自己网站做seo免费的建站软件有哪些
一、基于DNN的风电功率预测
1.1、背景
在全球能源转型的浪潮中,风力发电因其清洁和可再生的特性而日益重要。然而,风力发电功率的波动性给电网的稳定运行和能源调度带来了挑战。准确预测风力发电机的功率输出,对于优化能源管理、提高电网可靠性以及促进风能的高效利用至关重要。传统的预测方法在应对风力发电固有的复杂性和非线性时存在局限,因此,利用深度学习等先进人工智能技术,从历史运行数据中学习并预测风功率,已成为一个重要的研究方向。
1.2、目标
旨在探索如何利用风机运行的历史数据,特别是风速、发电机转速和叶片角度等关键参数,构建一个深度学习模型来预测风力发电机的功率输出。通过对数据进行预处理、选择合适的模型架构、进行有效的训练和验证,并在独立的测试集上评估模型的预测性能,最终实现对风力发电机功率的准确预测,并可视化展示预测结果。
1.3、数据展示
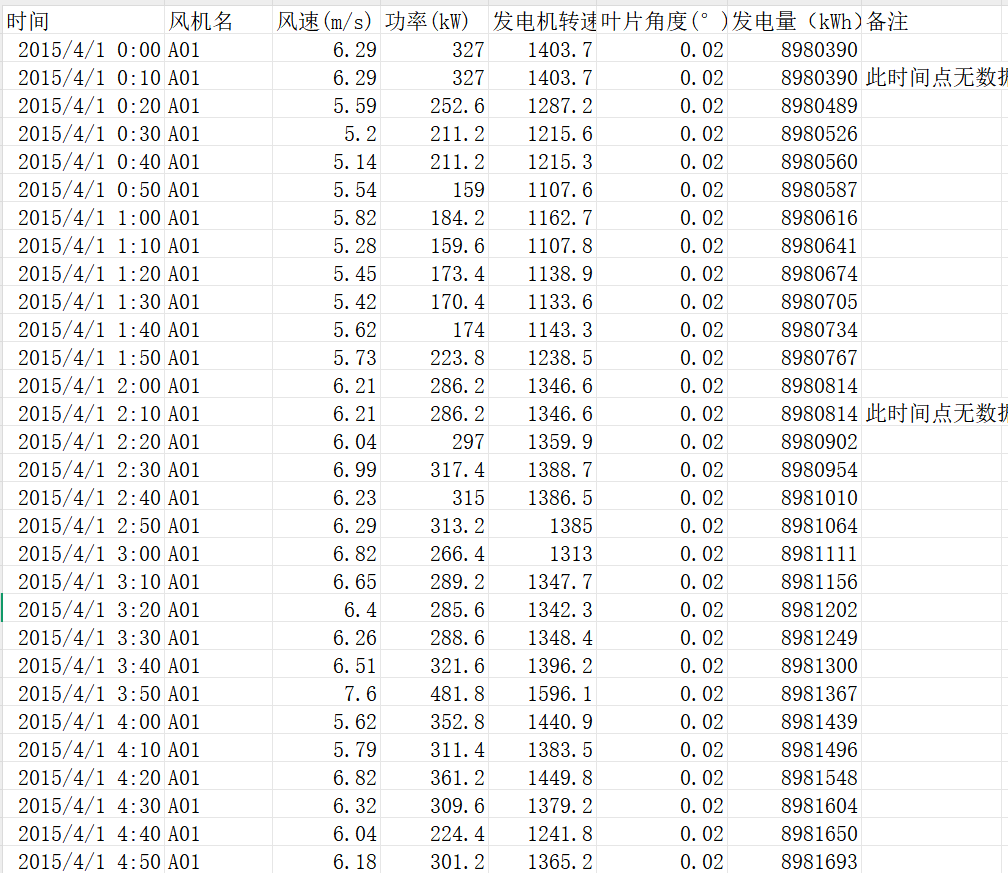
二、数据准备与预处理
class PowerData(Dataset):def __init__(self,path,input_len):super().__init__()# 从CSV文件读取数据self.data=pd.read_csv(path)# 定义输入序列的长度self.input_len=input_len# 将功率值限制在0到1500之间,处理异常值self.data['功率(kW)']=np.minimum(self.data['功率(kW)'],1500)# 初始化MinMaxScaler,用于将功率值归一化到[-1, 1]的范围self.scaler=MinMaxScaler(feature_range=(-1,1))# 对功率数据进行归一化处理并存储self.data['power_nomalized']=self.scaler.fit_transform(self.data['功率(kW)'].values.reshape(-1,1))# 返回数据集的长度,即可以生成多少个输入-输出对def __len__(self):return len(self.data)-self.input_len# 根据给定的索引返回一个样本def __getitem__(self, idx):# 定义输入序列的起始和结束索引start_idx=idxend_idx=idx+self.input_len# 获取输入特征序列feature=self.data['power_nomalized'].values[start_idx:end_idx]# 获取对应的目标值(下一个时间点的功率值)target=self.data['power_nomalized'].values[end_idx:end_idx+1]# 将特征和目标转换为PyTorch张量并返回return torch.tensor(feature,dtype=torch.float32),torch.tensor(target,dtype=torch.float32)# 创建PowerData数据集实例,指定数据文件路径和输入序列长度
power_dataset=PowerData('./A01.csv',input_len=6)Scaler之前:(tensor([327.0000, 327.0000, 252.6000, 211.2000, 211.2000, 159.0000]), tensor([184.2000]))
Scaler之后:(tensor([-0.5640, -0.5640, -0.6632, -0.7184, -0.7184, -0.7880]), tensor([-0.7544]))# 定义训练集、验证集和测试集的比例
train_ratio = 0.8
val_ratio = 0.1
test_ratio = 0.1
# 计算各个数据集的大小
train_size = int(train_ratio * len(power_dataset))
val_size = int(val_ratio * len(power_dataset))
test_size = len(power_dataset) - train_size - val_size # 确保测试集大小正确# 创建训练集、验证集和测试集的Subset
train_dataset=Subset(power_dataset,list(range(len(power_dataset)))[:train_size])
val_dataset=Subset(power_dataset,list(range(len(power_dataset)))[train_size:train_size+val_size])
test_dataset=Subset(power_dataset,list(range(len(power_dataset)))[train_size+val_size:])# 创建训练集、验证集和测试集的数据加载器
