php 创建网站开发性价比最高网站建设哪里好
1. 算法概述
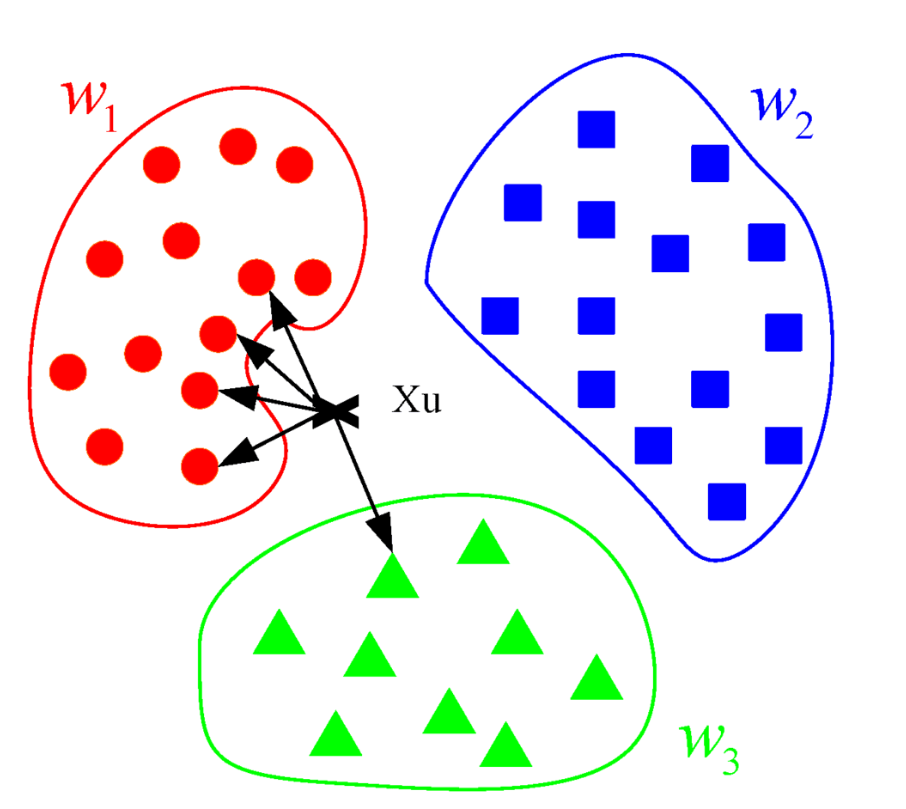
K近邻(K-Nearest Neighbors, KNN)是一种简单而有效的监督学习算法,可用于分类和回归任务。
作为"懒惰学习"的代表性算法,KNN的核心思想是:一个样本的类别或值可以由其周围最近的K个邻居的多数投票或平均值决定。
1.1 基本概念
KNN算法基于以下假设:相似的对象在特征空间中彼此靠近。
算法不显式地学习模型,而是在预测时通过计算待分类样本与训练样本的距离来确定其类别。
1.2 算法特点
-
非参数方法:不对数据分布做任何假设
-
懒惰学习:训练阶段仅存储数据,计算推迟到预测阶段
-
基于实例:直接使用训练实例进行预测
-
简单直观:易于理解和实现
2. 算法原理
2.1 距离度量
KNN算法的关键之一是距离计算,常用的距离度量包括:
-
欧氏距离(Euclidean Distance):
d(x,y) = √Σ(x_i - y_i)² -
曼哈顿距离(Manhattan Distance):
d(x,y) = Σ|x_i - y_i| -
闵可夫斯基距离(Minkowski Distance):
d(x,y) = (Σ|x_i - y_i|^p)^(1/p) -
余弦相似度(Cosine Similarity):
similarity = (x·y) / (||x||·||y||)
2.2 K值选择
K值的选择对算法性能有重要影响:
K值过小:模型复杂,容易过拟合,对噪声敏感
K值过大:模型简单,可能欠拟合,忽略局部特征
通常通过交叉验证来选择最优K值。
2.3 分类决策规则
对于分类问题,通常采用多数投票法:
-
找出测试样本的K个最近邻
-
统计K个邻居中各类别的数量
-
将测试样本归为数量最多的类别
2.4 回归决策规则
对于回归问题,通常采用平均值法:
-
找出测试样本的K个最近邻
-
计算K个邻居目标值的平均值
-
将该平均值作为测试样本的预测值
3. 算法实现步骤
3.1 训练阶段
-
存储训练数据集和对应的标签
3.2 预测阶段
-
计算测试样本与所有训练样本的距离
-
选择距离最近的K个训练样本
-
对于分类问题,统计K个样本的类别投票
-
对于回归问题,计算K个样本目标值的平均
-
返回预测结果
4. 代码实现
下面我们使用Python实现KNN算法,并使用Scikit-learn库进行演示。
4.1 从零实现KNN分类器
import numpy as np
from collections import Counterclass KNNClassifier:def __init__(self, k=5, distance_metric='euclidean'):"""初始化KNN分类器参数:k: int, 邻居数量distance_metric: str, 距离度量方法('euclidean'或'manhattan')"""self.k = kself.distance_metric = distance_metricself.X_train = Noneself.y_train = Nonedef fit(self, X, y):"""训练模型,仅存储数据参数:X: 训练特征,形状(n_samples, n_features)y: 训练标签,形状(n_samples,)"""self.X_train = Xself.y_train = ydef predict(self, X):"""预测新样本的类别参数:X: 测试特征,形状(n_samples, n_features)返回:predictions: 预测类别,形状(n_samples,)"""predictions = [self._predict(x) for x in X]return np.array(predictions)def _predict(self, x):"""预测单个样本的类别参数:x: 单个样本特征返回:预测类别"""# 计算距离if self.distance_metric == 'euclidean':distances = [np.sqrt(np.sum((x - x_train)**2)) for x_train in self.X_train]elif self.distance_metric == 'manhattan':distances = [np.sum(np.abs(x - x_train)) for x_train in self.X_train]else:raise ValueError("不支持的距離度量方法")# 获取最近的k个样本的索引k_indices = np.argsort(distances)[:self.k]# 获取最近的k个样本的标签k_nearest_labels = [self.y_train[i] for i in k_indices]# 多数投票most_common = Counter(k_nearest_labels).most_common(1)return most_common[0][0]def score(self, X, y):"""计算模型准确率参数:X: 测试特征y: 真实标签返回:准确率"""predictions = self.predict(X)return np.mean(predictions == y)4.2 使用Scikit-learn实现KNN
