通州富阳网站建设wordpress 文件大小
文章目录
- 1、Python GIL(全局解释器锁)
- 一、GIL 导致伪并发的核心机制
- 二、伪并发的表现与影响
- 1. CPU 密集型任务:多线程无效甚至负优化
- 2. I/O 密集型任务:多线程有效
- 3. 伪并发本质
- 三、为什么需要 GIL?设计初衷
- 四、解决 GIL 限制的方案
- 2、多线程和多进程
- 核心区别
- 实现方式与代码示例
- 1. 多线程实现(`threading`模块)
- 2. 多进程实现(`multiprocessing`模块)
- 高级用法
- 线程池/进程池(高效管理资源)
- 进程间通信(IPC)
- 选择建议
- 注意事项
- 3、threading.Thread 的方法与属性详解
- 一、核心方法与属性
- 二、线程创建示例
- 方式 1:函数式(推荐)
- 方式 2:继承 `Thread` 类
- 三、等待所有结果返回并汇总
- 方法 1:共享变量 + 锁(适合简单场景)
- 方法 2:队列(Queue)通信(线程安全)
- 方法 3:线程池(高效管理,推荐)
- 总结
1、Python GIL(全局解释器锁)
GIL(全局解释器锁)是 CPython 解释器的核心机制,它导致 Python 多线程在 CPU 密集型任务中仅能实现“伪并发”(即逻辑上的并发,非物理并行)。
一、GIL 导致伪并发的核心机制
-
单线程执行限制
GIL 是一个全局互斥锁,任何线程执行 Python 字节码前必须获取 GIL。同一时刻仅有一个线程能持有 GIL,其他线程被阻塞,形成串行化执行。-
示例:
# 线程工作流程伪代码 while True:with GIL: # 竞争获取 GILexecute_bytecode() # 执行 Python 代码if io_operation: # 遇到 I/O 时释放 GILrelease_gil()
-
-
时间片切换策略
- 固定间隔释放:线程每执行约 5ms(Python 3+)或 1000 条字节码指令后,强制释放 GIL。
- 竞争不公平性:释放 GIL 后,原线程可能立即重新获取,导致其他线程长时间饥饿(尤其 CPU 密集型循环)。
-
I/O 操作的特殊性
线程执行 I/O 操作(如网络请求、文件读写)时会主动释放 GIL,此时其他线程可获取 GIL 执行代码,实现 I/O 等待期的并发利用。
二、伪并发的表现与影响
1. CPU 密集型任务:多线程无效甚至负优化
-
性能对比:
线程数 任务类型 执行时间 原因 1 线程 计算 1 亿次累加 10 秒 单线程独占 CPU 2 线程 各计算 5 千万次 20 秒 GIL 切换开销 + 线程竞争 4 线程 各计算 2.5 千万次 40 秒 时间线性增长,多核无法利用 -
代码验证:
import threading, time def cpu_task():sum = 0for _ in range(100_000_000): # 1亿次计算sum += 1# 单线程:约10秒 start = time.time() cpu_task() print(f"单线程耗时: {time.time() - start:.2f}s")# 双线程:约20秒 t1 = threading.Thread(target=cpu_task) t2 = threading.Thread(target=cpu_task) t1.start(); t2.start() t1.join(); t2.join() print(f"双线程耗时: {time.time() - start:.2f}s")
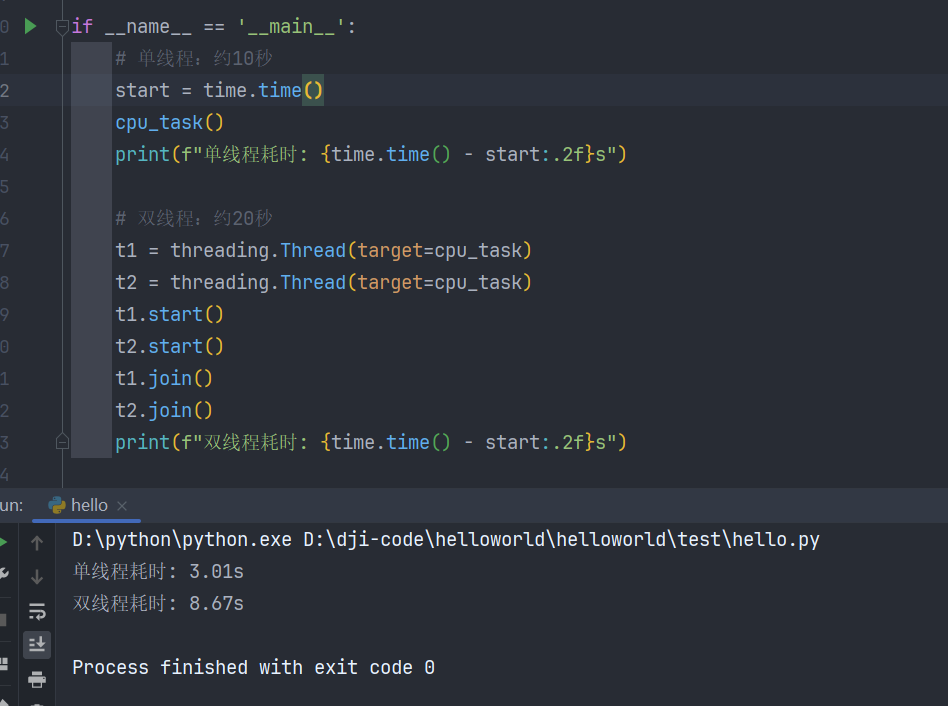
2. I/O 密集型任务:多线程有效
当任务含 I/O 阻塞时(如网络请求),线程在等待期间释放 GIL,其他线程可执行代码,显著提升效率。
示例场景:
- 爬虫并发下载(线程在等待响应时释放 GIL)
- Web 服务器处理请求(I/O 等待占比高)
3. 伪并发本质
- 伪并发本质:GIL 强制多线程串行执行字节码,仅通过时间片切换和 I/O 释放模拟“并发”。
- 性能影响:
- ✅ I/O 密集型:多线程有效(等待期释放 GIL)
- ❌ CPU 密集型:多线程无效(切换开销 > 收益)
三、为什么需要 GIL?设计初衷
- 简化内存管理
CPython 使用引用计数管理内存,GIL 避免多线程同时修改引用计数导致内存泄漏或崩溃。 - 保护 C 扩展兼容性
早期 C 扩展库非线程安全,GIL 降低其开发复杂度。 - 提升单线程性能
无锁竞争的单线程执行更快(历史硬件多为单核)。
四、解决 GIL 限制的方案
| 方案 | 适用场景 | 原理 | 优势 |
|---|---|---|---|
| 多进程 | CPU 密集型任务 | 每个进程独立 GIL,利用多核 CPU | 真并行,绕过 GIL |
| C 扩展 | 关键计算模块 | 用 C/C++ 实现核心逻辑,释放 GIL | 无 GIL 限制,高性能 |
| 异步编程 | 高并发 I/O 任务 | 单线程事件循环,非阻塞 I/O | 避免线程切换开销 |
| 换用解释器 | 需真并行的场景 | 使用 Jython(无 GIL)或 PyPy | 彻底摆脱 GIL,但生态兼容性差 |
2、多线程和多进程
