dedecms 把自己的网站添加进去微信里面的小程序怎么设置
目录
强化学习
强化学习的应用
电子游戏:太空侵略者
编辑
下围棋:AlphaGo
强化学习框架
step1:定义函数
step2:定义损失
step3:优化
评价动作的标准
Version 1:即时奖励作为评分标准
Version 2:累计奖励作为评分标准
Version 3:折扣累计奖励作为评分标准
Version 4:折扣累计奖励减去基线作为评分标准
Policy Gradient策略梯度方法
Actor-Critic演员-评论员
Critic常用的训练方法有两个
Monte-Carlo (MC)
Temporal-difference (TD)
Sparse Reward 稀疏奖励
强化学习
之前介绍的都是监督学习和子监督学习,比如说猫狗分类器,我们输入一张图片后知道最佳的输出就是“猫”,但是在很多情况下,最佳的输出是未知的,或者是收集有标注的数据是很困难的,这个时候可以考虑使用强化学习。在强化学习里面,机器可以和环境environment做交互,然后得到自己每一步行为获得的奖励reward,从而知道自己输出的好坏,强化学习的智能体观测环境,然后输出动作,动作输出之后会更新环境,再给智能体一个观测,以此重复进行。
强化学习的应用
电子游戏:太空侵略者
这个游戏是玩家控制一个飞船,可以左右移动和开火,上面的外星人会攻击玩家,中间橙色的是玩家的盾,玩家要尽可能击落外星人的同时又不可以击中自己的盾。
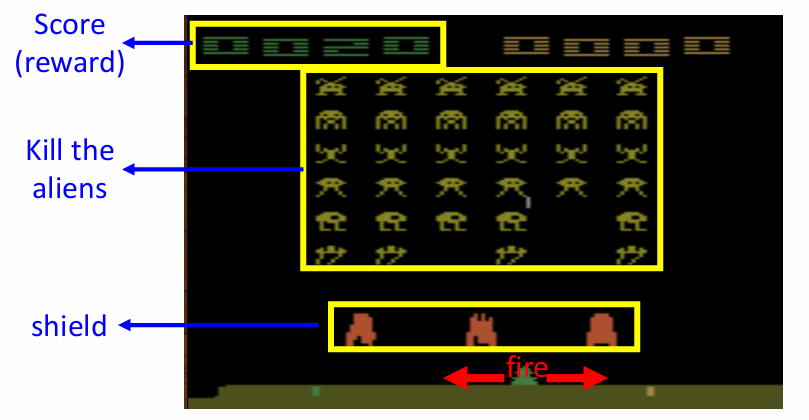
在这个游戏中,智能体充当人的角色,在观测环境之后给出一个操作,然后更新自己的奖励和环境。
下围棋:AlphaGo
下围棋的奖励是稀疏的,机器只有在赢了或者输了之后才会有±1分的奖励或惩罚。
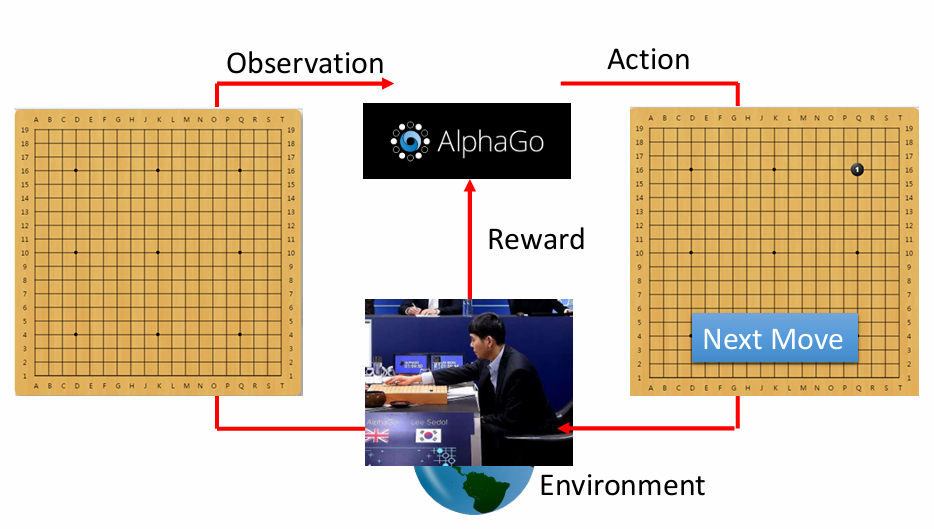
强化学习框架
step1:定义函数
有未知数的函数是一个智能体,在强化学习里,智能体是一个网络,称为策略网络,可以自己设计,只要能够做到输入环境输出动作即可,比如下面这个玩游戏的智能体,他计算出如果向左会得到0.7分,向右得到0.2分,攻击得到0.1分,这个分数是由最后一层的softmax分类器得到的,他会给每个类别一个分数并且分数的总和是1,通常是吧分数作为选择这个动作的概率而不是直接选择一个最大的分数的动作,因为我们的智能体很可能需要一些随机性,
