一建建设网站首页手机怎样建设网站
本文是在通过各种渠道(视频(李沐)、网站)学习多模态的记录
1. 模型结构
图像输入和文本输入,因此有两支输入(视觉编码器和文本编码器)来抽取图像和文本特征。在多模态学习中,视觉特征远远大于文本特征,因此使用更大更强的视觉编码器是好的,如VSE、CLIP、ViLBERT。同时模态间的融合也很重要,因此像CLIP这种简单的点乘融合模块无法执行复杂任务,但是在图像文本匹配做的很好,ViLT和ViLBERT具有更大的模态融合模块。
2. 从词到数:Tokenizer与Embedding
单词分词法:根据空格或标点分词,如['Today', 'is', 'Sunday'];
单字分词法:每个字符是一个最小单元,如['T', 'o', 'd', ..., 'a', 'y'];
子词分词法:最常用,介于前两者之间,把单词分成子词,如['To', 'day', 'is', 'S', 'un', 'day']。
GPT族:Byte-Pair Encoding (BPE),选择频数最高的相邻子词合并
BERT族:Word-Piece,选择能够提升语言模型概率最大的相邻子词加入词表
3. 文本编码器流程
Tokenization和Embeddings的过程:
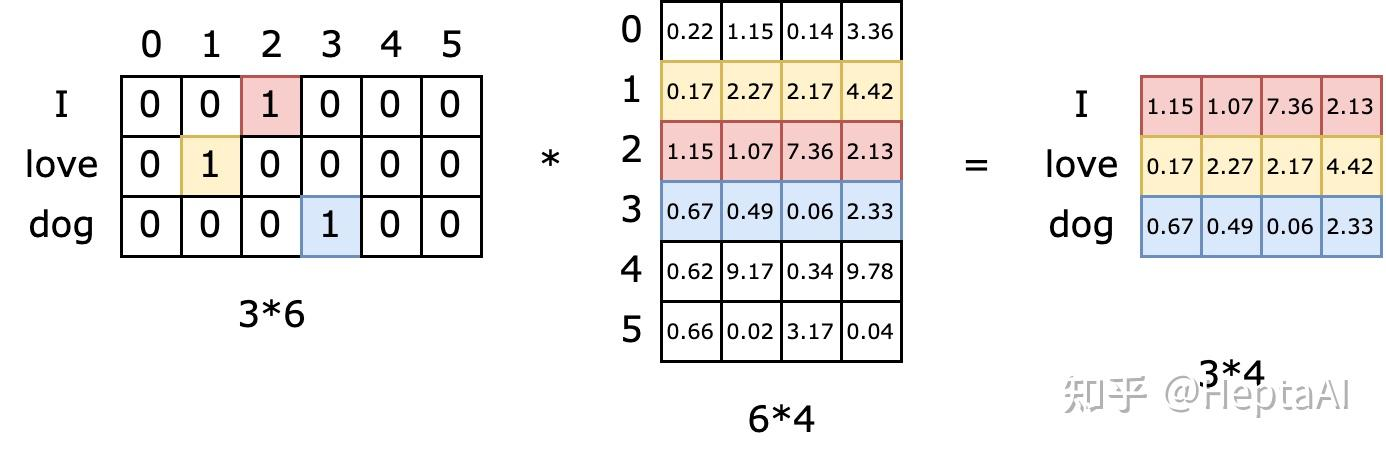
- one-hot 编码:
[1, 0, 0]→ Embedding 编码:[0.25, -0.1, 0.7, ..., 0.02]
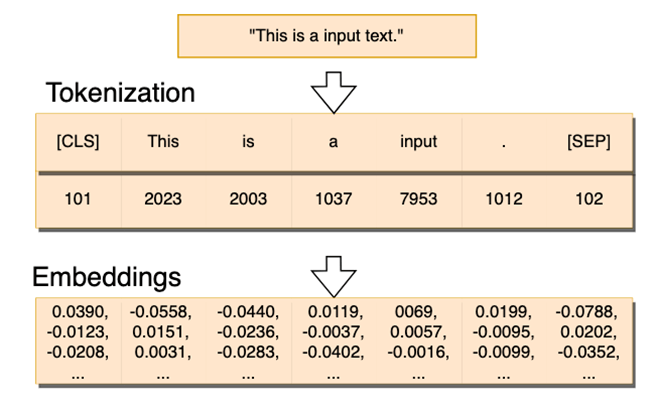
embedding的具体过程:查找表
总结为:tokenizer将文本序列分词并转换为数字,这个时候的token长度太大、数字太大、不利于收敛,因此使用embedding将其降维,转换为-1到1的元素的向量。