train_dataloader=DataLoader(train_dataset,batch_size=64,shuffle=True)
val_dataloader=DataLoader(val_dataset,batch_size=64,shuffle=False)
test_dataloader=DataLoader(test_dataset,batch_size=1,shuffle=False)三、模型构建
class DNN(nn.Module):def __init__(self,input_len=6,hidden_size=128,output_size=1):super().__init__()# 定义第一个线性层self.liner1=nn.Linear(input_len,hidden_size)# 定义第二个线性层(输出层)self.liner2=nn.Linear(hidden_size,output_size)# 定义模型的前向传播过程def forward(self,x):# 通过第一个线性层并应用ReLU激活函数x=F.relu(self.liner1(x))# 通过第二个线性层得到最终的预测值x=self.liner2(x)return x# 创建DNN模型实例
model=DNN()四、模型训练与验证
# 定义损失函数为均方误差
cri=nn.MSELoss()
# 定义优化器为Adam,并设置学习率和权重衰减
optim=torch.optim.Adam(model.parameters(),lr=0.001,weight_decay=1e-5)# 开始训练模型
for epoch in range(1,21):# 设置模型为训练模式model.train()# 初始化每个epoch的总损失total_loss=0# 遍历训练数据加载器for batch_feature,batch_target in train_dataloader:# 使用模型进行预测y_pred=model(batch_feature)# 计算损失loss=cri(y_pred.squeeze(1),batch_target.view(-1))# 清空之前的梯度optim.zero_grad()# 反向传播计算梯度loss.backward()# 更新模型参数optim.step()# 累加批次损失total_loss+=loss# 计算平均训练损失train_loss=total_loss/len(train_dataloader)# 设置模型为评估模式model.eval()# 初始化验证集的总损失total_loss=0# 在不计算梯度的上下文中进行验证with torch.no_grad():# 遍历验证数据加载器for batch_feature,batch_target in val_dataloader:# 使用模型进行预测y_pred = model(batch_feature)# 计算损失loss = cri(y_pred.squeeze(1), batch_target.view(-1))# 累加批次损失total_loss += loss# 计算平均验证损失avg_loss = total_loss / len(val_dataloader)# 计算平均验证损失val_loss=total_loss/len(val_dataloader)# 打印每个epoch的训练损失和验证损失print(train_loss.item(),val_loss.item())五、模型评估与结果可视化
# 设置模型为评估模式
model.eval()
# 初始化预测值列表和真实值列表
pred_list=[]
target_list=[]
# 在不计算梯度的上下文中进行测试
with torch.no_grad():# 遍历测试数据加载器for batch_feature, batch_target in test_dataloader:# 使用模型进行预测y_pred = model(batch_feature)# 将预测值和真实值添加到列表中pred_list.append(y_pred.squeeze(1).item())target_list.append(batch_target.item())# 将预测值和真实值反归一化到原始范围
pred_list=power_dataset.scaler.inverse_transform(np.array(pred_list).reshape(-1,1))
target_list=power_dataset.scaler.inverse_transform(np.array(target_list).reshape(-1,1))# 绘制最后200个真实值和预测值的对比图
