自己做的网站显示不全九江建设监督网站
目录
引言
1 增量数据导入概述
1.1 增量同步与全量同步对比
1.2 增量同步技术选型矩阵
2 Sqoop增量导入原理剖析
2.1 Sqoop架构设计
2.2 增量同步核心机制
3 Sqoop增量模式详解
3.1 append模式(基于自增ID)
3.2 lastmodified模式(基于时间戳)
3.3 merge模式(增量合并)
4 案例方案设计
4.1 自动化增量同步架构
4.2 分区表增量策略
5 性能优化
5.1 并行度调优矩阵
5.2 高级参数配置
5.3 数据压缩策略
6 常见问题解决方案
6.1 数据一致性问题
6.2 时区处理方案
6.3 大表同步策略
7 结论
引言
在企业级数据仓库建设中,增量数据同步是ETL流程中的核心环节。如何利用Sqoop工具实现关系型数据库到Hive的高效增量数据导入,掌握增量同步的各种模式、Sqoop调优技巧以及企业级解决方案,构建可靠的数据管道。
1 增量数据导入概述
1.1 增量同步与全量同步对比
增量同步核心优势:
- 效率高:仅传输变化数据,减少I/O和网络开销
- 延迟低:可实现准实时数据同步
- 资源省:降低对源系统压力
- 成本优:节省存储和计算资源
1.2 增量同步技术选型矩阵
| 工具 | 实时性 | 复杂度 | 数据量 | 适用场景 |
| Sqoop | 分钟级 | 中 | 大 | 结构化数据批同步 |
| CDC工具 | 秒级 | 高 | 中 | 事务数据捕获 |
| 双写 | 实时 | 高 | 小 | 高一致性要求 |
| 日志解析 | 近实时 | 很高 | 中 | 无修改权限场景 |
2 Sqoop增量导入原理剖析
2.1 Sqoop架构设计
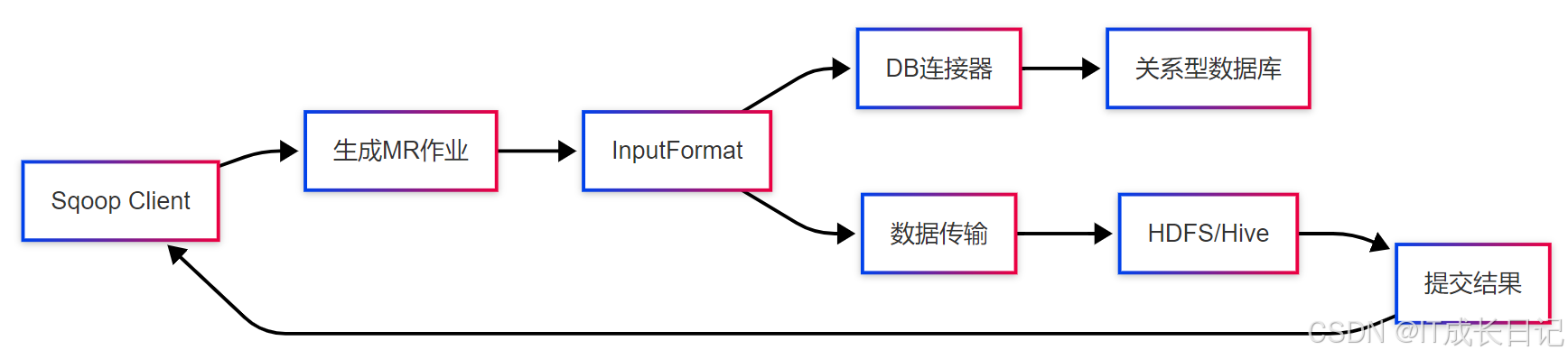
组件说明:
- Connector:数据库特定插件,实现与各种数据库的交互
- InputFormat:控制数据分片和读取逻辑
- MR作业:实际执行数据转移的MapReduce任务
2.2 增量同步核心机制
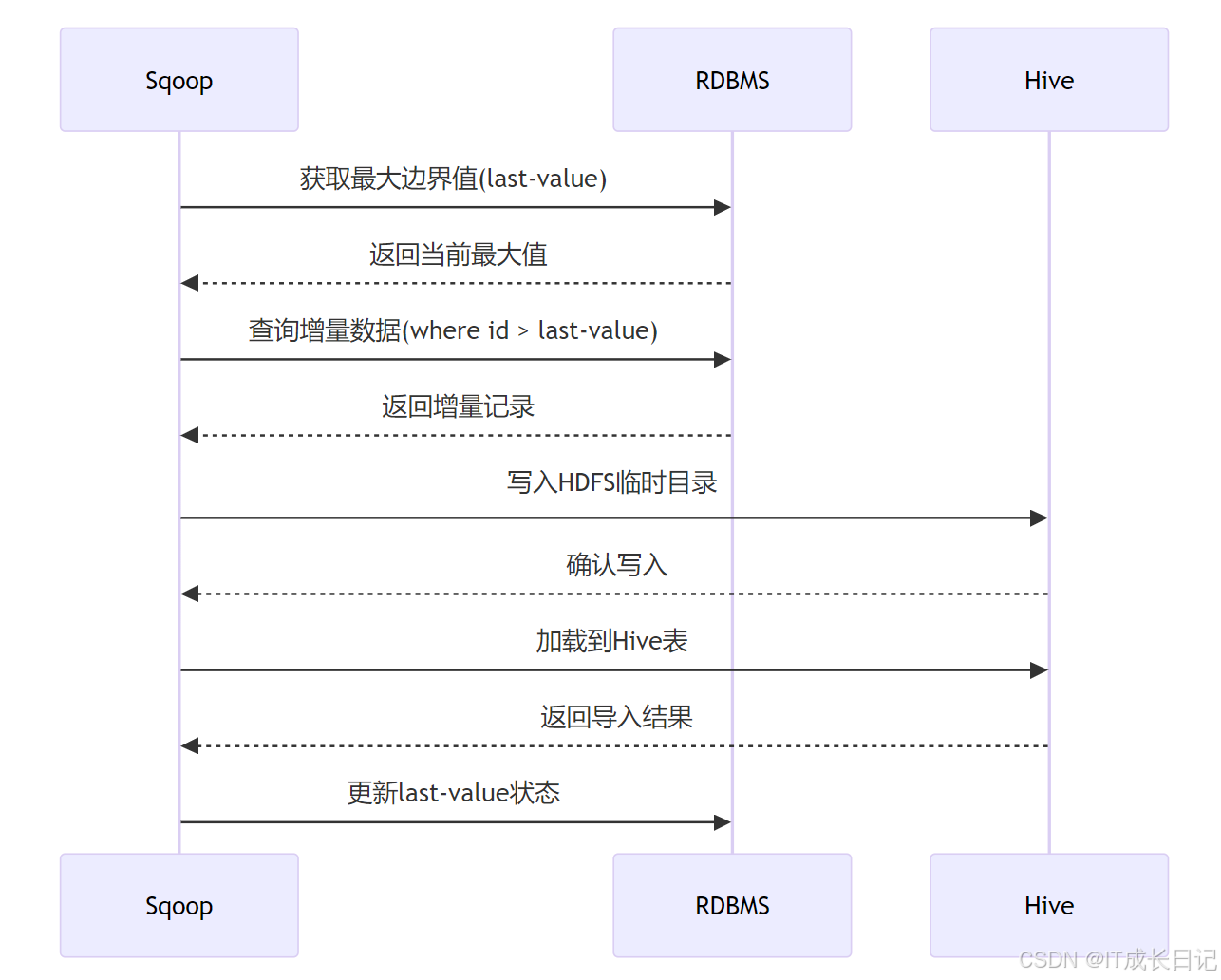
3 Sqoop增量模式详解
3.1 append模式(基于自增ID)
适用场景:
- 包含自增主键的表
- 只追加不更新的数据(如日志表)
-- 创建目标Hive表
CREATE TABLE orders (order_id INT,customer_id INT,order_date TIMESTAMP,amount DECIMAL(10,2)
