如可做网站如何自己开发一个平台
一、引言
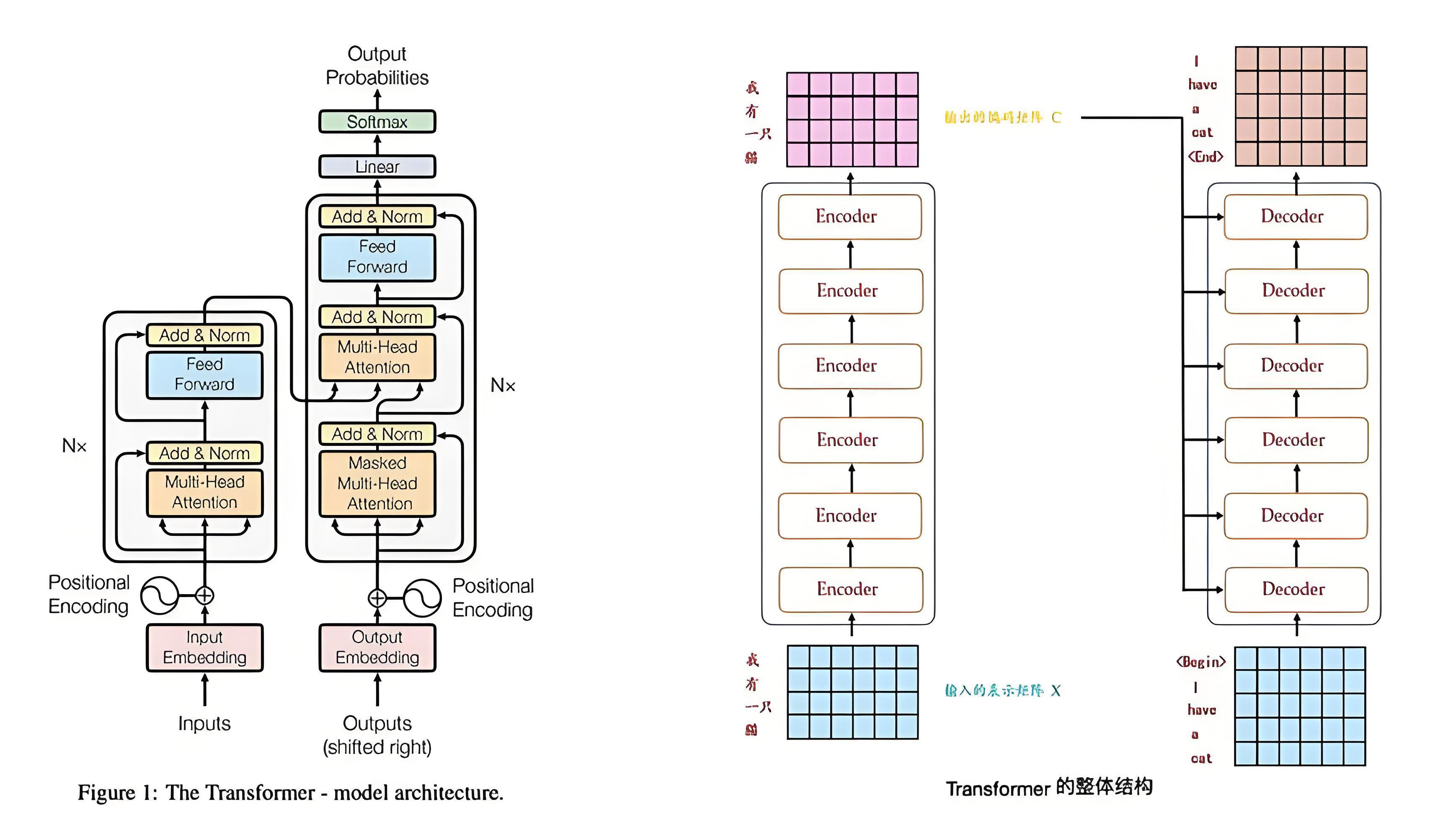
Transformer 作为现代自然语言处理(NLP)的基石,其核心在于自注意力机制(Self-Attention)和位置编码(Positional Encoding)。自 2017 年论文《Attention Is All You Need》提出以来,Transformer 已成为 BERT、GPT 等模型的底层架构。本文将从原理到代码实现,详细解析 Transformer 的核心组件。
二、Transformer 架构概览
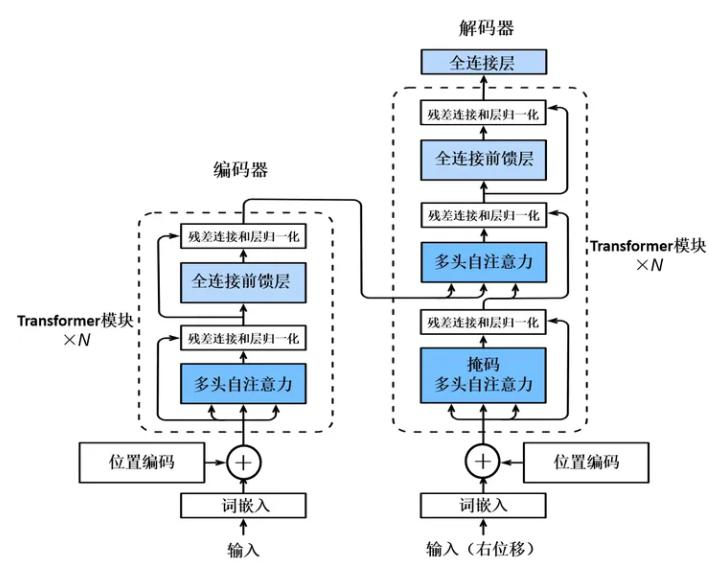
Transformer 由编码器(Encoder)和解码器(Decoder)组成,两者均包含多头自注意力层(Multi-Head Self-Attention)和前馈神经网络(Feed-Forward Neural Network)。编码器负责将输入序列编码为上下文向量,解码器基于该向量生成输出序列。
三、自注意力机制(Self-Attention)
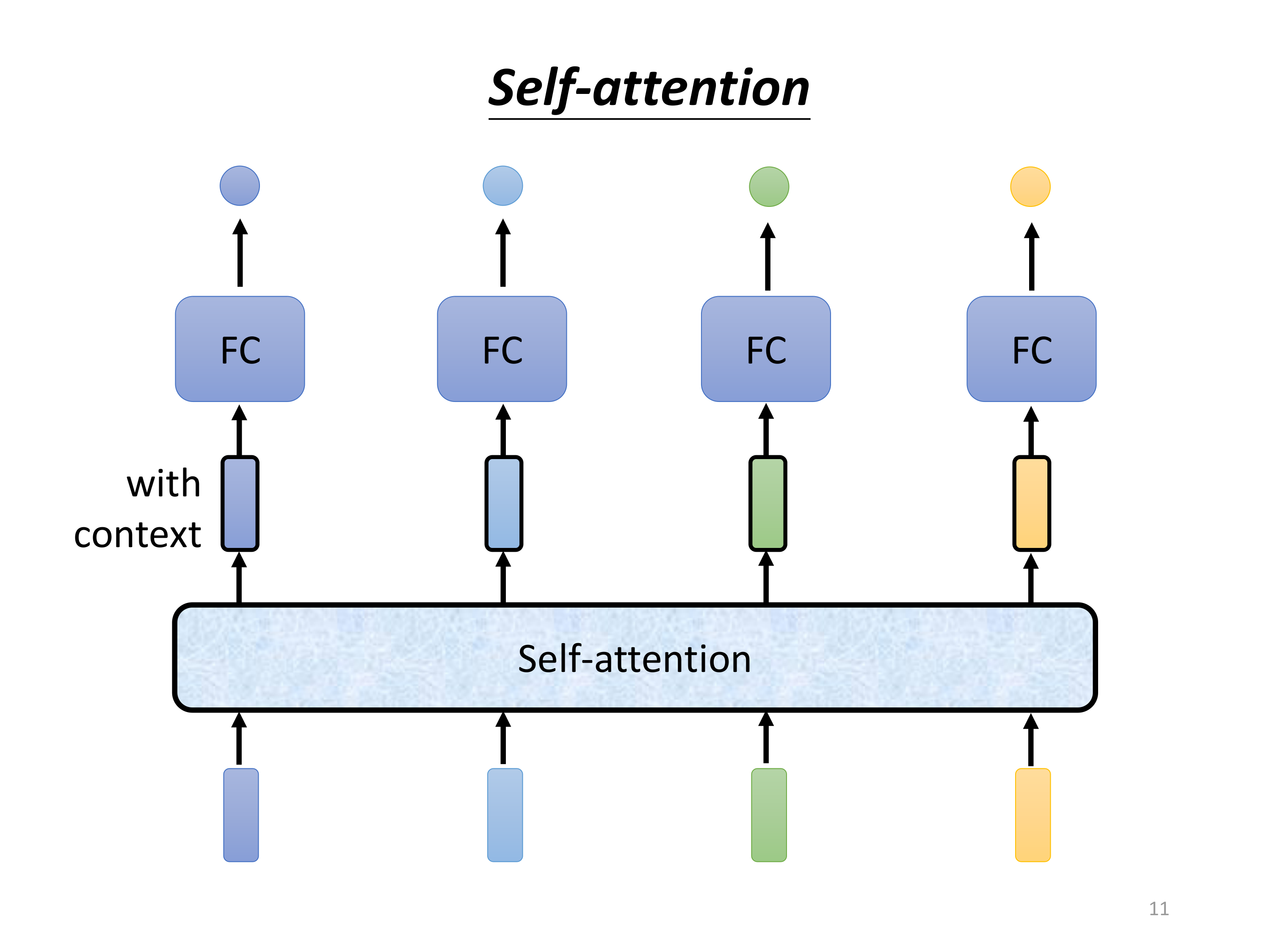
3.1 核心思想
自注意力机制通过计算序列中每个位置与其他位置的相关性,动态生成上下文表示。其核心公式为:
Attention(Q,K,V)=softmax(dkQKT)V
其中,Q(查询)、K(键)、V(值)由输入向量通过线性变换得到。
3.2 计算步骤
- 线性投影:输入向量 X 分别乘以三个权重矩阵 WQ、WK、WV,得到 Q、K、V。
- 点积计算:计算 Q 和 KT 的点积,得到注意力得分矩阵。
- 缩放与归一化:除以 dk 防止梯度消失,应用 softmax 得到归一化权重。
- 加权求和:将权重矩阵与 V 相乘,得到最终输出。
3.3 多头注意力(Multi-Head Attention)
多头注意力将输入分割为多个子空间,每个头独立计算注意力,最后拼接结果:
MultiHead(Q,K,V)=Concat(head1,…,headh)WO
其中,每个头的计算与单头注意力相同,但使用不同的权重矩阵。
3.4 PyTorch 实现
python
import torch
import torch.nn as nn
import torch.nn.functional as Fclass SelfAttention(nn.Module):def __init__(self, d_model, d_k, d_v):super().__init__()self.q = nn.Linear(d_model, d_k)self.k = nn.Linear(d_model, d_k)self.v = nn.Linear(d_model, d_v)def forward(self, x):Q = self.q(x)K = self.k(x)V = self.v(x)scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(d_k, dtype=torch.float32))weights = F.softmax(scores, dim=-1)output = torch.matmul(weights, V)return outputclass MultiHeadAttention(nn.Module):def __init__(self, d_model, num_heads):super().