4. 位置编码position embedding
嵌入后的向量不具有位置信息,因此需要再进行position embedding,只需要把位置向量与词向量相加即可,相加能够满足距离与词语的相互作用。

实现的功能:
每个token的向量唯一(每个sin函数的频率足够小);
位置向量的值是有界的,且位于连续空间中;
不同的位置向量是可以通过线性转换得到的。
实现的效果,位置编码:
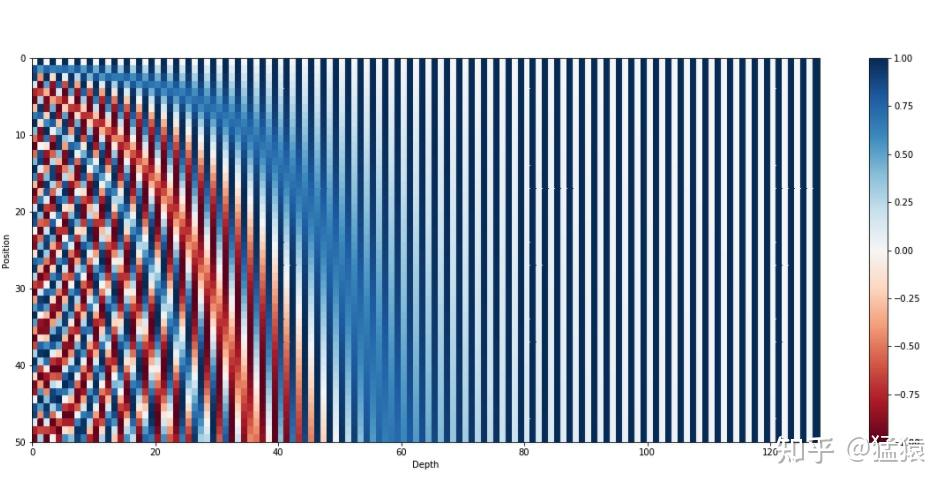
5. transformers剩余步骤
a. Attention
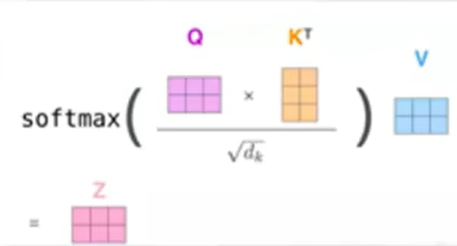
归一化是为了训练时梯度能够稳定
b. Add and Norm:残差+层归一化(加速收敛、提高泛化能力)
c. Feed Forward:全连接+非线性
d.Add and Norm
6. BERT和GPT
BERT是用了transformer的encoder侧的网络,GPT是用了decoder侧的网络;
BERT更倾向于理解,GPT更倾向于生成;
BERT是双向编码(上下文理解),GPT是单向编码(理解上文,预测下文);
BERT有三个Embedding,GPT有两个。
-
Token Embeddings, (1, n, d) ,词的向量表示
-
Segment Embeddings, (1, n, d),辅助BERT区别句子对中的两个句子的向量表示
-
Position Embeddings ,(1, n, d) ,让BERT学习到输入的顺序属性,(如 ”你爱我“ 和 ”我爱你“)
三个embedding结果相加。