在Python中,多线程(multithreading)和多进程(multiprocessing)是实现并发的两种主要方式,它们有本质区别且适用于不同场景。以下是详细对比和实现方法:
核心区别
| 特性 | 多线程 | 多进程 |
|---|---|---|
| 内存空间 | 共享同一进程内存空间 | 每个进程有独立内存空间 |
| GIL影响 | 受GIL限制,CPU密集型任务无法并行 | 无GIL限制,可真正并行执行CPU任务 |
| 创建开销 | 开销小,创建快 | 开销大,创建慢 |
| 数据共享 | 可直接共享数据(需线程同步) | 需通过IPC(管道、队列等)共享数据 |
| 容错性 | 一个线程崩溃会导致整个进程崩溃 | 进程间隔离,单个进程崩溃不影响其他 |
| 适用场景 | I/O密集型任务(网络请求、文件读写等) | CPU密集型任务(计算、数据处理等) |
📌 关键点:Python的GIL(全局解释器锁)导致多线程无法利用多核CPU执行并行计算,但多进程可以绕过此限制。
实现方式与代码示例
1. 多线程实现(threading模块)
import threading
import timedef task(name):print(f"Thread {name}: starting")time.sleep(2) # 模拟I/O操作print(f"Thread {name}: finished")# 创建并启动线程
threads = []
for i in range(3):t = threading.Thread(target=task, args=(i,))threads.append(t)t.start()# 等待所有线程结束
for t in threads:t.join()
print("All threads done")
2. 多进程实现(multiprocessing模块)
import multiprocessing
import timedef compute(name):print(f"Process {name}: starting")result = sum(i*i for i in range(10**7)) # 模拟CPU计算print(f"Process {name}: finished ({result})")if __name__ == '__main__': # ⚠️ Windows系统必须加此保护processes = []for i in range(3):p = multiprocessing.Process(target=compute, args=(i,))processes.append(p)p.start()for p in processes:p.join()print("All processes done")
高级用法
线程池/进程池(高效管理资源)
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor# I/O密集型任务用线程池
with ThreadPoolExecutor(max_workers=4) as executor:executor.map(task, range(5))# CPU密集型任务用进程池
if __name__ == '__main__':with ProcessPoolExecutor(max_workers=4) as executor:executor.map(compute, range(5))
进程间通信(IPC)
# 使用Queue共享数据
import multiprocessingdef worker(q):q.put("Hello from child!")if __name__ == '__main__':queue = multiprocessing.Queue()p = multiprocessing.Process(target=worker, args=(queue,))p.start()print(queue.get()) # 输出: Hello from child!p.join()
选择建议
| 场景 | 推荐方案 | 原因 |
|---|---|---|
| 网络请求/文件读写 | 多线程 | I/O等待释放GIL,线程切换开销小 |
| 图像处理/数据计算 | 多进程 | 避开GIL限制,利用多核CPU |
| 混合型任务(I/O+计算) | 多进程+线程池 | 进程处理计算,线程处理I/O |
注意事项
- 线程安全:多线程操作共享数据时需用
Lock避免竞争。 - 进程启动:Windows系统必须用
if __name__ == '__main__'保护入口。 - 资源开销:进程数不超过CPU核心数(
multiprocessing.cpu_count())。
3、threading.Thread 的方法与属性详解
threading.Thread 是 Python 多线程编程的核心类,提供线程创建、管理和同步功能。
一、核心方法与属性
| 类型 | 名称 | 说明 | 示例 |
|---|---|---|---|
| 方法 | start() | 启动线程,自动调用 run() 方法 | t.start() |
run() | 线程执行入口,需在子类中重写 | class MyThread(Thread): def run(self): ... | |
