做介绍翻译英文网站排名app
大型语言模型(LLMs)在数据理解方面表现出色,这也促成了它们最重要的应用场景之一:能够将常规的人类语言(我们称之为非结构化数据)转化为特定的、规范的、可被计算机程序处理的格式。我们将这一过程的输出称为结构化数据。由于在转换过程中通常会忽略大量冗余数据,因此我们称其为提取(extraction)。
LlamaIndex 中结构化数据提取的核心是 Pydantic 类:你可以在 Pydantic 中定义一个数据结构,然后 LlamaIndex 会与 Pydantic 协作,将 LLM 的输出强制转换为该结构。
Pydantic 介绍
Pydantic 是一个广泛使用的数据验证和转换库。它 heavily 依赖于 Python 的类型声明。该项目的官方文档中有一份关于 Pydantic 的详尽指南,但在这里我们将仅介绍其基本内容。
要创建一个 Pydantic 类,需要继承自 Pydantic 的 BaseModel 类:
from pydantic import BaseModelclass User(BaseModel):id: intname: str = "Jane Doe"在这个示例中,你创建了一个 User 类,包含两个字段:id 和 name。你将 id 定义为整数,name 定义为字符串,默认值为 Jane Doe。
你可以通过嵌套这些模型来创建更复杂的结构:
from typing import List, Optional
from pydantic import BaseModelclass Foo(BaseModel):count: intsize: Optional[float] = Noneclass Bar(BaseModel):apple: str = "x"banana: str = "y"class Spam(BaseModel):foo: Foobars: List[Bar]现在,Spam 拥有一个 foo 和一个 bars。Foo 包含一个 count 和一个可选的 size,而 bars 是一个对象列表,每个对象都有一个 apple 和 banana 属性。
将 Pydantic 对象转换为 JSON Schema
Pydantic 支持将 Pydantic 类转换为符合流行标准的 JSON 序列化模式对象。例如,上面的 User 类将被序列化为以下形式:
{"properties": {"id": {"title": "Id","type": "integer"},"name": {"default": "Jane Doe","title": "Name","type": "string"}},"required": ["id"],"title": "User","type": "object"
}这一特性至关重要:这些 JSON 格式的模式经常被传递给大型语言模型(LLMs),而 LLMs 会将其用作如何返回数据的指令。
使用注解
如前所述,大型语言模型(LLMs)会使用来自 Pydantic 的 JSON 模式作为返回数据的指令。为了帮助 LLM 更好地理解并提高返回数据的准确性,建议在模式中包含对对象和字段的自然语言描述,说明它们的用途。Pydantic 通过文档字符串(docstrings)和 Field 支持这一功能。
使用结构化 LLM
在 LlamaIndex 中提取结构化数据的最高级方式是实例化一个结构化 LLM(Structured LLM)。首先,让我们像之前一样实例化我们的 Pydantic 类:
from datetime import datetime
from typing import Listfrom pydantic import BaseModel, Fieldclass LineItem(BaseModel):""" 发票中的一项明细。 """item_name: str = Field(description="产品名称")price: float = Field(description="产品价格")class Invoice(BaseModel):""" 发票信息 """invoice_id: str = Field(description="该发票的唯一标识符,通常是一个数字")date: datetime = Field(description="该发票的创建日期")line_items: List[LineItem] = Field(description="该发票中所有项目的列表")接着安装用于读取 PDF 文件的模块:
pip install llama-index-readers-file -i https://mirrors.aliyun.com/pypi/simple/现在,我们来加载一份实际发票的文本内容:
from llama_index.readers.file import PDFReader
from pathlib import Pathpdf_reader = PDFReader()
documents = pdf_reader.load_data(file=Path("./uber_receipt.pdf"))
text = documents[0].text接下来,我们实例化一个 LLM,传入我们的 Pydantic 类,并让它使用发票的纯文本内容进行补全处理:
from llama_index.llms.openai import OpenAIllm = OpenAI(model="gpt-4o")
sllm = llm.as_structured_llm(Invoice)response = sllm.complete(text)response 是一个 LlamaIndex 的 CompletionResponse 对象,它包含两个属性:text 和 raw。其中,text 包含经过 Pydantic 处理后的响应的 JSON 序列化形式:
json_response = json.loads(response.text)
print(json.dumps(json_response, indent=2)){"invoice_id": "Visa \u2022\u2022\u2022\u20224469","date": "2024-10-10T19:49:00","line_items": [{"item_name": "Trip fare", "price": 12.18},{"item_name": "Access for All Fee", "price": 0.1},{"item_name": "CA Driver Benefits", "price": 0.32},{"item_name": "Booking Fee", "price": 2.0},{"item_name": "San Francisco City Tax", "price": 0.21},],
}请注意,这张发票没有编号,因此 LLM 尽力而为,使用了信用卡号作为替代。需要强调的是,Pydantic 的验证并不能保证数据一定准确!
