做个购物网站自己的网站怎么做下载链接
【AI大模型入门指南】概念与专有名词详解 (二)
一 、前言
当你和聊天机器人聊得天花乱坠时,当你用文字让AI生成精美图片时,当手机相册自动帮你分类照片时 —— 这些看似智能的操作背后,都藏着 AI 大模型的身影。
本文将用最接地气的比喻和案例,带新手穿透专业术语的迷雾:从大模型家族,再到模型调教的核心逻辑(如何给模型喂数据、怎么让它瘦身提速)。
无论你是对 AI 好奇的小白,还是想梳理知识框架的学习者,都可以有所收获。
二、大模型专有名词解释
(一)模型家族成员
| 模型名称 | 核心架构/特点 | 通俗比喻 | 典型应用场景 | 代表作/说明 |
|---|---|---|---|---|
| 大语言模型(LLM) | 采用Transformer架构,在海量文本数据中训练 | 自然语言处理领域的“大佬” | 写文章、做翻译、回答问题等 | GPT系列、文心一言 |
| 循环神经网络(RNN) | 擅长处理序列数据,但长距离理解能力较弱 | 像记忆力不好的人,读长句子易“断片” | 自然语言处理中的序列数据处理 | / |
| 长短期记忆网络(LSTM) | RNN的改进版,增加特殊门控机制 | RNN的“加强版”,解决了记忆问题 | 更擅长处理长文本 | / |
