做的比较好网站有哪些建设干部学校网站首页
1. 准备工作
虚拟机环境
- 确保虚拟机中 Hadoop 已正确安装并启动(
start-dfs.sh和start-yarn.sh)。 - 确认 HDFS 的访问地址(通常为
hdfs://localhost:9000或hdfs://<虚拟机IP>:9000)。
IDEA 环境
- 安装 Java JDK(建议 1.8+)并配置环境变量。
2. 创建 Maven 项目
- 打开 IDEA → New Project → Maven
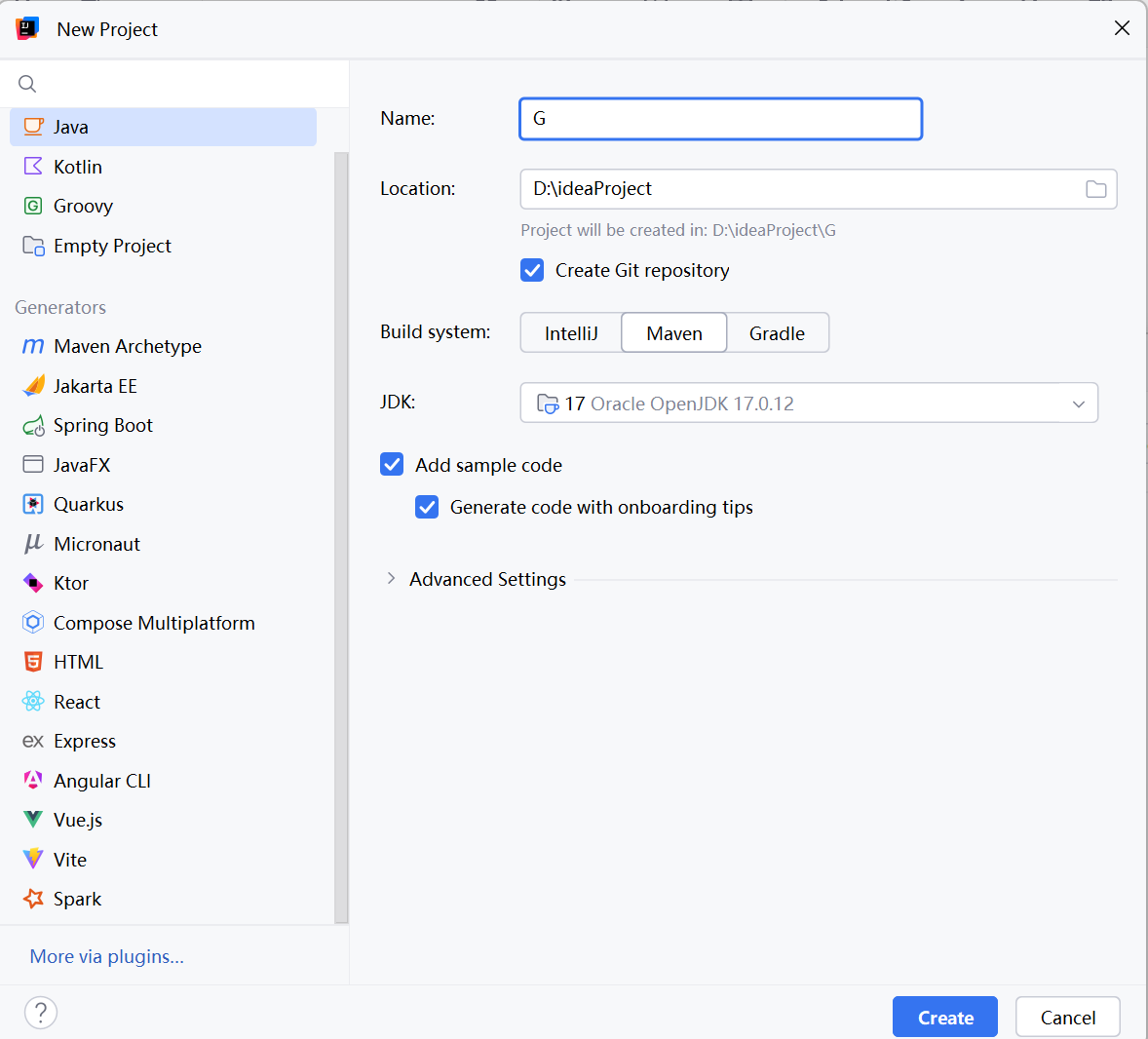
2.配置 JDK
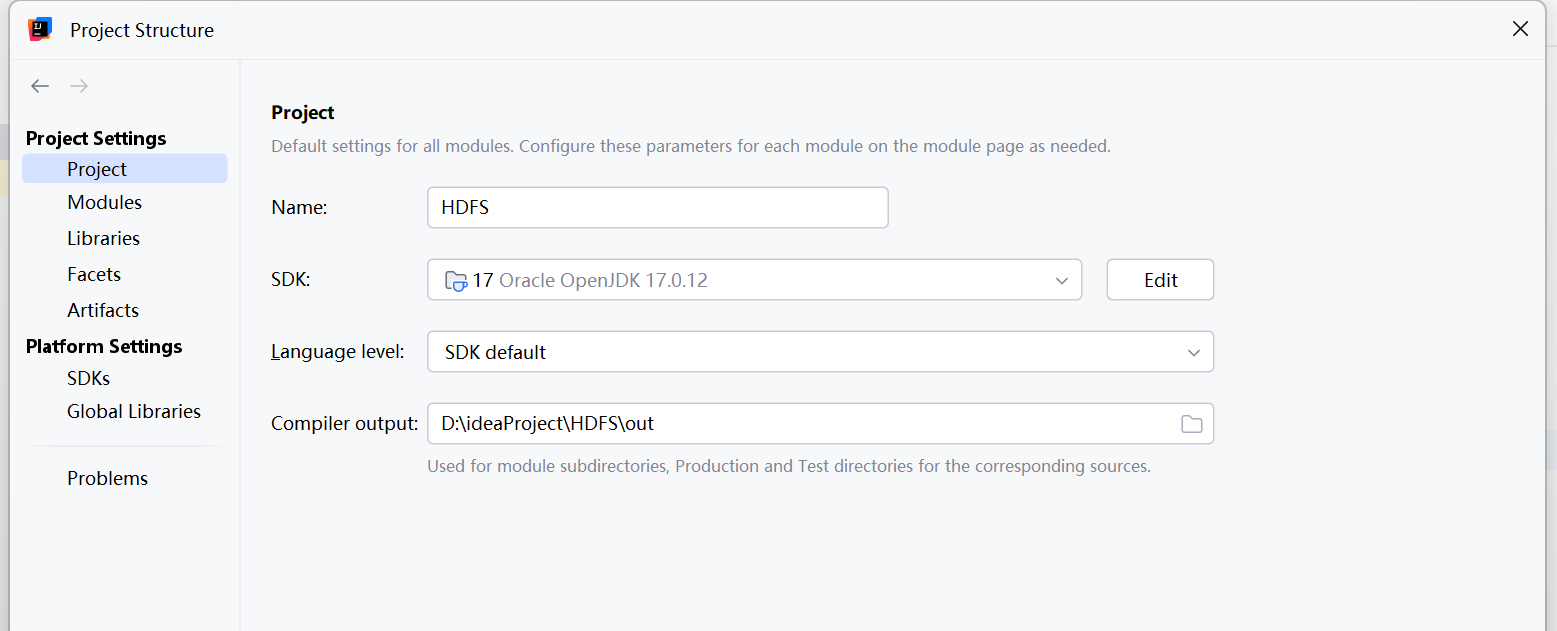
3.需要准备三个文件,日志文件、pom.xml配置文件、Java类,接着要实现的功能是通过idea来调用虚拟机的hdfs功能对文件的单词进行数量统计。
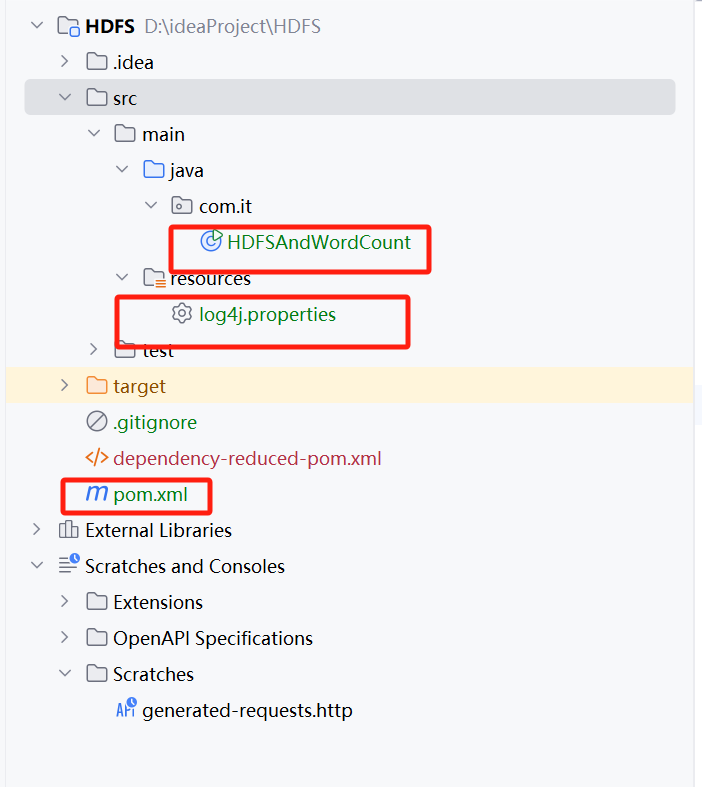
3. 添加 Hadoop 依赖
在 pom.xml 中添加以下依赖(根据你的 Hadoop 版本调整,也可以直接把我的粘在上面):
<project><groupId>cn.edu.xmu</groupId><artifactId>simple-project</artifactId><modelVersion>4.0.0</modelVersion><name>Simple Project</name><packaging>jar</packaging><version>1.0</version><properties><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><spark.version>2.4.0</spark.version><hadoop.version>3.2.1</hadoop.version></properties><repositories><repository><id>maven-central