join(timeout=None) | 阻塞当前线程,等待目标线程结束(timeout 为超时时间) | t.join() 等待线程完成 | |
is_alive() | 检查线程是否在运行(启动后且未终止) | if t.is_alive(): print("运行中") | |
| 属性 | name | 线程名称(可自定义,无默认语义) | t = Thread(name="Worker-1") |
ident | 线程唯一标识符(非零整数) | print(t.ident) | |
daemon | 守护线程标志(True:主线程结束则终止;False:默认,需等待执行完成) | t.daemon = True 或 t = Thread(daemon=True) |
二、线程创建示例
方式 1:函数式(推荐)
import threading
import timedef task(num):print(f"线程 {threading.current_thread().name} 开始")time.sleep(1)return num * num # 返回计算结果# 创建并启动线程
threads = []
results = []
for i in range(3):t = threading.Thread(target=task, args=(i,))t.start()threads.append(t)# 等待所有线程结束
for t in threads:t.join()# 注意:直接获取返回值需自定义存储(见第三节)
print("所有线程完成")
方式 2:继承 Thread 类
class CalcThread(threading.Thread):def __init__(self, num):super().__init__()self.num = numself.result = None # 存储结果def run(self):self.result = self.num * self.num# 使用线程
threads = [CalcThread(i) for i in range(3)]
for t in threads:t.start()
for t in threads:t.join()
results = [t.result for t in threads] # 获取所有结果
print(f"汇总结果: {results}") # 输出: [0, 1, 4]
三、等待所有结果返回并汇总
方法 1:共享变量 + 锁(适合简单场景)
import threadingshared_results = []
lock = threading.Lock()def task(num):with lock: # 加锁避免竞争result = num * numshared_results.append(result)threads = [threading.Thread(target=task, args=(i,)) for i in range(3)]
for t in threads: t.start()
for t in threads: t.join()
print(f"汇总结果: {shared_results}") # 输出: [0, 1, 4]
方法 2:队列(Queue)通信(线程安全)
import threading
import queueresult_queue = queue.Queue()def task(num):result_queue.put(num * num) # 结果放入队列threads = [threading.Thread(target=task, args=(i,)) for i in range(3)]
for t in threads: t.start()
for t in threads: t.join()results = []
while not result_queue.empty():results.append(result_queue.get())
print(f"汇总结果: {results}") # 输出: [0, 1, 4]
方法 3:线程池(高效管理,推荐)
from concurrent.futures import ThreadPoolExecutordef task(num):return num * numwith ThreadPoolExecutor(max_workers=3) as executor:futures = [executor.submit(task, i) for i in range(3)]results = [future.result() for future in futures] # 阻塞直到所有完成print(f"汇总结果: {results}") # 输出: [0, 1, 4]
优势:自动管理线程生命周期,支持回调(
add_done_callback)和超时控制。
总结
- 基础操作:使用
start()启动线程,join()等待结束,daemon控制守护行为。 - 结果汇总:
- 少量线程 → 共享变量 + 锁(需手动同步)
- 复杂场景 → 队列(线程安全)
- 高效任务 → 线程池(
ThreadPoolExecutor,自动结果收集)
- 避坑指南:
- 避免直接操作全局变量(需用锁)
- 守护线程(
daemon=True)勿用于需返回结果的任务(可能未执行完即终止)。