商务互联 网站南宁网络公司
目录
一、什么是DQN?
二、基本原理
三、训练过程
四、应用场景
五、PPO策略梯度算法
六、DQN 算法
一、什么是DQN?
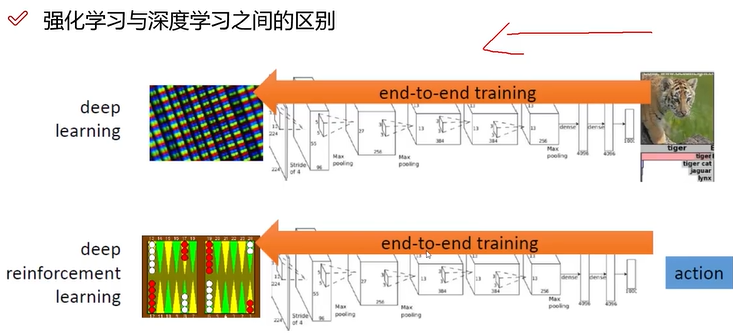
DQN Deep Q-Network (DQN) 是一种强化学习算法,它使用深度神经网络来估计Q值函数。Q值函数用于评估在特定状态下采取某一动作的预期回报。
二、基本原理
- Q值函数:Q值函数表示在某个状态下采取某个动作后,未来可能获得的总奖励。传统的Q学习方法使用一个表格来存储每个状态-动作对的Q值,但在复杂环境中,这种方法会遇到维度灾难问题。
- 深度神经网络:DQN使用深度神经网络来近似Q值函数,从而能够处理高维状态空间。神经网络的输入是当前状态,输出是所有可能动作的Q值。
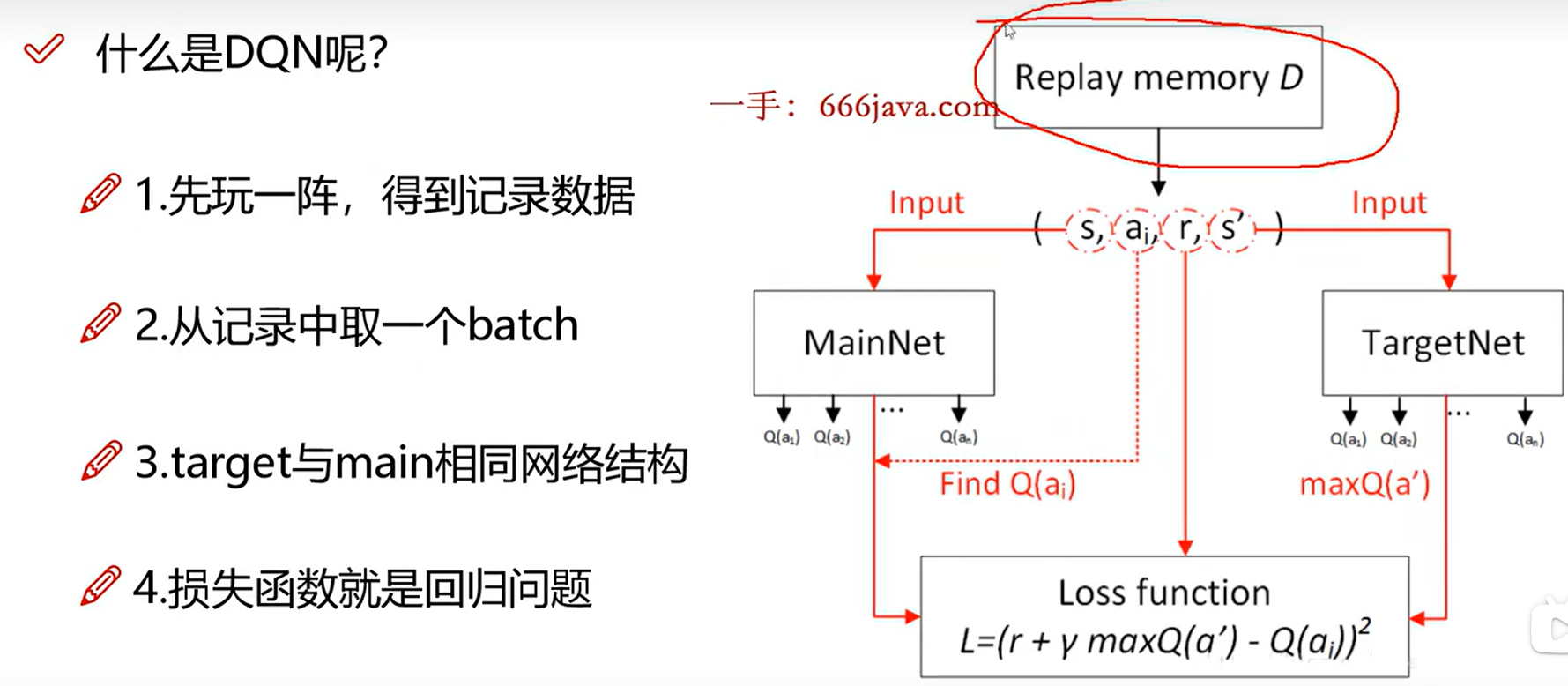