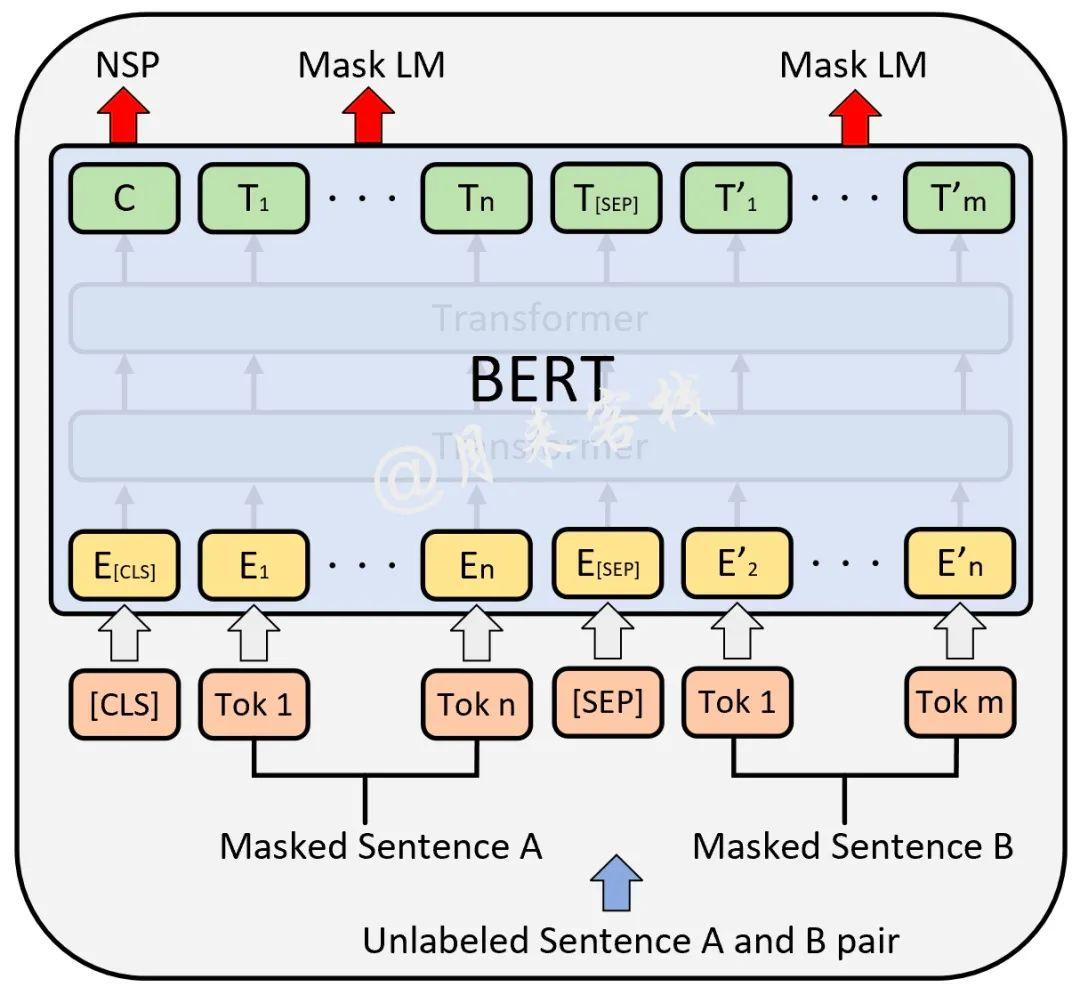
为了训练BERT网络,BERT有两个任务:MLM和NSP。MLM即遮挡语言模型,15%的token用于遮挡处理,其中80%MASK遮挡,10%其他token替代,10%不变。BERT的输出结果取对应掩盖位置上的向量进行真实值预测。NSP即下句预测,用于分析两句话之间的关系。两个任务可以同时训练,如下图所示,图片来自https://zhuanlan.zhihu.com/p/426184475。
7. ViT:视觉transfomer
打通了视觉和文本处理模型的桥梁
a. Patch Embedding
224x224x3 ->切块-> 196x[16x16x3] ->展平-> 196x768 ->全连接线性变换-> 196x768 ->分类字符cls-> 197x768
b. Position Embedding
二维位置(x,y) -> 197x(384+384) -> 与Patch Embedding结果相加
8. CLIP(Contrastive Language-Image Pre-training)
对比学习,多模态的奠基
文本和图片匹配。文本编码器为GPT2,图像编码器为ViT,提取的特征向量进行点积使匹配的数据结果最大化,不匹配的结果最小化,即下图矩阵对角线最大化,其他最小化。

推理预测:图片进入图像编码器,得到特征与文本特征匹配,相似度最大的即为目标文本。
CLIP 的损失: ITC loss,本质上是分类任务,首先输入图像,得到与各个可能文本的相似度,输入softmax得到概率分布,与真实分布进行交叉熵
9. VLM(Vision-Language Model)
模型训练分为:预训练(图像文本匹配)和微调(提升特定任务能力)。
