网站开发遵循做一样的模板网站会被告侵权吗
例1
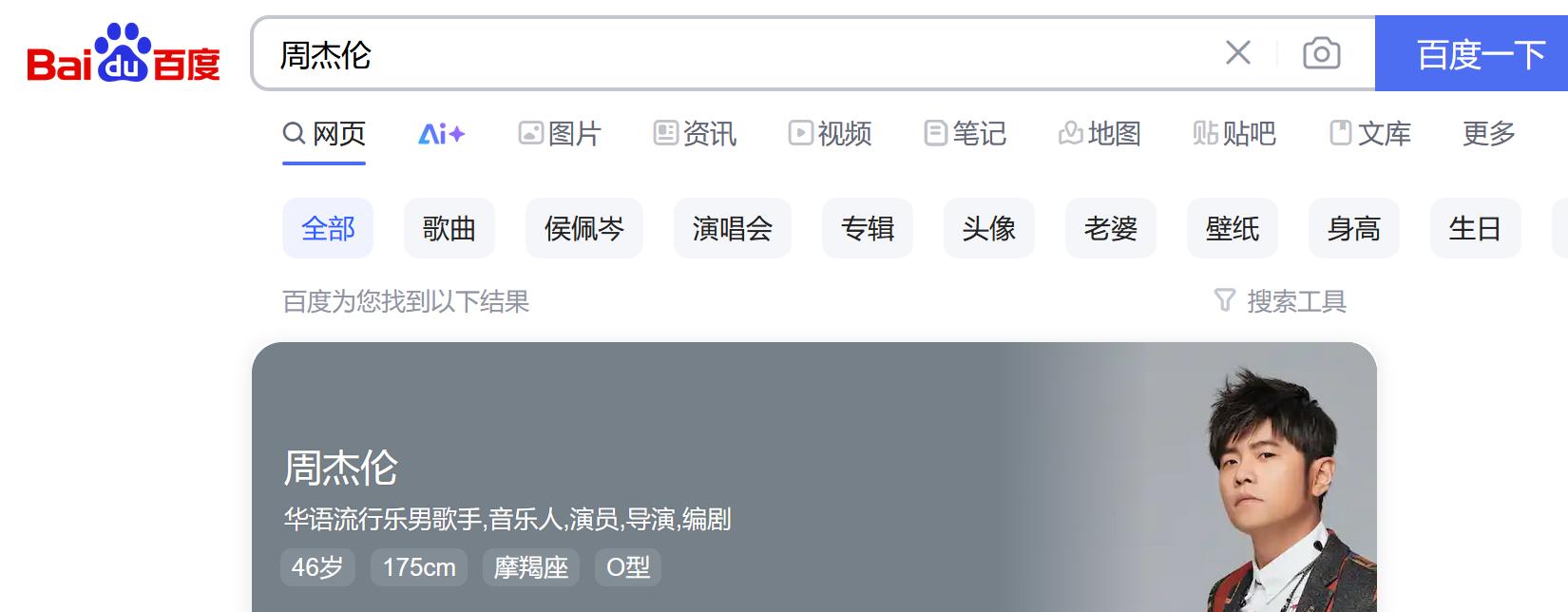
例1:写一个爬取百度搜索页面的程序,以搜索一个喜欢的明星为例(如在搜索框中输入周杰伦)
正常搜索

页面
爬虫思路:
1.用一个query变量,在控制台输入的方式更加灵活的输入想爬取的明星的百度搜索页面
因为是get请求,所以把wd=周杰伦的‘周杰伦’替换成{},{}的作用是把一个变量放到一个字符串里面,再在url后面追加字符串的format方法.format(query)实现,其中wd的作用是作为查询参数
2.添加一个user-agent代理在请求头里面,伪装成一个更像正常浏览器搜索的动作,因为百度有反爬机制,如果未检测到一个请求的user-agent(请求的设备【浏览器&操作系统&设备型号】),就会阻止访问
3.将爬取到的信息保存到一个文件中zhou.html
代码实现:
import requests
query = input("你喜欢的一个明星")
url='https://www.baidu.com/baidu?ie=utf-8&wd={}'.format(query)#大括号将某个变量放到一个字符串里面
myHeaders ={#伪装一个UserAgent,伪装的更像浏览器