__init__()self.d_k = d_model // num_headsself.d_v = d_model // num_headsself.heads = nn.ModuleList([SelfAttention(d_model, self.d_k, self.d_v) for _ in range(num_heads)])self.fc = nn.Linear(num_heads * self.d_v, d_model)def forward(self, x):head_outputs = [head(x) for head in self.heads]concatenated = torch.cat(head_outputs, dim=-1)return self.fc(concatenated)
四、位置编码(Positional Encoding)
4.1 必要性
自注意力机制不依赖顺序,因此需位置编码注入顺序信息。Transformer 采用正弦和余弦函数生成位置编码:
PE(pos,2i)=sin(100002i/dmodelpos)
PE(pos,2i+1)=cos(100002i/dmodelpos)
其中,pos 是位置,i 是维度。
4.2 优势
- 可扩展性:可处理任意长度序列。
- 相对位置:PE(pos+k) 可由 PE(pos) 和 PE(k) 表示,便于模型捕捉相对位置关系。
4.3 PyTorch 实现
python
class PositionalEncoding(nn.Module):def __init__(self, d_model, max_len=512):super().__init__()pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-torch.log(torch.tensor(10000.0)) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0)self.register_buffer('pe', pe)def forward(self, x):return x + self.pe[:, :x.size(1)]
五、残差连接与层归一化
5.1 残差连接(Residual Connection)
为缓解梯度消失,Transformer 在每个子层(自注意力或前馈网络)后添加残差连接:
Output=LayerNorm(x+SubLayer(x))
5.2 层归一化(Layer Normalization)
对每个样本的特征维度进行归一化,稳定训练过程:
LayerNorm(x)=γσx−μ+β
其中,γ 和 β 是可学习参数。
5.3 PyTorch 实现
python
class ResidualConnection(nn.Module):def __init__(self, d_model, dropout=0.1):super().__init__()self.norm = nn.LayerNorm(d_model)self.dropout = nn.Dropout(dropout)def forward(self, x, sublayer):return x + self.dropout(sublayer(self.norm(x)))
六、掩码机制(Masking)
6.1 因果掩码(Causal Mask)
解码器在生成序列时,需防止看到未来信息。因果掩码将未来位置的注意力权重置为负无穷:
python
def create_causal_mask(seq_len):mask = torch.triu(torch.ones(seq_len, seq_len), diagonal=1)return mask.masked_fill(mask == 1, float('-inf'))
6.2 填充掩码(Padding Mask)
处理变长序列时,需忽略填充位置的影响:
python
def create_padding_mask(seq, pad_token_id):return (seq == pad_token_id).unsqueeze(1).unsqueeze(2)
七、Transformer 完整实现
python
class TransformerEncoder(nn.Module):def __init__(self, d_model, num_heads, d_ff, dropout=0.1):super().__init__()self.self_attn = MultiHeadAttention(d_model, num_heads)self.ffn = nn.Sequential(nn.Linear(d_model, d_ff),nn.ReLU(),nn.Linear(d_ff, d_model))self.residual1 = ResidualConnection(d_model, dropout)self.residual2 = ResidualConnection(d_model, dropout)def forward(self, x, padding_mask):x = self.residual1(x, lambda x: self.self_attn(x, padding_mask))x = self.residual2(x, self.ffn)return xclass TransformerDecoder(nn.Module):def __init__(self, d_model, num_heads, d_ff, dropout=0.1):super().