) STORED AS ORC;- Sqoop命令示例:
sqoop job --create inc_order_import \
-- import \
--connect jdbc:mysql://mysql-server:3306/sales \
--username etl_user \
--password-file /user/password.txt \
--table orders \
--hive-import \
--hive-table orders \
--incremental append \
--check-column order_id \
--last-value 0 \
--split-by order_id3.2 lastmodified模式(基于时间戳)
适用场景:
- 包含更新时间戳的表
- 需要捕获新增和修改的记录

- 关键参数:
--incremental lastmodified \
--check-column update_time \
--last-value "2025-05-03 00:00:00" \
--append3.3 merge模式(增量合并)
-- 目标表需支持ACID
CREATE TABLE customer_merge (id INT,name STRING,email STRING,last_update TIMESTAMP
) STORED AS ORC TBLPROPERTIES ('transactional'='true');- Sqoop命令示例:
sqoop import \
--connect jdbc:oracle:thin:@//oracle-host:1521/ORCL \
--username scott \
--password tiger \
--table customers \
--hive-import \
--hive-table customer_merge \
--incremental lastmodified \
--check-column last_update \
--last-value "2023-01-01" \
--merge-key id4 案例方案设计
4.1 自动化增量同步架构
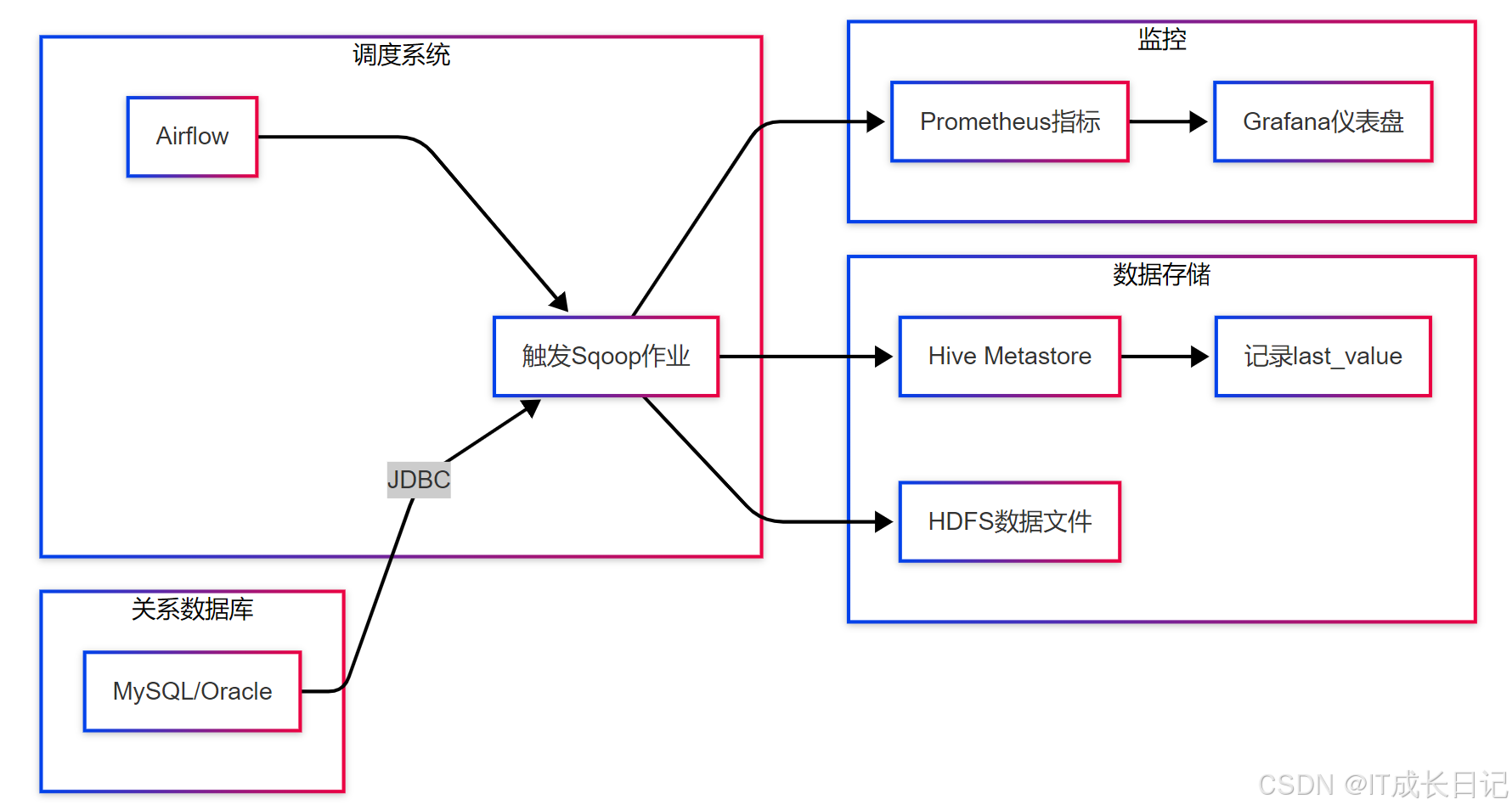
关键组件:
- 状态存储:将last-value持久化到Hive Metastore或专用表
- 作业编排:使用Airflow/Oozie调度增量作业
- 失败处理:实现自动重试和告警机制
4.2 分区表增量策略
- 按日分区表示例:
CREATE TABLE sales_partitioned (id INT,product STRING,quantity INT,update_time TIMESTAMP
) PARTITIONED BY (dt STRING)
STORED AS PARQUET;- 增量同步脚本:
#!/bin/bash
LAST_DATE=$(hive -e "SELECT MAX(dt) FROM sales_partitioned")
CURRENT_DATE=$(date +%Y-%m-%d)
sqoop import \
--connect jdbc:postgresql://pg-server/db \
--table sales \
--where "update_time BETWEEN '$LAST_DATE' AND '$CURRENT_DATE'" \
--hive-import \
--hive-table sales_partitioned \
--hive-partition-key dt \
--hive-partition-value $CURRENT_DATE \
--incremental lastmodified \
--check-column update_time \
--last-value "$LAST_DATE"5 性能优化
5.1 并行度调优矩阵
| 数据量 | 建议mappers | 分割列选择 |
| 4-8 | 自增主键 | |
| 10-100GB | 8-16 | 均匀分布列 |
| >100GB | 16-32 | 复合键组合 |
5.2 高级参数配置
# 控制事务大小
--batch
--fetch-size 1000# 内存优化
-Dmapreduce.map.memory.mb=4096
-Dmapreduce.reduce.memory.mb=8192# 连接池配置
-Dsqoop.connection.pool.size=10
-Dsqoop.connection.pool.timeout=3005.3 数据压缩策略
-- 创建支持压缩的Hive表
CREATE TABLE compressed_orders (id INT,-- 其他列...