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:137.0) Gecko/20100101 Firefox/137.0"
}
resp = requests.get(url,headers=myHeaders)#处理一个小小的反爬
with open("Zhou.html", mode="w",encoding="utf-8") as f:#写入模式f.write(resp.text)结果 :
控制台输入周杰伦
![]()
创建了一个爬取的信息的文件zhou.html,用浏览器打开这个html前端页面
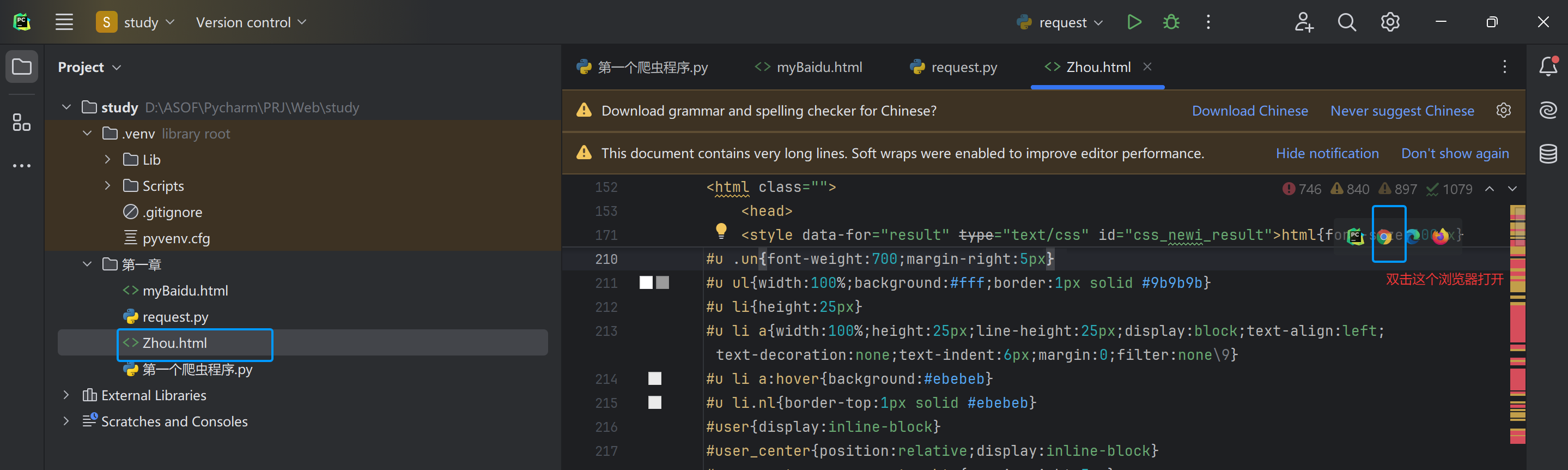
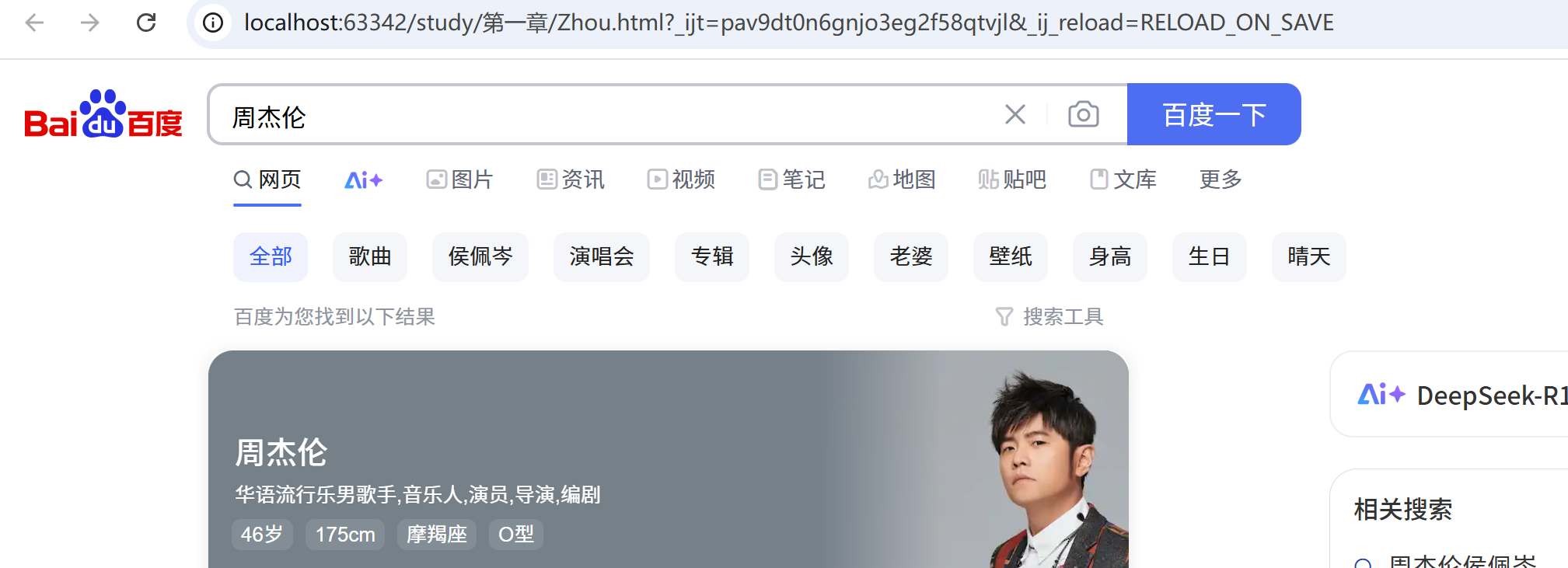
由下面的localhost地址知道这个页面是爬取到的,和正常访问的页面一样,爬取成功
例2
例2:百度翻译爬虫爬取
正常访问的页面:
1、右键->检查:进入抓包工具页面
2、输入dog,点击sug(链接),点击preview,查看响应的json数据
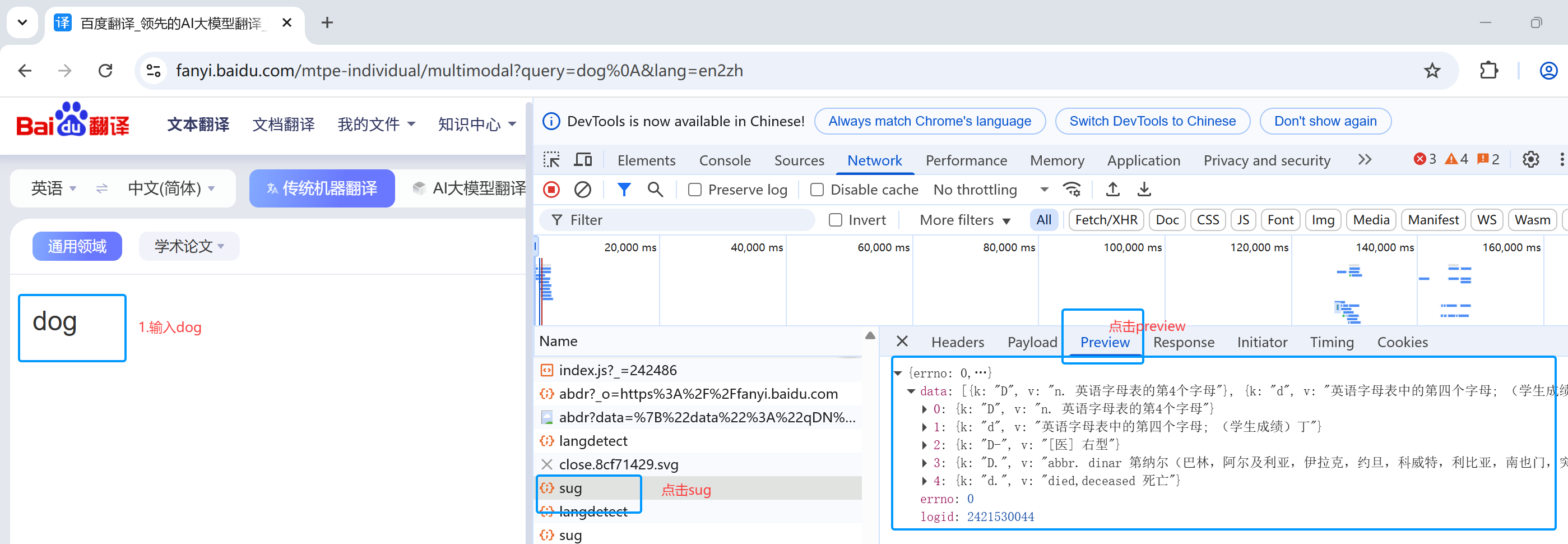
3.查看请求方式
