怎么创建自己公司的网站网站建设最新技术
一、前言
在日常业务需求中,往往会遇到解析pdf文件中的段落或者表格数据的需求。
常见的做法是使用 pdfbox 来做,但是它只能提取文本数据,没有我们在文件页面上面的那种结构化组织,文本通常是散乱的包含各种换行回车空格等格式,因而它适合做一些段落文本提取。
而 tabula 在 pdfbox 的基础上做了表格的特殊处理,能够直接读取到单元格中的内容,但是它处理的前提是表格必须常规完整边框的表格,只有部分边框或者无边框的这种结构化数据还是束手无策。
针对上述情况,笔者实现了有边框和无边框表格的数据读取并结构化,也支持段落文本提取。
二、功能实现
2.1 引入依赖
<!-- PDF解析,内含pdfbox -->
<dependency><groupId>technology.tabula</groupId><artifactId>tabula</artifactId><version>1.0.5</version>
</dependency>
2.2 完整边框表格
- 支持多表格
- 支持分页
- 支持跳过标题行
- 支持跳过标题前无关行
- 支持生成字段
- 返回完整集合数据
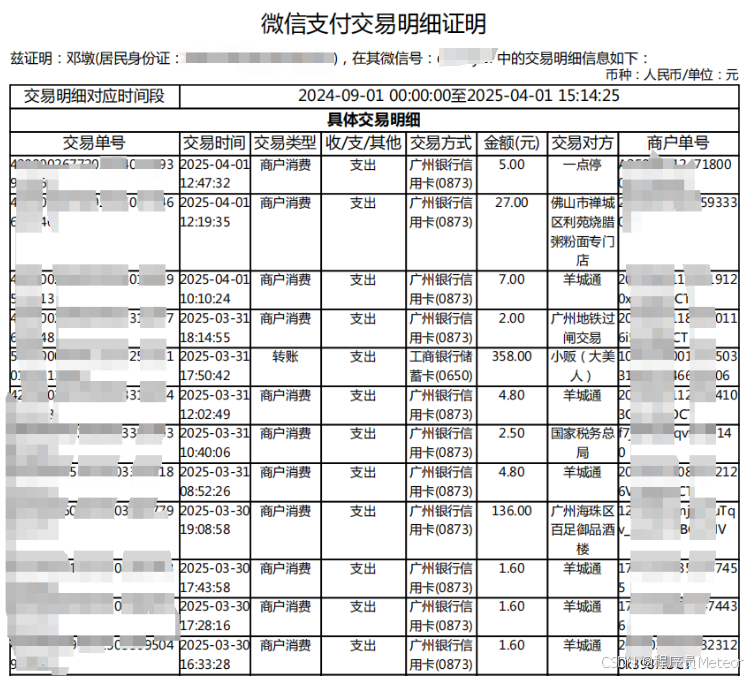
2.2.1 代码实现
package com.qiangesoft.pdf.util;import com.alibaba.fastjson.JSON;
import lombok.extern.slf4j.Slf4j;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;
import technology.tabula.*;
import technology.tabula.extractors.SpreadsheetExtractionAlgorithm;import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.math.BigDecimal;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;/*** pdf工具类* ps:适合解析纯文本、解析表格数据** @author qiangesoft* @date 2025-05-28*/
@Slf4j
public class PdfUtil {public static void main(String[] args) throws FileNotFoundException {String txt = readTxtFromPdf("C:\\Users\\admin\\Desktop\\微信流水.pdf", null);System.out.println(txt);List<List<Map<String, String>>> dataGroupList = readTableDataFromPdf("C:\\Users\\admin\\Desktop\\微信流水.pdf", null, true);for (List<Map<String, String>> list : dataGroupList) {for (Map<String, String> map : list) {System.out.println(JSON.toJSONString(map));}}}/*** 解析pdf的文本数据** @param filePath 文件路径* @param password 文件密码* @return*/public static String readTxtFromPdf(String filePath, String password) throws FileNotFoundException {return readTxtFromPdf(new FileInputStream(filePath), password);}/*** 解析pdf的文本数据** @param inputStream 文件流* @param password 文件密码* @return*/public static String readTxtFromPdf(InputStream inputStream, String password) {String textContent = "";try (PDDocument document = PDDocument.load(inputStream, password)) {PDFTextStripper stripper = new PDFTextStripper();textContent = stripper.getText(document);} catch (IOException e) {e.printStackTrace();}return textContent;}/*** 解析pdf的表格数据** @param filePath 文件路径* @param password 文件密码* @param skipFirstRow 是否跳过表头行 