plt.plot(target_list[-200:], label="True values")
plt.plot(pred_list[-200:], label="Predict values")
# 设置x轴标签
plt.xlabel("Time")
# 设置y轴标签
plt.ylabel("Power")
# 显示图例
plt.legend()
# 显示图像
plt.show()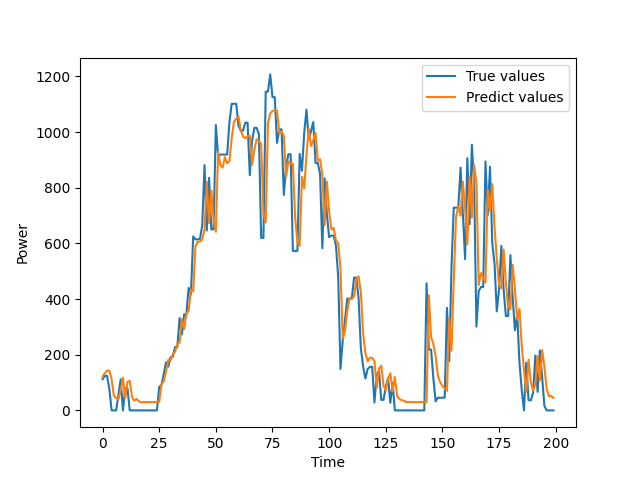
六、完整代码
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import Dataset,DataLoader,Subset
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
import torch.nn.functional as F# 定义用于加载电力数据的Dataset类
class PowerData(Dataset):def __init__(self,path,input_len):super().__init__()# 从CSV文件读取数据self.data=pd.read_csv(path)# 定义输入序列的长度self.input_len=input_len# 将功率值限制在0到1500之间,处理异常值self.data['功率(kW)']=np.minimum(self.data['功率(kW)'],1500)# 初始化MinMaxScaler,用于将功率值归一化到[-1, 1]的范围self.scaler=MinMaxScaler(feature_range=(-1,1))# 对功率数据进行归一化处理并存储self.data['power_nomalized']=self.scaler.fit_transform(self.data['功率(kW)'].values.reshape(-1,1))# 返回数据集的长度,即可以生成多少个输入-输出对def __len__(self):return len(self.data)-self.input_len# 根据给定的索引返回一个样本def __getitem__(self, idx):# 定义输入序列的起始和结束索引start_idx=idxend_idx=idx+self.input_len# 获取输入特征序列feature=self.data['power_nomalized'].values[start_idx:end_idx]# 获取对应的目标值(下一个时间点的功率值)target=self.data['power_nomalized'].values[end_idx:end_idx+1]# 将特征和目标转换为PyTorch张量并返回return torch.tensor(feature,dtype=torch.float32),torch.tensor(target,dtype=torch.float32)# 创建PowerData数据集实例,指定数据文件路径和输入序列长度
power_dataset=PowerData('./A01.csv',input_len=6)# 定义训练集、验证集和测试集的比例
train_ratio = 0.8
val_ratio = 0.1
test_ratio = 0.1
# 计算各个数据集的大小
train_size = int(train_ratio * len(power_dataset))
val_size = int(val_ratio * len(power_dataset))
test_size = len(power_dataset) - train_size - val_size # 确保测试集大小正确# 创建训练集、验证集和测试集的Subset
train_dataset=Subset(power_dataset,list(range(len(power_dataset)))[:train_size])
val_dataset=Subset(power_dataset,list(range(len(power_dataset)))[train_size:train_size+val_size])
test_dataset=Subset(power_dataset,list(range(len(power_dataset)))[train_size+val_size:])# 创建训练集、验证集和测试集的数据加载器
train_dataloader=DataLoader(train_dataset,batch_size=64,shuffle=True)
val_dataloader=DataLoader(val_dataset,batch_size=64,shuffle=False)