观察到此次请求的方式为POST,利用POST请求发送的参数为Form Data,传参方式与GET有差别,GET的传输参数是直接拼接到了URL里面
下面的url为https://fanyi.baidu.com/sug

代码实现:
import requests
url = "https://fanyi.baidu.com/sug"
s = input("请输入你要翻译的英文单词")
myData = {"kw": s
}myHeaders = {#伪装浏览器,反反爬策略
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:137.0) Gecko/20100101 Firefox/137.0"
}
#发送post请求(发送的数据必须放在字典中,通过data的参数进行传递
resp = requests.post(url, data=myData, headers=myHeaders)
#将服务器返回的内容直接处理成json格式的数据(在python中就是词典)
print(resp.json())结果:

例3
请求路径和请求方式
如下图,请求路径URL如下,问号?前面的是请求的统一路径,问号?后面的是GET请求具体的参数(直接拼接到原URL上面)
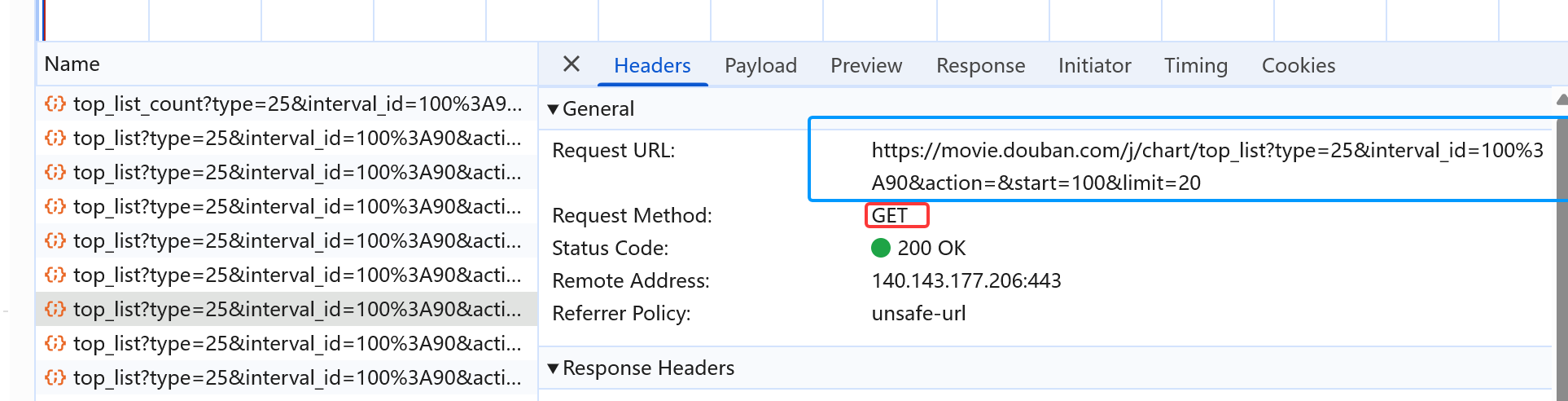
