wordpress搭建子網站扶余手机网站开发
目录
- 代码
- 代码解释
- 导入模块
- 常量定义
- MCP服务器初始化
- 工具函数定义
- 1. search_papers 函数
- 2. extract_info 函数
- 主程序
- 总结
- 运行示例
代码
import arxiv
import json
import os
from typing import List
from mcp.server.fastmcp import FastMCPPAPER_DIR = "papers"mcp = FastMCP("research")@mcp.tool()
def search_papers(topic: str, max_results: int = 5) -> List[str]:"""Search for papers on arXiv based on a topic and store their information.Args:topic: The topic to search formax_results: Maximum number of results to retrieve (default: 5)Returns:List of paper IDs found in the search"""# Use arxiv to find the papersclient = arxiv.Client()# Search for the most relevant articles matching the queried topicsearch = arxiv.Search(query = topic,max_results = max_results,sort_by = arxiv.SortCriterion.Relevance)papers = client.results(search)# Create directory for this topicpath = os.path.join(PAPER_DIR, topic.lower().replace(" ", "_"))os.makedirs(path, exist_ok=True)file_path = os.path.join(path, "papers_info.json")# Try to load existing papers infotry:with open(file_path, "r") as json_file:papers_info = json.load(json_file)except (FileNotFoundError, json.JSONDecodeError):papers_info = {}# Process each paper and add to papers_infopaper_ids = []for paper in papers:paper_ids.append(paper.get_short_id())paper_info = {'title': paper.title,'authors': [author.name for author in paper.authors],'summary': paper.summary,'pdf_url': paper.pdf_url,'published': str(paper.published.date())}papers_info[paper.get_short_id()] = paper_info# Save updated papers_info to json filewith open(file_path, "w") as json_file:json.dump(papers_info, json_file, indent=2)print(f"Results are saved in: {file_path}")return paper_ids@mcp.tool()