response 的 raw 属性(名称上有些令人困惑)包含了 Pydantic 对象本身:
from pprint import pprintpprint(response.raw)Invoice(invoice_id="Visa ••••4469",date=datetime.datetime(2024, 10, 10, 19, 49),line_items=[LineItem(item_name="Trip fare", price=12.18),LineItem(item_name="Access for All Fee", price=0.1),LineItem(item_name="CA Driver Benefits", price=0.32),LineItem(item_name="Booking Fee", price=2.0),LineItem(item_name="San Francisco City Tax", price=0.21),],
)请注意,Pydantic 创建的是一个完整的 datetime 对象,而不仅仅是将日期表示为字符串。
结构化 LLM 的行为与常规的 LLM 类完全相同:你可以调用 chat、stream、achat、astream 等方法,它在所有情况下都会返回 Pydantic 对象。你还可以将结构化 LLM 作为参数传递给 VectorStoreIndex.as_query_engine(llm=sllm),它将自动以结构化对象的形式响应你的 RAG 查询。
结构化 LLM 会自动为你处理所有的提示(prompting)工作。如果你想对提示内容拥有更多控制权,请继续学习《结构化预测(Structured Prediction)》相关内容。
结构化预测
结构化预测(Structured Prediction)让您对自己的应用程序如何调用大语言模型(LLM)具有更细致的控制,并且可以使用 Pydantic。我们将沿用之前示例中的同一个 Invoice 类,以相同的方式加载 PDF 文件,并继续使用 OpenAI。不同之处在于,我们不再创建一个结构化的 LLM,而是直接在 LLM 本身上调用 structured_predict 方法;这是每个 LLM 类都提供的一个方法。
结构化预测(Structured predict)接受一个 Pydantic 类和一个提示模板(Prompt Template)作为参数,同时还接受提示模板中所需变量的关键词参数。
from my_llms.MyLLMsClients import MyLLMsClients
from llama_index.core.prompts import PromptTemplate
from models.MyModels import Invoicefrom llama_index.readers.file import PDFReader
from pathlib import Pathllm = MyLLMsClients.deepseek_client()pdf_reader = PDFReader()
documents = pdf_reader.load_data(file=Path("../data/发票/发票_20250510202033.pdf"))
text = documents[0].text
#print(text)prompt = PromptTemplate("从以下文本中提取发票信息。如果找不到发票编号(invoice ID),则使用公司名称“{company_name}”和日期作为发票编号:{text}"
)response = llm.structured_predict(Invoice, prompt, text=text, company_name="Uber"
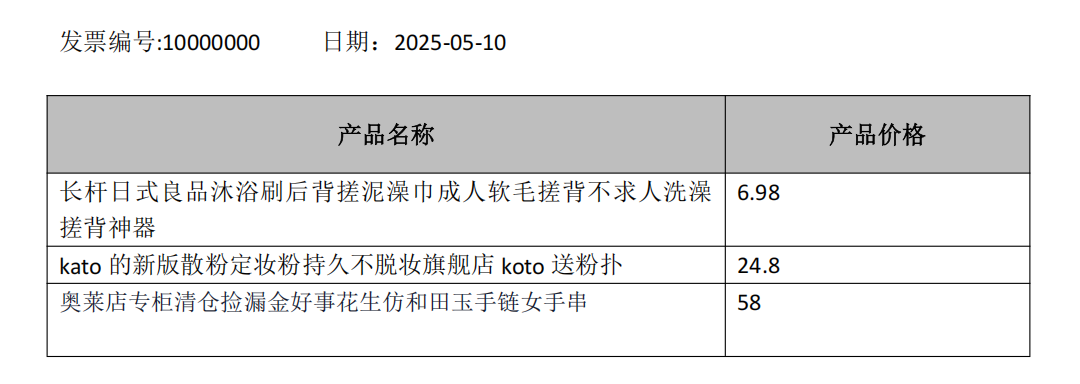
)print(response)invoice_id='10000000' date=datetime.datetime(2025, 5, 10, 0, 0) line_items=[LineItem(item_name='长杆日式良品沐浴刷后背搓泥澡巾成人软毛搓背不求人洗澡 搓背神器', price=6.98), LineItem(item_name='kato 的新版散粉定妆粉持久不脱妆旗舰店 koto 送粉扑', price=24.8), LineItem(item_name='奥莱店专柜清仓捡漏金好事花生仿和田玉手链女手串', price=58.0)]如你所见,这使我们能够在 Pydantic 无法完全正确解析数据时,为 LLM 提供额外的提示指令。在这种情况下,返回的对象本身就是 Pydantic 对象。如果需要,我们还可以将其输出为 JSON 格式:
