python策略网站怎么做电影宣传推广方案
目录
1.导包
2.torchvision数据处理的方法
3.下载加载手写数字的训练数据集
4.下载加载手写数字的测试数据集
5. 将训练数据与测试数据 转换成dataloader
6.转成迭代器取数据
7.创建模型
8. 把model拷到GPU上面去
9. 定义损失函数
10. 定义优化器
11. 定义训练过程
12.最终运行测试
1.导包
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plttorch.__version__'2.4.1+cu121'
# 检查GPU是否可用
torch.cuda.is_available()True
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')devicedevice(type='cuda', index=0)
# pytorch中使用GPU进行训练的主要流程注意点:
#1. 把模型转移到GPU上.
#2. 将每一批次的训练数据转移到GPU上.
# torchvision 内置了常用的数据集和常见的模型.
#使用pyTorch框架 整迁移学习时,可以从torchvision中加载出来
2.torchvision数据处理的方法
import torchvisionfrom torchvision import datasets, transforms# transforms.ToTensor 的作用如下:
# 1. 把数据转化为tensor
# 2. 数据的值转化为0到1之间.
# 3. 会把channel放到第一个维度上.
# transforms用来做数据增强, 数据预处理等功能的.
#Compose()可以将很多数据处理的方法组合起来, 用列表来组合
transformation = transforms.Compose([transforms.ToTensor(),])3.下载加载手写数字的训练数据集
#下载获取手写数字数据集MNIST ,获取其中的训练数据集
#train=True表示获取训练数据集
train_ds = datasets.MNIST('./', train=True, transform=transformation, download=True)
datasets<module 'torchvision.datasets' from 'D:\\anaconda3\\lib\\site-packages\\torchvision\\datasets\\__init__.py'>
4.下载加载手写数字的测试数据集
# 下载获取 手写数字的 测试数据集
#train=False表示获取测试数据集
test_ds = datasets.MNIST('./', train=False, transform=transformation, download=True)5. 将训练数据与测试数据 转换成dataloader
# 将训练数据与测试数据 转换成dataloader
train_dl = torch.utils.data.DataLoader(train_ds, batch_size=64, shuffle=True) #shuffle=True表示打乱数据
test_dl = torch.utils.data.DataLoader(test_ds, batch_size=256) #测试数据时,不需要进行反向传播,可以将batch_size的值给大一些6.转成迭代器取数据
#可迭代对象 与 迭代器 不同
#train_dl是可迭代对象
#iter()将train_dl可迭代对象的数据 变成 迭代器
#next()从迭代器中取出一批数据
images, labels = next(iter(train_dl))#tensorflow中图片的表现形式[batch, hight, width, channel]
# pytorch中图片的表现形式[batch, channel, hight, width]
images.shapetorch.Size([64, 1, 28, 28])
labels #还没有one_hot编码的tensor([1, 1, 2, 3, 2, 1, 8, 4, 5, 8, 4, 3, 0, 0, 4, 8, 2, 3, 3, 7, 3, 0, 5, 5,5, 6, 7, 2, 9, 4, 7, 9, 6, 7, 1, 4, 3, 9, 2, 4, 6, 4, 1, 1, 9, 2, 4, 7,7, 6, 2, 6, 8, 1, 3, 5, 4, 7, 5, 0, 6, 0, 9, 1])
img = images[0] #取一张图的数据img.shape #一张图数据的形状 #三维数据 不方便可视化img = img.numpy() #可以先将数据转成numpy数据类型, 再进行数据降维, 再进行可视化img = np.squeeze(img) #数据降维,降一个维度,把只有1的维度降掉, 将形状变成(28, 28)img.shape(28, 28)
plt.imshow(img, cmap='gray') #图片数据可视化 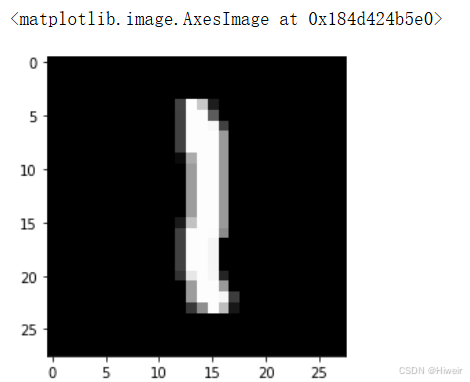
7.创建模型
class Model(nn.Module): #继承nn.Moduledef __init__(self): #重写方法super().__init__() #继承父类的方法#无论经过什么层,batch_size一直保持不变(第一个数)#第一层卷积层#nn.Conv2d(输入的通道数, 自定义输出的通道数=这一层使用的卷积核的个数, 卷积核的大小)#输出的通道数=卷积核的个数(神经元个数)#nn.Conv2d()参数dilation=1(默认值),表示 不膨胀卷积#padding 默认为0#卷积核的大小为奇数时,padding=valid, 图片大小= ((原图片大小w - 卷积核的大小F)+ 1) / 步长s (此时步长默认steps = 1)self.conv1 = nn.Conv2d(1, 32, 3)# in: 64, 1, 28 , 28 -> out: 64, 32, 26, 26#池化层nn.MaxPool2d((卷积核的大小)) ,卷积核的大小可以用元组(2,2)表示,或者直接用一个数2表示 #strip步长默认为2#池化层的数值设置一般都一样,可重复使用,创建一次就行#卷积核的大小为偶数时,padding=same, 图片大小= 原图片大小w / 步长s(此时的步长steps默认为2)#上一句化 等同于 经过一次池化层,原图片大小减半#经过池化层,输入通道数=上一层的输出通道数=上一层使用的卷积核个数self.pool = nn.MaxPool2d((2, 2)) # out: 64, 32, 13, 13
