哪些企业需要网站建设的邢台短视频优化
《TensorRT全流程部署指南》专栏文章目录:
- 《TensorRT全流程部署指南》专栏主页
- cap1:TensorRT介绍及CUDA环境安装
- cap2:1000分类的ResNet的TensorRT部署指南(python版)
- cap3:自定义数据集训练ResNet的TensorRT部署指南(python版)
- cap4:YoloV5目标检测任务的TensorRT部署指南(python版)
- cap5:YoloV5分割任务的TensorRT部署指南(python版)
- 从训练到部署:基于YOLOv5和TensorRT的人脸口罩检测系统全流程实战指南
- 更多专栏文章…
文章目录
- 0、流程介绍
- 1、数据标注
- 1.1 标注软件推荐:X-AnyLabeling
- 1.2 导出YOLO格式
- 2、训练口罩检测模型
- 2.1 配置数据集
- 2.2 开启训练
- 2.3 模型验证
- 2.4 效果检测
- 3、导出onnx模型
- 3.1 导出
- 3.2 可视化模型结构
- 3.3 验证模型格式是否正确
- 3.4 图片测试
- 4、环境搭建
- 4.1 TensorRT的安装
- 4.2 安装pycuda
- 5、转换TensorRT引擎
- 5.1 使用trtexec工具完成序列化
- 5.2 使用python的API进行转换
- 6、TensorRT部署推理
- 6.1 TensorRT推理流程介绍
- 7、完整代码
在之前的文章中,我们已经探讨了如何使用TensorRT加速YOLOv5模型的推理过程。如果你已经掌握了这些基础知识,那么现在是时候更进一步了!本文将带你深入实战,从零开始,一步步部署一个属于你自己的目标检测项目。
无论你是刚入门深度学习,还是已经有一定经验的开发者,本文都将为你提供清晰的指引。我们将覆盖从数据标注与整理、模型训练、模型导出,到TensorRT序列化和部署推理的完整流程。通过这个项目,你将不仅学会如何搭建一个高效的目标检测系统,还能掌握如何在实际应用中优化模型性能。
你将学到:
- 数据标注与整理:如何为你的目标检测任务准备高质量的数据集。
- 模型训练:使用YOLOv5进行模型训练的技巧与最佳实践。
- 模型导出与优化:如何将训练好的模型导出为TensorRT支持的格式,并进行序列化。
- TensorRT部署推理:在实际系统中部署模型,实现高效的推理。
无论你是想为自己的项目增添目标检测功能,还是希望深入理解模型部署的各个环节,本文都将为你提供实用的解决方案。让我们一起动手,打造一个高效、实时的目标检测系统!
为了方便,下面的介绍中没有给出完整的代码,只是给出一个框架。完整的项目可以在这里获取:ishyj/python-tensorrt-yolov5-mask ,包括从yolov5训练(含数据集)到onnx验证推理,再到TensorRT推理的所有代码。
0、流程介绍
在开始之前,需要对各个阶段有一个大概的了解
1. YOLOv5 训练
YOLOv5 是 YOLO(You Only Look Once)系列的最新版本之一,是一种单阶段目标检测算法,以其高速度和较高的检测精度著称。训练阶段的目标是通过标注数据学习目标的特征,生成模型权重文件。
训练阶段是模型开发的核心环节,通过训练可以得到一个能够识别特定目标的模型。训练完成后,模型会保存为 .pt 文件(PyTorch 格式),这是后续所有流程的基础。
2. 导出 ONNX
ONNX(Open Neural Network Exchange)是一种开放的模型格式,支持跨框架(如 PyTorch、TensorFlow)和跨平台(如 CPU、GPU)部署。将 YOLOv5 模型导出为 ONNX 格式,可以方便后续在 TensorRT 等推理引擎中使用。
ONNX 格式的模型具有通用性,能够被多种推理框架加载和优化。通过导出 ONNX 模型,可以为后续的 TensorRT 优化和推理提供标准化的输入。
3. TensorRT 序列化
