建设网站需要了解些什么问题百度权重从1提升到2的办法
近日,Qwen 3系列大模型正式发布,涵盖从0.6B到235B参数的多个规模版本,包括6个Dense模型和2个混合专家(MoE)模型。本文将从模型架构、预训练策略、后训练优化等方面进行全面解读,帮助读者深入理解Qwen 3的技术细节与创新之处。
1 模型架构
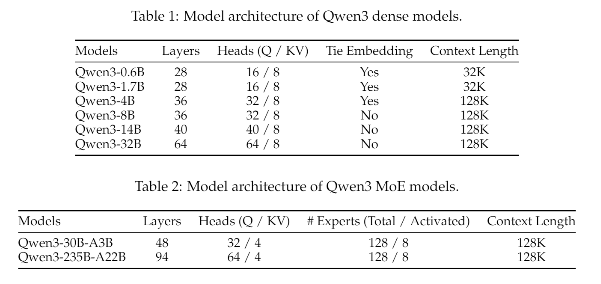
1.1 基础架构
Qwen 3延续了Qwen 2.5的核心技术,包括:
-
GQA(Grouped Query Attention) :平衡计算效率和建模能力
-
SwiGLU激活函数:提升非线性表达能力
-
RoPE(Rotary Position Embedding) :增强位置编码效果
1.2 关键改进
相比Qwen 2.5,Qwen 3在注意力机制和MoE架构上进行了优化:
-
QK-Norm取代QKV-bias
-
Qwen 2.5采用QKV-bias来稳定训练,但可能引入偏差
-
Qwen 3改用QK-Norm(Query-Key Normalization),通过归一化提升注意力计算的稳定性
-
实验表明,该方法能有效缓解传统注意力机制的不稳定性问题
-
-
MoE架构优化
-
去除共享专家:Qwen 2.5-MoE包含部分共享专家,而Qwen 3-MoE完全采用独立专家
-
引入Global-Batch Load Balancing Loss
-
-
MoE模型中,不同专家的计算负载可能不均衡
-
该损失函数确保专家间的计算量合理分配,提高训练效率和任务均衡性
1.3 模型规模覆盖
Qwen 3系列包含多种参数规模的模型(0.6B、1.7B、4B、14B、72B、235B及MoE版本),尤其注重小模型的优化(如0.6B、1.7B),以适配边缘设备和移动端应用场景。
2 预训练
2.1 数据规模与多样性
-
总数据量达36T tokens(是Qwen 2.5的两倍)
-
支持119种语言和方言(覆盖范围扩大至Qwen 2.5的三倍)
2.2 三阶段训练策略
阶段详解
-
S1阶段:语言与常识奠基
-
使用大规模通用语料训练基础语言能力
-
采用4k上下文窗口,确保高效训练
-
-
S2阶段:推理能力专项提升
-
引入高质量数学、代码、逻辑推理数据
-
通过课程学习(Curriculum Learning)逐步增加难度
-
-
S3阶段:长上下文扩展
-
扩展序列长度至32k,适应文档理解、长对话等任务
-
采用动态NTK(Neural Tangent Kernel)方法缓解长序列训练的稳定性问题
-
2.3 基座模型性能
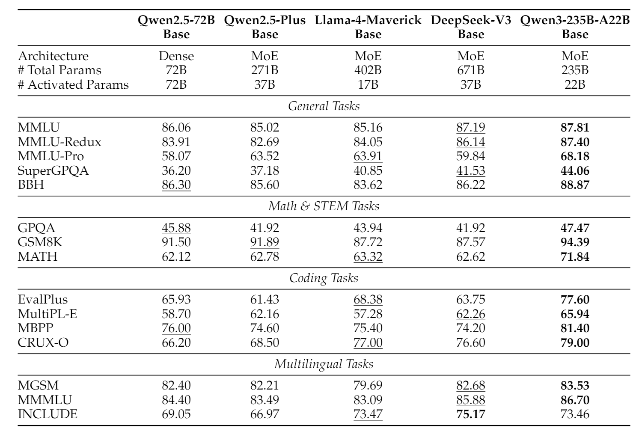
基座模型主实验
旗舰模型235B-A22B在大部分数据集上均为SOTA。其他小模型的结果详见下图。
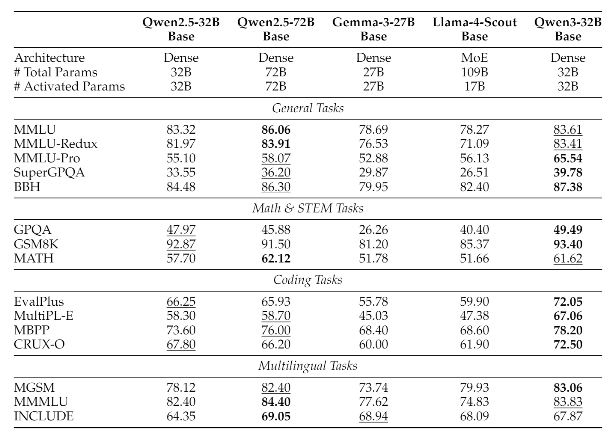
小基座模型实验结果
3 后训练
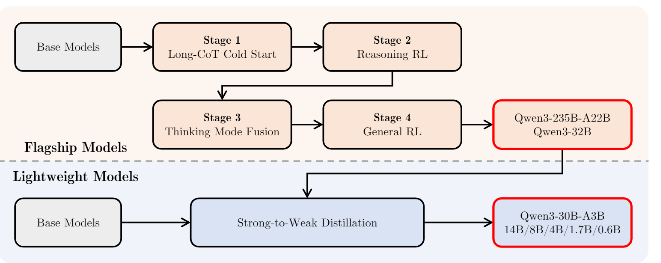
