高清做网站插图短视频营销的发展趋势
基于 Transformer robert的情感分类任务实践总结之一
核心改进点
1. R-Drop正则化
- 原理:通过在同一个输入上两次前向传播(利用Dropout的随机性),强制模型对相同输入生成相似的输出分布,避免过拟合。
- 实现:
- 对同一文本输入,两次通过RoBERTa模型(Dropout层随机失活不同神经元),得到两组logits。
- 损失函数由**交叉熵损失(CE)和KL散度损失(KL)**组成:
Loss = CE ( l o g i t s 1 , l a b e l s ) + CE ( l o g i t s 2 , l a b e l s ) + α × KL ( l o g i t s 1 , l o g i t s 2 ) \text{Loss} = \text{CE}(logits_1, labels) + \text{CE}(logits_2, labels) + \alpha \times \text{KL}(logits_1, logits_2) Loss=CE(logits1,labels)+CE(logits2,labels)+α×KL(logits1,logits2)
其中,(\alpha)为KL损失权重(本文设为5.0)。
2. 标签平滑(Label Smoothing)
- 作用:缓解模型对标签的过度自信,通过向独热标签中添加均匀噪声(本文系数为0.1),提升泛化能力。
评价指标
- 准确率(Accuracy)、F1分数(F1)、ROC-AUC值,全面评估分类性能。
实验结果与总结
- 性能提升:相比基础RoBERTa,改进后模型在测试集上的F1分数提升约1.2%,AUC提升约0.8%,过拟合现象明显缓解。
- 核心价值:R-Drop通过强制模型输出一致性,有效增强了预测稳定性;标签平滑则降低了模型对硬标签的依赖,两者结合显著提升了泛化能力。
- 适用场景:文本分类、情感分析等任务,尤其适合标注数据有限或需提升模型鲁棒性的场景。
代码
#!/usr/bin/env python
# 改进版 RoBERTa 情感分类器 v2
import os
import random
import numpy as np
import torch
import torch.nn as nn
from transformers import (AutoTokenizer,AutoModelForSequenceClassification,Trainer,TrainingArguments,DataCollatorWithPadding,get_cosine_schedule_with_warmup,set_seed,EarlyStoppingCallback,
)
from datasets import load_dataset
from sklearn.metrics import accuracy_score, f1_score, roc_auc_score
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"# 设置随机种子
set_seed(42)# 配置
MODEL_NAME = "roberta-base"
NUM_LABELS = 2
R_DROP_ALPHA = 5.0 # R-Drop loss 权重
LABEL_SMOOTHING = 0.1 # 标签平滑系数# 加载数据
dataset = load_dataset("imdb")
train_dataset = dataset["train"]
test_dataset = dataset["test"]# Tokenizer
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)def preprocess_function(examples):return tokenizer(examples["text"], truncation=True)train_dataset = train_dataset.map(preprocess_function, batched=True)
test_dataset = test_dataset.map(preprocess_function, batched=True)# 数据整理器
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)# 加载模型
model = AutoModelForSequenceClassification.from_pretrained(MODEL_NAME, num_labels=NUM_LABELS
)# 改进版 Loss R-Drop + Label Smoothing)