TensorRT 是 NVIDIA 推出的高性能深度学习推理库,能够优化模型并在 NVIDIA GPU 上实现低延迟、高吞吐量的推理。将 ONNX 模型序列化为 TensorRT 引擎(.engine),可以充分利用 GPU 的硬件加速能力。
TensorRT 通过层融合、精度校准(FP16/INT8)、内存优化等技术,显著提升模型的推理速度。序列化后的 TensorRT 引擎是专门针对目标硬件优化的,能够实现高效的推理。
流程:
- 安装 TensorRT:
- 确保环境中已安装 TensorRT、CUDA 和 cuDNN。
- 转换 ONNX 为 TensorRT 引擎:
- 使用 TensorRT 提供的
trtexec工具或 Python API 将 ONNX 模型转换为 TensorRT 引擎。 - 在转换过程中,可以指定精度(FP32、FP16 或 INT8)和批处理大小。
- 使用 TensorRT 提供的
- 优化引擎:
- 根据实际需求调整引擎参数,如动态输入尺寸、最大工作空间大小等。
4. TensorRT 推理
TensorRT 推理阶段是将优化后的 TensorRT 引擎部署到实际应用中的过程。通过 TensorRT 推理,可以在 NVIDIA GPU 上实现高效的实时目标检测。
TensorRT 推理引擎能够最大化 GPU 的利用率,提供低延迟、高吞吐量的推理服务。在实际应用中,TensorRT 推理可以满足实时性要求较高的场景(如自动驾驶、视频监控等)。
流程:
- 加载 TensorRT 引擎:
- 使用 TensorRT 的 API 加载序列化后的
.engine文件。
- 使用 TensorRT 的 API 加载序列化后的
- 预处理输入:
- 将输入图像调整为模型要求的尺寸(如 640x640),并进行归一化等操作。
- 执行推理:
- 调用 TensorRT 的推理接口,将预处理后的图像输入模型,获取输出结果。
- 后处理:
- 解析模型的输出(通常是边界框、类别和置信度),应用非极大值抑制(NMS)等操作,生成最终的检测结果。
- 可视化结果:
- 将检测结果绘制在图像上,并显示或保存。
总结
- 训练:通过标注数据训练 YOLOv5 模型,生成
.pt权重文件。 - 导出 ONNX:将 PyTorch 模型转换为通用的 ONNX 格式,便于跨平台部署。
- TensorRT 序列化:将 ONNX 模型优化并序列化为 TensorRT 引擎,充分利用 GPU 硬件加速。
- TensorRT 推理:加载优化后的 TensorRT 引擎,实现高效的目标检测推理。
该方案从模型训练到部署推理,兼顾了精度和性能,适用于需要高效实时目标检测的场景。
1、数据标注
数据标注其实不需要太多的介绍,就是自己收集图片,然后进行标注,再转成yolo支持的格式。
1.1 标注软件推荐:X-AnyLabeling
数据标注软件有很多,这里介绍我认为好用的工具:X-AnyLabeling。这款工具是AI附魔版的labelme,除了常规的标注功能外,支持一键导出yolo格式,支持AI自动标注。
比如下方的AI功能,选择yolov5n模型,点击运行后就会自动对当前图像进行检测并标注,十分快捷。
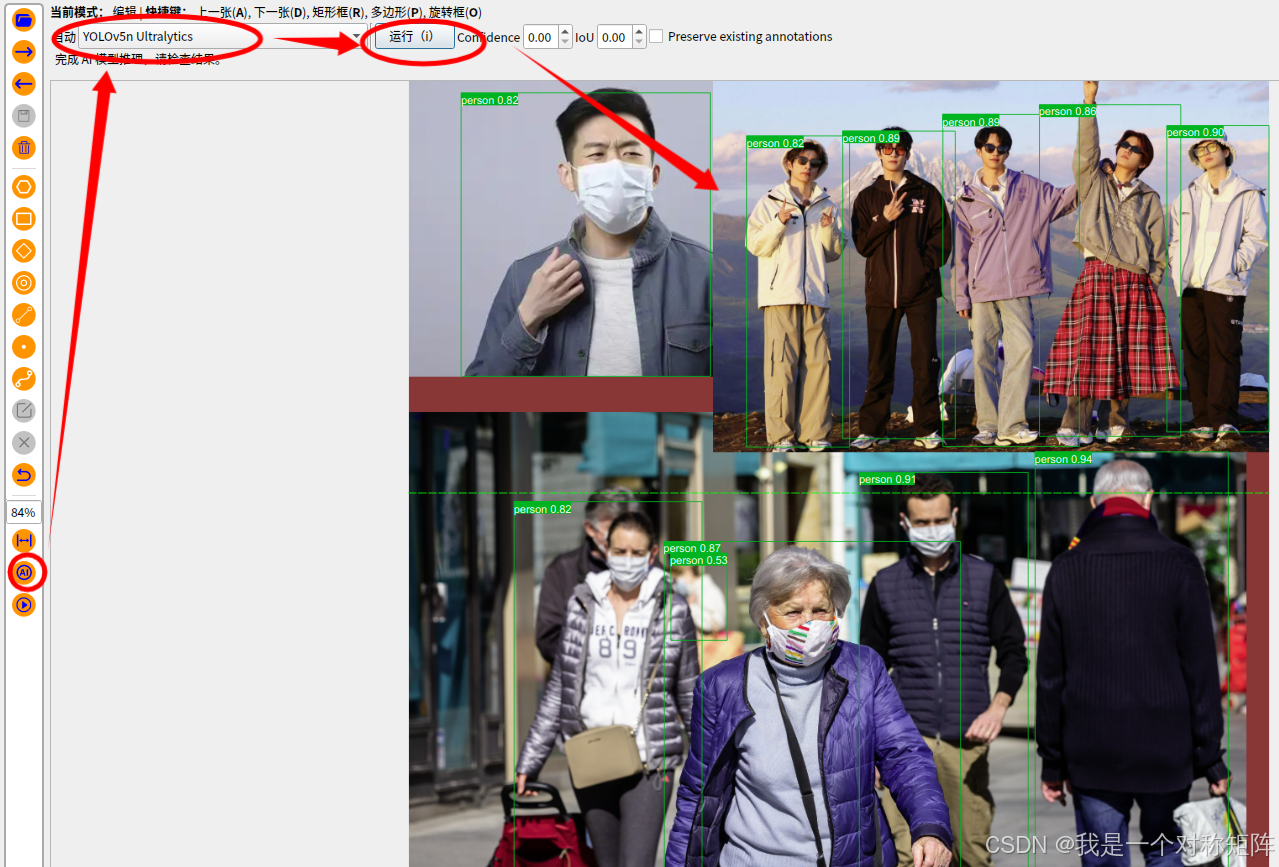
目前支持的模型多达上百个,包括了常见的分类、检测、分割等模型,比如主流的YOLO检测、SAM分割等等,具体见:X-AnyLabeling Model Zoo。
除此之外,你还可以自己先标注部分数据训练一个yolo模型,然后添加到X-AnyLabeling中,这样就可以使用自己的模型来标注剩余的数据,实现定制的自动标注。
1.2 导出YOLO格式
使用X-AnyLabeling标注完毕后,依此点击:导出-->Export YOLO-Hbb Annotations后,就导出了yolo格式的数据集。结果如下,每一张图片对应一个txt标注文件。
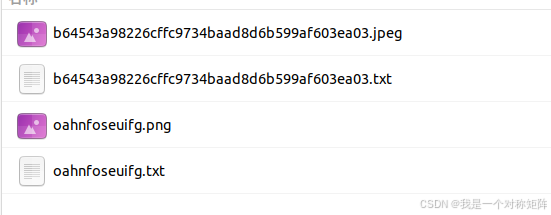
