自己做的电影网站打开很慢哈尔滨市建设工程交易
目录
摘要
14 梯度提升决策树
14.1 本章工作任务
14.2 本章技能目标
14.3 本章简介
14.4 编程实战
14.5 本章总结
14.6 本章作业
本章已完结!
摘要
本章实现的工作是:首先采用Python语言读取含有英语成绩、数学成绩以及学生所属类型的样本数据。然后将样本数据划分为训练集和测试集,接着采用GBDT算法,对训练集数据进行拟合,最后在输入更多学生的数学成绩和英语成绩后,使用已求解的最优模型去预测其分类结果。
本章掌握的技能是:1、使用NumPy包读取连续的样本数据。2、使用sklearn库model_selection模块中的model_selection函数实现训练集和测试集的划分。3、使用Matplotlib实现数据的可视化,绘制树状图。
14 梯度提升决策树
14.1 本章工作任务
采用梯度提升决策树(GBDT)算法编写程序,根据700名学生的数学成绩和英语成绩对其进行分类,将其划分为文科生、理科生和综合生。1、算法的输入是:700名学生的数学和英语成绩以及相应的的学生类型。2、算法模型需要求解的是:N颗残差树(每颗残差树需要求解所有分支,每个分支节点需要求解该分支的属性及分支的阈值)。3、算法的结果是:待测样本中学生的分类。
14.2 本章技能目标
掌握GBDT原理。
使用Python读取样本数据,并划分为训练集和测试集。
使用Python实现GBDT的建模与求解。
掌握GBDT模型实现预测。
使用Python实现GBDT分类结果进行可视化展示。
14.3 本章简介
梯度提升决策树(GBDT)是指:一种集成算法,由多个子分类器(弱分类器)的分类结果进行累加,从而得到总分类器(强分类器)的分类结果。GBDT子分类器的特点是后一个子分类器是对前一个子分类器得到的分类结果与目标值之间的差值进行的拟合,即后一个子分类器是对前一个子分类器得到的残差值的矫正。
梯度提升决策树(GBDT)算法可以解决的实际应用问题是:已知N个样本数据,样本特征是学生的数学成绩和英语成绩,样本标签是学生的类型。通过建立GBDT模型对样本数据进行训练,找到样本特征和样本标签之间的关系,从而预测出T个新的样本(学生)的类型。
本章的重点是:梯度提升决策树方法的理解和使用。
14.4 编程实战
步骤1 引入NumPy库,命名为np;引入pandas库,命名为pd;引入os.path.abspath()模块,命名为plt,用于绘制图像;引入os模块,用于处理文件和目录。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os步骤2 将当前文件所在目录的路径设置为Python的当前工作目录。os.path.abspath()用于将相对路径转化为绝对路径;os.chdir()用于改变当前工作目录;os.getcwd()用于获取当前工作目录(不同设备的绝对路径不同)。
thisFilePath = os.path.abspath('.') # 获取当前文件的绝对路径
os.chdir(thisFilePath) # 改变当前工作目录
os.getcwd() # 获取当前工作目录输出结果:
'D:\\MyPythonFiles'步骤3 导入并读取数据。pd.read_csv()函数用于读取数据,usecols参数用于读取文件中指定的数据列。type()函数用于返回对象的类型。head()函数用于查看前几行数据,tail()函数用于查看后几行数据。
myData = pd.read_csv('DataForClassify(1).csv', usecols=['YingYu', 'ShuXue', 'Label'])
type(myData)
myData.head()输出结果:
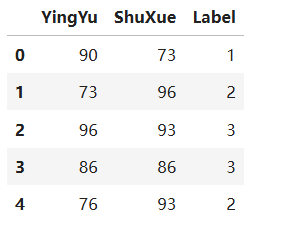
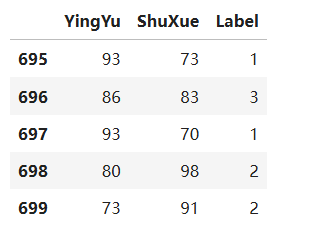
myData.tail()输出结果:
步骤4 划分训练集和测试集。从sklearn包的model_selection模块中引入train_test_split函数,函数中的第一个参数表示所要划分的样本特征集;第二个参数表示所要划分的样本标签;第三个参数表示测试集占样本数据的比例,若为整数,则表示绝对数量;第四个参数表示随机数种子。
from sklearn.model_selection import train_test_split
trainSet_x, testSet_x, trainSet_y, testSet_y = train_test_split(myData.iloc[:, 0:2],myData.iloc[:, 2],test_size = 0.2,random_state=220
)
trainSet_x.shape输出结果:
(560,2)步骤5 拟合并验证梯度提升决策树(GBDT)模型。从sklearn包中引入ensemble,并构建模型。
从sklearn包的model_selection模块中引入cross_val_score函数,运用 K 折交叉验证对模型的稳定性进行验证。其中,第一个参数表示模型的名称,第二个参数表示样本特征集,第三个参数表示样本标签,第四个参数表示进行几个交叉验证。K 折交叉验证指把初始训练样本分成 K份,其中 K-1份被用作训练集,剩下一份被用作评估集,进行K次训练后得到K个训练结果,通过结果对比来验证模型的稳定性。
from sklearn import ensemble
import datetime
start_time = datetime.datetime.now() # 获取函数的开始时间
GBDT_model = ensemble.GradientBoostingClassifier(n_estimators=10, min_samples_split=50)