- 经验回放:为了打破数据之间的相关性,DQN使用一个经验回放缓冲区,存储智能体在环境中经历的状态、动作、奖励和下一个状态的元组。每次训练时,从缓冲区随机抽取小批量样本进行训练。
- 目标网络:DQN引入了一个目标网络,用于稳定训练过程。目标网络的参数在一定的时间间隔内更新,以减少训练过程中的波动。
三、训练过程
- 与环境交互:智能体在环境中采取动作并获得奖励,同时记录下当前状态、动作、奖励和下一个状态。
- 更新Q值:使用深度神经网络来预测当前状态下所有动作的Q值,并根据贝尔曼方程更新Q值。
- 经验回放:从经验回放缓冲区中随机抽取样本进行训练,以打破数据之间的相关性。
- 更新目标网络:定期更新目标网络的参数,以稳定训练过程。
四、应用场景
DQN在多个领域取得了显著成果,包括游戏、机器人控制和自动驾驶等
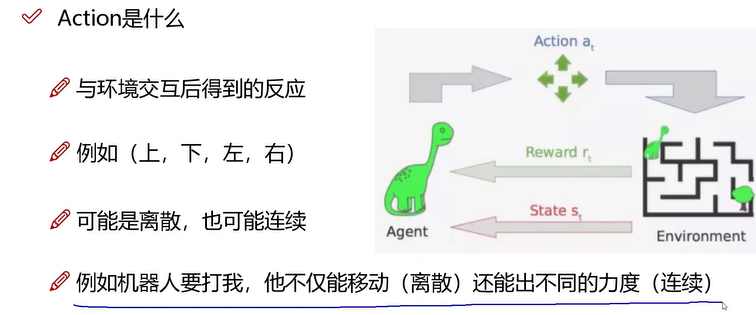
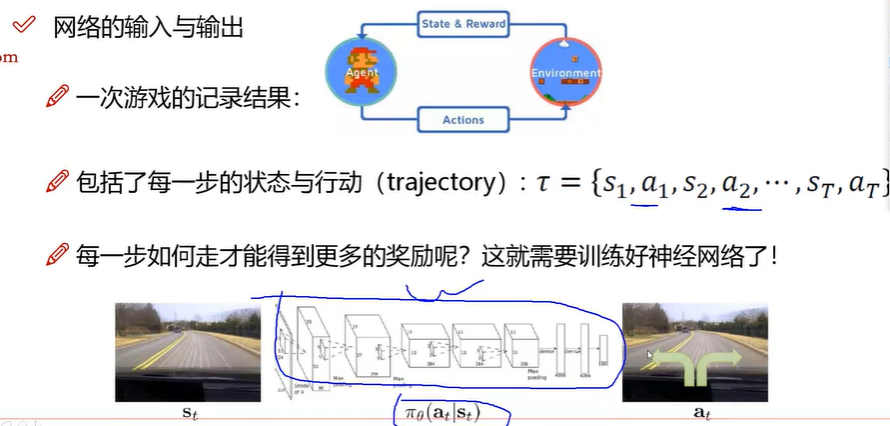
目标:每一个行动(左/右),都会产生一种状态,对应一个奖励,落到指定的范围,会有更多的奖励