Qwen 3 后训练流程图
Qwen3的后训练流程涵盖四个阶段,旨在使模型能够在不同模式下执行任务,并在不同任务中表现出色。小模型的性能主要通过蒸馏大模型来提升。
Stage1: Long-CoT冷启动
该阶段构建了一个综合数据集,覆盖数学、编程、逻辑推理及通用STEM问题,每个问题都配有经过验证的参考答案或基于代码的测试用例。
数据构建包括query filtering和response filtering两个阶段。
对于query的过滤,使用 Qwen2.5-72B-Instruct 来识别并剔除那些难以验证的问题,包括:
-
含多个子问题的问题
-
要求生成通用文本的问题
-
那些 Qwen2.5-72B-Instruct 能不依赖 CoT 推理就直接答对的问题。这是想确保仅保留需要深度推理的问题。
此外,还用 Qwen2.5-72B-Instruct 给每个问题标注了所属领域,以保证领域覆盖的广度和平衡性。
对于response的过滤,使用QwQ-32B为每个问题生成 N 个候选response。对于 QwQ-32B 一直无法正确回答的题目,则进行人工标注。
对于通过 Pass@N 的问题,还需进一步筛选,剔除以下类型的response:
-
最终答案错误
-
存在大量重复内容
-
明显是在猜测,没有充分推理过程
-
推理过程与结论不一致
-
存在不恰当的语言混杂或风格突变
-
与评测集样本过于相似
经过严格筛选后,将选出的部分用于模型冷启动sft。这一阶段的目标是灌输基本推理模式,而非追求高性能。所以要尽量保留模型的潜力,便于在之后的强化学习阶段(RL) 进一步提升。为此,建议尽量减少训练样本量和训练步骤,以避免过早收敛。
Stage2: Reasoning RL
该阶段通过强化学习进一步提升模型的推理能力,使用了3,995个query-verifier pairs进行训练。
这些pairs的筛选必须满足以下四个标准:
-
没有用于冷启动阶段
-
适合冷启动后的模型学习:必须是冷启动模型可以理解并且能有效学习的,确保在推理能力上逐步进阶
-
尽可能具有挑战性:能够推动模型的推理能力不断提升,不仅仅是简单任务的重复训练
-
涵盖广泛的子领域:确保模型的全面性
训练技巧上采用了Large Batch Size和High Number of Rollouts per Query,Batch Size调大很好理解,High Number of Rollouts per Query指的一个query会被模型反复推理多次。算法用的GRPO,Qwen3-235B-A22B 模型在 170 个step后,AIME’24 分数从 70.1 提升至 85.1。
Stage3: Thinking Mode Fusion
该阶段的核心目的是将Think模式和No Think模式进行融合,使用户可以通过\think或者\no_think来控制模型是否进入思考模式。
SFT数据构建