标注文件的格式如下图所示,每一行代表一个标注框。每一行按照class_id cx cy w h格式标注,其中cx cy w h都是归一化到0~1后的浮点值:
- class_id:类别号,这表示这个图中有14的bbox,全部为类别0
- cx:即center_x,标注框中心点的x坐标
- cy:即center_y,标注框中心店的y坐标
- w和h:标注框的宽和高

导出后按照下方的结构存放即可。
MaskWearing/
├── images
│ ├── test
│ │ └── 1.jpg
│ ├── train
│ │ ├── 4.jpg
│ │ ├── 5.jpg
│ │ └── 6.jpg
│ └── val
│ └── 7.jpg
└── labels├── test│ └── 1.txt├── train│ ├── 4.txt│ ├── 5.txt│ └── 6.txt└── val└── 7.txt
2、训练口罩检测模型
我们使用YOLOv5训练口罩检测模型,使用官方的项目:ultralytics/yolov5。下载项目到本地后,按照文档配置环境。
2.1 配置数据集
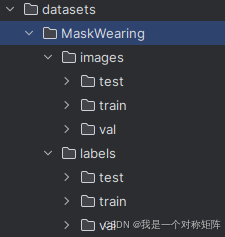
在上一节我们标注了数据并按照结构得到了数据集文件夹MaskWearing,将其放置到yolov5/datasets/MaskWearing下,如下图所示。
然后在yolov5/data下创建mask.yaml文件,文件内容如下:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ./datasets/MaskWearing # dataset root dir
train: images/train # train images (relative to 'path')
val: images/val # val images (relative to 'path')
test: images/test ## Classes
names:0: mask1: nomask
各个参数的含义十分明确,不再做过多介绍
2.2 开启训练
训练的脚本在train.py中,其中def parse_opt(known=False):中定义了非常多的参数,我们按照下面的指令开启训练:
python train.py --name masktest --imgsz 640 --epochs 100 --batch-size 16 --cfg yolov5n.yaml --data mask.yaml --weight yolov5n.pt
- name:本次训练的项目名字,和保存文件夹相关
- imgz:目标尺寸,会缩放到该尺寸进行训练
- epochs:迭代次数
- batch-size:即bs
- cfg:使用哪种模型结构
- data:指定数据集配置文件
- weight:预训练权重(和cfg模型结构相关)
开始训练后会输出一些如模型结构、数据集的信息,可以通过这些信息判断是否正确加载期望的数据集之类的。

等待模型训练完成后,如下图所示:
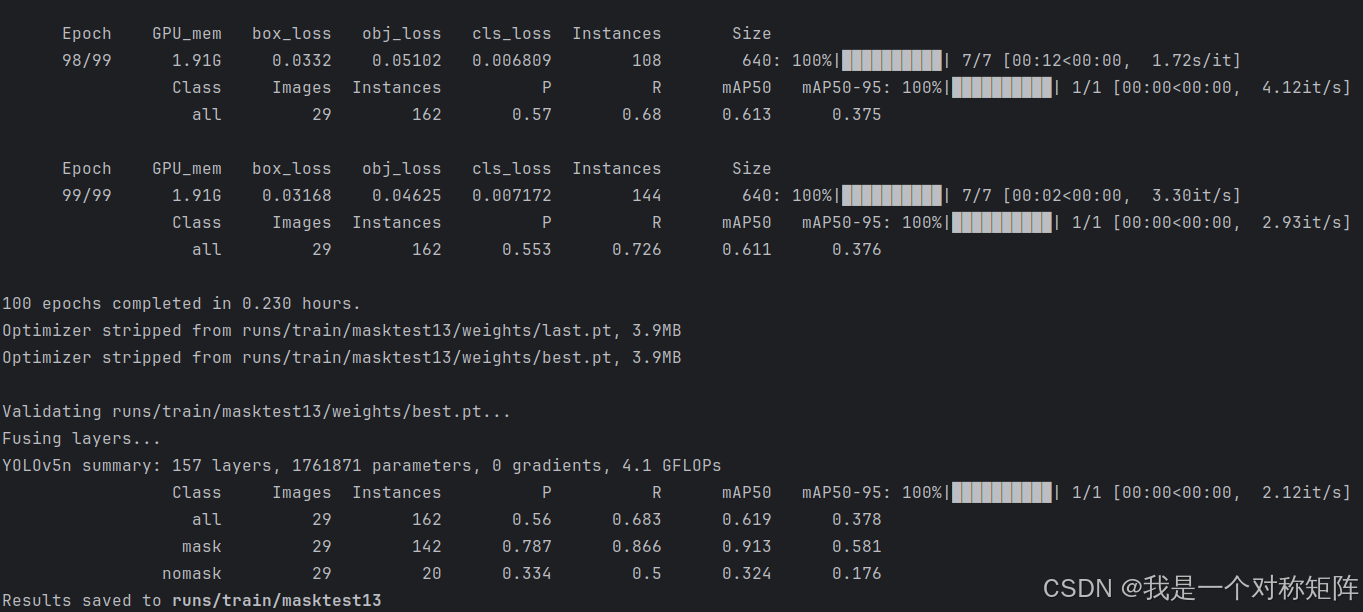
训练数据和权重都保存在runs/train/下,其中还包括其他过程数据,可以通过tensorboard --logdir path_to_runs_dir可以可视化数据。
2.3 模型验证
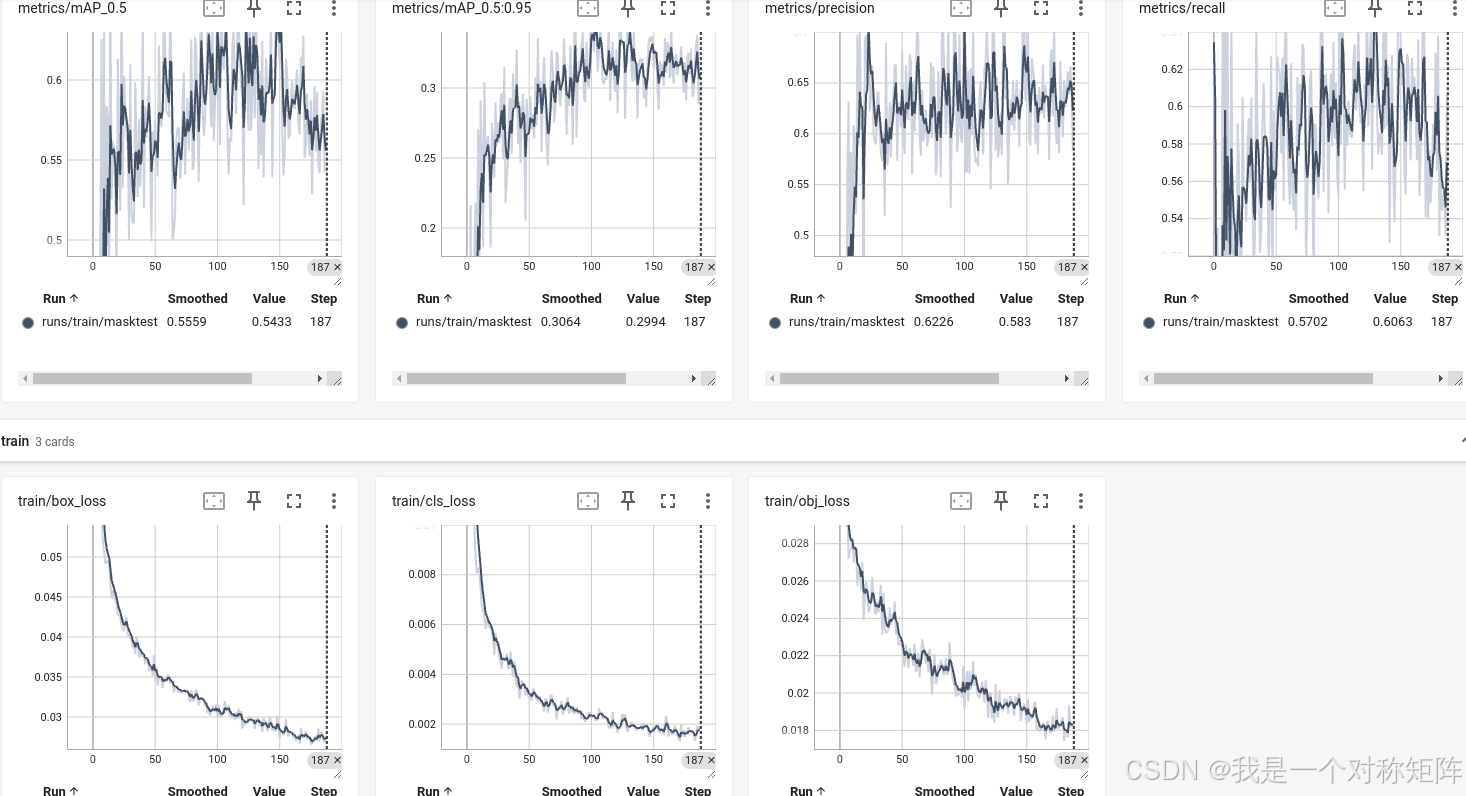
模型训练完毕后,需要看一下在验证集上的指标。该部分由val.py实现,其中weight是训练得到的模型路径:
python val.py --imgsz 640 --epochs 100 --batch-size 16 --cfg yolov5n.yaml --data mask.yaml --weight runs/train/masktest/weights/best.pt