当前的环境(状态),智能体观察环境之后会输出一个动作(上下左右),执行完动作后对应的环境(状态)也会随之改变,智能体会产生下一个动作。

行为是什么,是智能体,控制对象决策的行为:
强化学习是一个会决策的网络,根据action和奖励来更新网络:
五、PPO策略梯度算法
智能体根据环境状态和奖励决策出一个动作,进而影响当前的环境状态和对应的奖惩值,每一步都有状态和行动。
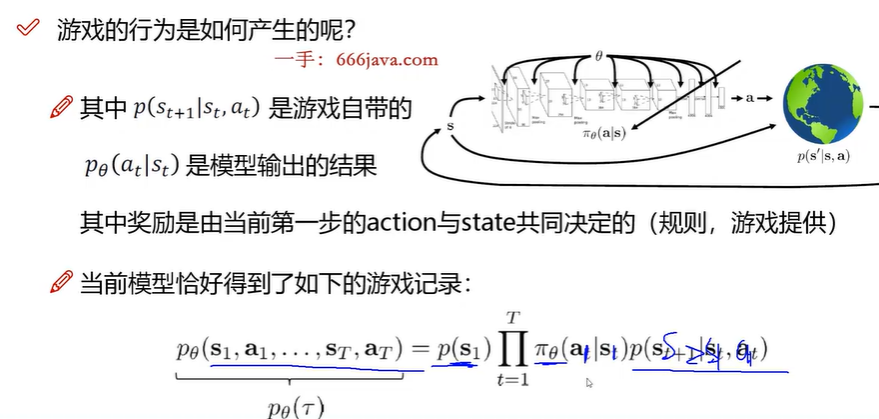
训练学习的目的是梯度下降法获得一个θ


如何设计奖惩值,设置baseline

什么是在线离线策略:
在线策略:每玩一局游戏就去训练一次获得更新后的θ,进行下一次训练学习
离线策略Off Policy:agent只负责学习不跟环境进行交互,数据由其他者获取

把On policy 改为 Off policy把前一轮的结果当作当前的替代。
六、DQN 算法
6.1 Q-learning


输入当前状态,做了action 动作A之后,会得到一个即时的奖惩值R
Q(s,a)等于当前瞬时奖励r(s,a) + 下一时刻收益最大奖励值(执行了哪个动作)*学习率(下一步跟当前有距离), 这是我们的Y值
常规的Q矩阵如下:

迭代Q矩阵:
-
奖励矩阵(R矩阵):
- 定义:R矩阵定义了在特定状态下执行特定动作所能获得的即时奖励。它是一个状态-动作对的奖励表。
- 作用:R矩阵提供了环境的即时反馈,帮助智能体了解哪些动作在当前状态下是有利的。
-
Q矩阵(Q-table):
- 定义:Q矩阵记录了在每个状态下执行每个动作的预期累积奖励。它是一个状态-动作对的价值表。
- 作用:Q矩阵通过迭代更新,逐渐逼近最优策略。它帮助智能体在每个状态下选择最优动作,以最大化长期累积奖励。
-
关系:
- 更新规则:Q矩阵的更新基于贝尔曼方程:
Q(s,a)=R(s,a)+γmaxa′Q(s′,a′)Q(s,a)=R(s,a)+γa′maxQ(s′,a′)
其中,s是当前状态,a是当前动作,R(s, a)是即时奖励,gamma是折扣因子,s'是下一状态,a'是下一状态下的动作。 - 迭代过程:在每一步中,智能体根据当前状态选择动作,执行动作后获得即时奖励,并根据新的状态更新Q值。这个过程不断重复,直到Q矩阵收敛到最优值。
- 更新规则:Q矩阵的更新基于贝尔曼方程:
6.2 Deep Q-learning Net
DQN是解决Qlearning针对无数种状态的场景,比如一张图有无数像素
第一个网络是主网络输入S,A; 第二个网络是目标网络,相当于max中的最大值Q(s,a),标签值;两个网络结构是一样的;
1).初始化网络
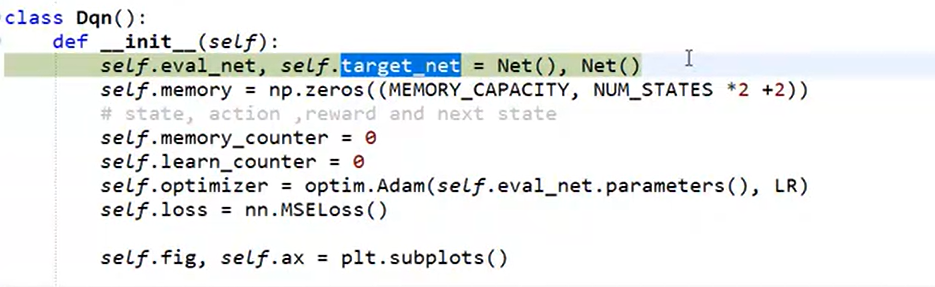
2).选择行为
state:x,y
层数,2层,30个神经元
action: 左移,右移,不动
self.eval_net.forward是根据状态得到每个action的值
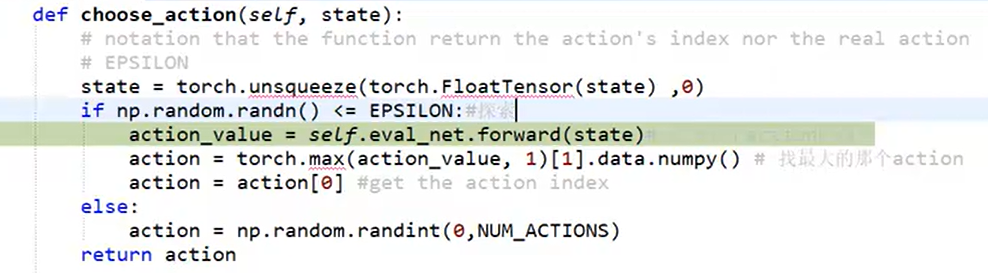
3)取到最大值的action后,直接执行,然后会获得,下一步状态next_state,即时奖励reward(规则设定的顺势奖励), 以此来收集数据。

