网站制作详细教程阿里云 上传wordpress
在大语言模型(LLMs)蓬勃发展的时代,推理能力成为衡量模型优劣的关键指标。今天为大家解读的这篇论文,介绍了小米的MiMo-7B模型,它通过独特的预训练和后训练优化,展现出强大的推理实力,快来一探究竟吧!
论文标题
MiMo: Unlocking the Reasoning Potential of Language Model – From Pretraining to Posttraining
来源
https://github.com/xiaomimimo/MiMo
文章核心
研究背景
当前,具有先进推理能力的大语言模型不断涌现,如OpenAI o系列、DeepSeek R1和Claude 3.7等,在复杂任务中表现出色。但大多数成功的强化学习工作依赖较大的基础模型,且在小模型中同时提升数学和代码能力颇具挑战。
研究问题
-
如何在预训练阶段提高数据质量和多样性,增强小模型的推理潜力?
-
后训练中,怎样设计有效的奖励机制和数据处理策略,解决稀疏奖励和采样效率问题,提升模型性能?
-
如何构建高效的强化学习基础设施,减少训练时间和资源浪费,提高训练效率?
主要贡献
1. 强化预训练:优化数据预处理流程,采用多阶段数据混合策略,引入MultiToken Prediction(MTP)目标,增强模型推理潜力,使MiMo-7B-Base在与其他同规模开源模型对比中表现卓越。
2. 创新后训练:精心整理高质量的数学和代码问题作为强化学习数据,设计测试难度驱动的奖励机制缓解稀疏奖励问题,实施数据重采样策略稳定训练,有效提升模型在数学和代码推理任务中的性能。
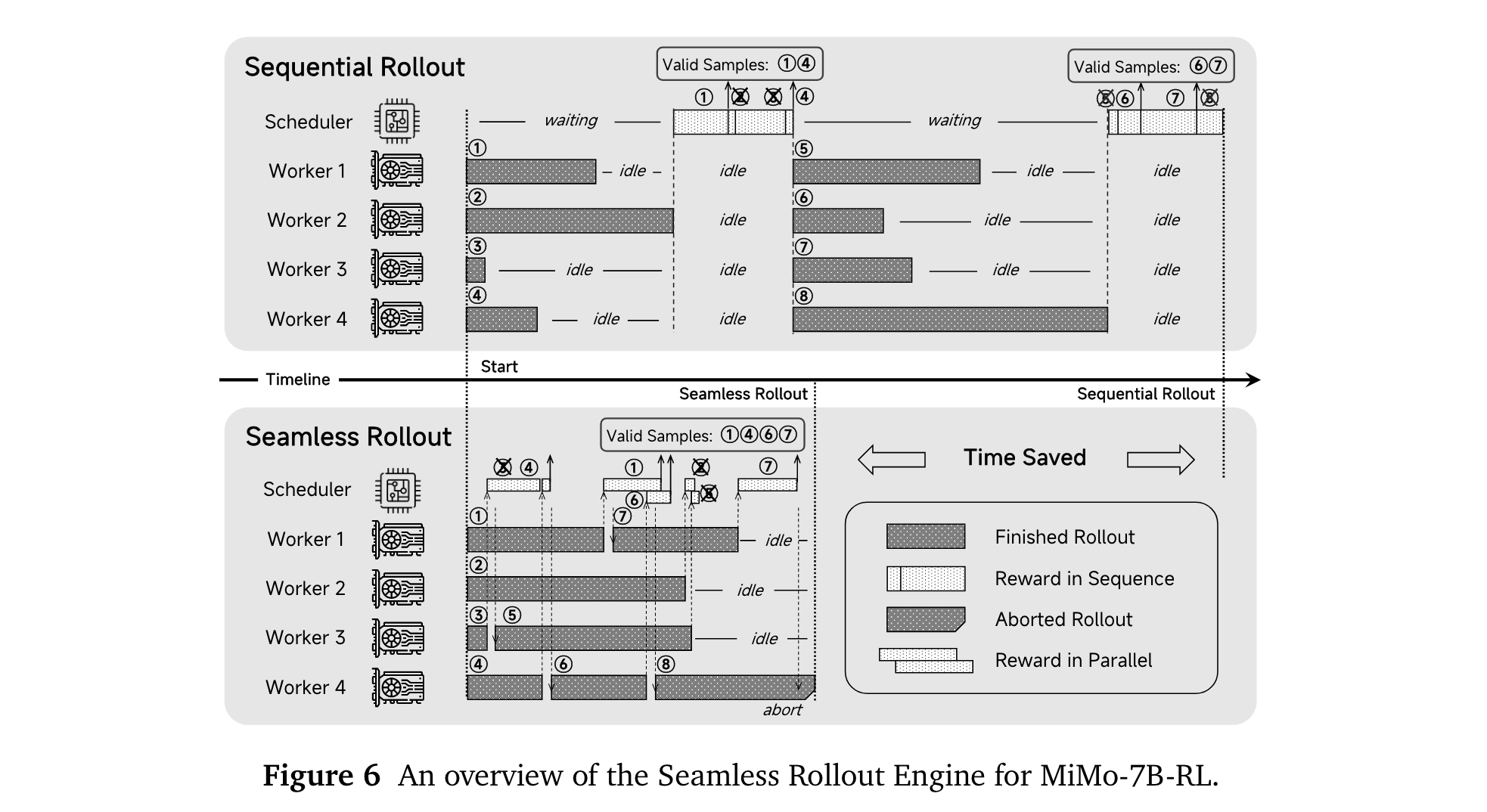