) STORED AS ORC
TBLPROPERTIES ("orc.compress"="SNAPPY");- Sqoop压缩参数:
--compress
--compression-codec org.apache.hadoop.io.compress.SnappyCodec6 常见问题解决方案
6.1 数据一致性问题
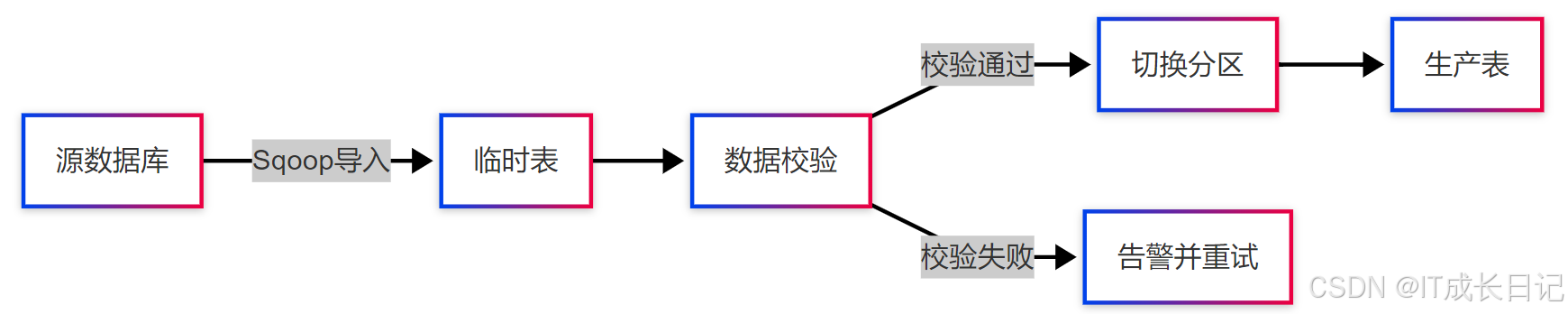
- 校验脚本示例:
-- 记录数比对
SELECT (SELECT COUNT(*) FROM rdb_table) AS source_count,(SELECT COUNT(*) FROM hive_temp_table) AS target_count,(SELECT COUNT(*) FROM hive_temp_table t JOIN rdb_table r ON t.id=r.id) AS match_count;6.2 时区处理方案
# 显式指定时区
-Duser.timezone=UTC
--map-column-java update_time=java.sql.Timestamp
--hive-overwrite
--hive-import6.3 大表同步策略
- 分片导入技术:
# 按ID范围分批导入
for i in {0..9}; dosqoop import \--query "SELECT * FROM big_table WHERE MOD(id,10)=$i AND \$CONDITIONS" \--split-by id \--target-dir /data/big_table/part=$i
done7 结论
本文探讨了基于Sqoop的Hive增量数据导入全流程。关键要点包括:
- 掌握append和lastmodified两种增量模式的适用场景
- 构建自动化、可监控的增量同步管道
- 实施性能优化策略应对不同规模数据
- 解决企业实践中遇到的典型问题
随着数据架构的演进,增量同步技术将持续发展,但核心原则不变:在保证数据一致性的前提下,实现高效、可靠的数据流动。建议读者根据实际业务需求,灵活应用本文介绍的各种技术和模式。