中国新农村建设网站淘宝客的网站怎么做呢
今天教大家如何设计一个企业级的 deepseek问答 一样的系统 , 基于目前主流的技术:前端vue3,后端springboot。同时还带来的项目的部署教程。
系统的核心功能
1. 支持本地上传文档知识库,RAG技术。 支持的文档有txt,doc,docx,pdf 。
2. 支持联网搜索。
3. 支持深度思考。
4. 支持历史上下文消息。
5.支持websocket流式。
6. 支持用户登录,注册。
7. 支持会话管理。
系统需要的组件
ElasticSearch8 : 存储知识库文档向量。
redis: 存储系统用的消息缓存。
mysql8: 存储关系型表。
技术栈
JDK11 + SpringBoot + VUE3
视频演示
仿DeepSeek AI问答系统完整版
图片演示
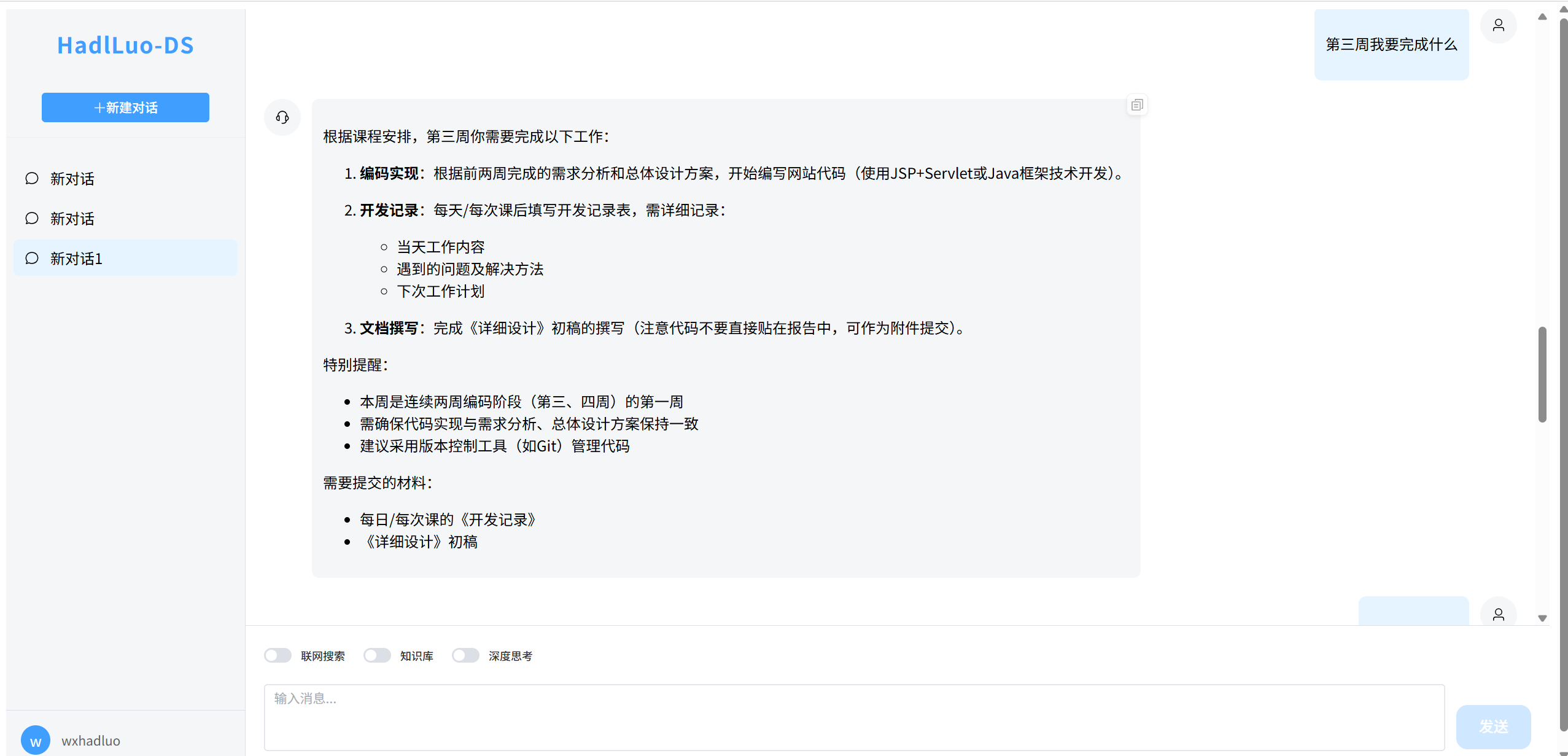
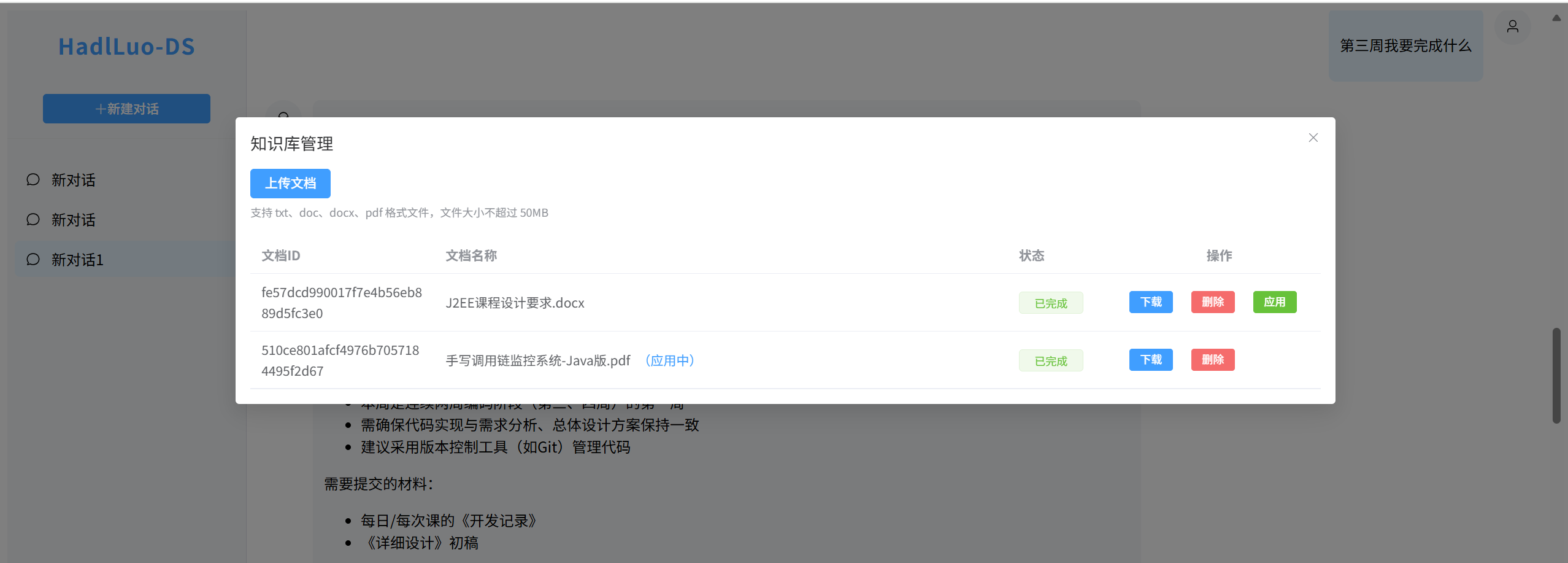
系统实现
RAG技术实现
RAG是一种结合 信息检索(Retrieval) 和 文本生成(Generation) 的 AI 技术,主要用于提升大语言模型(LLM)生成内容的准确性和时效性。
下面来介绍下RAG实现的核心步骤。
文本提取分块
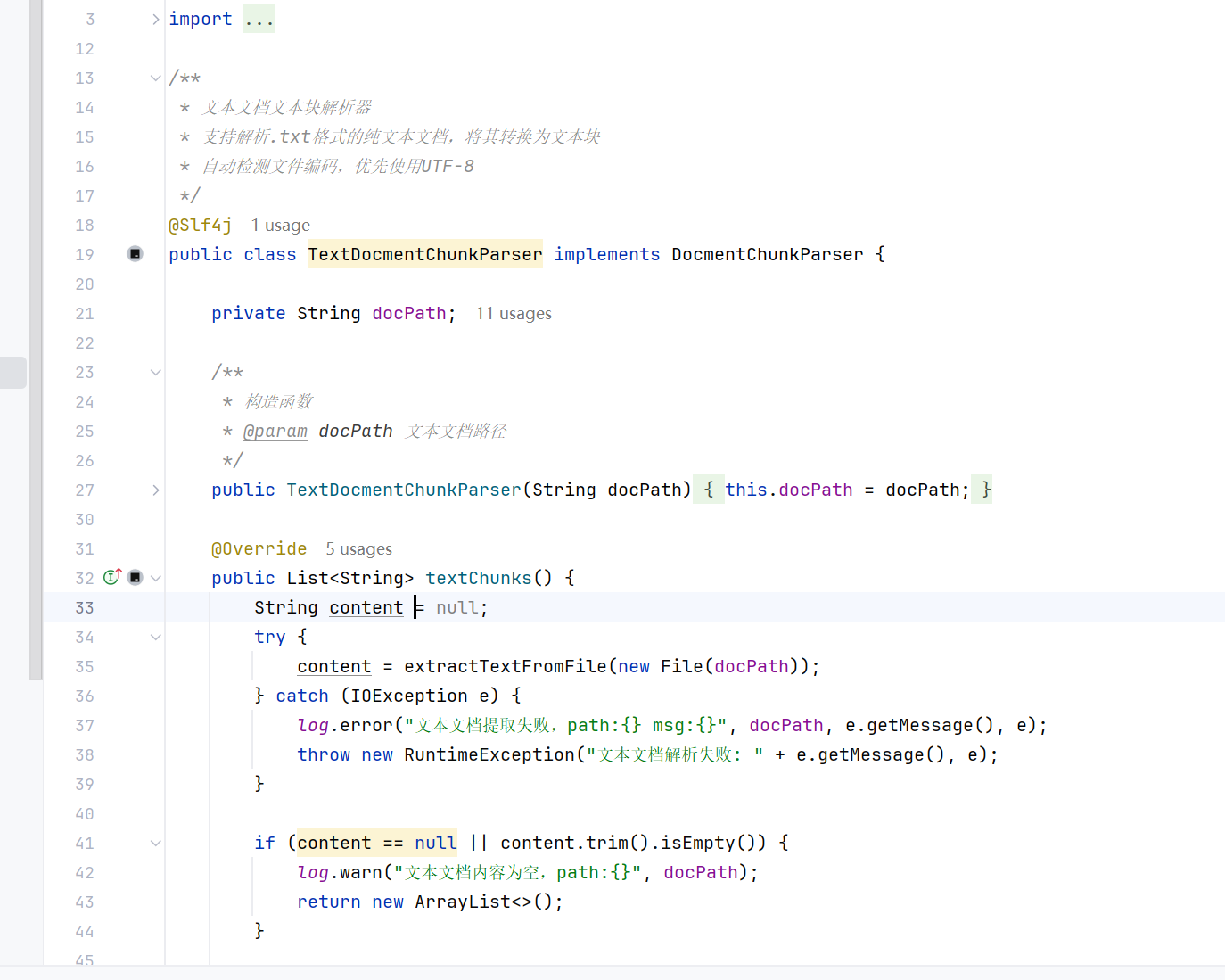
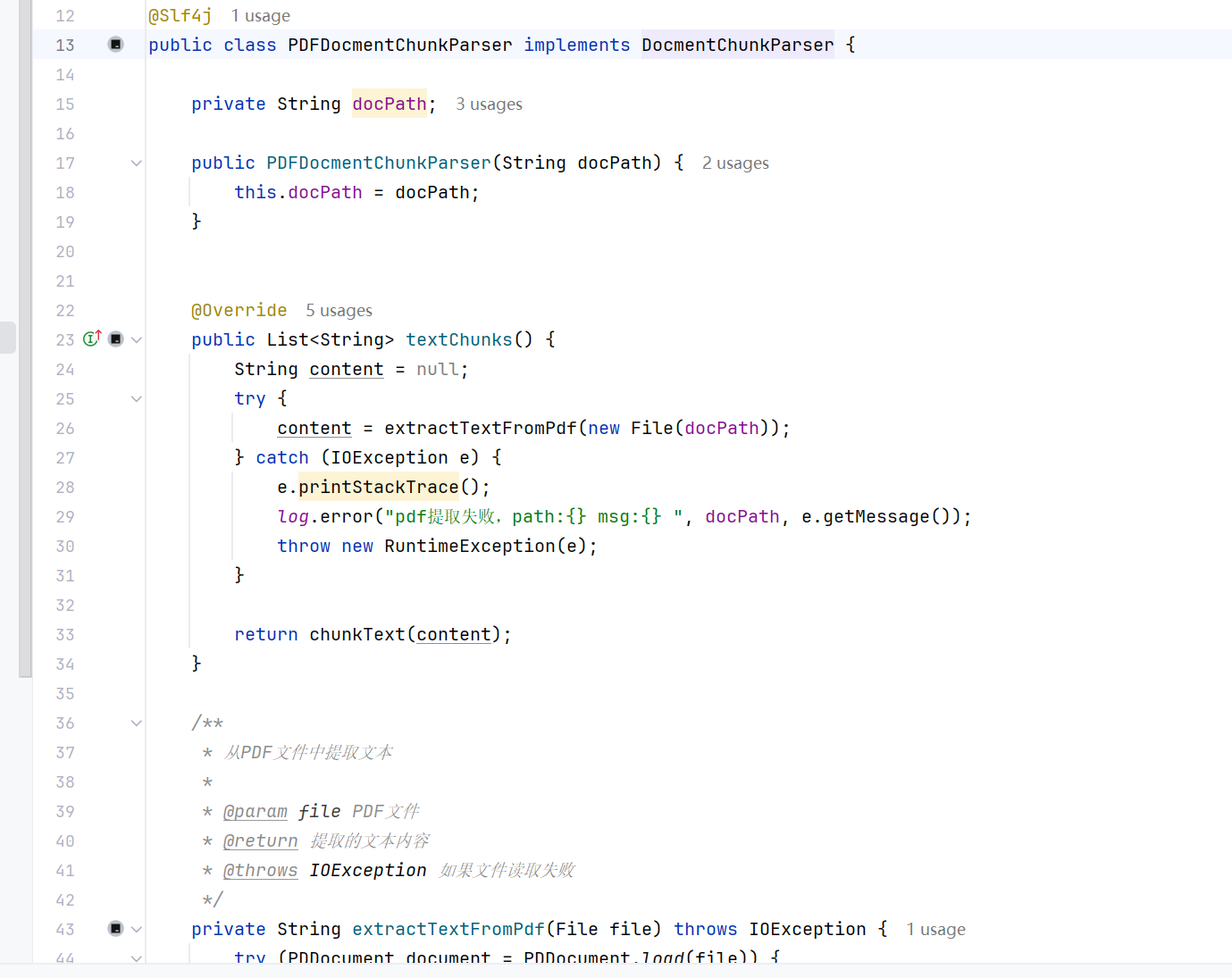
用户上传文档时, 首选需要将文档解析成很多文本块, 系统通过 DocmentChunkParser 接口的 textChunks 方法 将传入 的文档(txt,docx,pdf)解析成文本块,代码:
public interface DocmentChunkParser {// 每个文本块的最大字符数public static final int CHUNK_SIZE = 1000;// 文本块之间的重叠字符数public static final int CHUNK_OVERLAP = 200;List<String> textChunks();
}对应的TXT实现:
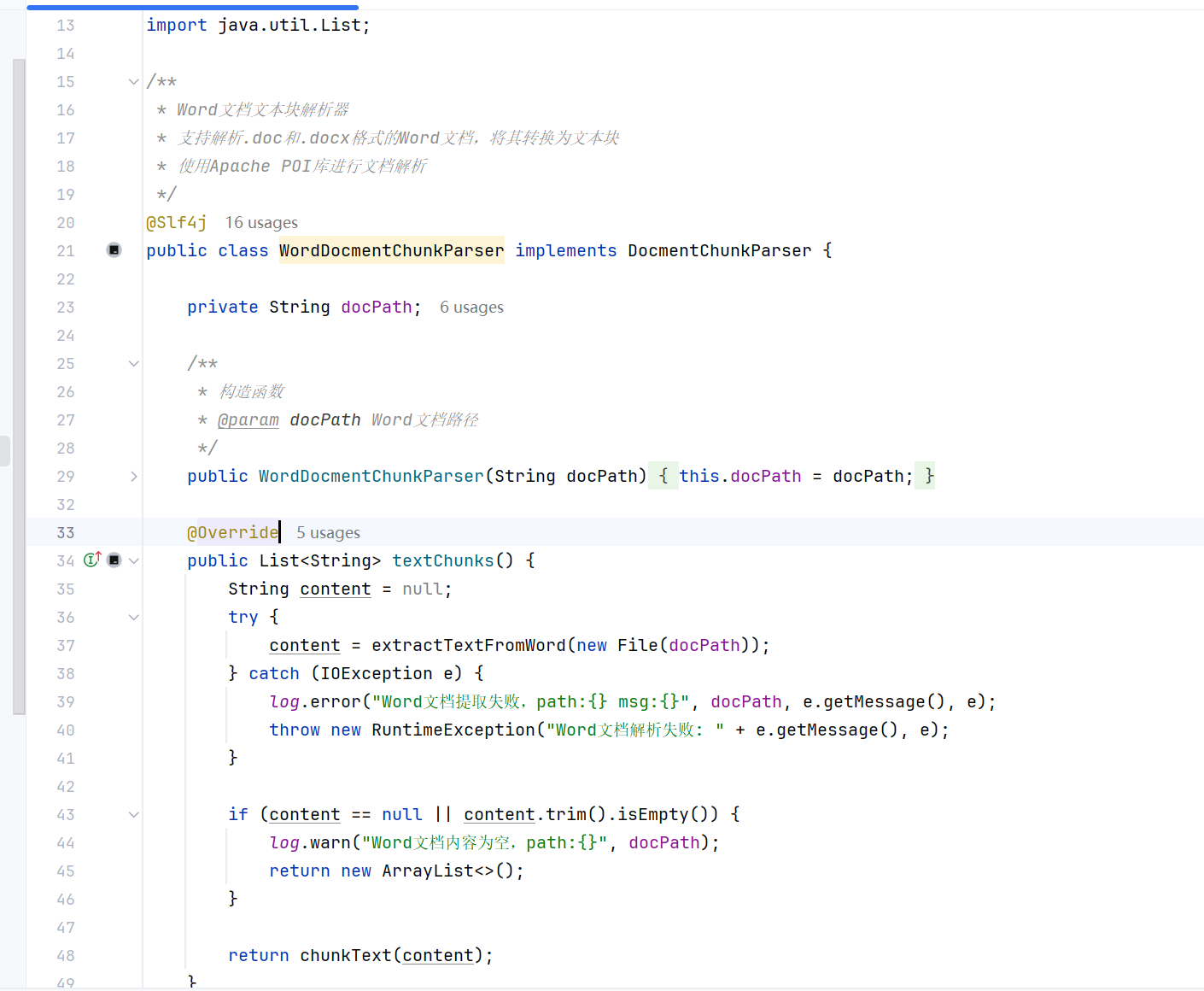
对应的WORD实现:
对应的PDF实现:
embeddings阶段,文本转向量