结果如下所示,因为我的数据量很少,所以指标比较低。

2.4 效果检测
除了看指标,我们还希望在图片上进行测试。在detect.py脚本中给定图片和模型权重就可以进行检测,具体命令如下:
python detect.py --imgsz 640 --conf-thres 0.5 --weight runs/train/masktest/weights/best.pt --source images/无标题.png


可以看到模型能够检测到人脸并区分是否戴了口罩。
3、导出onnx模型
3.1 导出
ONNX是一个中间件,比如下图只要各深度学习框架支持onnx,那么就能够实现互通,大大方便框架的维护和使用者的部署。像本文就是pytorch–>onnx–>tensorrt实现最终的模型转换和部署。

在yolov5/export.py中提供了将模型权重导出为onnx模型的脚本,命令为:
python export.py --imgsz 640 --weight runs/train/masktest/weights/best.pt --include onnx
- include:导出格式,除了onnx还支持导出其他格式
执行后产生 runs/train/masktest/weights/best.onnx 文件。
3.2 可视化模型结构
Netron 是神经网络、深度学习和机器学习模型的查看器。Netron 支持 ONNX、TensorFlow Lite、Core ML、Keras、Caffe、Darknet、PyTorch、TensorFlow.js、Safetensors 和 NumPy。在这里我们使用该工具可视化resnet18.onnx模型结构。netron提供了在线版本(也有桌面应用版本),在网页中直接打开模型自动上传后就可以显示了。
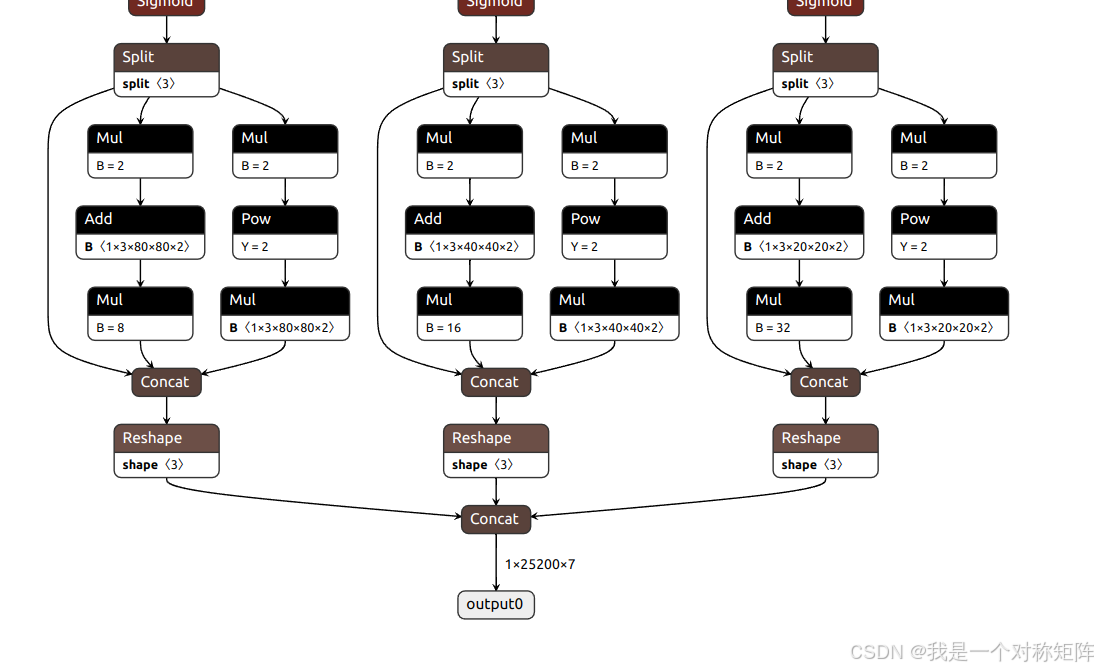
下图可视化best.onnx,展示了输入输出两个节点的信息。输入是[1,3,640,640],输出是[1,25200,7]。
3.3 验证模型格式是否正确
导出成功后,我们可以验证一下onnx模型是否正常。可以使用onnxruntime推理引擎简单推理一下:
import onnx
import onnxruntime as ort
import numpy as np# 1. 用checker方法检查模型是否有效
onnx_model = onnx.load("best.onnx")
onnx.checker.check_model(onnx_model) # 检查模型是否有效,如果无效会报错# 2. 用模拟推理的方式检查模型是否有效
ort_session = ort.InferenceSession("best.onnx")# 3. 准备输入数据
input_name = ort_session.get_inputs()[0].name
input_data = np.full((1, 3, 640, 640),127,np.float32)# 4. 运行推理
outputs = ort_session.run(None, {input_name: input_data})# 5. 打印输出形状
print(outputs[0].shape) # 输出:(1, 25200, 7)
3.4 图片测试
现在导出了onnx模型,我们希望测试一下onnx导出是否正确,其检测结果是否依然准确。
模型
import cv2
import onnxruntime as ort
import numpy as npdef letterbox(img_path, dst_size):passdef postprocess(outputs):passdef get_coco_label(class_id):"""根据 COCO 数据集的 class_id 返回对应的类别名称。参数:- class_id: int,类别索引 (0-79)返回:- str,类别名称,如果 ID 超出范围,则返回 "Unknown""""pass# 加载ONNX模型