</id><url>https://repo.maven.apache.org/maven2</url></repository></repositories><dependencyManagement><dependencies><dependency><groupId>org.apache.sp</groupId><artifactId>spark-core_2.11</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>2.11.12</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>1.7.36</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-reload4j</artifactId><version>1.7.36</version></dependency><dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>27.0-jre</version></dependency></dependencies></dependencyManagement><dependencies><!-- Spark Core --><dependency><groupId>org.apache.spark</groupId> <!-- 修正 groupId --><artifactId>spark-core_2.11</artifactId><version>${spark.version}</version><exclusions><exclusion><groupId>com.google.guava</groupId><artifactId>guava</artifactId></exclusion></exclusions></dependency><!-- Hadoop Client --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version><exclusions><exclusion><groupId>com.google.guava</groupId><artifactId>guava</artifactId></exclusion></exclusions></dependency><!-- Scala Library --><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>2.11.12</version></dependency><!-- Logging --><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>1.7.36</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-reload4j</artifactId><version>1.7.36</version></dependency><!-- 显式添加兼容的 Guava 依赖 --><dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>27.0-jre</version></dependency></dependencies><build><sourceDirectory>src/main/java</sourceDirectory><plugins><!-- Java Compiler --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.8.1</version><configuration><source>${maven.compiler.source}</source><target>${maven.compiler.target}</target></configuration></plugin><!