拿到文本块后, 需要将文本转换成向量, 也就是 embeddings阶段。系统采用的是 “阿里云百炼” 平台的 向量模型:
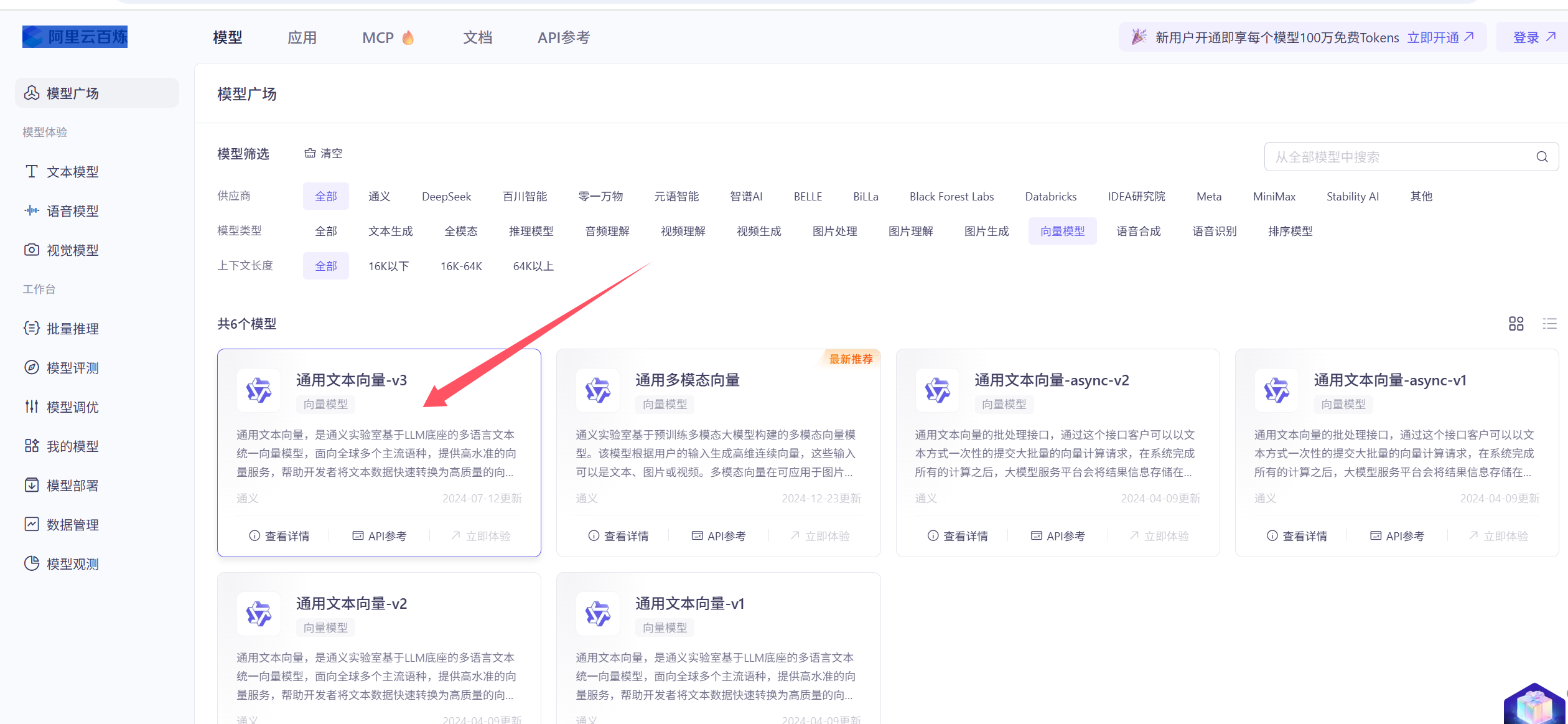
用户需要自己申请api的key。 到阿里百炼平台申请就行了。
向量数据库存储+检索
将文本转成向量后,需要存储到向量数据库里面,这里我选择的是elasticsearch8。
为什么选择elasticsearch , 支持数据量大,能水平分片, 支持 dense_vector 字段,直接支持向量存储和相似性搜索,无需插件。支持 cosine(余弦相似度)、dot_product(点积)、l2_norm(欧式距离)等计算方式。
支持 近似最近邻搜索(ANN)。如果企业用也可以选择。
整个向量数据操作都是在 DocumentChunkRepository 接口中实现:
public interface DocumentChunkRepository {/*** 通过文档id查询文本块* @param documentId* @return*/List<DocumentChunk> findByDocumentId(String documentId);/*** 删除文档* @param documentId*/void deleteByDocumentId(String documentId);/*** 存储文本向量* @param documentChunk* @return*/DocumentChunk save(DocumentChunk documentChunk);/*** 向量关键词搜索,基于KNN算法* @param documentId* @param queryVector* @param k* @return*/List<DocumentChunk> findTopKSimilarChunks(String documentId, List<Float> queryVector, int k);
}联网搜索实现
我们直到deepseek模型是不能搜索到今天的天气,新闻等信息的。如果有这样的需求,就需要开启联网搜索功能。
首先 需要寻找一个联网搜索的插件或者api接口。目前有很多这样的接口,比如:
searchapi (国外), duckduckgo(国外),必应搜索API 等。