model_path = 'best.onnx'
session = ort.InferenceSession(model_path)# 读取图片
image_path = '无标题.png'src_image = cv2.imread(image_path)
# 预处理图片
input_shape = session.get_inputs()[0].shape[2] # 获取模型的输入尺寸 (通常是640x640)
letter_image, scale, x_offset, y_offset = letterbox(image_path, input_shape)
letter_image = letter_image.transpose((2, 0, 1))[::-1] # BGR-->RGB,HWC-->CHW
input_data = letter_image / 255.0 # 归一化
input_data = np.expand_dims(input_data, axis=0) # 添加 batch 维度:CHW-->1CHW
input_data = input_data.astype(np.float32) # 转换为 float32# 进行推理
input_name = session.get_inputs()[0].name
outputs = session.run(None, {input_name: input_data})
outputs = postprocess(outputs)# 你可以根据需要进一步处理输出,绘制边界框
H, W, C = src_image.shape
for batch_bboxs in outputs:for bbox in batch_bboxs:cx, cy, w, h, score, clas_id = bbox# lettbox->src_imagecx = (cx - x_offset) / (W * scale)cy = (cy - y_offset) / (H * scale)w = w / (W * scale)h = h / (H * scale)# (cx,cy,w,h)-->(x1,y1,x2,y2)x1 = int((cx - w / 2) * W)y1 = int((cy - h / 2) * H)x2 = int((cx + w / 2) * W)y2 = int((cy + h / 2) * H)# 获取标签名cls = get_coco_label(int(clas_id))# visualcv2.rectangle(src_image, (x1, y1), (x2, y2), (0, 0, 255), 2)cv2.putText(src_image, f'{cls} {score:.2f}', (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 0, 255), 2)# 显示结果
cv2.imshow('Result', src_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
推理结果如图:

代码大体流程为:创建onnx推理session-->图像预处理-->onnx推理-->后处理(过滤bbox、非极大值抑制处理)-->可视化。上面的代码中大部分都是后处理(用pass省略,完整看源码)。
预处理中使用letterbox缩放扩充到(640,640),然后像素范围缩放到0~1,再reshape为(1,3,640,640)。
4、环境搭建
TensorRT在Nvidia显卡上优化并推理,所以必然需要先配置好显卡驱动、CUDA以及cuDNN等。
这部分的教程可以参考:cap1:TensorRT介绍及CUDA环境安装中的4、基础环境配置
4.1 TensorRT的安装