# self.pool = nn.MaxPool2d(2) #等同于上一行代码#第二层卷积核nn.Conv2d(上一层卷积的输出通道数, 自定义在这一层使用的卷积核的个数, 3)self.conv2 = nn.Conv2d(32, 64, 3)# in: 64, 32, 13, 13 -> out: 64, 64, 11, 11# 再加一层池化操作, in: 64, 64, 11, 11 --> out: 64, 64, 5, 5#第一层全连接层(输入通道数=上一层维度形状相乘,自定义输出通道数量=这一层使用的神经元数量)self.linear_1 = nn.Linear(64 * 5 * 5, 256)#第二层全连接层(输入通道数=上一层输出通道数,自定义输出通道数=问题分类数量(数字识别0~9,共10个数字))self.linear_2 = nn.Linear(256, 10)#定义前向传播def forward(self, input):#链式调用 #relu激活函数(第一层卷积层) #调用自定义方法,需要加上self.x = F.relu(self.conv1(input))x = self.pool(x) #第二层:池化层x = F.relu(self.conv2(x)) #第三层:卷积层,然后+ relu激活函数x = self.pool(x) #第四层:池化层# flatten 展平, 进行维度变形x = x.view(-1, 64 * 5 * 5) # (每批次具有64个样本, 特征数量)x = F.relu(self.linear_1(x)) #第五层:全连接层+激活函数relux = self.linear_2(x) #第六层:输出层 #一般会在这一层之后添加一个sigmoid函数,这里没有加,后面需要处理一下return x8. 把model拷到GPU上面去
model = Model()# 把model拷到GPU上面去
model.to(device)Model((conv1): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1))(pool): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)(conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1))(linear_1): Linear(in_features=1600, out_features=256, bias=True)(linear_2): Linear(in_features=256, out_features=10, bias=True) )
9. 定义损失函数
#定义损失函数
loss_fn = torch.nn.CrossEntropyLoss()10. 定义优化器
#定义优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)11. 定义训练过程
#定义训练过程
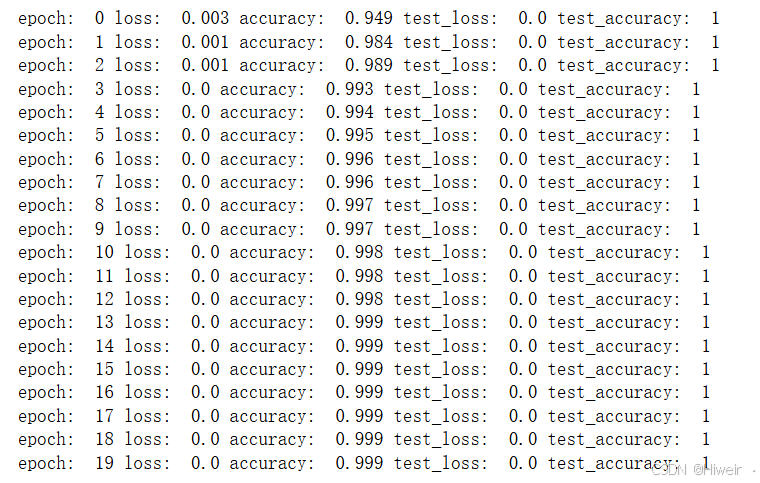
def fit(epoch, model, train_loader, test_loader):#声明变量correct = 0 #预测准确的数量total = 0 #总共的样本数量running_loss = 0 #每运行一次的累计损失for x, y in train_loader:# 把CPU上的数据放到GPU上去. x, y = x.to(device), y.to(device)y_pred = model(x)loss = loss_fn(y_pred, y)optimizer.zero_grad()loss.backward()optimizer.step()with torch.no_grad(): #不计算梯度求导时#计算预测值 #argmax()是取最大值的索引, y_pred是10个预测数字的概率(包含10个概率数值),是二维数据类型 # dim=1表示取第二个维度上的索引:列上y_pred = torch.argmax(y_pred, dim=1)#计算预测准确的数量, #.item()表示把sum()求和的聚合运算(bool值会直接用1或0表示)之后的 标量(一个具体的数)取出来correct += (y_pred == y).sum().item()total += y.size(0) #总共样本数量running_loss += loss.item() #每运行一次的累计损失epoch_loss = running_loss / len(train_loader.dataset) #计算平均损失epoch_acc = correct / total #计算准确率# 测试过程,不需要计算梯度求导test_correct = 0test_total = 0test_running_loss = 0with torch.no_grad():for x, y in test_loader:x, y = x.to(device), y.to(device)y_pred = model(x)loss = loss_fn(y_pred, y)y_pred = torch.argmax(y_pred, dim=1)test_correct += (y_pred == y).sum().item()test_total += y.size(0)test_running_loss += loss.item()test_epoch_loss = test_running_loss / len(test_loader.dataset)test_epoch_acc = test_correct / test_totalprint('epoch: ', epoch,'loss: ', round(epoch_loss, 3), #3表示三位小数'accuracy: ', round(epoch_acc, 3),'test_loss: ', round(test_epoch_loss, 3),'test_accuracy: ', round(test_epoch_acc))return epoch_loss, epoch_acc, test_epoch_loss, test_epoch_acc12.最终运行测试
epochs = 20 #指定运行的次数
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):epoch_loss, epoch_acc, test_epoch_loss, test_epoch_acc = fit(epoch, model, train_dl, test_dl)train_loss.append(epoch_loss)train_acc.append(epoch_acc)test_loss.append(epoch_loss)test_acc.append(epoch_acc)