-- JAR Packaging --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.2.4</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><transformers><transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"><mainClass>com.it.HDFSAndWordCount</mainClass></transformer></transformers></configuration></execution></executions></plugin></plugins></build>
</project>若出现爆红信息可以点击如下图的刷新即可,将依赖导入进去,直到不出现爆红:
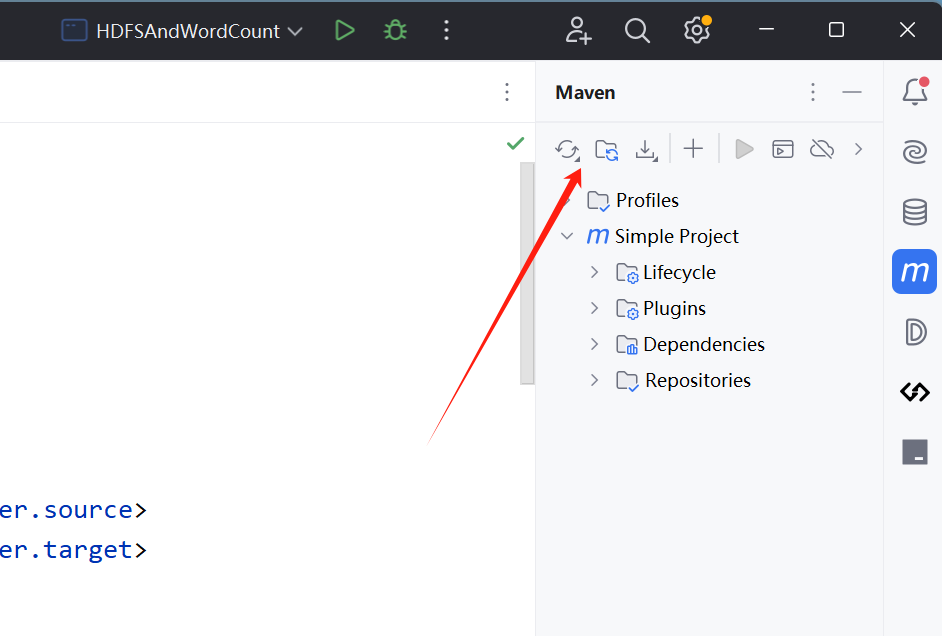
4. 配置日志文件 log4j.properties:
(直接粘贴这个就行)
log4j.rootCategory=WARN, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n5. 配置 HDFS 连接
查看虚拟机ip地址、和端口号
首先要查看自己虚拟机的ip地址(输入ifconfig):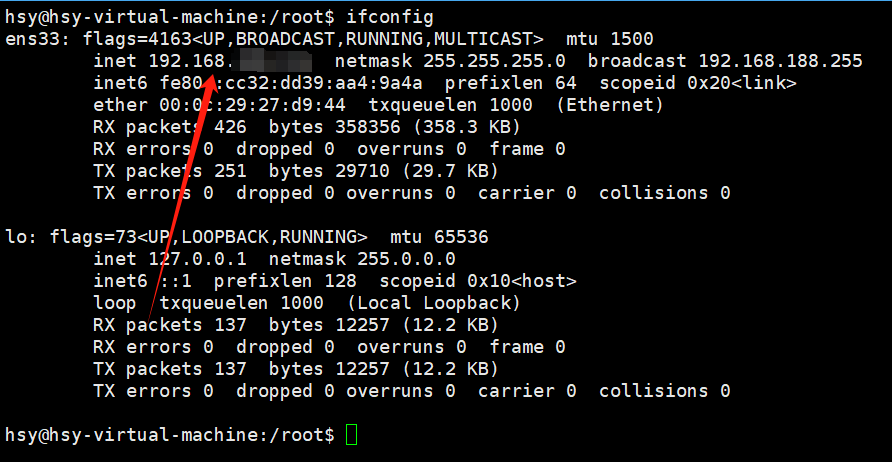
查看自己的端口地址(如果没有,就在core-site.xml里面添加):
格式为:
"hdfs://<虚拟机IP>:<port>"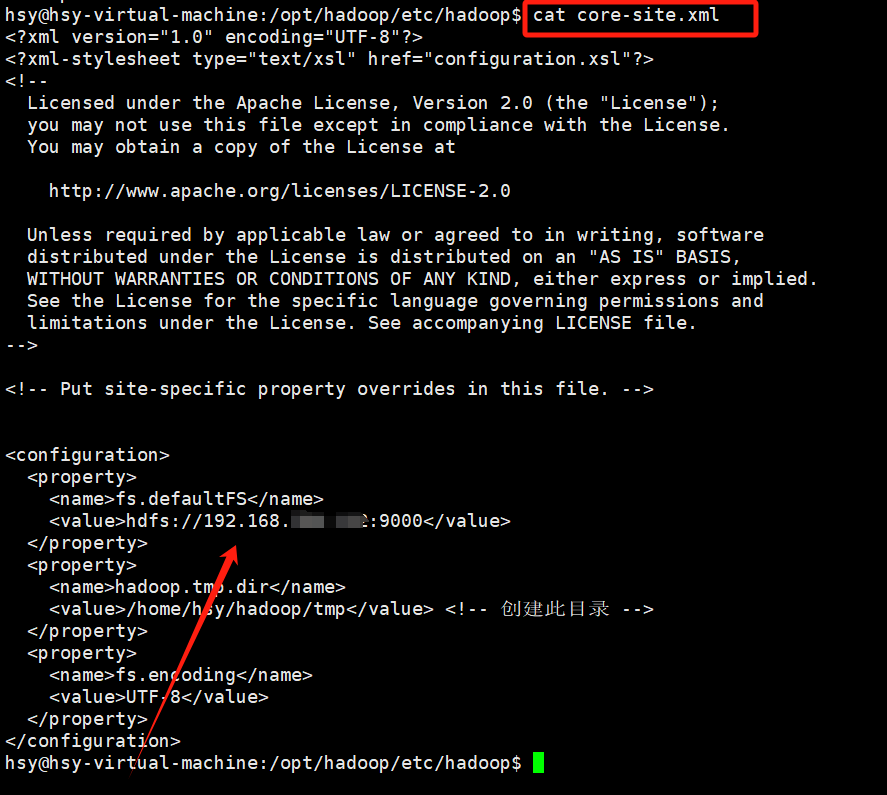
创建java 类(把ip地址和端口号替换成自己的,要指定读取的文件要提前创建好,并把路径添加进去):
package com.it;import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;import java.util.Arrays;