首先去NVIDIA TensorRT Download选择一个版本,比如TensorRT8。我是Ubuntu20,但是选择TAR包,所以选择Linux_X86_64+TAR package下载。

下载并解压后,有多个目录,其中:
- bin:有trtexec可执行文件,通过这个工具可以实现序列化转换
- include和lib:是C++开发用的头文件和库文件
- python:python的whl文件,通过pip安装
在python中根据python版本安装对应的whl文件,比如我的是python3.10则pip install tensorrt-8.6.1-cp310-none-linux_x86_64.whl
4.2 安装pycuda
TensorRT是在nvidia显卡上推理,要求直接输入输出都在GPU显存空间中。所以会使用CUDA进行相关操作,pycude就是python操作CUDA的库。
安装方式非常简单:pip install pycuda
5、转换TensorRT引擎
这一步主要完成红框内的工作,就是将onnx模型序列化为TensorRT的engine模型。在这个过程中会自动根据设备的特异性进行优化,该过程十分缓慢。但是完成后会保存为本地文件,下次可以直接加载使用,不用再次序列化。

这个过程可以使用基于python的API完成,或者直接使用trtexec工具。
5.1 使用trtexec工具完成序列化
在第3节中下载了TensorRT包,在bin中有trtexec工具。打开终端进入trtexec工具所在文件夹就可以使用该命令工具了。

转换命令为:
trtexec --onnx=resnet18.onnx --saveEngine=resnet18.engine --fp16
onnx指定onnx模型路径,saveEngine知道转换后engine模保存路径,fp16表示使用FP16,这个可以大大提高推理速度。不加–fp16则默认使用FLOAT32
转换完成后如图,最后会出现PASSED结果,此时就得到engine模型。

5.2 使用python的API进行转换
使用python的API进行转换具有比较固定的流程,只不过可以根据需求比如动态输入等进行相应的设置。最终结果和trtexec转换没有什么区别。
不管什么方式转换得到的engine都可以被python或者c++拿去部署使用,但是要注意:1)版本对应:即转换使用的TensorRT版本和部署推理使用的版本需要一致;2)不支持跨设备:即在哪种设备上转换的就只能在哪种设备上使用,因为转换时根据设备特异性进行了优化。
import tensorrt as trt
# import pycuda.driver as cuda
# import pycuda.autoinit# TensorRT 需要一个 日志对象,用于输出 WARNING 级别的日志,帮助调试问题
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)def build_engine(onnx_file_path, engine_file_path):with trt.Builder(TRT_LOGGER) as builder, \builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)) as network, \trt.OnnxParser(network, TRT_LOGGER) as parser:# config 配置 TensorRT 编译选项builder_config = builder.create_builder_config()builder_config.set_flag(trt.BuilderFlag.FP16) # 设置FP16加速(如果 GPU 支持),提高计算速度并减少显存占用。