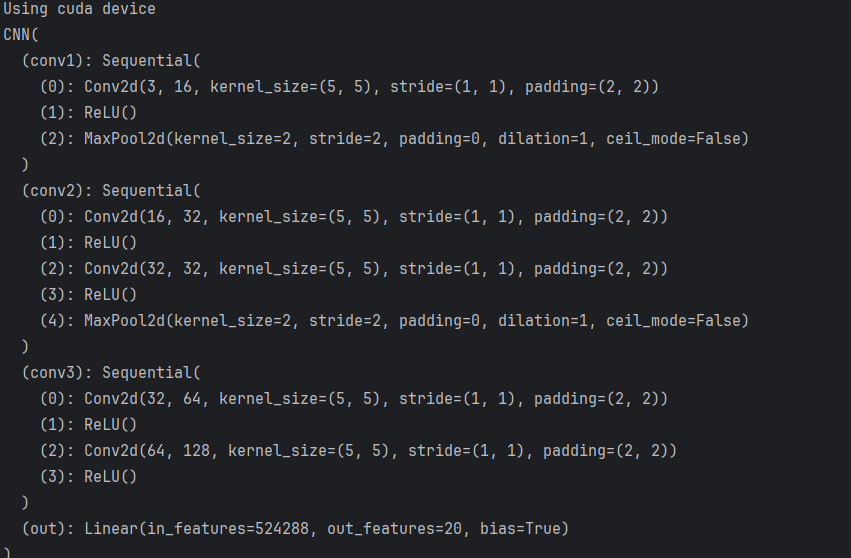
3、设置训练模式
def train(dataloader, model, loss_fn, optimizer):model.train()
#pytorch提供2种方式来切换训练和测试的模式,分别是:model.train() 和 model.eval()。
# 一般用法是:在训练开始之前写上model.trian(),在测试时写上 model.eval() 。batch_size_num = 1for X, y in dataloader: #其中batch为每一个数据的编号X, y = X.to(device), y.to(device) #把训练数据集和标签传入cpu或GPUpred = model.forward(X) #自动初始化 w权值loss = loss_fn(pred, y) #通过交叉熵损失函数计算损失值loss# Backpropagation 进来一个batch的数据,计算一次梯度,更新一次网络optimizer.zero_grad() #梯度值清零loss.backward() #反向传播计算得到每个参数的梯度值optimizer.step() #根据梯度更新网络参数loss = loss.item() #获取损失值if batch_size_num %1 == 0:print(f"loss: {loss:>7f} [number:{batch_size_num}]")batch_size_num += 1
4、设置测试模式并加入最优模型best_acc
best_acc = 0
def test(dataloader, model, loss_fn):global best_accsize = len(dataloader.dataset)num_batches = len(dataloader)model.eval() #测试模式test_loss, correct = 0, 0with torch.no_grad(): #一个上下文管理器,关闭梯度计算。当你确认不会调用Tensor.backward()的时候。这可以减少计算所用内存消耗。for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model.forward(X)test_loss += loss_fn(pred, y).item() #correct += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss /= num_batchescorrect /= sizeif correct > best_acc:best_acc = correcttorch.save(model,'best.pt')print(f"Test result: \n Accuracy: {(100*correct)}%, Avg loss: {test_loss}")
5、创建交叉熵损失函数以及优化器
loss_fn = nn.CrossEntropyLoss() #创建交叉熵损失函数对象,因为手写数字识别中一共有10个数字,输出会有10个结果optimizer = torch.optim.Adam(model.parameters(),lr=0.001)#创建一个优化器,SGD为随机梯度下降算法
scheduler = torch.optim.lr_scheduler.StepLR(optimizer,step_size=5,gamma=0.5)
##params:要训练的参数,一般我们传入的都是model.parameters()。
##lr: learning_rate 学习率,也就是步长。#loss表示模型训练后的输出结果与样本标签的差距。如果差距越小,就表示模型训练越好,越逼近真实的模型。
6、开始训练模型
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True) # 创建数据加载器,将训练集和测试集图片及其标签打包
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)epochs = 150 # 设置模型训练的轮数,不停更新模型参数,找到最优值
acc_s = [] # 初始化了两个空列表,用于存储模型在每个epoch结束时的准确率和损失值
loss_s = []
for t in range(epochs): # 遍历轮数print(f"Epoch {t+1}\n---------------------------") # 表示轮数展示train(train_dataloader,model,loss_fn,optimizer) # 调用函数train传入训练集数据加载器、初始化的模型、损失函数、优化器test(test_dataloader, model, loss_fn) # 上述训练集训练完后有了初步的模型,现传入测试集然后在对其进行测试,然后保存模型,然后进行迭代轮数,每每遇到最大准确率则重新保存新的模型
7、结果
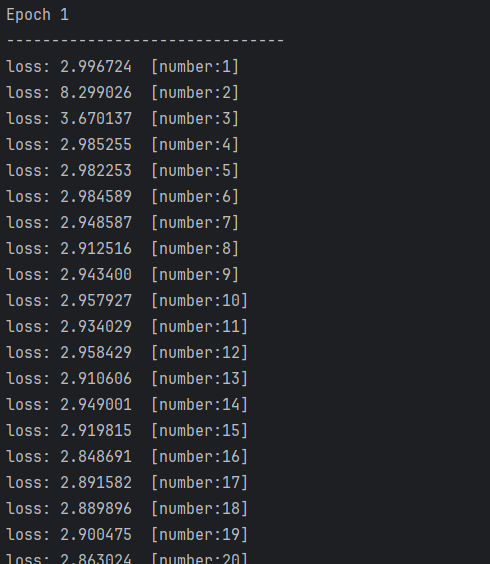
因为要遍历150次,耗费时间巨大,大家感兴趣的可以自己去实现一下!
8、生成最优模型文件
训练结束得到当前训练的最优模型,其为pt\pth\t7文件,可以直接拿过来使用。

总结
通过合理的模型保存策略,研究者可以在不增加额外计算成本的前提下,最大化卷积神经网络的潜在性能。