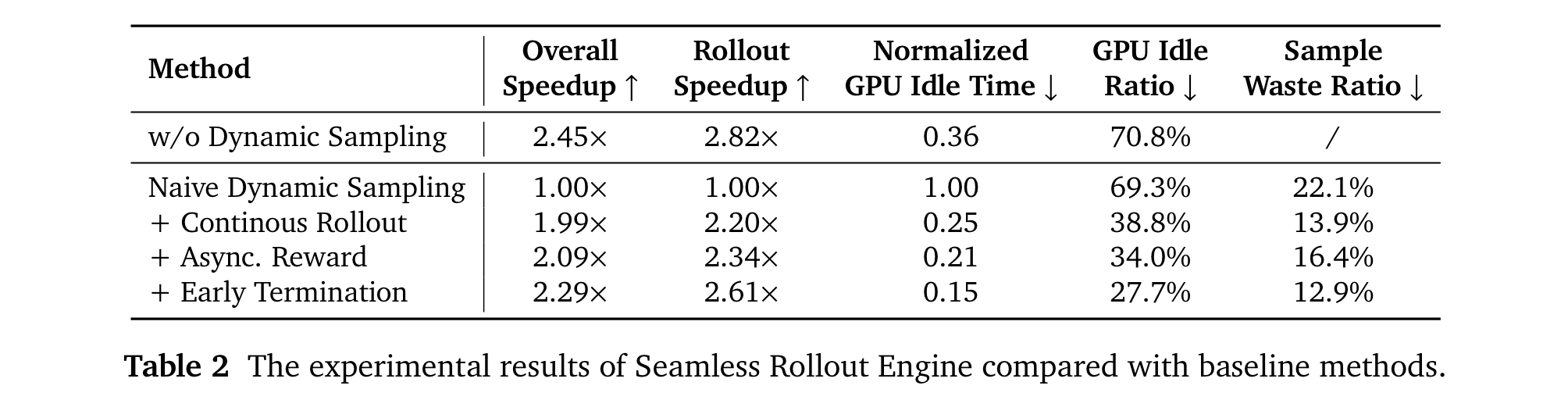
3. 优化基础设施:开发Seamless Rollout Engine加速强化学习训练和验证,增强vLLM推理引擎的鲁棒性并支持MTP,显著提高训练效率,减少GPU空闲时间。
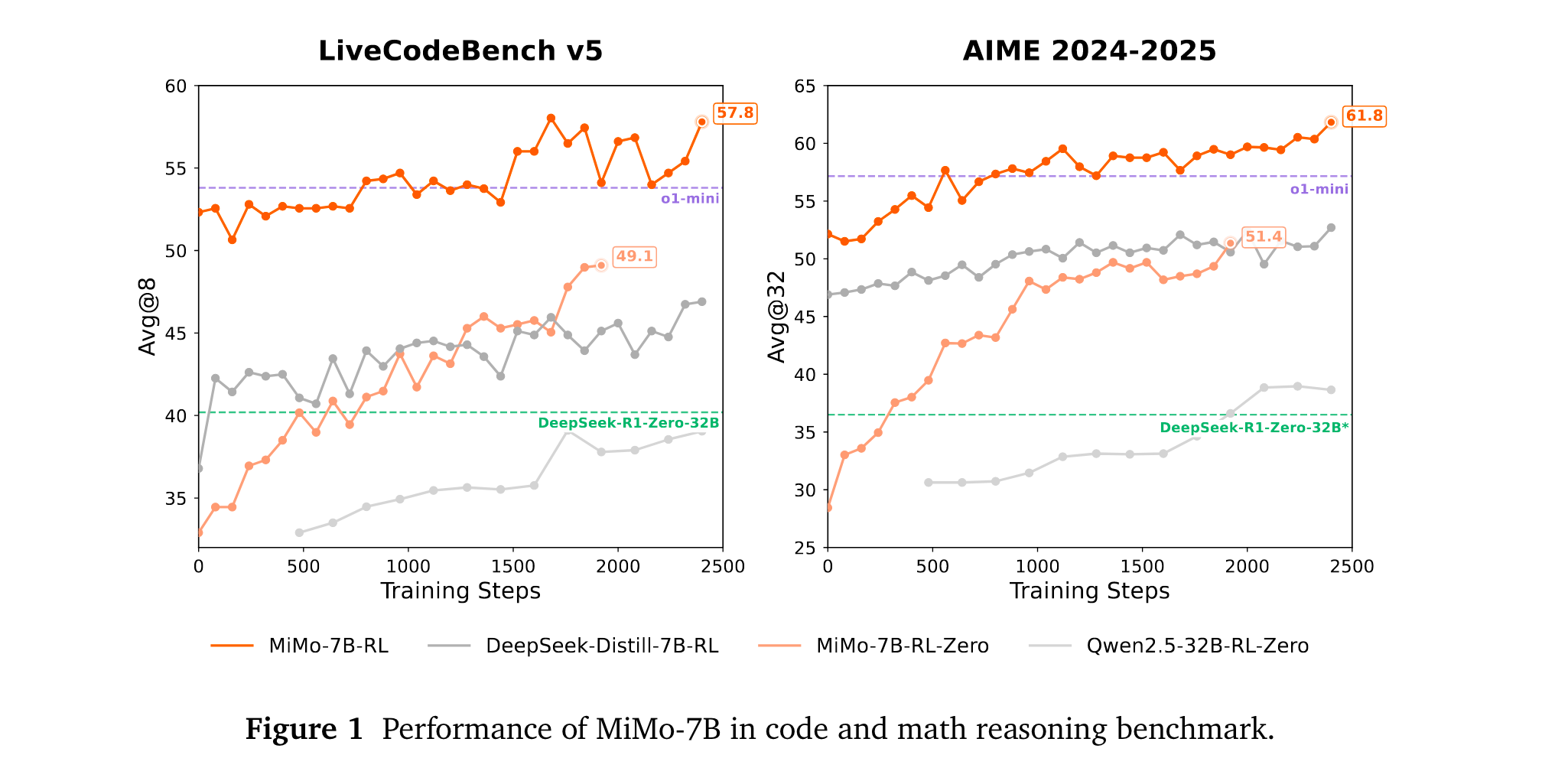
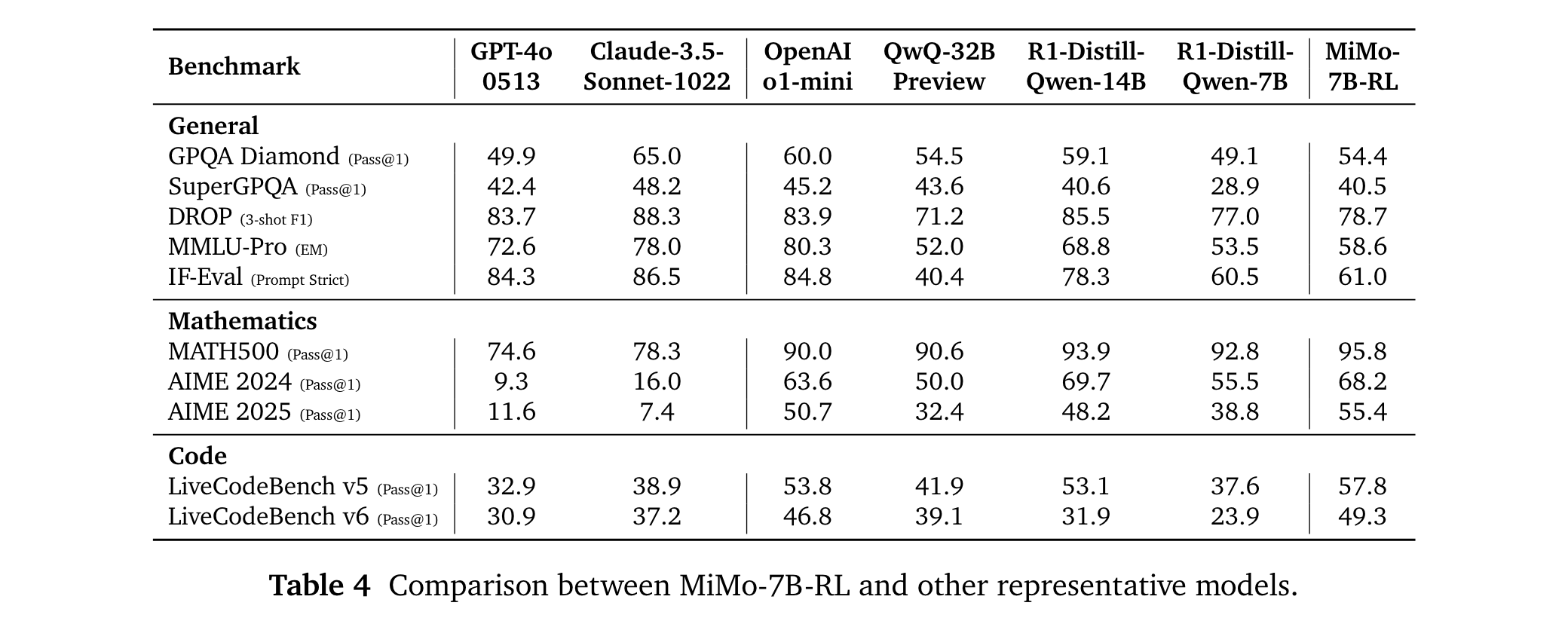
4. 模型性能卓越:MiMo-7B-RL在数学、代码和一般推理任务上表现优异,在AIME 2025上得分55.4,超过OpenAI o1-mini,在算法代码生成任务中也大幅领先。同时开源模型,为研究社区提供有价值的参考。
方法论精要
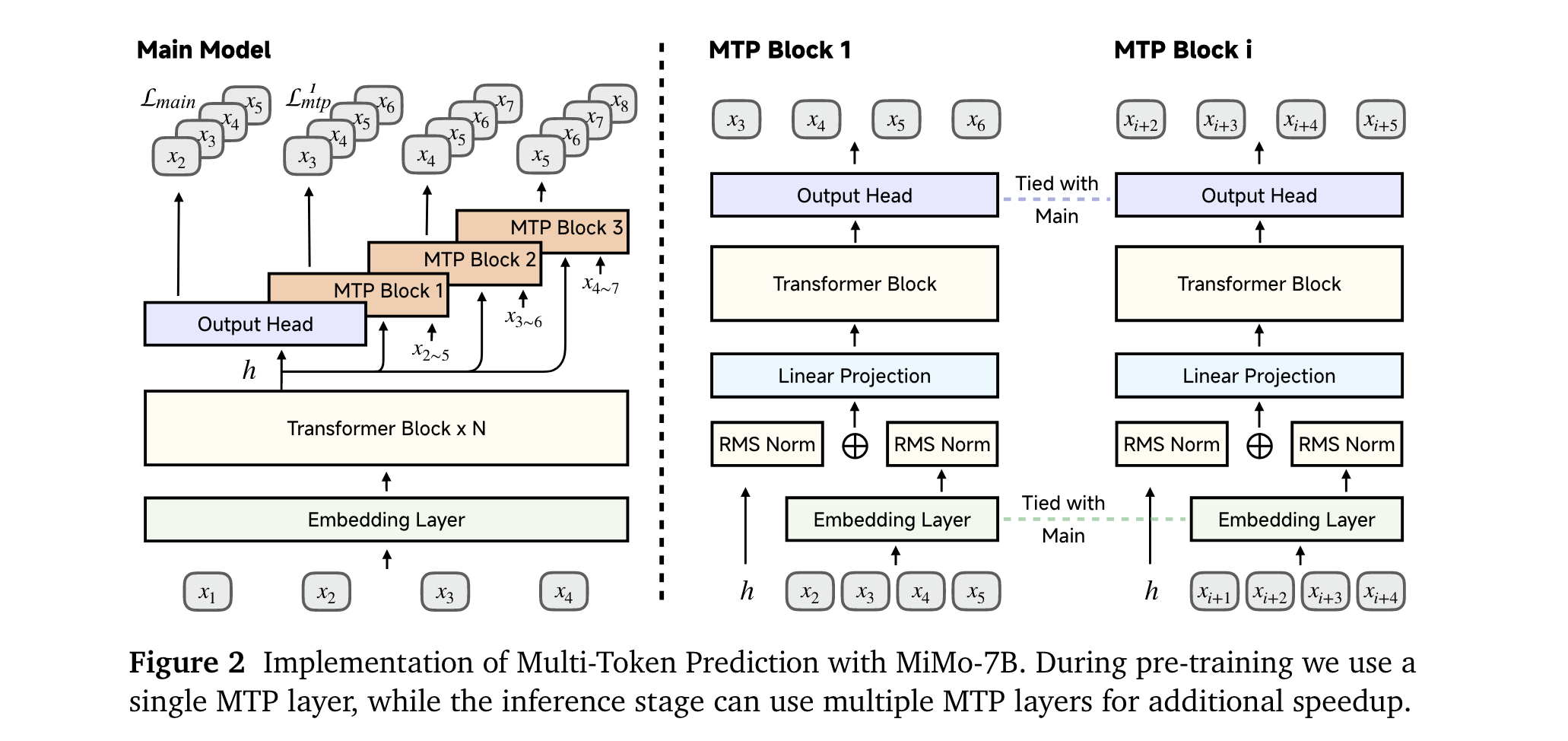