import java.util.Iterator;public class HDFSAndWordCount {public static void main(String[] args) {// 创建 Spark 配置SparkConf conf = new SparkConf();conf.setAppName("SimpleWordCount");conf.setMaster("local[*]"); // 使用本地模式,* 表示使用所有可用核心// 创建 Spark 上下文JavaSparkContext sc = new JavaSparkContext(conf);try {// 读取输入文件(自己的虚拟机ip+端口号)String inputFile = "hdfs://192.168.*.*:9000/opt/hadoop/input/word.txt";JavaRDD<String> lines = sc.textFile(inputFile);// 分词操作JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {@Overridepublic Iterator<String> call(String line) throws Exception {return Arrays.asList(line.split(" ")).iterator();}});// 映射为键值对JavaPairRDD<String, Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() {@Overridepublic Tuple2<String, Integer> call(String word) throws Exception {return new Tuple2<>(word, 1);}});// 统计词频JavaPairRDD<String, Integer> counts = pairs.reduceByKey(new Function2<Integer, Integer, Integer>() {@Overridepublic Integer call(Integer count1, Integer count2) throws Exception {return count1 + count2;}});// 打印结果counts.foreach(new VoidFunction<Tuple2<String, Integer>>() {@Overridepublic void call(Tuple2<String, Integer> tuple) throws Exception {System.out.println("单词: " + tuple._1() + " 次数: " + tuple._2());}});} catch (Exception e) {e.printStackTrace();} finally {// 关闭 Spark 上下文sc.close();}}
}
6. 测试连接:
首先启动hdfs
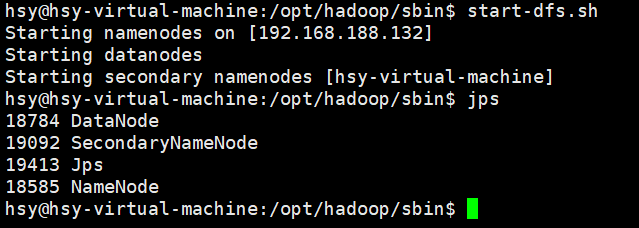
如果用的是Java9以上的版本,在运行环境中配置VM(这是一组与 Java 9 及更高版本的模块系统相关的 JVM 参数,主要用于解决反射访问时的模块访问限制问题):
--add-opens
java.base/java.util=ALL-UNNAMED
--add-opens
java.base/java.lang=ALL-UNNAMED
--add-opens
java.base/java.lang.reflect=ALL-UNNAMED
--add-opens
java.base/java.util.concurrent=ALL-UNNAMED
否则会出现如下报错信息:
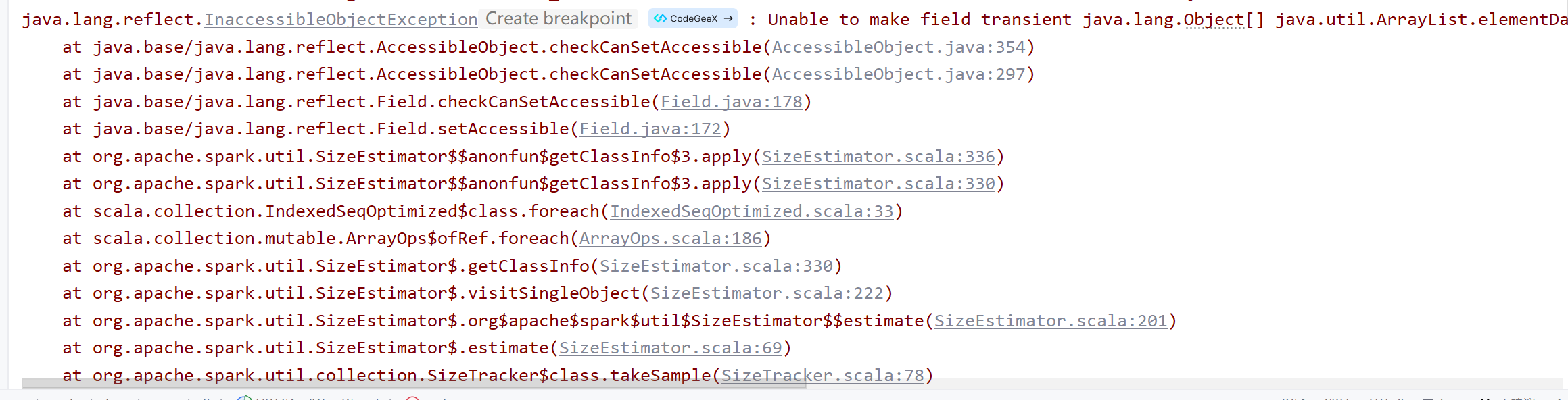
全部配置完成后,直接运行即可:
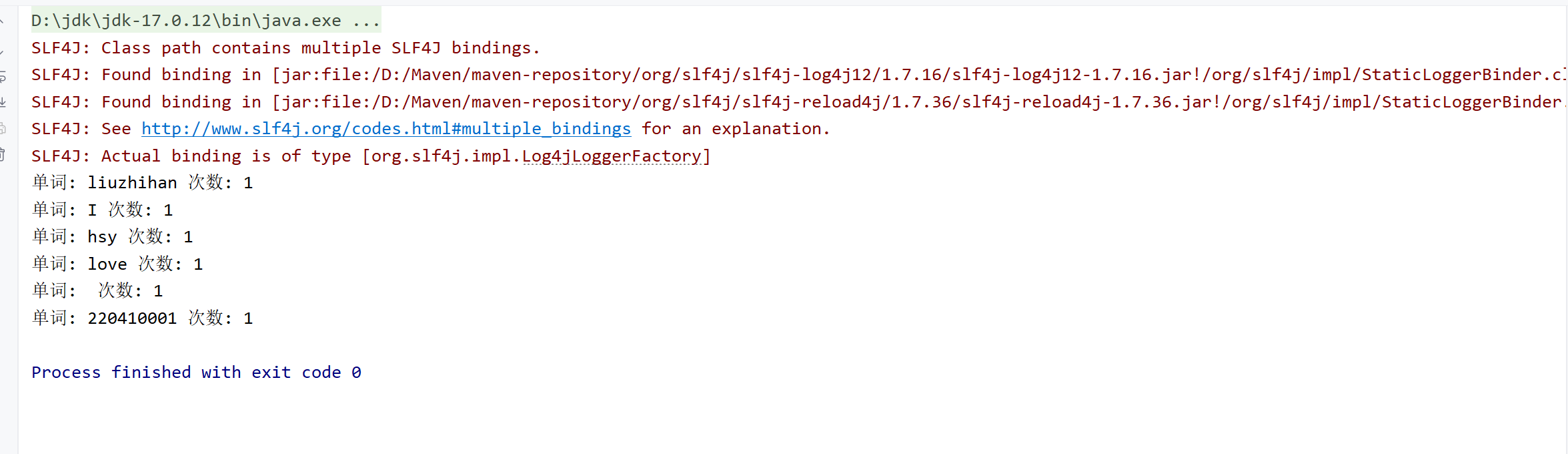
结果与原文件中的内容一致:

这样就大功告成了!