test_dataloader=DataLoader(test_dataset,batch_size=1,shuffle=False)# 定义一个简单的深度神经网络模型
class DNN(nn.Module):def __init__(self,input_len=6,hidden_size=128,output_size=1):super().__init__()# 定义第一个线性层self.liner1=nn.Linear(input_len,hidden_size)# 定义第二个线性层(输出层)self.liner2=nn.Linear(hidden_size,output_size)# 定义模型的前向传播过程def forward(self,x):# 通过第一个线性层并应用ReLU激活函数x=F.relu(self.liner1(x))# 通过第二个线性层得到最终的预测值x=self.liner2(x)return x# 创建DNN模型实例
model=DNN()# 定义损失函数为均方误差
cri=nn.MSELoss()
# 定义优化器为Adam,并设置学习率和权重衰减
optim=torch.optim.Adam(model.parameters(),lr=0.001,weight_decay=1e-5)# 开始训练模型
for epoch in range(1,21):# 设置模型为训练模式model.train()# 初始化每个epoch的总损失total_loss=0# 遍历训练数据加载器for batch_feature,batch_target in train_dataloader:# 使用模型进行预测y_pred=model(batch_feature)# 计算损失loss=cri(y_pred.squeeze(1),batch_target.view(-1))# 清空之前的梯度optim.zero_grad()# 反向传播计算梯度loss.backward()# 更新模型参数optim.step()# 累加批次损失total_loss+=loss# 计算平均训练损失train_loss=total_loss/len(train_dataloader)# 设置模型为评估模式model.eval()# 初始化验证集的总损失total_loss=0# 在不计算梯度的上下文中进行验证with torch.no_grad():# 遍历验证数据加载器for batch_feature,batch_target in val_dataloader:# 使用模型进行预测y_pred = model(batch_feature)# 计算损失loss = cri(y_pred.squeeze(1), batch_target.view(-1))# 累加批次损失total_loss += loss# 计算平均验证损失avg_loss = total_loss / len(val_dataloader)# 计算平均验证损失val_loss=total_loss/len(val_dataloader)# 打印每个epoch的训练损失和验证损失print(train_loss.item(),val_loss.item())# 设置模型为评估模式
model.eval()
# 初始化预测值列表和真实值列表
pred_list=[]
target_list=[]
# 在不计算梯度的上下文中进行测试
with torch.no_grad():# 遍历测试数据加载器for batch_feature, batch_target in test_dataloader:# 使用模型进行预测y_pred = model(batch_feature)# 将预测值和真实值添加到列表中pred_list.append(y_pred.squeeze(1).item())target_list.append(batch_target.item())# 将预测值和真实值反归一化到原始范围
pred_list=power_dataset.scaler.inverse_transform(np.array(pred_list).reshape(-1,1))
target_list=power_dataset.scaler.inverse_transform(np.array(target_list).reshape(-1,1))# 绘制最后200个真实值和预测值的对比图
plt.plot(target_list[-200:], label="True values")
plt.plot(pred_list[-200:], label="Predict values")
# 设置x轴标签
plt.xlabel("Time")
# 设置y轴标签
plt.ylabel("Power")
# 显示图例
plt.legend()
# 显示图像
plt.show()