1. 核心算法/框架:模型采用通用的解码器仅Transformer架构,包含Grouped-Query Attention(GQA)、pre-RMSNorm、SwiGLU激活和Rotary Positional Embedding(RoPE)等组件,模型使用MTP(multi-token prediction)结构。后训练采用改进的Group Relative Policy Optimization(GRPO)算法。
2. 关键参数设计原理:预训练时,设置Transformer层数为36,隐藏层维度为4096等参数。使用AdamW优化器,设置不同阶段的学习率、批量大小等参数。后训练中,调整改进GRPO算法的超参数,如训练批量大小为512,演员小批量大小为32,学习率为1e-6等。
3. 创新性技术组合:预训练阶段,结合优化的文本提取工具、数据去重和过滤技术,以及多策略生成的合成推理数据。后训练中,将测试难度驱动的奖励机制与数据重采样策略相结合,同时优化强化学习基础设施,构建Seamless Rollout Engine加速强化学习效率。
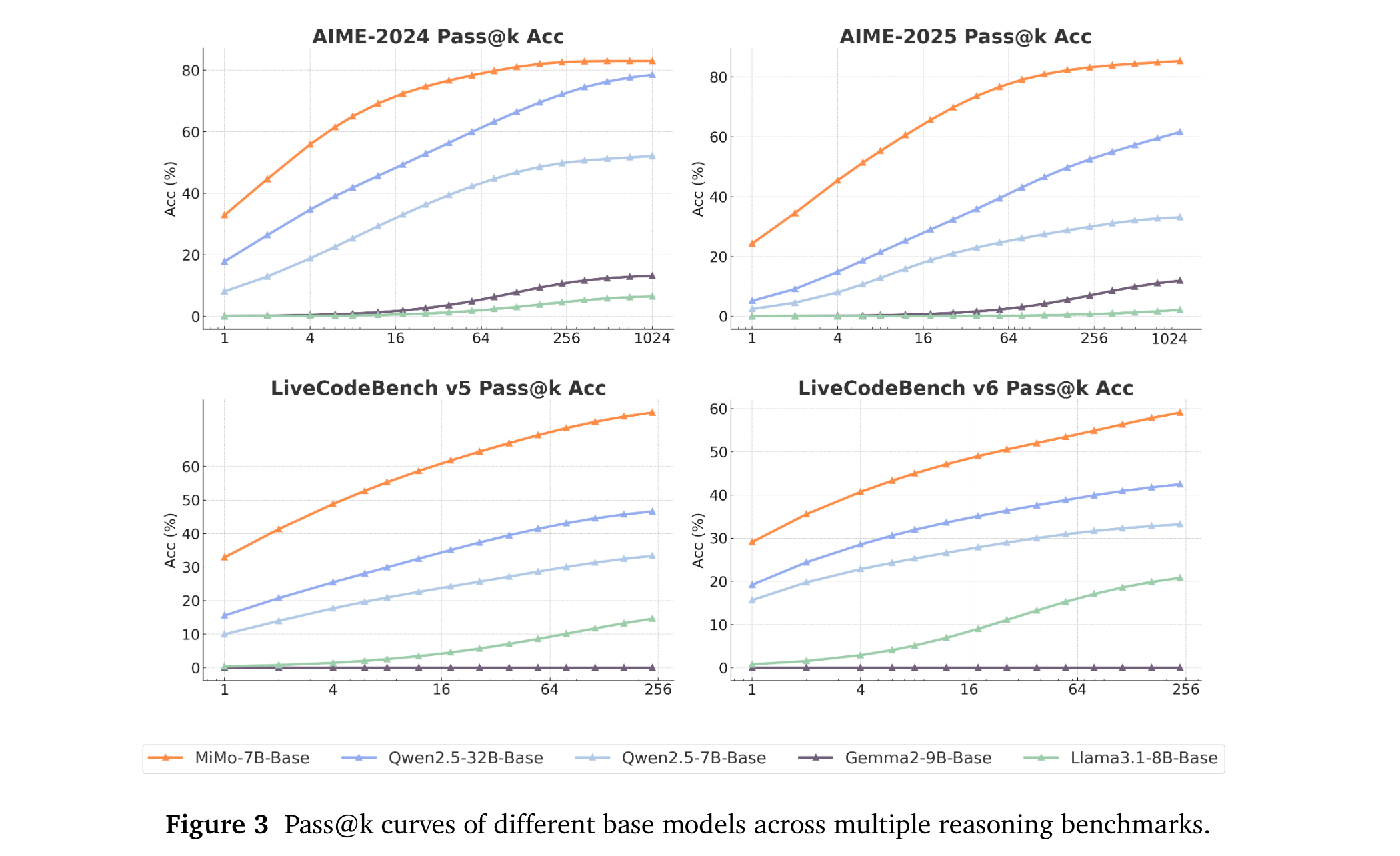
4. 实验验证方式:使用多种基准测试评估模型,包括自然语言理解、科学问答、阅读理解、数学推理、编码等任务的相关数据集。对比基线选择其他开源的同规模模型以及一些先进的推理模型,如Llama-3.1-8B、Gemini-2-9B、OpenAI o1-mini等,通过对比评估模型性能。
实验洞察
1. 性能优势:在数学推理任务中,MiMo-7B-RL在AIME 2024上得分68.2,AIME 2025上得分55.4,超越OpenAI o1-mini等模型。在代码推理任务中,LiveCodeBench v5上得分57.8,LiveCodeBench v6上得分49.3,大幅领先部分对比模型。在一般推理任务中,在多个基准测试中也展现出较强的性能。
2. 效率突破:Seamless Rollout Engine使训练速度提升2.29倍,验证速度提升1.96倍,有效减少GPU空闲时间,提高了训练和验证效率。通过优化vLLM推理引擎并支持MTP,提升了推理速度,如MTP层在AIME24基准测试中,第一层接受率约90%,第三层也保持在75%以上,加速了解码速度。
3. 消融研究:研究发现从MiMo-7B-Base直接进行强化学习(RL)训练,模型在早期主要学习适应答案提取格式。“轻量级”SFT帮助模型对齐答案格式的尝试效果不佳,MiMo-7B-RL-LiteSFT模型在推理潜力和最终性能上均落后。此外,在RL训练后期,平衡数学和代码任务的性能存在挑战,且语言混合问题难以通过简单的惩罚函数解决。