SFT使用融合了“think”和“no_think”的数据。其中,think数据 query 来自 Stage 1 的任务,然后用 Stage 2 得到的模型进行拒绝采样生成response;“no_think”数据则覆盖代码、数学、多语言、指令跟随、创意写作、问答、角色扮演等更广泛的任务。为了提升模型对低资源语言的能力,特别提高了翻译任务的比例。
Chat模版设计
用户输入中可通过 /think 或 /no_think 指定模式;默认情况下模型为思维模式。非思维模式下,response中仍保留空的think块() ,以确保格式一致性。多轮对话中,系统会随机插入多个 /think 和 /no_think,让模型学习根据最近一个标签的模式进行回复。

Thinking Budget(思考预算)
无需训练,可以让用户指定思考输出的token长度,当思考token数达到用户指定长度后,直接加上“Considering the limited time by the user, I have to give the solution based on the thinking directly now.\n.\n\n”,强制模型结束思考给出结果。
Stage4: General RL
该阶段旨在全面提升模型在不同任务场景下的能力和稳定性,构建了一个涵盖20多个任务的大规模奖励体系。
每个任务都有定制的评分标准,重点强化以下几个核心能力:
-
指令遵循:确保模型能准确理解并执行用户的要求,包括内容、格式、长度、结构等各类指令。
-
格式遵循:不仅要理解用户显式的指令,还需遵循隐式格式规则,例如正确响应 /think 与 /no think 标记,规范使用和分隔思维内容与最终回答。
-
偏好对齐:对于开放性问题,提升模型的有用性、互动性和表达风格,使回答更符合人类偏好。
-
Agent 能力:训练模型正确调用工具接口,提升作为智能体的执行能力。
-
特殊任务:例如在 RAG(检索增强生成)任务中,引导模型生成更准确且具上下文契合度的回答,降低幻觉风险。
奖励类型包括三类:
-
规则型奖励(Rule-based):适用于推理与格式类任务,通过明确的规则精准判断模型输出是否正确。
-
带参考答案的模型奖励:提供参考答案,用 Qwen2.5-72B-Instruct 来对模型输出进行评分。
-
无参考答案的模型奖励:基于人类偏好数据训练的奖励模型,对模型输出打分。
蒸馏
用于5个dense模型和一个MoE模型。主要是两个阶段:结合教师模型在 /think 和 /no think 两种模式下生成的输出对学生模型进行response蒸馏(数据蒸馏),以及将学生模型的logits与教师模型对齐,以最小化KL散度(logits蒸馏)。
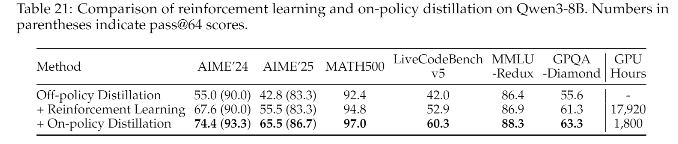
小模型上蒸馏和RL的效果对比
从上图的结果可以看到,在小模型上使用logits蒸馏的效果要优于直接做RL的效果,并且logits蒸馏的GPU Hours仅为RL的1/10。(蒸馏YYDS)
4 结语
Qwen 3的主要改进在于预训练数据的增加和后训练流程的优化,特别是think和no think模式的融合是其亮点。

