苏州知名高端网站建设企业wordpress isset
@浙大疏锦行 https://blog.csdn.net/weixin_45655710
https://blog.csdn.net/weixin_45655710
仔细回顾一下之前21天的内容,没跟上进度的同学补一下进度。
作业:
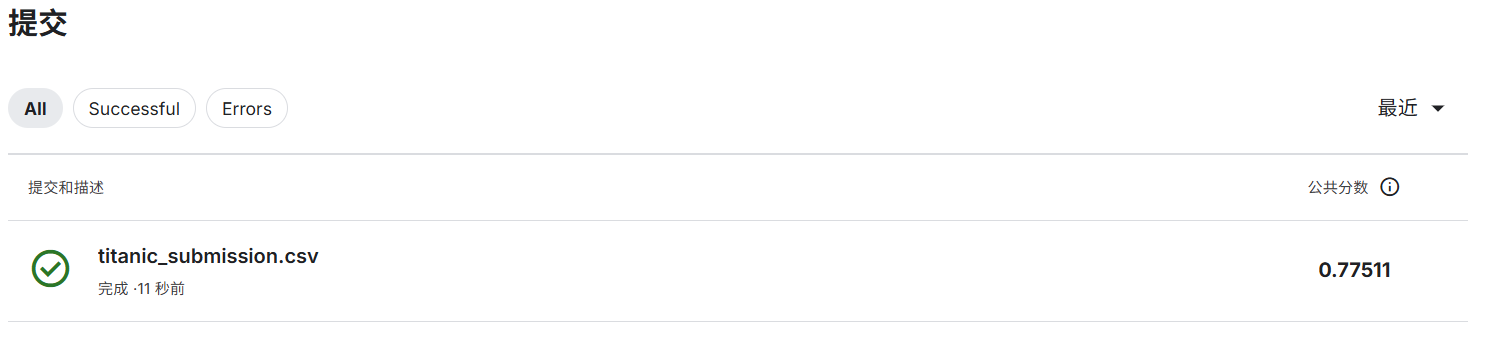
自行学习参考如何使用kaggle平台,写下使用注意点,并对下述比赛提交代码
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import LabelEncoder, OneHotEncoder, StandardScaler# --- 步骤 1: 加载数据 ---
print("--- 步骤 1: 加载数据 ---")
try:train_df = pd.read_csv('train.csv')test_df = pd.read_csv('test.csv')submission_df = pd.read_csv('gender_submission.csv') # 加载示例提交文件以了解格式print("✅ 训练集、测试集和提交示例文件加载成功!")print(f"训练集形状: {train_df.shape}")print(f"测试集形状: {test_df.shape}")
except FileNotFoundError as e:print(f"❌ 错误: 找不到文件 {e.filename}。请确保所有CSV文件都在同一目录下。")exit()# 为了统一处理,先将训练集和测试集合并
# 我们将 test_df 的 PassengerId 保存下来,以便最后生成提交文件
test_passenger_ids = test_df['PassengerId']
# 在合并前,给测试集的 'Survived' 列填充一个临时值,以统一列结构
test_df['Survived'] = -1 # 临时填充,不会用于训练
full_df = pd.concat([train_df, test_df], ignore_index=True)
print(f"\n合并后的数据集形状: {full_df.shape}")# --- 步骤 2: 数据探索与预处理 / 特征工程 ---
print("\n--- 步骤 2: 数据预处理与特征工程 ---")# 2.1 处理缺失值
# Age (年龄): 使用中位数进行填充
print("处理 'Age' 列的缺失值...")
age_median = full_df['Age'].median()
full_df['Age'].fillna(age_median, inplace=True)
print(f"✅ 'Age' 缺失值已用中位数 {age_median:.2f} 填充。")# Fare (票价): 测试集中有一个缺失值,用中位数填充
print("处理 'Fare' 列的缺失值...")
fare_median = full_df['Fare'].median()
full_df['Fare'].fillna(fare_median, inplace=True)
print(f"✅ 'Fare' 缺失值已用中位数 {fare_median:.2f} 填充。")# Embarked (登船港口): 训练集中有两个缺失值,用众数填充
print("处理 'Embarked' 列的缺失值...")
embarked_mode = full_df['Embarked'].mode()[0]
full_df['Embarked'].fillna(embarked_mode, inplace=True)
print(f"✅ 'Embarked' 缺失值已用众数 '{embarked_mode}' 填充。")# Cabin (船舱号): 缺失值太多,我们先创建一个新特征 'HasCabin' 表示有无船舱记录
print("处理 'Cabin' 列...")
full_df['HasCabin'] = full_df['Cabin'].notna().astype(int)
print("✅ 已根据 'Cabin' 创建新特征 'HasCabin'。")# 2.2 将非数值特征转换为数值特征
print("\n转换非数值特征...")