json_output = response.model_dump_json()
print(json.dumps(json.loads(json_output), indent=2, ensure_ascii=False)){"invoice_id": "10000000","date": "2025-05-10T00:00:00","line_items": [{"item_name": "长杆日式良品沐浴刷后背搓泥澡巾成人软毛搓背不求人洗澡搓背神器","price": 6.98},{"item_name": "kato 的新版散粉定妆粉持久不脱妆旗舰店 koto 送粉扑","price": 24.8},{"item_name": "奥莱店专柜清仓捡漏金好事花生仿和田玉手链女手串","price": 58.0}]
}structured_predict 拥有多种变体,适用于不同的使用场景,包括异步调用(astructured_predict)和流式传输(stream_structured_predict、astream_structured_predict)。
根据你使用的 LLM 不同,structured_predict 会使用两种不同的类中的一种来处理调用 LLM 和解析输出。
FunctionCallingProgram
如果你使用的 LLM 拥有函数调用(function calling)API,FunctionCallingProgram 将会:
-
将 Pydantic 对象转换为一个工具(tool)
-
在提示(prompt)LLM 的同时强制其使用该工具
-
返回生成的 Pydantic 对象
这通常是一种更可靠的方法,如果可用,将优先使用该方法。然而,某些 LLM 仅支持文本输出,这类模型将会使用另一种方法。
LLMTextCompletionProgram
如果 LLM 仅支持文本输出,LLMTextCompletionProgram 将会:
-
将 Pydantic 对象的结构以 JSON 格式输出
-
将该结构和数据一同发送给 LLM,并通过提示指令要求其以符合该结构的形式进行响应
-
在 Pydantic 对象上调用 model_validate_json() 方法,并传入 LLM 返回的原始文本
这种方法的可靠性明显较低,但所有基于文本的 LLM 都支持这种方式。
直接调用预测类
在实际使用中,structured_predict 应该可以很好地兼容任何 LLM,但如果你需要更底层的控制,也可以直接调用 FunctionCallingProgram 和 LLMTextCompletionProgram,并进一步自定义其行为:
textCompletion = LLMTextCompletionProgram.from_defaults(output_cls=Invoice,llm=llm,prompt=PromptTemplate("从以下文本中提取发票信息。如果找不到发票编号(invoice ID),则使用公司名称“{company_name}”和日期作为发票编号:{text}"),
)output = textCompletion(company_name="Uber", text=text)以上操作等同于在没有函数调用 API 的 LLM 上调用 structured_predict,它会像 structured_predict 一样返回一个 Pydantic 对象。不过,你可以通过继承 PydanticOutputParser 来自定义输出的解析方式:
from llama_index.core.output_parsers import PydanticOutputParserclass MyOutputParser(PydanticOutputParser):def get_pydantic_object(self, text: str):# do something more clever than thisreturn self.output_parser.model_validate_json(text)textCompletion = LLMTextCompletionProgram.from_defaults(output_cls=Invoice,llm=llm,prompt=PromptTemplate("从以下文本中提取发票信息。如果找不到发票编号(invoice ID),则使用公司名称“{company_name}”和日期作为发票编号:{text}"),output_parser=MyOutputParser(output_cls=Invoice),
)output = textCompletion(company_name="Uber", text=text)print(output)如果你使用的是性能较弱的 LLM,需要在解析过程中获得额外帮助,这种方法将非常有用。