| 卷积神经网络(CNN) | 通过卷积、池化操作提取图像特征 | 图像识别的“主力军” | 计算机视觉领域的图像识别等任务 | / |
| 混合专家模型(MoE) | 包含多个“专家”,根据任务选择合适“专家”处理并整合结果 | 有多个“专家”分工协作 | 处理大规模数据 | / |
| 图神经网络(GNN) | 专门处理图形结构数据 | 图形结构数据处理的“专家” | 社交网络分析、分子结构研究等 | / |
(二)训练那些事儿
1、预训练:让模型在海量无标注数据上“自学”,掌握通用知识,为后续学习打基础。
2、微调:在预训练基础上,用特定领域少量有标注数据“开小灶”,让模型适应具体任务,比如让通用语言模型学会医疗术语。
3、监督微调(SFT):微调的一种,用标注好的“标准答案”数据训练,让模型在特定任务上表现更出色。
4、少样本学习:只给模型看少量示例,它就能快速学会新任务,靠的是之前预训练积累的“知识”。
5、 零样本学习:模型没见过相关数据也能推理,比如没见过独角兽,也能根据已有概念和描述回答相关问题。
6、对抗训练:生成器和判别器“互相对抗”,生成器生成“假数据”,判别器分辨真假,让模型更抗干扰,更鲁棒。
7、 超参数调优:超参数是训练前要设置的“学习参数”,像学习率、批量大小等,通过各种方法找到最佳组合,让模型学习效果更好。
(三)其他重要概念
1、注意力机制:让模型在处理数据时,能重点关注关键部分,就像看书时用荧光笔标记重点内容。