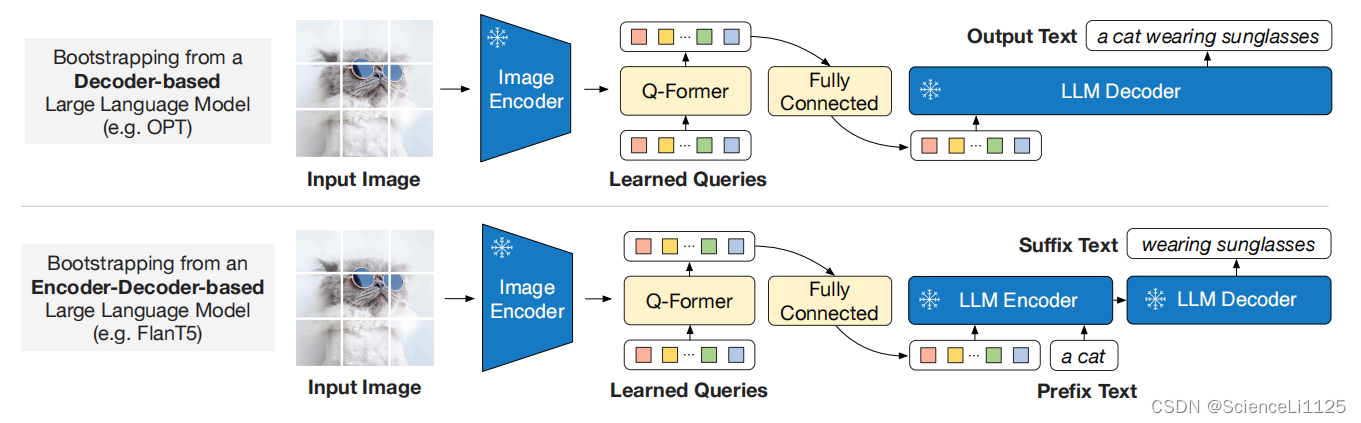
基于大语言模型,设计视觉编码器使得图片映射到大语言模型的对应特征空间。这里可以与Encoder-Decoder架构类比,比如翻译任务,需要翻译的内容变成了图像,生成一段文本描述。
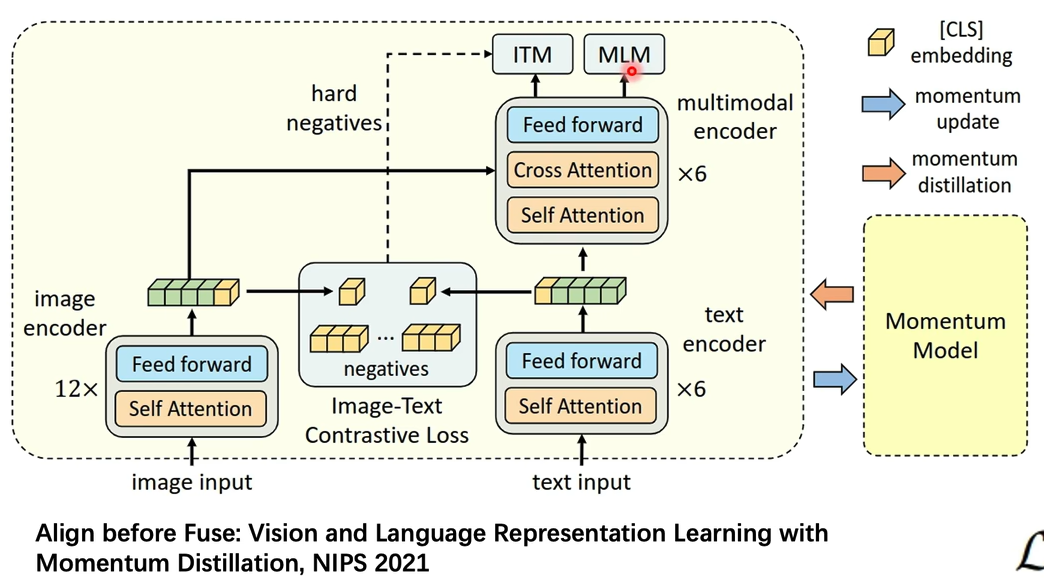
10. ALBEF
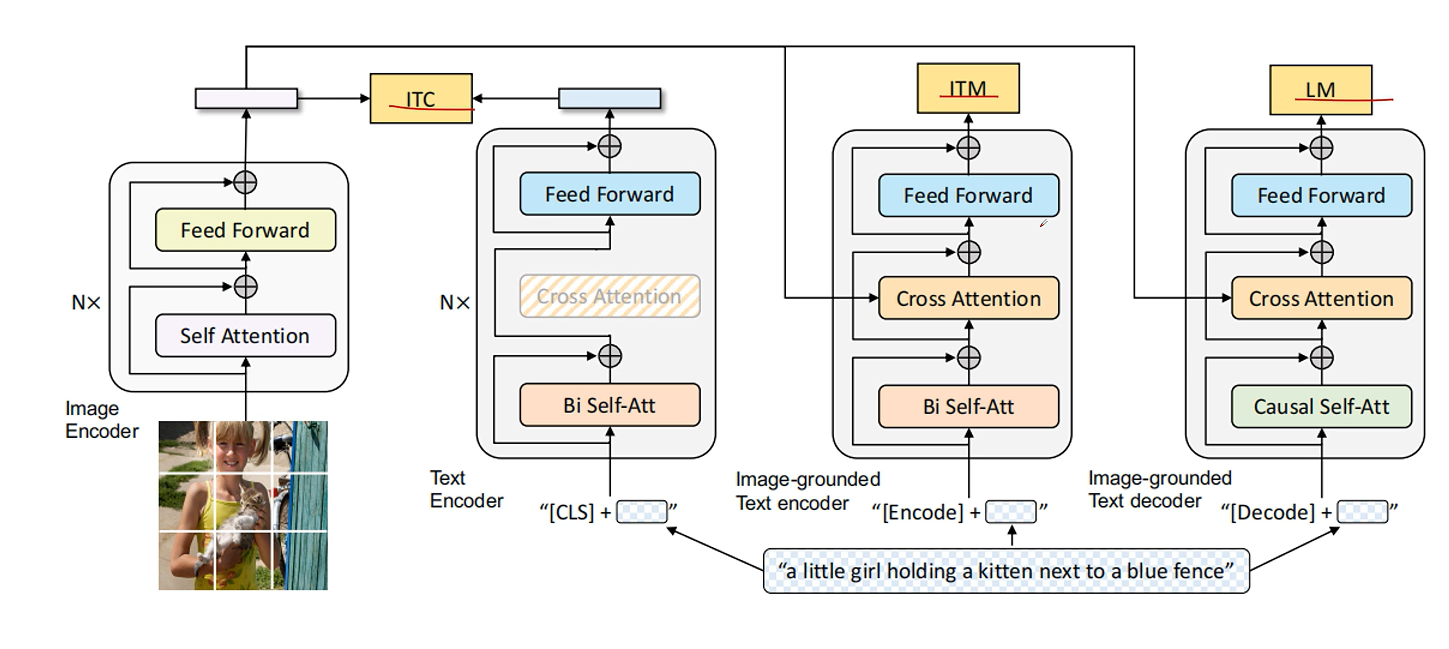
10. BLIP
提出的动机:在此之前的多模态模型无法同时完成多模态的理解和生成:根据图像检索文本、根据图像回答问题。前者基于Encoder-Only模型,后者基于Encoder-Decoder模型。
a. 模型结构
(参考链接:BLIP:统一视觉语言理解与生成的预训练模型_blip预训练模型-CSDN博客)
基于编码器 - 解码器的多模态混合结构 (Multimodal mixture of Encoder-Decoder, MED)
单模态编码器 lmage Encoder:基于 transformer 的 ViT 的架构,将输入图像分割为多个的 patch 并将它们编码为一系列 Image Embedding,并使用 [CLS] token 来表示全局的图像特征。lmage Encoder 用来提取图像特征做对比学习,相当于 CLIP 中的 Image Encoder;
单模态编码器 Text Encoder:基于 BERT 的架构,将 [CLS] token 加到输入文本的开头以总结句子。Text Encoder 用来提取文本特征做对比学习,相当于 CLIP 中的 Text Encoder;