def extract_info(paper_id: str) -> str:"""Search for information about a specific paper across all topic directories.Args:paper_id: The ID of the paper to look forReturns:JSON string with paper information if found, error message if not found"""for item in os.listdir(PAPER_DIR):item_path = os.path.join(PAPER_DIR, item)if os.path.isdir(item_path):file_path = os.path.join(item_path, "papers_info.json")if os.path.isfile(file_path):try:with open(file_path, "r") as json_file:papers_info = json.load(json_file)if paper_id in papers_info:return json.dumps(papers_info[paper_id], indent=2)except (FileNotFoundError, json.JSONDecodeError) as e:print(f"Error reading {file_path}: {str(e)}")continuereturn f"There's no saved information related to paper {paper_id}."if __name__ == "__main__":mcp.run(transport="stdio")代码解释
导入模块
import arxiv # 用于访问arXiv API搜索论文
import json # 处理JSON数据
import os # 操作系统功能,如文件路径处理
from typing import List # 类型提示
from mcp.server.fastmcp import FastMCP # 导入MCP框架
常量定义
PAPER_DIR = "papers" # 定义存储论文信息的目录
MCP服务器初始化
mcp = FastMCP("research") # 创建一个名为"research"的MCP服务器实例
工具函数定义
1. search_papers 函数
@mcp.tool()
def search_papers(topic: str, max_results: int = 5) -> List[str]:
这个函数被注册为MCP工具,用于在arXiv上搜索特定主题的论文并保存信息:
- 装饰器:
@mcp.tool()将此函数注册为MCP服务的工具 - 参数:
topic: 要搜索的主题max_results: 最大结果数量(默认5个)
- 返回值:找到的论文ID列表
功能流程:
- 创建arXiv客户端
- 按相关性搜索主题相关论文
- 为该主题创建目录(如
papers/machine_learning) - 尝试加载已有的论文信息(如果存在)
- 处理每篇论文,提取标题、作者、摘要等信息
- 将论文信息保存到JSON文件中
- 返回论文ID列表
2. extract_info 函数
@mcp.tool()
def extract_info(paper_id: str) -> str:
这个函数也被注册为MCP工具,用于在所有主题目录中搜索特定论文的信息:
- 装饰器:
@mcp.tool()将此函数注册为MCP服务的工具 - 参数:
paper_id- 要查找的论文ID - 返回值:包含论文信息的JSON字符串(如果找到),否则返回错误信息
功能流程:
- 遍历
papers目录下的所有子目录 - 在每个子目录中查找
papers_info.json文件 - 如果找到文件,检查是否包含指定的论文ID
- 如果找到论文信息,返回格式化的JSON字符串
- 如果未找到,返回未找到的提示信息
主程序
if __name__ == "__main__":mcp.run(transport="stdio")
总结
research_server.py是一个基于MCP框架的研究服务器,提供了两个主要工具:
- 搜索arXiv上的论文并保存信息
- 提取已保存的论文信息
这个服务器可以作为AI助手的后端,通过MCP协议与前端交互,提供论文研究相关的功能。
运行示例
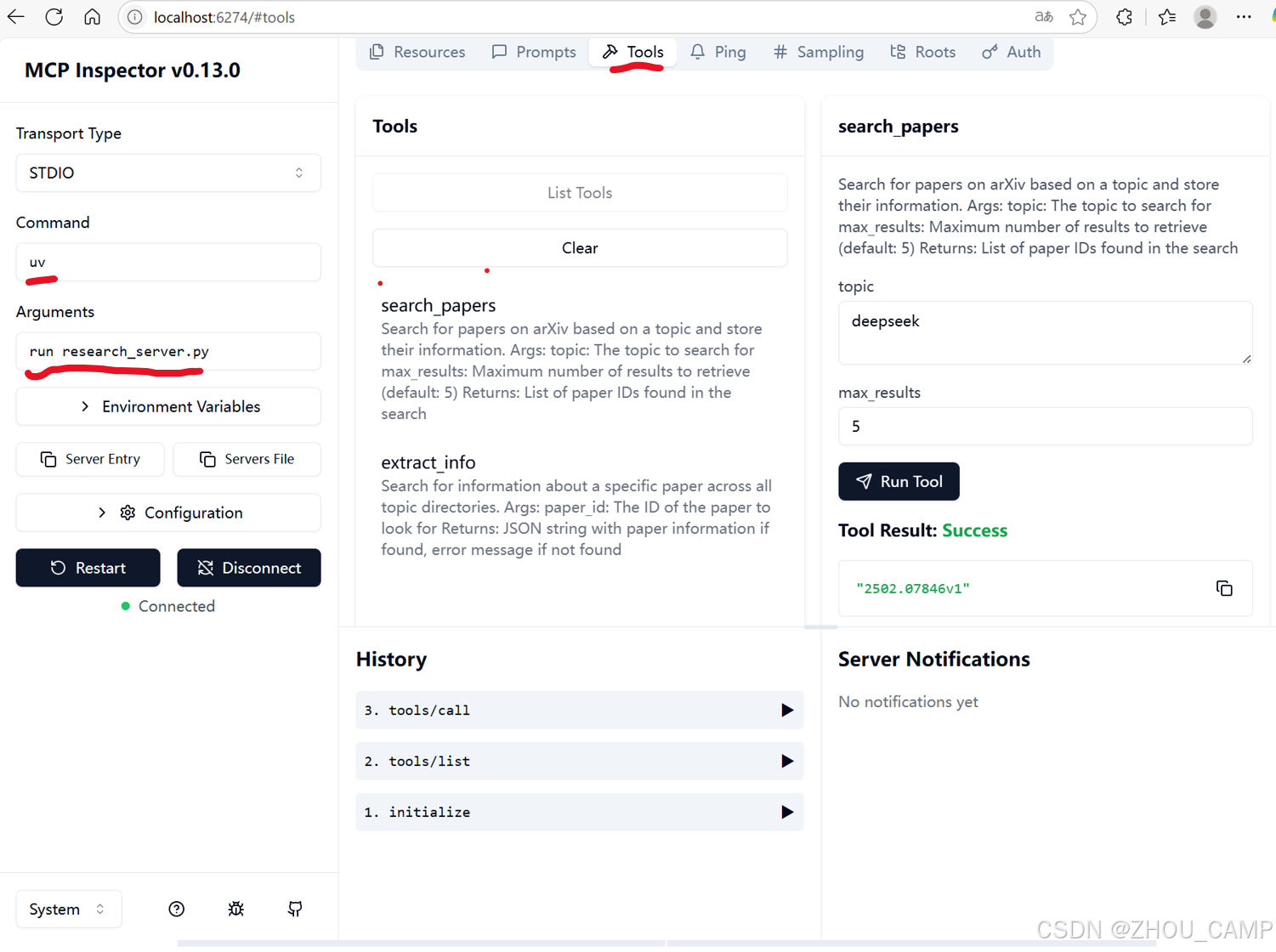
可用inspector工具查看,可以参照这个例子MarkItDown-MCP 测试与debug
前一节链接:
吴恩达MCP课程(1):chat_bot