2、位置编码:给Transformer模型“补课”,让它记住数据的顺序,不然模型容易“分不清先后”。
3、激活函数:给神经网络增加“灵活性”,引入非线性因素,让模型能学习复杂模式,ReLU函数就是常见的“得力助手”。
4、嵌入层:把离散数据(如单词)转换成连续向量,让模型能理解单词的语义,还能计算单词相似度。
三、AI大模型的调教步骤
1、模型架构:Transformer——大模型的“黄金骨架”
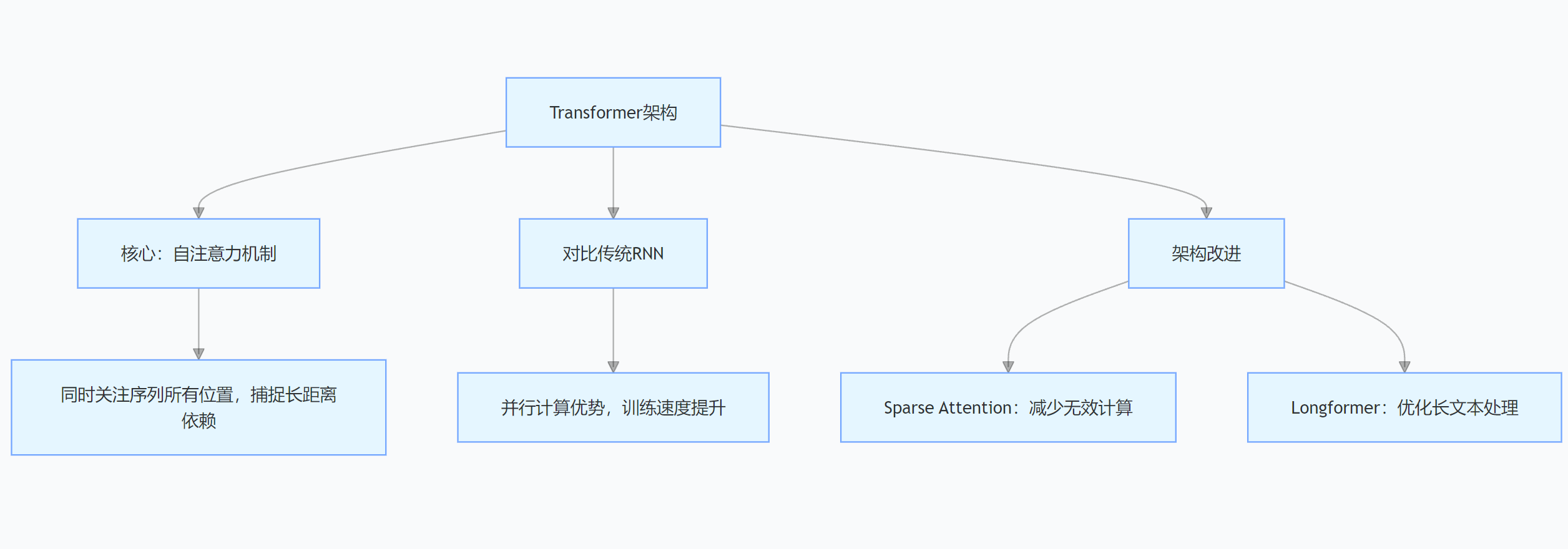
Transformer架构是大模型的“黄金骨架”,它的核心自注意力机制,就像给模型装上了“鹰眼”,在处理文本等序列数据时,能同时关注每个位置,轻松捕捉长距离依赖关系。
和传统RNN相比,Transformer在并行计算上优势巨大,训练速度就像坐了火箭。在机器翻译中,它能精准理解源语言句子里词汇的关系,翻译出更流畅的译文。
还有很多对Transformer的改进,比如Sparse Attention减少不必要计算,Longformer专为长文本优化,让大模型处理数据更高效。
2、数据处理与预训练:大模型的“营养餐”
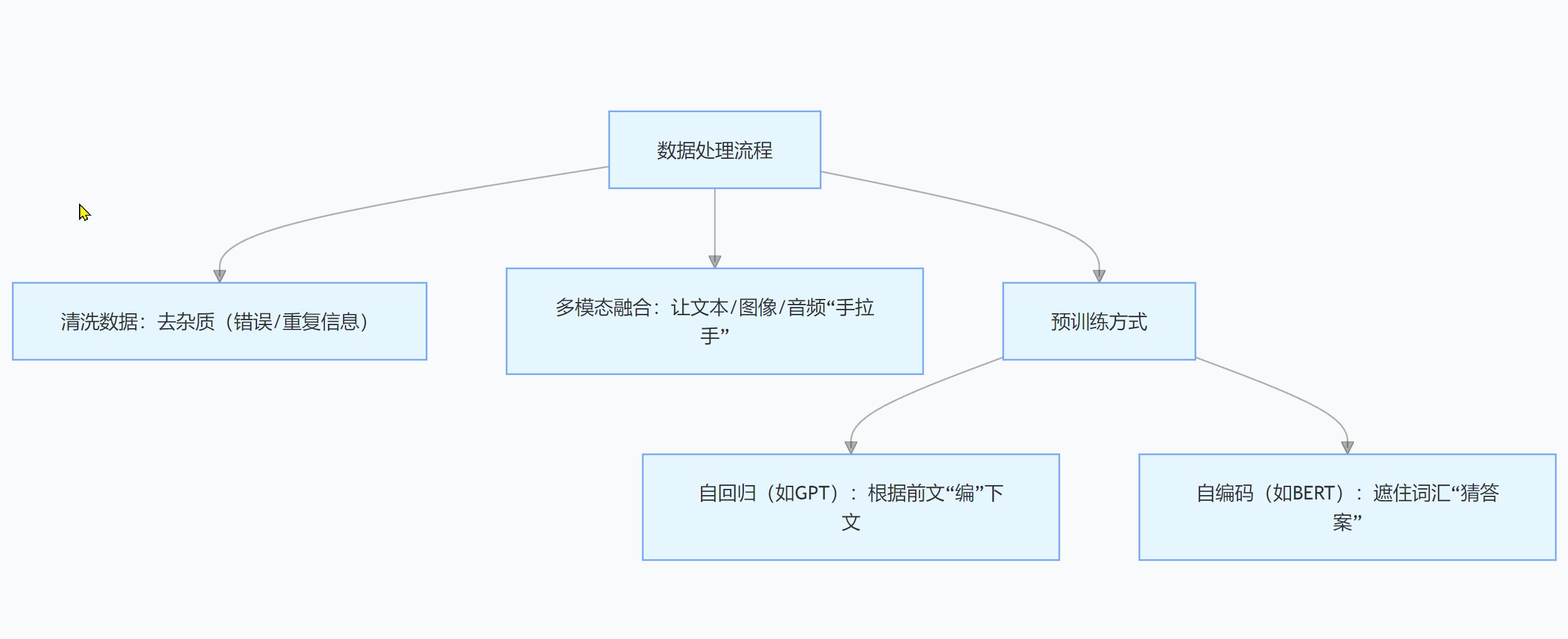