GBDT_model = GBDT_model.fit(trainSet_x, trainSet_y) # 导入训练集的数据进行模型拟合from sklearn.model_selection import cross_val_score
print("%s Score: %0.2f" % ("GBDT", GBDT_model.score(testSet_x, testSet_y)))
scores = cross_val_score(GBDT_model, testSet_x, testSet_y, cv=5)
print("%s Cross Avg. Score: %0.2f(+/-%0.2f)" % ("GBDT", scores.mean(), scores.std()*2))
end_time = datetime.datetime.now() # 求得函数结束的时间
time_spend = end_time - start_time # 求得函数运行的时间
print("%s Time:%0.2f" % ("GBDT", time_spend.total_seconds())) # 输出模型的训练时间输出结果:GBDT Score: 1.00
GBDT Cross Avg. Score: 1.00(+/-0.00)
GBDT Time:333.33步骤6 对模型的输出结果进行可视化。
from sklearn import treeestimator = GBDT_model.estimators_[0,1]dot_data = tree.export_graphviz(estimator,out_file = None,feature_names = trainSet_x.columns.values,filled = True,impurity = False,rounded = True
)
import pydotplus
graph = pydotplus.graph_from_dot_data(dot_data)
graph.get_nodes()[1].set_fillcolor("#FFF2DD")
from IPython.display import Image
Image(graph.create_png())输出结果:

步骤7 对样本数据的分类结果进行可视化。
import matplotlib as mpldef plot(train_x, train_y, test_x, test_y, model):x1_min, x1_max = train_x.iloc[:, 0].min(), train_x.iloc[:, 0].max() # YingYu的最低分和最高分x2_min, x2_max = train_x.iloc[:, 1].min(), train_x.iloc[:, 1].max() # ShuXue的最低分和最高分x1, x2 = np.mgrid[x1_min:x1_max:80j, x2_min:x2_max:80j] # 生成网格采样点grid_test = np.stack((x1.flat, x2.flat), axis = 1)grid_test_df = pd.DataFrame(grid_test, columns=train_x.columns)grid_hat = model.predict(grid_test_df)grid_hat = grid_hat.reshape(x1.shape)color = ['g', 'r', 'b']color_dark = ['darkgreen', 'darkred', 'darkblue']markers = ["o", "D", "^"]plt.pcolormesh(x1, x2, grid_hat)train_x_arr = np.array(train_x)test_x_arr = np.array(test_x)for i, marker in enumerate(markers):plt.scatter(train_x_arr[train_y==i+1][:,0],train_x_arr[train_y==i+1][:,1],c=color[i],edgecolors='black',s=20,marker=marker)plt.scatter(test_x_arr[test_y==i+1][:,0],test_x_arr[test_y==i+1][:,1],c=color_dark[i],edgecolors='black',s=40,marker=marker)plt.xlabel('English', fontsize=13)plt.ylabel('Math', fontsize=13)plt.xlim(x1_min, x1_max)plt.ylim(x2_min, x2_max)plt.title('Students Grade', fontsize=15)plt.show()
plot(trainSet_x, trainSet_y, testSet_x, testSet_y, GBDT_model)输出结果:
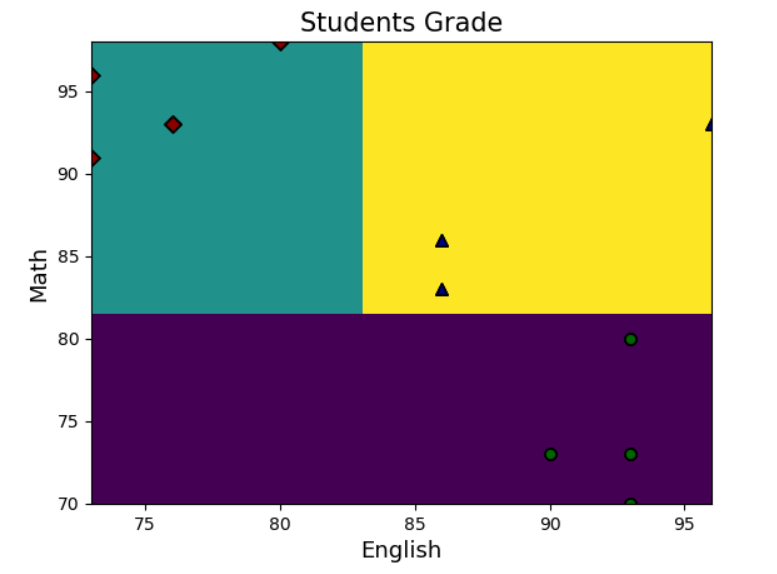
14.5 本章总结
本章实现的工作是:首先采用Python语言读取含有英语成绩、数学成绩以及学生所属类型的样本数据。然后将样本数据划分为训练集和测试集,接着采用GBDT算法,对训练集数据进行拟合,最后在输入更多学生的数学成绩和英语成绩后,使用已求解的最优模型去预测其分类结果。
本章掌握的技能是:1、使用NumPy包读取连续的样本数据。2、使用sklearn库model_selection模块中的model_selection函数实现训练集和测试集的划分。3、使用Matplotlib实现数据的可视化,绘制树状图。
14.6 本章作业
1、实现本章的案例,即生成样本数据,实现梯度提升决策树模型的建模、参数调整、预测和数据可视化。
2、利用 Iris(鸢尾花)原始数据集,运用GBDT算法,实现根据鸢尾花的任意两个特征对其进行分类。