# Sex (性别): 使用标签编码 (Male -> 1, Female -> 0)
le_sex = LabelEncoder()
full_df['Sex'] = le_sex.fit_transform(full_df['Sex'])
print("✅ 'Sex' 列已进行标签编码。")# Embarked (登船港口): 使用独热编码
# 独热编码会创建新的列,如 Embarked_C, Embarked_Q, Embarked_S
full_df = pd.get_dummies(full_df, columns=['Embarked'], prefix='Embarked')
print("✅ 'Embarked' 列已进行独热编码。")# 2.3 创建新的特征 (特征工程)
print("\n创建新特征...")
# FamilySize: 家庭成员总数 = SibSp (兄弟姐妹/配偶数) + Parch (父母/子女数) + 1 (自己)
full_df['FamilySize'] = full_df['SibSp'] + full_df['Parch'] + 1
print("✅ 已创建新特征 'FamilySize'。")# IsAlone: 是否独自一人
full_df['IsAlone'] = (full_df['FamilySize'] == 1).astype(int)
print("✅ 已创建新特征 'IsAlone'。")# 2.4 移除不再需要的列
# 'Name', 'Ticket', 'Cabin' 对简单的模型来说难以直接使用,我们先移除它们
# 'SibSp' 和 'Parch' 的信息已经被 'FamilySize' 包含
print("\n移除不再需要的原始列...")
cols_to_drop = ['Name', 'Ticket', 'Cabin', 'SibSp', 'Parch']
full_df.drop(columns=cols_to_drop, inplace=True)
print(f"✅ 已移除列: {cols_to_drop}")# 2.5 将预处理后的数据分离回训练集和测试集
print("\n分离回训练集和测试集...")
# Survived == -1 的是我们的测试集数据
train_processed_df = full_df[full_df['Survived'] != -1]
test_processed_df = full_df[full_df['Survived'] == -1]# 移除测试集中的临时 'Survived' 列
test_processed_df.drop(columns=['Survived'], inplace=True)print(f"处理后的训练集形状: {train_processed_df.shape}")
print(f"处理后的测试集形状: {test_processed_df.shape}")# --- 步骤 3: 准备最终的训练和测试数据 ---
print("\n--- 步骤 3: 准备最终的训练和测试数据 ---")
# 定义特征 (X) 和目标 (y)
X = train_processed_df.drop(columns=['Survived', 'PassengerId'])
y = train_processed_df['Survived']
X_test = test_processed_df.drop(columns=['PassengerId']) # 确保测试集的列与训练集一致# 确保训练集和测试集的列完全一致且顺序相同
# (独热编码可能导致列不一致,不过因为我们是先合并再处理,所以这里通常没问题)
X_test = X_test[X.columns]print(f"最终特征集 X 的形状: {X.shape}")
print(f"最终测试集 X_test 的形状: {X_test.shape}")# --- 步骤 4: 模型训练 ---
print("\n--- 步骤 4: 模型训练 (使用随机森林) ---")
# 初始化随机森林分类器
# n_estimators: 森林中树的数量
# max_depth: 树的最大深度,用于防止过拟合
# random_state: 确保结果可复现
model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=42)# 在整个训练集上训练模型
model.fit(X, y)
print("✅ 模型训练完成!")# (可选) 查看特征重要性
# feature_importances = pd.Series(model.feature_importances_, index=X.columns).sort_values(ascending=False)
# print("\n特征重要性排名:")
# print(feature_importances)# --- 步骤 5: 在测试集上进行预测并生成提交文件 ---
print("\n--- 步骤 5: 进行预测并生成提交文件 ---")
# 使用训练好的模型对测试集进行预测
predictions = model.predict(X_test)
# 将预测结果转换为整数类型
predictions = predictions.astype(int)# 创建提交文件
submission = pd.DataFrame({'PassengerId': test_passenger_ids,'Survived': predictions
})# 保存提交文件为 CSV
output_filename = 'titanic_submission.csv'
submission.to_csv(output_filename, index=False)
print(f"🎉 预测完成!提交文件已保存为 '{output_filename}'")
print("\n提交文件预览:")
print(submission.head())