注释则默认使用FP32builder_config.set_memory_pool_limit(trt.MemoryPoolType.WORKSPACE, 1 << 30) # 设置最大工作空间(1GB),用于存储中间 Tensor 和计算资源# 读取 ONNX 文件with open(onnx_file_path, 'rb') as model:if not parser.parse(model.read()):for error in range(parser.num_errors):print(parser.get_error(error))return None# 构建 TensorRT 引擎serialized_engine = builder.build_serialized_network(network, builder_config)# 开始反序列化为可执行引擎runtime = trt.Runtime(TRT_LOGGER)engine = runtime.deserialize_cuda_engine(serialized_engine)# 序列化并保存引擎with open(engine_file_path, 'wb') as f:f.write(engine.serialize())print(f"Saved TensorRT engine to {engine_file_path}")if __name__ == "__main__":onnx_file = "resnet18.onnx"engine_file = "resnet18.engine"build_engine(onnx_file, engine_file)
通过这种方式,我们也成功得到的engine模型。
6、TensorRT部署推理
6.1 TensorRT推理流程介绍
推理的代码十分简单,推理的流程图如下。TensorRT的推理是在GPU上完成,所以推理只能从GPU的显存获取数据,推理的直接输出也是在显存中。所以输入数据需要从RAM(cpu端,或者host端)复制到GPU(设备端)中去。推理后需要从GPU复制到cpu后,才能使用numpy或者其他库进行操作。
为什么要分配显存空间,因为CUDA程序只能读取位于显存上的数据,而一般程序读取得数据都位于RAM。所以我们需要先在CUDA上用cuda.mem_alloc为模型推理的输入和输出开辟足够的空间,然后将python读取的图像数据用cuda.memcpy_htod_async复制到CUDA显存中去,推理时直接从显存读取数据。推理结束后,输出放在显存上,再使用cuda.memcpy_dtoh_async将结果从显存复制到RAM中。同理接收数据时,需要再RAM中开辟足够的空间接收从显存来的数据,所以使用output = np.empty((1, 25200, 7), dtype=np.float32)开辟了足够大小的空间。

为了方便大家理解,下面给出了只和TensorRT有关的代码。YoloTRT类中初始化时负责创建TensoRT上下文推理环境和分配显存,infer函数则负责推理(接受输入数据–>复制到CUDA–>推理–>将结果复制到CPU):
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit # cuda初始化import numpy as npTRT_LOGGER = trt.Logger(trt.Logger.WARNING)def load_engine(engine_file_path):"""从engine模型反序列化:param engine_file_path::return:""""""加载 TensorRT 引擎"""with open(engine_file_path, "rb") as f, trt.Runtime(TRT_LOGGER) as runtime:return runtime.deserialize_cuda_engine(f.read())def allocate_buffers(engine):"""给模型直接输入和输出分配CUDA缓存区:param