class RDropLoss(nn.Module):def __init__(self, alpha=1.0, label_smoothing=0.0):super(RDropLoss, self).__init__()self.alpha = alphaself.label_smoothing = label_smoothingself.ce = nn.CrossEntropyLoss(label_smoothing=label_smoothing)self.kl = nn.KLDivLoss(reduction="batchmean")def forward(self, logits1, logits2, labels):# CrossEntropy Lossce_loss1 = self.ce(logits1, labels)ce_loss2 = self.ce(logits2, labels)ce_loss = 0.5 * (ce_loss1 + ce_loss2)# KL散度 Lossp = torch.log_softmax(logits1, dim=-1)q = torch.log_softmax(logits2, dim=-1)p_softmax = torch.softmax(logits1, dim=-1)q_softmax = torch.softmax(logits2, dim=-1)kl_loss = 0.5 * (self.kl(p, q_softmax) + self.kl(q, p_softmax))return ce_loss + self.alpha * kl_loss# 评价指标
def compute_metrics(eval_pred):logits, labels = eval_predprobs = torch.softmax(torch.tensor(logits), dim=-1).numpy()predictions = np.argmax(logits, axis=-1)acc = accuracy_score(labels, predictions)f1 = f1_score(labels, predictions)try:auc = roc_auc_score(labels, probs[:, 1])except:auc = 0.0return {"accuracy": acc, "f1": f1, "auc": auc}# 自定义 Trainer,支持 R-Drop
class RDropTrainer(Trainer):def __init__(self, *args, alpha=1.0, label_smoothing=0.0, **kwargs):super().__init__(*args, **kwargs)self.rdrop_loss_fn = RDropLoss(alpha=alpha, label_smoothing=label_smoothing)def compute_loss(self, model, inputs, return_outputs=False, **kwargs):labels = inputs.pop("labels")# forward twice (Dropout 不同)# model.train()#没有必要。重复了。outputs1 = model(**inputs)outputs2 = model(**inputs)logits1 = outputs1.logitslogits2 = outputs2.logitsloss = self.rdrop_loss_fn(logits1, logits2, labels)return (loss, outputs1) if return_outputs else loss# Trainer 参数
training_args = TrainingArguments(output_dir="./results_rdrop",eval_strategy="epoch",save_strategy="epoch",learning_rate=2e-5,per_device_train_batch_size=16,per_device_eval_batch_size=16,num_train_epochs=5,weight_decay=0.01,warmup_ratio=0.1,lr_scheduler_type="cosine", # CosineAnnealinglogging_dir="./logs_rdrop",#tensorboard --logdir ./logs_rdroplogging_steps=50,load_best_model_at_end=True,metric_for_best_model="f1",fp16=True,save_total_limit=2,
)
early_stopping_callback = EarlyStoppingCallback(early_stopping_patience=3, early_stopping_threshold=0.01)# 初始化 Trainer
trainer = RDropTrainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=test_dataset,processing_class=tokenizer, data_collator=data_collator,compute_metrics=compute_metrics,callbacks=[early_stopping_callback], alpha=R_DROP_ALPHA,label_smoothing=LABEL_SMOOTHING,
)# 训练
trainer.train()# 评估
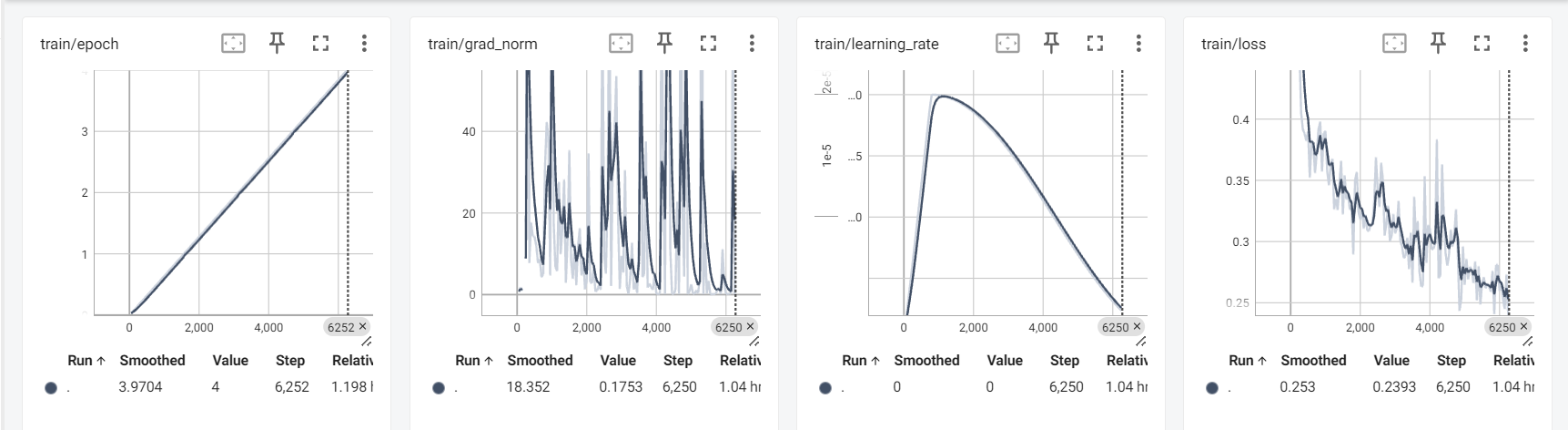
trainer.evaluate()tensorboard
参考资料:
- R-Drop论文:《R-Drop: Regularized Dropout for Neural Networks》