【连续分页表格可能每页有表头】* @return*/public static List<List<Map<String, String>>> readTableDataFromPdf(String filePath, String password, boolean skipFirstRow) throws FileNotFoundException {return readTableDataFromPdf(new FileInputStream(filePath), password, skipFirstRow);}/*** 解析pdf的表格数据** @param inputStream 文件流* @param password 文件密码* @param skipFirstRow 是否跳过表头行* @return*/public static List<List<Map<String, String>>> readTableDataFromPdf(InputStream inputStream, String password, boolean skipFirstRow) {// 按照同一个表格分组List<List<Map<String, String>>> dataGroupList = new ArrayList<>();// 表格提取算法SpreadsheetExtractionAlgorithm algorithm = new SpreadsheetExtractionAlgorithm();try (PDDocument document = PDDocument.load(inputStream, password)) {ObjectExtractor extractor = new ObjectExtractor(document);PageIterator pi = extractor.extract();// 遍历页double x = 0;int tableIndex = 0;int tableHeadRowNum = 0;List<Table> tables = new ArrayList<>();List<String> fieldList = new ArrayList<>();while (pi.hasNext()) {Page page = pi.next();List<Table> tableList = algorithm.extract(page);// 遍历表格for (Table table : tableList) {if (tableIndex == 0) {tableHeadRowNum = getTableHeadRowNum(table, fieldList);tables.add(table);tableIndex++;} else {// 第一个 or x轴且列数相同为同一个表格if (new BigDecimal(table.getX()).subtract(new BigDecimal(x)).abs().compareTo(new BigDecimal("0.001")) <= 0&& fieldList.size() == table.getRows().get(0).size()) {tables.add(table);} else {List<Map<String, String>> dataList = convertTableToMap(tables, fieldList, tableHeadRowNum, skipFirstRow);dataGroupList.add(dataList);tables = new ArrayList<>();tables.add(table);tableIndex = 0;}}x = table.getX();}}// 最后一个特殊处理if (!tables.isEmpty()) {List<Map<String, String>> dataList = convertTableToMap(tables, fieldList, tableHeadRowNum, skipFirstRow);dataGroupList.add(dataList);}} catch (Exception e) {e.printStackTrace();}return dataGroupList;}/*** 获取字段并返回表格头的行** @param table 表格* @param fieldList 字段列表* @return*/private static int getTableHeadRowNum(Table table, List<String> fieldList) {// 获取表格头int headRowNum = 0;List<List<RectangularTextContainer>> rowList = table.getRows();for (int i = 0; i < rowList.size(); i++) {fieldList.clear();List<RectangularTextContainer> cellList = rowList.get(i);int k = 0;for (int j = 0; j < cellList.size(); j++) {RectangularTextContainer cell = cellList.get(j);if (cell instanceof Cell) {k++;fieldList.add("k" + k);}}if (fieldList.size() == cellList.size()) {headRowNum = i;break;}}return headRowNum;}/*** 将表格数据转为映射数据** @param tableList 表格列表* @param fieldList 字段列表* @param tableHeadRowNum 表格头行* @param skipFirstRow 是否跳过表头行* @return*/private static List<Map<String, String>> convertTableToMap(List<Table> tableList, List<String> fieldList, int tableHeadRowNum, boolean skipFirstRow) {List<Map<String, String>> dataList = new ArrayList<>();for (int i = 0; i < tableList.size(); i++) {// 表格所有行Table table = tableList.get(i);List<List<RectangularTextContainer>> rowList = table.getRows();// 遍历行for (int j = (i == 0 ? tableHeadRowNum + 1 : skipFirstRow ? 1 : 0); j < rowList.size(); j++) {List<RectangularTextContainer> cellList = rowList.get(j);Map<String, String> data = new HashMap<>();// 遍历列for (int m = 0; m < cellList.size(); m++) {RectangularTextContainer cell = cellList.get(m);// 去除换行符后设置值String text = cell.getText().replace("\r", "");data.put(fieldList.get(m), text);}dataList.add(data);}}return dataList;}/*** 读取指定文字中间的文本** @param txt 文本* @param startStr 开始字符串* @param endStr 结束字符串* @return*/public static String readTxtFormTxt(String txt, String startStr, String endStr) {int index1 = txt.indexOf(startStr);if (index1 == -1) {return null;}int index2 = txt.length();if (endStr != null) {index2 = txt.indexOf(endStr);if (index2 == -1) {index2 = txt.length();}}return txt.substring(index1 + startStr.length(), index2);}}2.2.2 解析结果
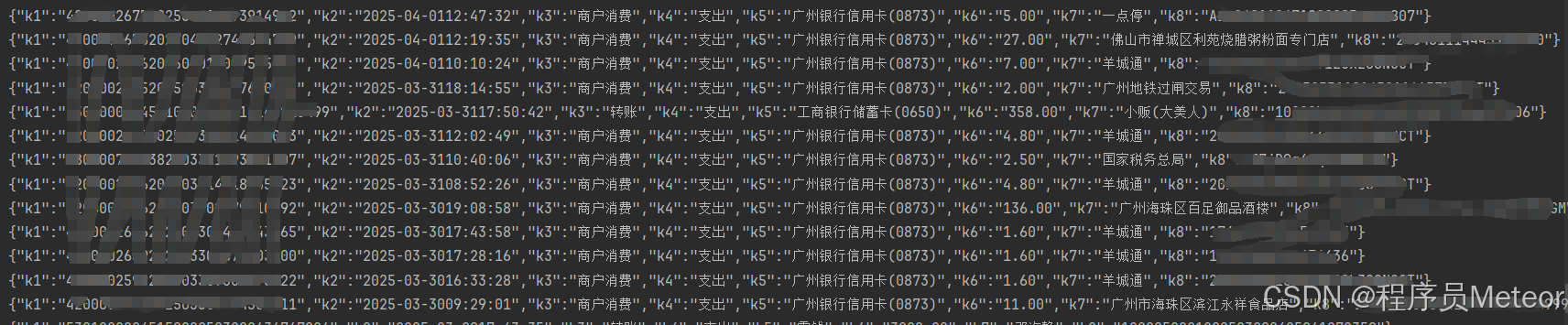
2.3 无边框表格
- 支持单表格
- 支持分页
- 支持跳过标题行
- 支持生成字段
- 返回完整集合数据
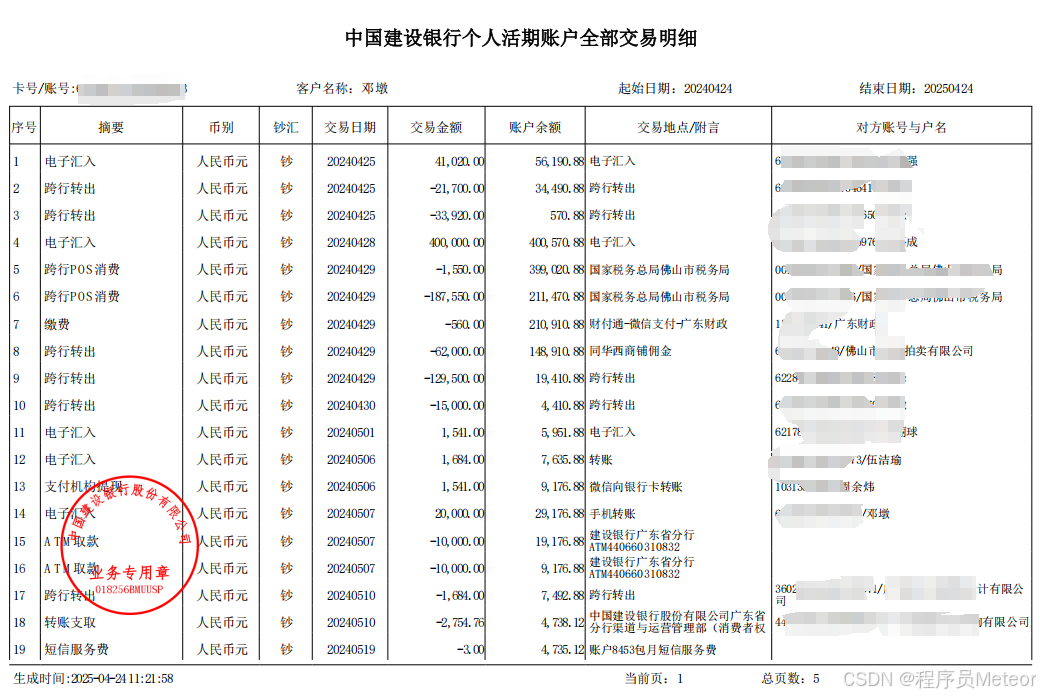
2.3.1 代码实现
package com.qiangesoft.pdf.util;import com.alibaba.fastjson.JSONObject;
import org.springframework.util.CollectionUtils;import java.io.IOException;
import java.util.*;/*** pdf规则数据分析工具类* ps:分析处理PdfUtil解决不了的表格,没有格子** @author qiangesoft* @date 2025-05-28*/