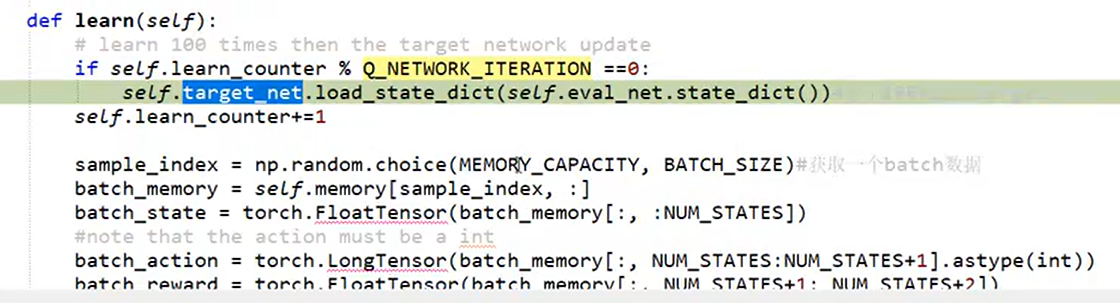
4).Target网络和主网络关系
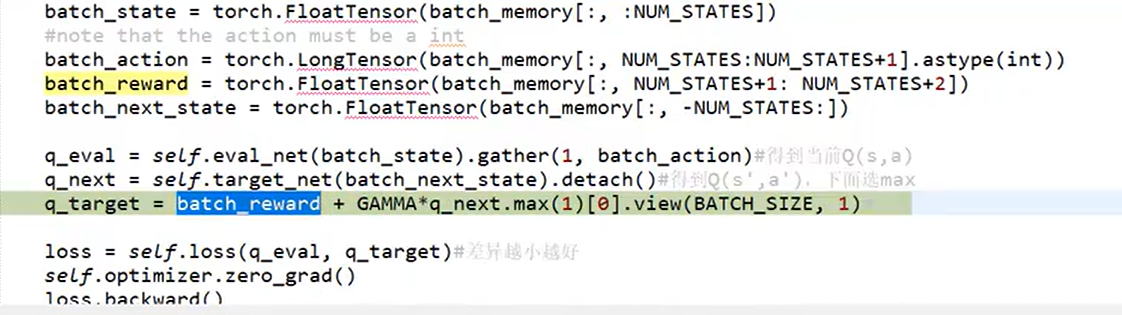
target网络的wb参数直接只用主网络更新100次之后的值,从MEMORY_CAPACITY = 2000步数据中,选取BATCH_SIZE=32个数据进行学习,每个数据是一个四元组(state,action,reward,next_state)
计算标签target Q值和实际Q值(因为当前state和当前action是已知的,所以可以求出Q值 ):