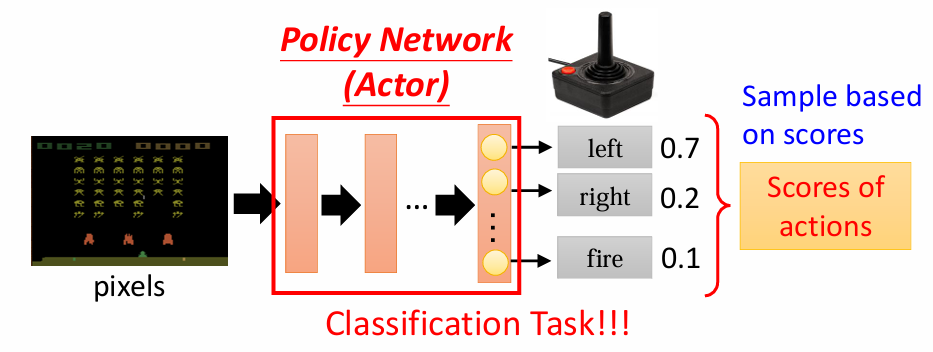
step2:定义损失
智能体在一个回合episode之后会获得自己的奖励reward,然后在进行完成这个游戏之后会获得自己的回报return,所以回报即为所有的奖励累加在一起得到的,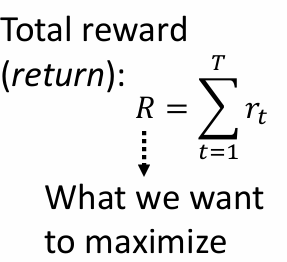
step3:优化
一个从头开始一直到游戏结束的序列叫做轨迹trajectory,优化的目的就是找一个参数,使得R越大越好。

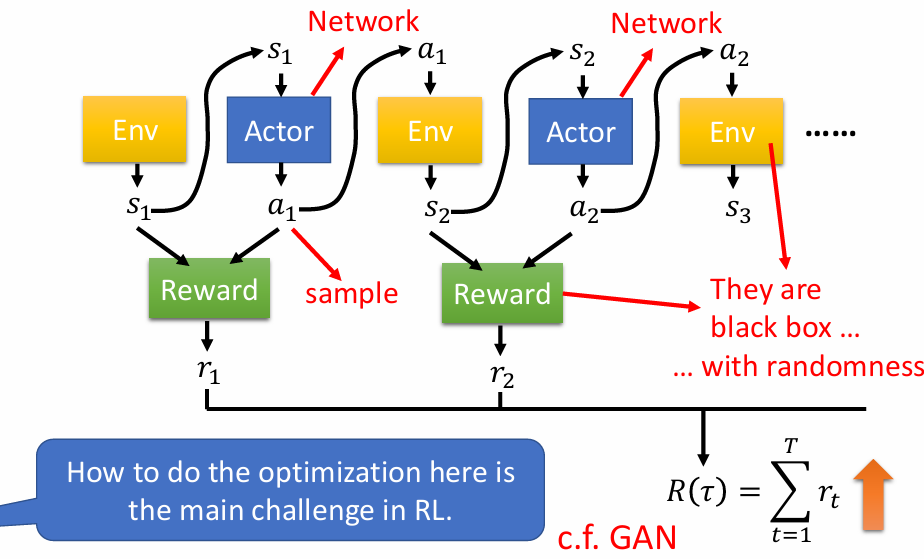
评价动作的标准
Version 1:即时奖励作为评分标准
在看到s1环境之后采取a1动作,然后获得r1的分数。
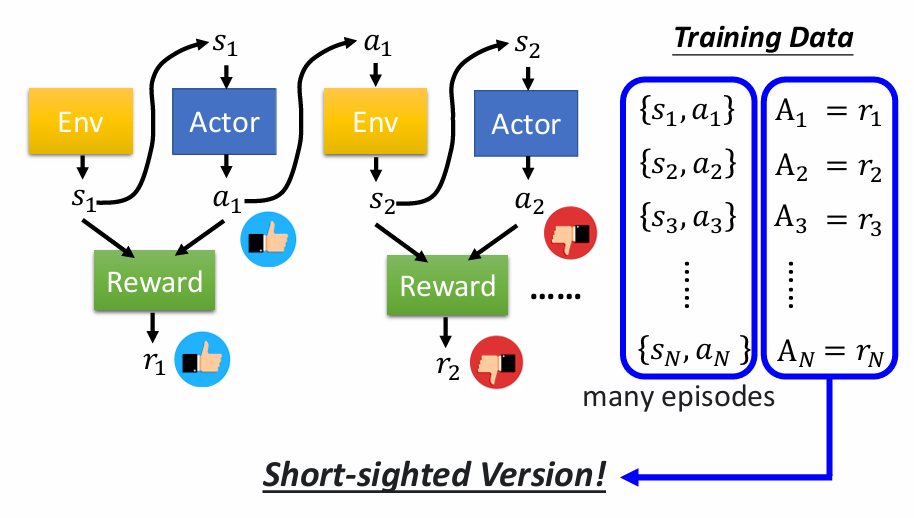
Version 2:累计奖励作为评分标准
在看到s1环境之后采取a1动作,但是a1的好坏不只是取决于r1获得的奖励,它取决于吧a1之后所有的动作,因为a1动作改变s1环境为s2,对后续的动作也会产生影响。