以图像为基础的编码器 Image-grounded text encoder:在 Text Encoder 的 self-attention 层和前馈网络之间添加一个 交叉注意 (cross-attention, CA) 层用来注入视觉信息,还将 [Encode] token 加到输入文本的开头以标识特定任务。Image-grounded text encoder 用来提取文本特征并将其和图像特征对齐,相当于 CLIP 中更精细化的 Text - Image 对齐;
以图像为基础的解码器 Image-grounded text decoder:将 Image-grounded text encoder 的 self-attention 层换成 causal self-attention 层,还将 [Decode] token 和 [EOS] token 加到输入文本的开头和结尾以标识序列的开始和结束。Image-grounded text decoder 用来生成符合图像和文本特征的文本描述,这是 CLIP 中所没有的;
b. 三个任务
ITC,图文比对损失,通过对比学习对其图像和文本特征空间,最大化正样本图像文本对相似度,最小化负样本图像文本对相似度。
ITM,图文匹配损失,通过学习图像和文本对的联合表征实现视觉和语言的细粒度对齐。
两者的区别在于,ITM的图像和文本特征是通过交叉注意力机制进行交互理解的,能直接反应图像和文本之间的关系。ITC则是将两者映射到对齐空间中进行距离比较。
LM,语言建模损失,实现基于图像生成文本的任务,使用交叉熵损失函数,最大化文本概率。
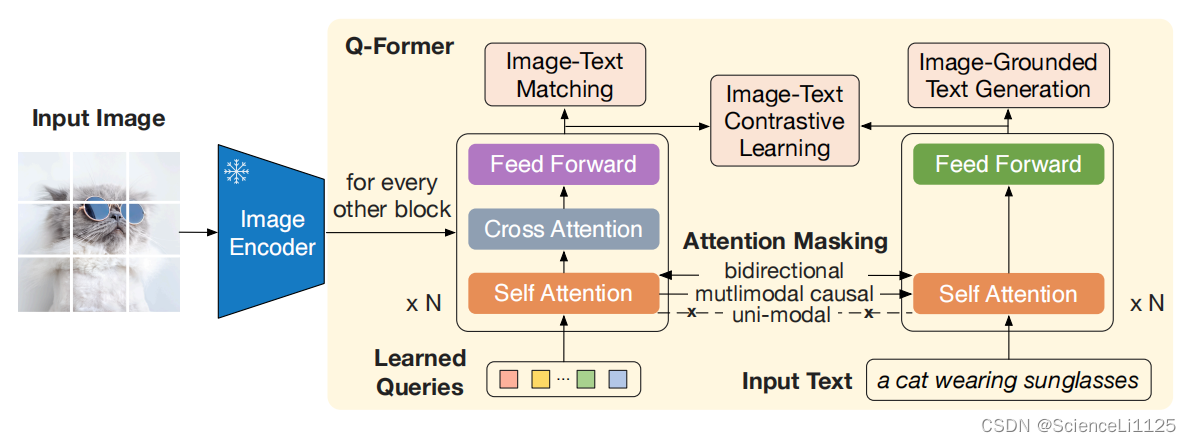
11. BLIP-2
参考:BLIP-2:冻结现有视觉模型和大语言模型的预训练模型_blip2模型-CSDN博客
a. 动机