训练大模型前,要先给它准备“营养餐”——处理海量数据。得先把数据里的“杂质”(错误、重复、无关信息)去掉,比如处理文本时要删掉拼写错误。
对于多模态数据,还得想办法把不同形式的数据“融合”在一起,让模型学习它们之间的联系。
预训练有两种主要方式:自回归,像GPT,根据前文预测下一个单词,一点点“编”出文本;自编码,像BERT,遮住部分输入让模型猜,以此学习文本语义和语法。
3、模型训练与优化:大模型的“高效学习法”
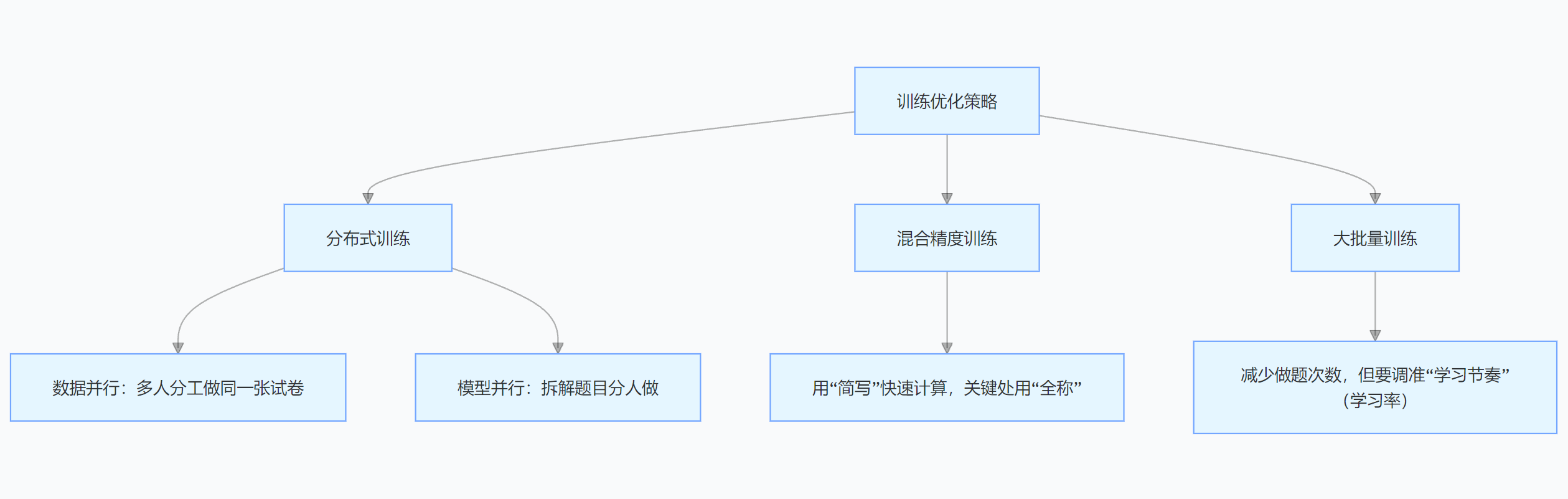
大模型参数太多,训练起来超费时间和资源,所以要用分布式训练。数据并行就像一群人分工合作,每个设备处理一部分数据,最后汇总结果;模型并行则是把模型拆分到不同设备上计算,大家齐心协力加快训练速度。
还有混合精度训练,就像灵活切换学习工具,用低精度数据快速计算,关键地方再用高精度数据保证准确,既能提速又能省显存。
大批量训练可以减少训练次数,但得调整好学习率等参数,不然模型容易“学歪”。
4、模型压缩:给大模型“瘦身”
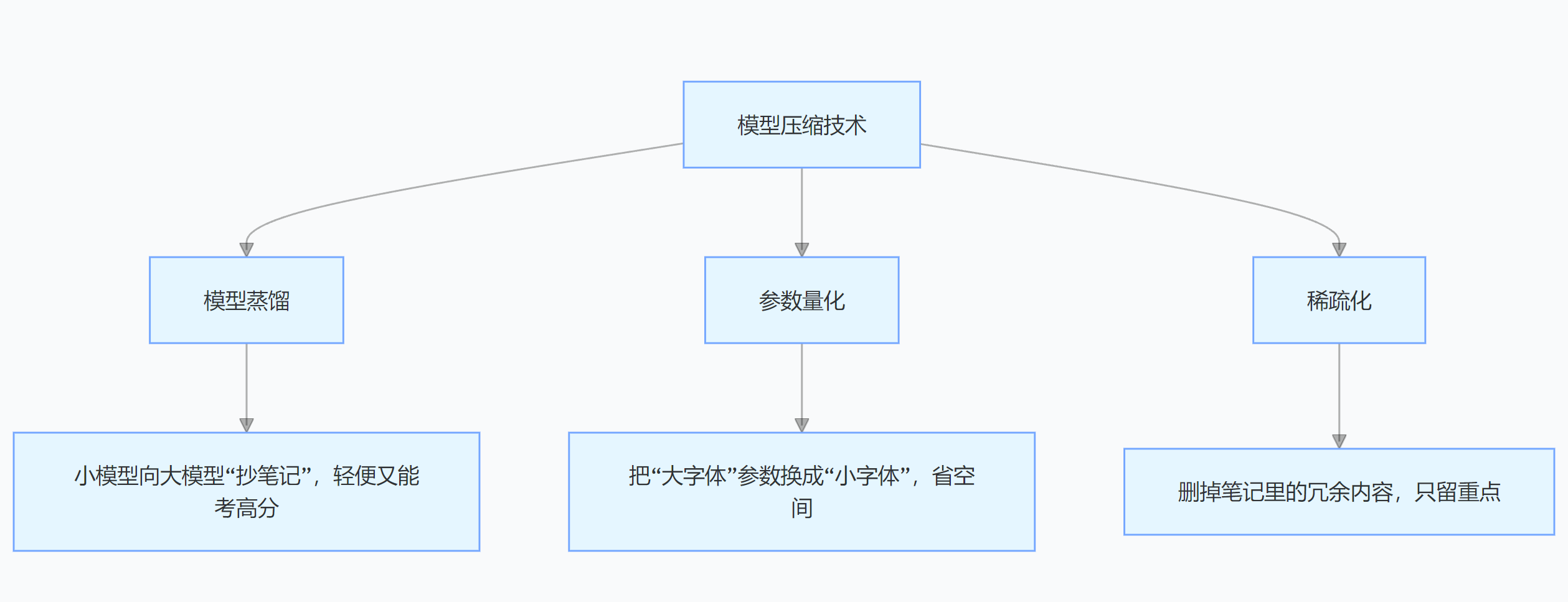
大模型训练好后“体型庞大”,部署起来成本高,所以要“瘦身”。
模型蒸馏是让小模型向大模型“拜师学艺”,小模型学到大模型的知识后,性能不错还更轻便;参数量化降低权重精度,就像把书里的字变小,不影响理解还省空间。稀疏化去掉冗余参数,让模型更简洁高效。