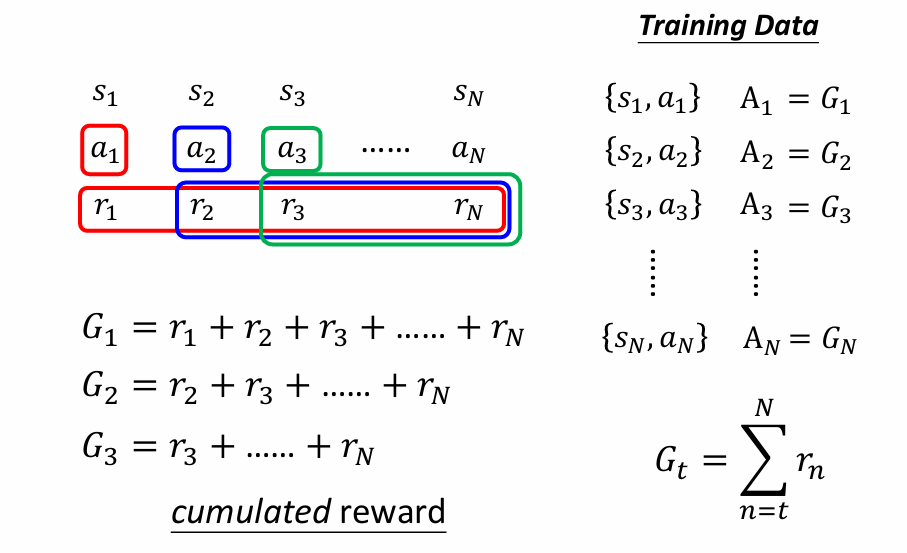
Version 3:折扣累计奖励作为评分标准
在计算的时候,可能越近的步骤获得的奖励是要占比更高的,把比例设置为r,计算方法如下所示。
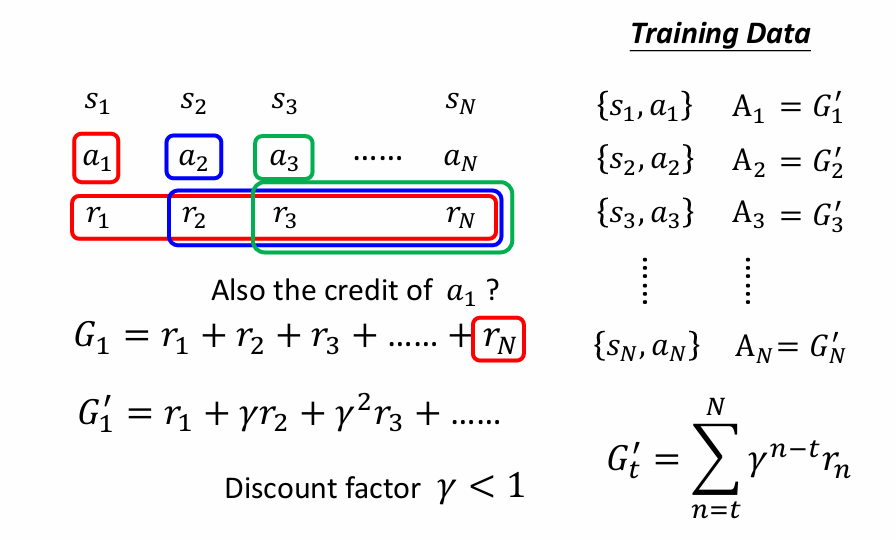
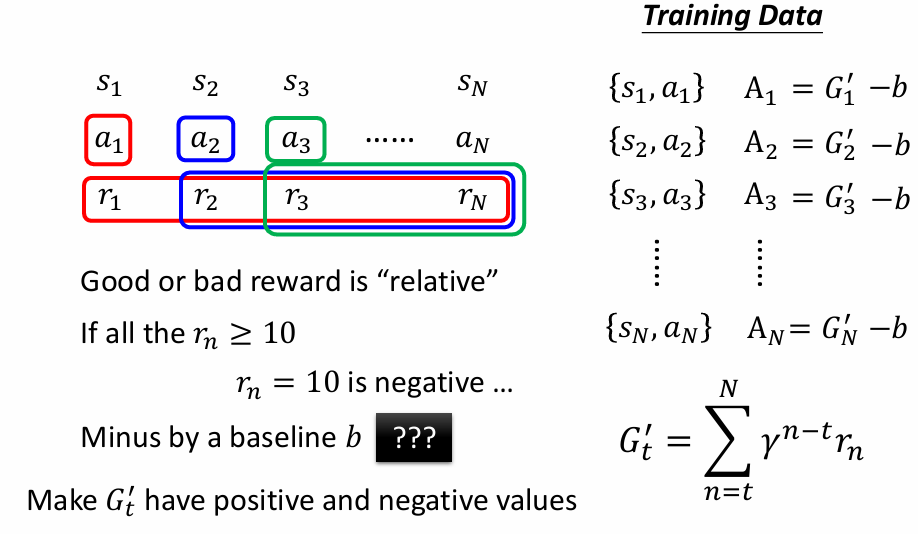
Version 4:折扣累计奖励减去基线作为评分标准
即为标准化操作,要让分数有正有负。
Policy Gradient策略梯度方法
在训练的时候,智能体要看到环境才能有所行动,但是行动会进一步改变环境,所以在进行下一轮的观测之后才会有行动,即为每次都要观测-行动-观测-行动,观测所需要的成本极高(因为在for循环的里面)。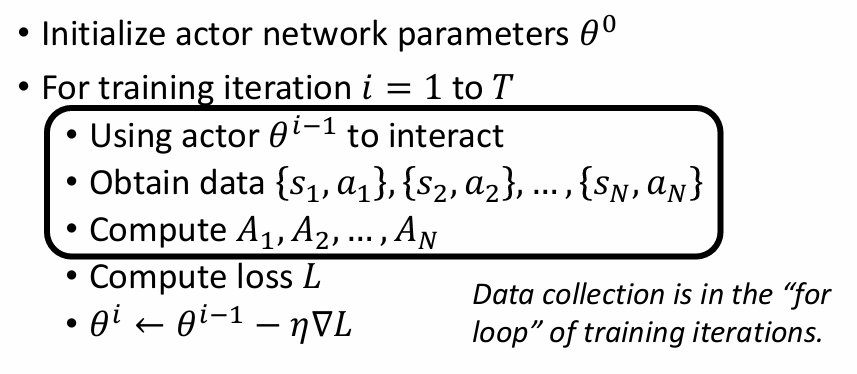
On-policy Gradient同策略梯度方法
The actor to train and the actor for interacting is the same.