__init__()self.self_attn = MultiHeadAttention(d_model, num_heads)self.cross_attn = MultiHeadAttention(d_model, num_heads)self.ffn = nn.Sequential(nn.Linear(d_model, d_ff),nn.ReLU(),nn.Linear(d_ff, d_model))self.residual1 = ResidualConnection(d_model, dropout)self.residual2 = ResidualConnection(d_model, dropout)self.residual3 = ResidualConnection(d_model, dropout)def forward(self, x, memory, padding_mask, causal_mask):x = self.residual1(x, lambda x: self.self_attn(x, causal_mask))x = self.residual2(x, lambda x: self.cross_attn(x, memory, padding_mask))x = self.residual3(x, self.ffn)return x
八、应用案例:BERT 与 GPT
8.1 BERT(双向编码器)
BERT 使用 Transformer 编码器,通过掩码语言模型(MLM)和下一句预测(NSP)预训练,可用于文本分类、问答等任务:
python
from transformers import BertTokenizer, BertForSequenceClassificationtokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')text = "I love Transformer!"
inputs = tokenizer(text, return_tensors='pt')
outputs = model(**inputs)
8.2 GPT(自回归解码器)
GPT 使用 Transformer 解码器,通过自回归语言模型预训练,可用于文本生成:
python
from transformers import GPT2Tokenizer, GPT2LMHeadModeltokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')prompt = "Once upon a time"
inputs = tokenizer(prompt, return_tensors='pt')
outputs = model.generate(**inputs, max_length=50)
九、总结
Transformer 通过自注意力机制捕捉长距离依赖,位置编码注入顺序信息,残差连接和层归一化优化训练稳定性,掩码机制确保因果性。其架构已成为现代 NLP 的标配,推动了 BERT、GPT 等模型的发展。理解 Transformer 的核心原理,是深入研究自然语言处理的关键。