public class PdfRuleDataUtil {public static void main(String[] args) throws IOException {String fileTxt = PdfUtil.readTxtFromPdf("C:\\Users\\admin\\Desktop\\流水文件\\中国建设银行.pdf", null);System.out.println(readTxt(fileTxt, "卡号/账号:", "客户名称:").trim());System.out.println(readTxt(fileTxt, "客户名称:", "起始日期:").trim());System.out.println(readTxt(fileTxt, "起始日期:", "结束日期:").trim());System.out.println(readTxt(fileTxt, "结束日期:", "序号").trim());List<Map<String, String>> dataList = readTableData(fileTxt, "序号 摘要 币别 钞汇 交易日期 交易金额 账户余额 交易地点/附言 对方账号与户名", "生成时间:");for (Map<String, String> map : dataList) {System.out.println(JSONObject.toJSONString(map));}}/*** 解析文本** @param fileTxt* @param startStr* @param endStr* @return*/public static String readTxt(String fileTxt, String startStr, String endStr) {return PdfUtil.readTxtFormTxt(fileTxt, startStr, endStr);}/*** 解析表格数据** @param fileTxt 文本数据* @param startStr 开始字符串 【一般为标题行,字段根据标题行定,***很重要***】* @param endStr 结束字符串 【结束标志,如果表格连续中间没有重复的标题行则直接使用表格末尾的结束标志即可,如果表格不连续每页都有标题行则使用每页的结束标志】* @return*/public static List<Map<String, String>> readTableData(String fileTxt, String startStr, String endStr) {int length = startStr.trim().split(" ").length;List<String> fieldList = new ArrayList<>();for (int i = 1; i <= length; i++) {fieldList.add("k" + i);}List<Map<String, String>> lists = new ArrayList<>();while (true) {String dataStr = readTxt(fileTxt, startStr, endStr);if (dataStr == null) {break;}List<Map<String, String>> pageLists = readDataFromTxt(dataStr, startStr, fieldList);fileTxt = fileTxt.substring(fileTxt.indexOf(endStr) + endStr.length());if (CollectionUtils.isEmpty(pageLists)) {break;} else {lists.addAll(pageLists);}}return lists;}/*** 解析pdf的文本数据* ps:通过换行符进行分割行,然后根据空格分割列【如果列中数据存在空格则无法解决】** @param dataStr 待解析的文本* @param tableHeadTxt 标题行文本* @param fieldList 字段列表* @return*/private static List<Map<String, String>> readDataFromTxt(String dataStr, String tableHeadTxt, List<String> fieldList) {List<Map<String, String>> dataList = new ArrayList<>();int cellNum = fieldList.size();// "\r\n" or "\n"String[] split = dataStr.split(System.lineSeparator());StringBuilder chargeStr = new StringBuilder();for (int a = 0; a < split.length; a++) {String itemStr = split[a];// 标题行跳过if (itemStr.contains(tableHeadTxt)) {continue;}String[] split1;if (!chargeStr.toString().isEmpty()) {// 上一行未处理【加上本行一起处理】chargeStr.append(itemStr);split1 = chargeStr.toString().split(" ");} else {split1 = itemStr.split(" ");}if (split1.length < cellNum) { // 不足列数// 拼接本行if (chargeStr.toString().isEmpty()) {chargeStr.append(itemStr);}// 最后一行特殊处理if (a == split.length - 1) {Map<String, String> dataMap = new HashMap<>();for (int i = 0; i < cellNum; i++) {if (i > split1.length - 1) {dataMap.put(fieldList.get(i), null);} else {dataMap.put(fieldList.get(i), split1[i]);}}dataList.add(dataMap);}} else if (split1.length > cellNum) { // 超过列数if (!chargeStr.toString().isEmpty()) {// 处理上一行String[] split2 = chargeStr.toString().replace(itemStr, "").split(" ");Map<String, String> dataMap = new HashMap<>();for (int i = 0; i < cellNum; i++) {if (i > split2.length - 1) {dataMap.put(fieldList.get(i), null);} else {dataMap.put(fieldList.get(i), split2[i]);}}dataList.add(dataMap);}// 处理本行chargeStr = new StringBuilder();String[] split3 = itemStr.split(" ");if (split3.length < cellNum) { // 本行不足列数// 拼接本行if (chargeStr.toString().isEmpty()) {chargeStr.append(itemStr);}// 最后一行特殊处理if (a == split.length - 1) {Map<String, String> dataMap = new HashMap<>();for (int i = 0; i < cellNum; i++) {if (i > split3.length - 1) {dataMap.put(fieldList.get(i), null);} else {dataMap.put(fieldList.get(i), split3[i]);}}dataList.add(dataMap);}} else { // 本行大于等于列数Map<String, String> dataMap = new HashMap<>();for (int i = 0; i < cellNum; i++) {if (i > split3.length - 1) {dataMap.put(fieldList.get(i), null);} else {dataMap.put(fieldList.get(i), split3[i]);}}dataList.add(dataMap);}} else { // 等于列数Map<String, String> dataMap = new HashMap<>();for (int i = 0; i < cellNum; i++) {dataMap.put(fieldList.get(i), split1[i]);}dataList.add(dataMap);chargeStr = new StringBuilder();}}return dataList;}}2.3.2 解析结果

2.4 解析段落

2.4.1 代码实现
/*** 读取指定文字中间的文本** @param txt 文本* @param startStr 开始字符串* @param endStr 结束字符串* @return*/public static String readTxtFormTxt(String txt, String startStr, String endStr) {int index1 = txt.indexOf(startStr);if (index1 == -1) {return null;}int index2 = txt.length();if (endStr != null) {index2 = txt.indexOf(endStr);if (index2 == -1) {index2 = txt.length();}}return txt.substring(index1 + startStr.length(), index2);}
2.4.2 解析结果

三、源码仓库
码云:https://gitee.com/qiangesoft/boot-business/tree/master/boot-business-pdf