Off-policy Gradient异策略梯度方法
The actor to train has to know its difference from the actor to interact.
Actor-Critic演员-评论员
Critic实际上就是一个价值函数,Actor实际上是一个智能体,让价值函数判断这个智能体这一步行动的分数。
Critic常用的训练方法有两个
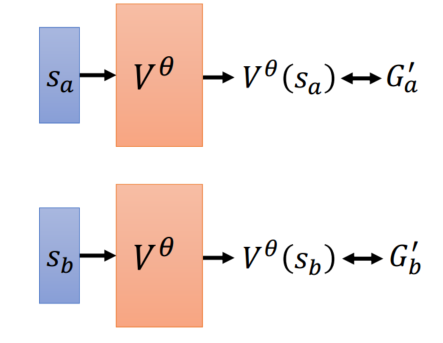
Monte-Carlo (MC)
把行动s输入到价值函数里面,得到预计出来的期望分数,与累计奖励越接近越好。
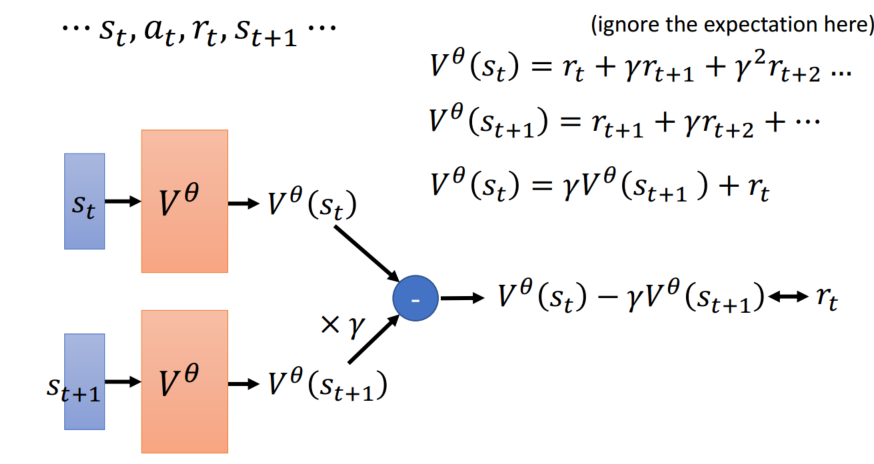
Temporal-difference (TD)
智能体无法打完一整个游戏(游戏不会结束)可以使用这个方法,
Sparse Reward 稀疏奖励
下围棋的时候只有最后才会有reward?这要求我们想办法在中间定义一些额外的reward的帮助及其进行学习。
Curiosityreward shipping好奇心奖励,如果机器发现新的有利的东西就给他加分?
如果真的完全没有reward,或者是reward没法定义怎么办?
那就用人类的示范让机器重复人类的行为。但这样有很多缺点。第一是机器要看到失败的处理方法,但这可能代价有点儿大,比如说在汽车的自动驾驶方面,机器要看到遇到车祸该怎么办?但是实际模拟车祸的话代价比较大,第二种缺点是可能有的行为不用模仿?但是机器会自动的模仿一些不相干的行为?增加了机器的压力?