请求的参数如下图
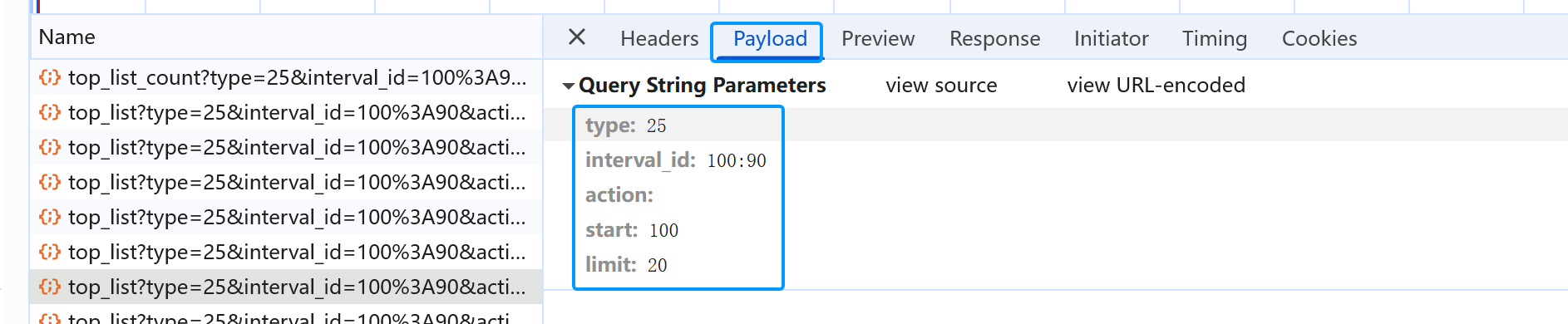
知道了请求的路径、请求的方式(GET请求)以及请求的参数就可以编写爬虫程序代码
代码实现:
GET请求的url拼接(因为原url问号后面的GET请求参数过长,所以统一封装成json格式的参数)
import requests
#1--url
url = "https://movie.douban.com/j/chart/top_list"#2--统一封装GET请求的参数
myParam = {
"type": "25",
"interval_id": "100:90",
"action": "",
"start": "100",
"limit": "20"
}#拼接url和parameter
resp = requests.get(url=url, params=myParam)
#验证这个url是否和原始url一样
print(resp.request.url)控制台输出 ,如下图所示,url完全相同,代表拼接正确

被反爬
如果运行成功,但是控制台没有出现任何的爬取内容,说明被反爬了,阻止了访问

排查原因进行反反爬(首先进行user-agent位置)
因为基本上被反爬的首要原因就是因为服务器对于user-agent进行了检查