- 多模态从头训练成本高,BLIP2希望利用预训练的视觉模型和大语言模型
- 单模态预训练模型直接加入多模态模型中联合训练可能产生灾难性遗忘问题,BLIP2选择冻结单模态模型参数,为了让两个冻结的单模态模型对其,引入了Q-Former
LLM 本质上是个语言模型,无法直接接受其他模态的信息,所以需要把各个模态的信息统一到 LLM 能理解的特征空间。
b. 预训练步骤
Image Encoder 接收图像作为输入,输出图像的视觉特征;
Q-Former 接收文本和 Image Encoder 输出的图像视觉特征,结合查询向量进行融合,学习与文本相近的视觉特征,输出 LLM 能够理解的视觉表示;
最后 LLM 模型接收 Q-Former 输出的视觉标识,生成对应文本。
12. 对比学习损失函数
infoNCE loss:NCE代表噪声对比估计,公式如下:
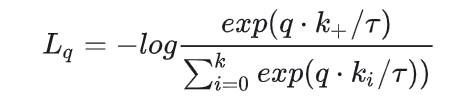
本质上与多分类交叉熵很像,多分类交叉熵的表达式是:
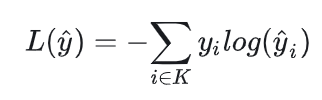
softmax公式是:
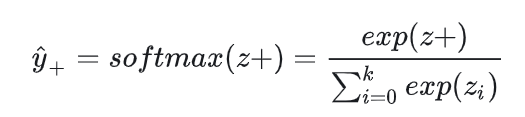
在有监督学习下,groundtruth是一个onehot向量,预测值zi经过softmax后,得到预测概率,可以写成下面公式:
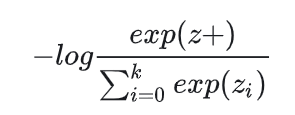
唯一的区别是,在cross entropy loss里,k指代的是数据集里类别的数量,而在对比学习InfoNCE loss里,这个k指的是负样本的数量。上式分母中的sum是在1个正样本和k个负样本上做的,从0到k,所以共k+1个样本,也就是字典里所有的key。