国内的我随便找了一个叫 “博查搜索” ,提供了api搜索。
下面是对接博查搜索的代码:
/*** 博查AI搜索服务实现* 基于博查AI开放平台的Web Search API* 支持实时网页搜索,适用于AI应用*/
@Slf4j
@Service
public class BochaWebSearchService implements WebSearchService {// 博查API配置private static final String BOCHA_API_URL = "https://api.bochaai.com/v1/web-search";private static final String BACKUP_API_URL = "https://api.bochaai.com/v1/search";@Value("${bocha.api.key}")private String apiKey;private final HttpClient httpClient;private final ObjectMapper objectMapper;private final Random random = new Random();// 用户代理池private static final String[] USER_AGENTS = {"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36","Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36","Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:121.0) Gecko/20100101 Firefox/121.0"};public BochaWebSearchService() {this.httpClient = HttpClient.newBuilder().connectTimeout(Duration.ofSeconds(10)).build();this.objectMapper = new ObjectMapper();}@Overridepublic List<String> search(String query, int maxResults) {if (query == null || query.trim().isEmpty()) {log.warn("搜索查询为空");return Collections.emptyList();}try {// 首先尝试主APIList<String> results = performSearch(BOCHA_API_URL, query, maxResults);if (!results.isEmpty()) {return results;}// 主API失败,尝试备用APIlog.warn("主API返回空结果,尝试备用API");results = performSearch(BACKUP_API_URL, query, maxResults);if (!results.isEmpty()) {return results;}log.warn("所有API都返回空结果,返回模拟结果");return getMockResults(query, maxResults);} catch (Exception e) {log.error("博查搜索服务异常: {}", e.getMessage(), e);return getMockResults(query, maxResults);}}/*** 执行搜索请求*/private List<String> performSearch(String apiUrl, String query, int maxResults) throws Exception {String requestBody = buildRequestBody(query, maxResults);HttpRequest request = HttpRequest.newBuilder().uri(URI.create(apiUrl)).header("Authorization", "Bearer " + apiKey).header("Content-Type", "application/json").header("Accept", "application/json").header("User-Agent", getRandomUserAgent()).POST(HttpRequest.BodyPublishers.ofString(requestBody, StandardCharsets.UTF_8)).timeout(Duration.ofSeconds(30)).build();log.info("发送博查搜索请求: {}", query);CompletableFuture<HttpResponse<String>> future = httpClient.sendAsync(request, HttpResponse.BodyHandlers.ofString(StandardCharsets.UTF_8));HttpResponse<String> response = future.get(30, TimeUnit.SECONDS);if (response.statusCode() == 200) {return parseSearchResults(response.body(), maxResults);} else {log.warn("博查API请求失败,状态码: {}, 响应: {}", response.statusCode(), response.body());throw new RuntimeException("API请求失败: " + response.statusCode());}}/*** 构建请求体*/private String buildRequestBody(String query, int maxResults) {try {Map<String, Object> requestData = new HashMap<>();requestData.put("query", query);requestData.put("count", Math.min(maxResults, 20)); // 博查API最大支持20个结果requestData.put("freshness", "oneYear"); // 搜索一年内的内容requestData.put("summary", false); // 不需要摘要requestData.put("safeSearch", "moderate"); // 中等安全搜索return objectMapper.writeValueAsString(requestData);} catch (Exception e) {log.error("构建请求体失败: {}", e.getMessage());throw new RuntimeException("构建请求体失败", e);}}/*** 解析搜索结果*/private List<String> parseSearchResults(String responseBody, int maxResults) {try {JsonNode root = objectMapper.readTree(responseBody);List<String> results = new ArrayList<>();// 解析博查API响应格式JsonNode data = root.path("data") ;JsonNode webPages = data.path("webPages");JsonNode valueArray = webPages.path("value");if (valueArray.isArray()) {for (JsonNode item : valueArray) {if (results.size() >= maxResults) {break;}String title = getJsonValue(item, "name");String url = getJsonValue(item, "url");String snippet = getJsonValue(item, "snippet");String siteName = getJsonValue(item, "siteName");if (!title.isEmpty() && !url.isEmpty()) {StringBuilder result = new StringBuilder();result.append("标题: ").append(title);if (!siteName.isEmpty()) {result.append(" (来源: ").append(siteName).append(")");}result.append("\n链接: ").append(url);if (!snippet.isEmpty()) {result.append("\n摘要: ").append(snippet);}results.add(result.toString());}}}log.info("博查搜索成功,返回{}个结果", results.size());return results;} catch (Exception e) {log.error("解析博查搜索结果失败: {}", e.getMessage(), e);return Collections.emptyList();}}/*** 安全获取JSON值*/private String getJsonValue(JsonNode node, String fieldName) {JsonNode field = node.path(fieldName);return field.isMissingNode() ? "" : field.asText("").trim();}/*** 获取随机User-Agent*/private String getRandomUserAgent() {return USER_AGENTS[random.nextInt(USER_AGENTS.length)];}/*** 获取模拟搜索结果(当API不可用时)*/private List<String> getMockResults(String query, int maxResults) {List<String> mockResults = new ArrayList<>();int count = Math.min(maxResults, 3);for (int i = 1; i <= count; i++) {mockResults.add(String.format("标题: 关于'%s'的搜索结果 %d (模拟数据)\n" +"链接: https://example.com/search-result-%d\n" +"摘要: 这是关于'%s'的模拟搜索结果,实际使用时请配置博查API Key。",query, i, i, query));}log.info("返回{}个模拟搜索结果", mockResults.size());return mockResults;}
}将联网搜索的结果转变成一个List<String>的字符串集合,然后传到deepseek ,deepseek就会按照联网的结果进行总结输出。
深度思考实现