user-agent
包括访问者使用的浏览器类型、浏览器语言、浏览器插件、OS版本、CPU类型、浏览器渲染引擎

反反爬步骤
1.复制自己的User-Agent,在抓包工具的network中的header请求头中可以查到,将自己的代理复制
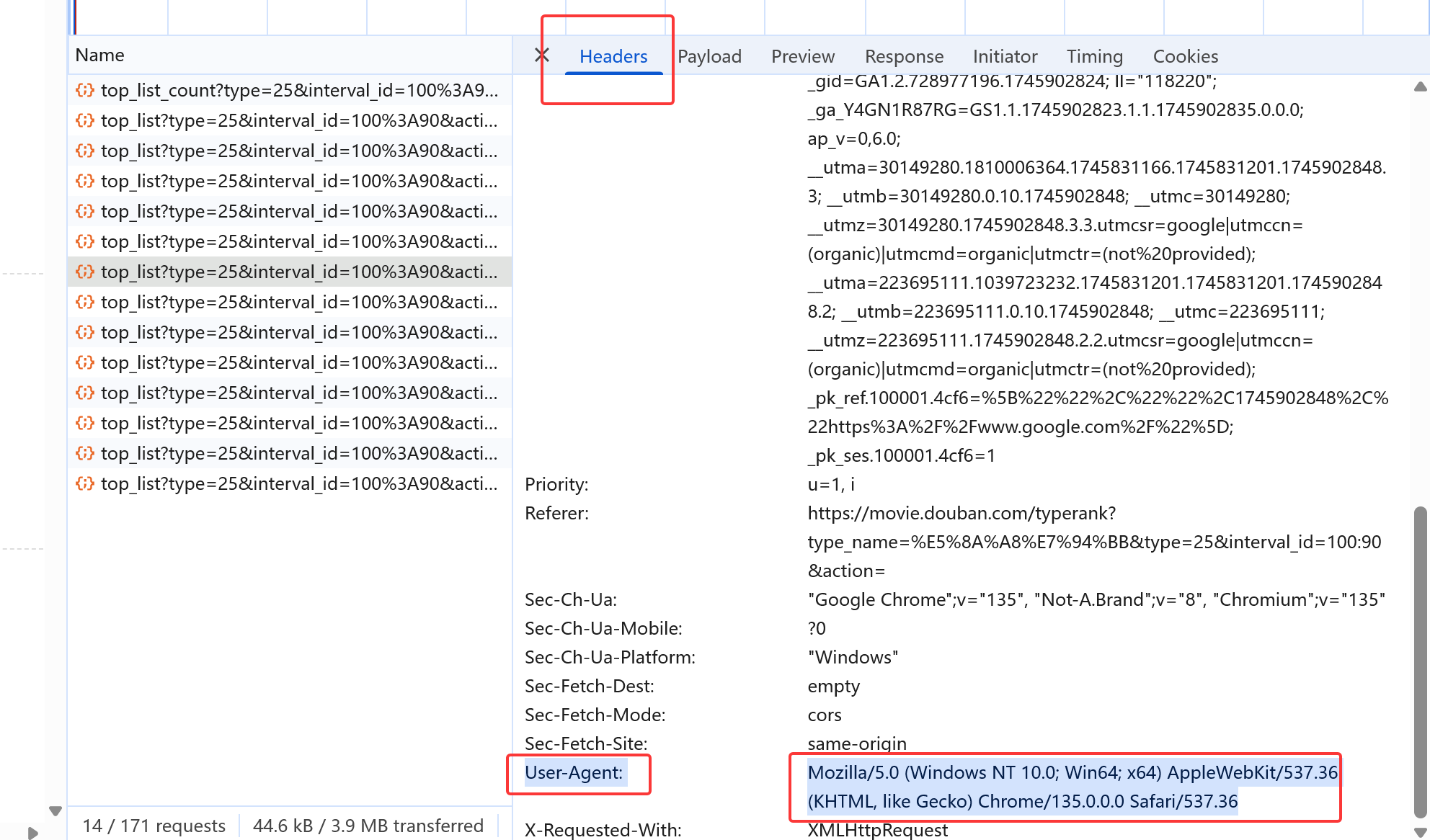
新增一个请求头的内容如下:
myHeaders = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:137.0) Gecko/20100101 Firefox/137.0"
}
添加到原来的请求中
resp = requests.get(url=url, params=myParam,headers=myHeaders)
再次运行,出现爬取内容,说明被反爬的原因就是因为该网站设置了对User-agent进行检查,此次反反爬成功

上面的内容太乱,所以输出改为json格式的,因为本来这些数据都是用json封装的
print(resp.json())输出结果
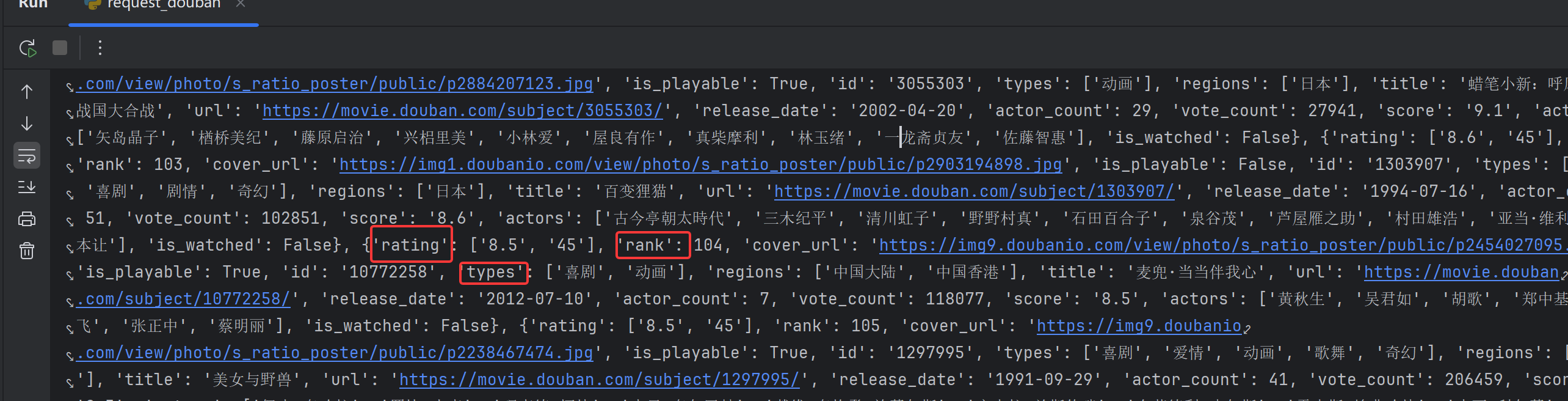
完整代码:
import requests
#1--url
url = "https://movie.douban.com/j/chart/top_list"#2--统一封装GET请求的参数
myParam = {
"type": "25",
"interval_id": "100:90",
"action": "",
"start": "100",
"limit": "20"
}
myHeaders = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:137.0) Gecko/20100101 Firefox/137.0"
}#拼接url和parameter
resp = requests.get(url=url, params=myParam,headers=myHeaders)
#验证这个url是否和原始url一样
print(resp.request.url)
#如果控制台没有任何内容但也没有报错说明被反爬了,要使用反反爬策略(挨个尝试是什么原因导致自己被反爬了(很大可能就是因为没有user-agent)
print(resp.json())
resp.close()#关闭掉请求(否则会一直保持这个url链接),请求会被堵死(出现请求次数过多的现象)注意在爬取完数据一定要关上请求,否则就会一直保持这个链接,多次访问这同一个URL后可能会造成堵死