engine::return:"""inputs, outputs, bindings = [], [], []stream = cuda.Stream()for binding in engine: # 遍历模型engine中的所有输入输出节点size = trt.volume(engine.get_tensor_shape(binding)) * np.dtype(np.float32).itemsizedevice_mem = cuda.mem_alloc(size) # 分配size大小的空间,用于储存该节点的数据engine.get_tensor_mode(binding)if engine.get_tensor_mode(binding) == trt.TensorIOMode.INPUT:inputs.append(device_mem) # 如果是输入节点则将该空间地址存入inputselif engine.get_tensor_mode(binding) == trt.TensorIOMode.OUTPUT:outputs.append(device_mem) # 如果是输出节点则将该空间地址存入outputsbindings.append(int(device_mem))return inputs, outputs, bindings, streamclass YoloTRT:def __init__(self, engine):self.context = engine.create_execution_context() # 创建推理的上下文环境self.inputs, self.outputs, self.bindings, self.stream = allocate_buffers(engine) # 初始化分配CUDA显存空间def infer(self, image):# 将输入数据拷贝到 GPUcuda.memcpy_htod_async(self.inputs[0], image, self.stream) # image是cpu的ram数据,需要拷贝到GPU,才能被tensorrt推理使用# 执行推理self.context.execute_async_v2(self.bindings, self.stream.handle, None) # 推理# 从 GPU 拷贝输出结果# 初始化一个cpu的ram空间,方便从gpu接受输出数据,数据量为25200*85output = np.empty((1, 25200, 7), dtype=np.float32)cuda.memcpy_dtoh_async(output, self.outputs[0], self.stream) # 将位于gpu上的输出数据复制到cpu上,方便对齐操作self.stream.synchronize() # 同步,gpu是并行的,这里相当于等待同步一下return output # 最后将输出结果返回if __name__ == "__main__":engine_path = "yolov5s.engine"engine = load_engine(engine_path)yoloTrt = YoloTRT(engine) # 初始化一次# input_data = yoloTrt.preprocess("test.jpeg", 640) # 输入预处理output = yoloTrt.infer(input_data) # 推理# output = yoloTrt.postprocess(output) # 后处理# yoloTrt.visual(output) # 可视化
使用TensorRT推理效果如下图所示

7、完整代码
为了方便,本文中一些代码,只是给出一个框架。完整的项目可以在这里获取:ishyj/python-tensorrt-yolov5-mask ,包括从yolov5训练(含数据集)到onnx验证推理,再到TensorRT推理的所有代码。