这个其实很简单,我们打开deepseek官网 , 找到推理模型, deepseek-reasoner。
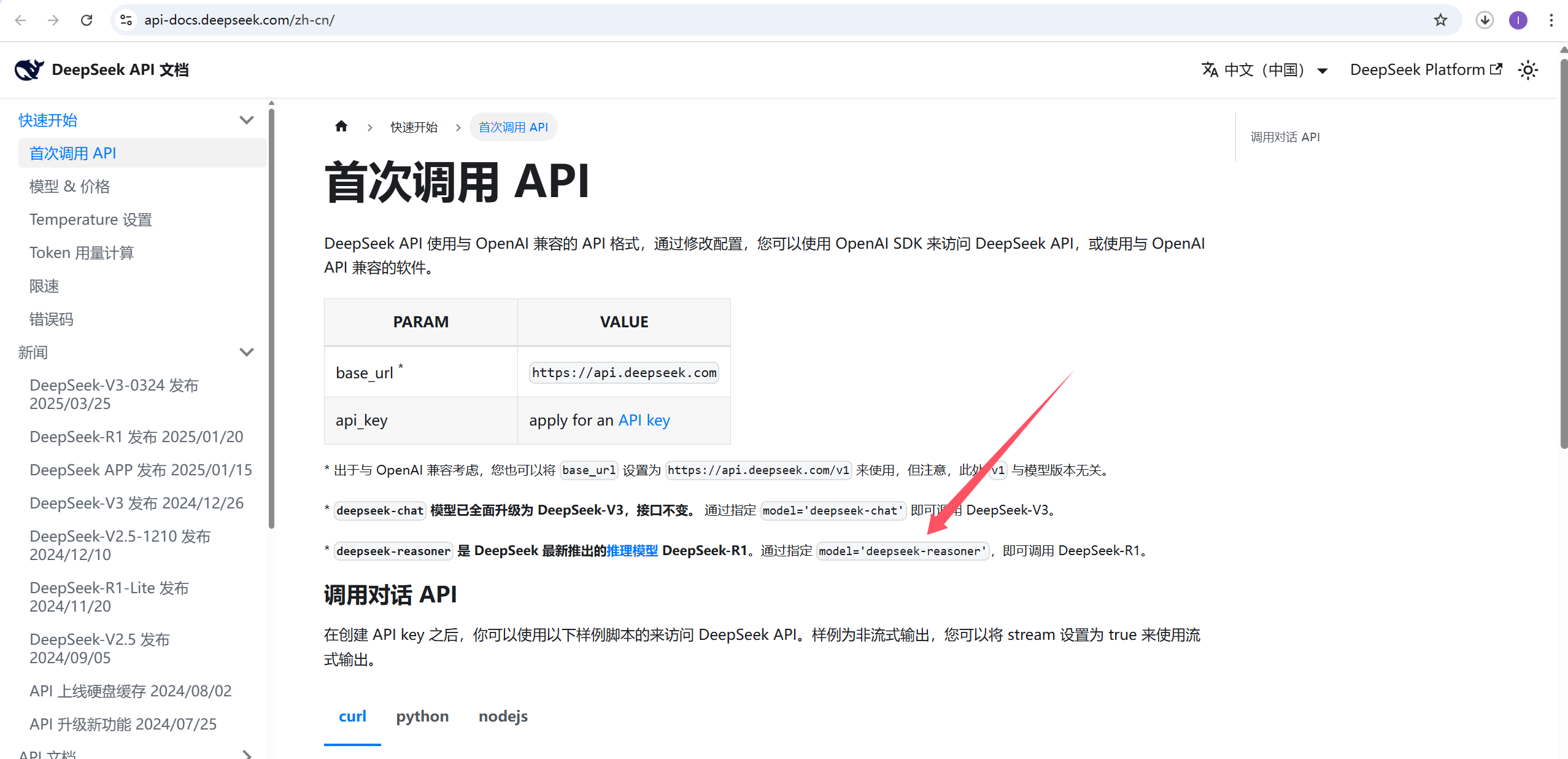
当设置为 deepseek-reasoner 模型,然后问答时, 就会先输出推理的内容, 然后才输出有用结果。
部署教程
前端部署
安装node , 版本:v22.15.0 , 安装完成后。
进入到项目 chatgpt-web 目录下,这个项目是vue前端, 右键,运行cmd,运行下面命令:
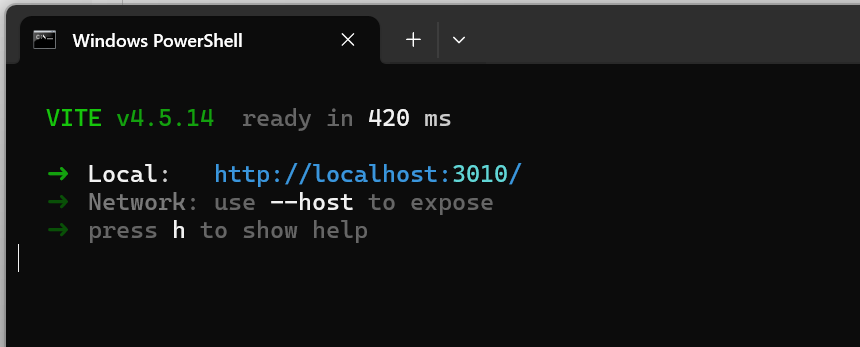
npm run dev
由于我已经跟你npm install好了,所以你无需执行,直接run就可以了!!
运行项目
执行sql
自己安装好数据库,注意,必须是mysql8 ,否则代码运行会出错。新建一个 wxhadluo-deepseek 数据库, 然后执行 “wxhadluo-deepseek.sql”
Redis安装
项目需要安装redis,直接下载一个windows版本的redis即可,没有的联系我。
ElasticSearch8安装
es的安装可以自行百度
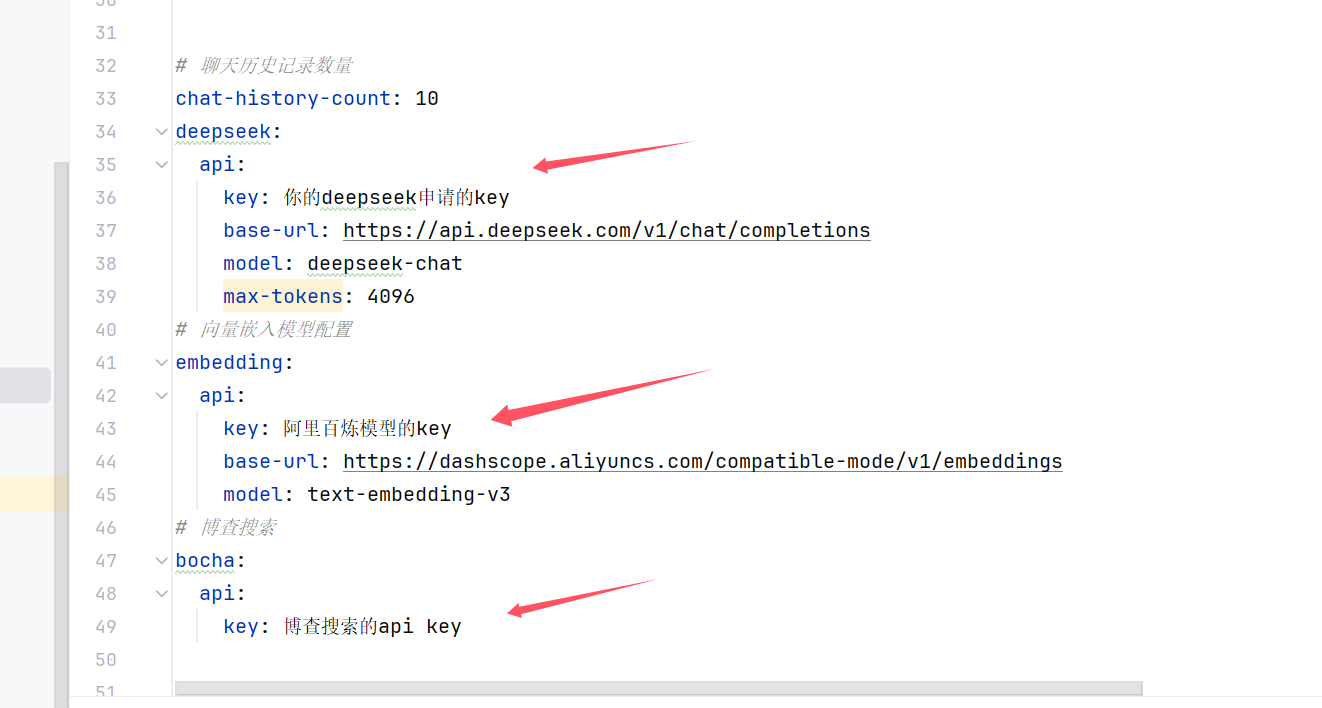
几个api key的申请
1. deepseek官网的api key申请,这个自己申请就好。
2. 博查搜索的api key 申请, 这个自己到官网申请就好。
3. 向量模型的api key 申请,这个到阿里的百炼大模型平台申请就好。前面讲解原理我也提到过。
启动后端项目
然后部署后端 , 打开idea, 导入maven工程 。
打开resources目录, 修改 application.yml 配置文件,主要修改下面几个信息:
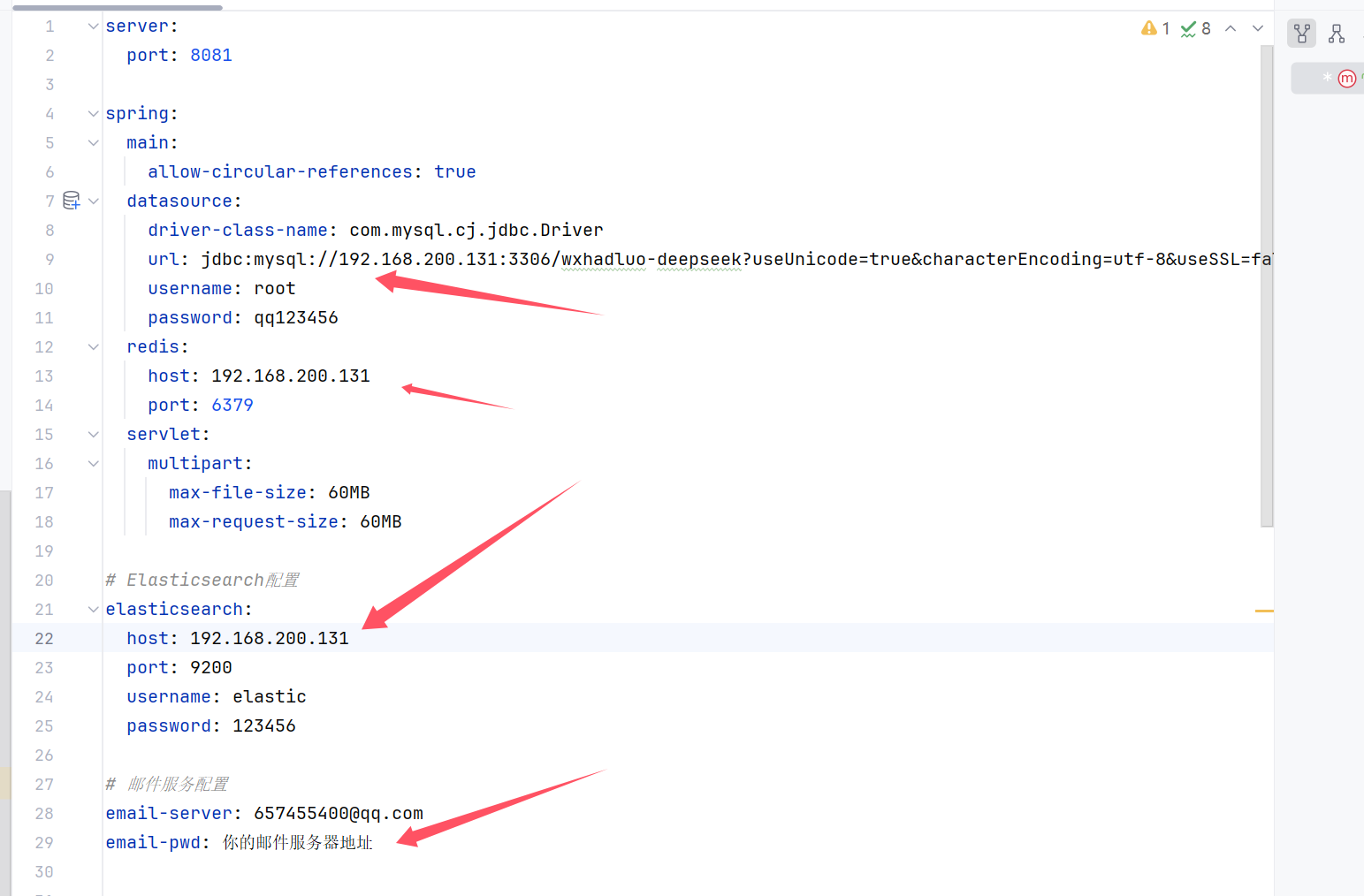
邮件服务器是用来注册 用户的, 因为是通过邮箱注册的。
然后就是几个api key:
然后启动 main 启动类 :DeepSeekApiApplication.class
访问项目
必须登录成功后,才可以使用。
前端:
http://localhost:3010/
账号可以自己注册用户。需要配置好邮箱服务器, 如果没有的,直接往数据库表 user 插入数据也行, 密码直接是明文的就可以。using_doc_id不用填。