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report, confusion_matrix# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 特征标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 创建KNN分类器
knn = KNeighborsClassifier(n_neighbors=5, metric='euclidean')# 训练模型
knn.fit(X_train, y_train)# 预测
y_pred = knn.predict(X_test)# 评估模型
print("混淆矩阵:")
print(confusion_matrix(y_test, y_pred))
print("\n分类报告:")
print(classification_report(y_test, y_pred))
print("\n准确率:", knn.score(X_test, y_test))
4.3 KNN回归实现
from sklearn.neighbors import KNeighborsRegressor
from sklearn.datasets import load_boston
from sklearn.metrics import mean_squared_error# 加载数据集
boston = load_boston()
X = boston.data
y = boston.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 特征标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 创建KNN回归器
knn_reg = KNeighborsRegressor(n_neighbors=5, metric='euclidean')# 训练模型
knn_reg.fit(X_train, y_train)# 预测
y_pred = knn_reg.predict(X_test)# 评估模型
mse = mean_squared_error(y_test, y_pred)
print("均方误差(MSE):", mse)
print("R^2分数:", knn_reg.score(X_test, y_test))5. 算法优化与技巧
5.1 数据预处理
-
特征缩放:KNN对特征尺度敏感,通常需要标准化或归一化
-
特征选择:去除不相关特征,提高效率和准确性
-
降维:对高维数据使用PCA等方法减少维度
5.2 距离加权
给较近的邻居赋予更大的权重,常见的加权方式:
-
反比权重:weight = 1 / distance
-
高斯权重:weight = exp(-distance² / σ²)
5.3 KD树与球树
对于大数据集,暴力计算距离效率低,可以使用空间分割数据结构:
-
KD树:k维二叉树,适合低维数据(k < 20)
-
球树:将数据递归划分为嵌套超球体,适合高维数据
5.4 参数调优
使用网格搜索和交叉验证寻找最优参数:
from sklearn.model_selection import GridSearchCVparam_grid = {'n_neighbors': range(1, 20),'weights': ['uniform', 'distance'],'metric': ['euclidean', 'manhattan']
}grid_search = GridSearchCV(KNeighborsClassifier(), param_grid, cv=5)
grid_search.fit(X_train, y_train)print("最佳参数:", grid_search.best_params_)
print("最佳分数:", grid_search.best_score_)6. 算法优缺点
6.1 优点
-
简单直观,易于理解和实现
-
无需训练阶段,新数据可以即时加入
-
适用于多分类问题
-
对数据分布没有假设
-
参数少(主要是K值和距离度量)
6.2 缺点
-
计算复杂度高,预测时需要计算所有训练样本的距离
-
对高维数据效果差(维度灾难)
-
对不平衡数据敏感
-
需要合适的距离度量和K值
-
对异常值和噪声敏感
7. 应用场景
KNN算法在以下场景表现良好:
-
简单分类问题:当数据简单、维度低时
-
推荐系统:基于用户或物品的相似度
-
图像识别:简单图像分类任务
-
异常检测:识别与大多数样本距离远的点
-
缺失值填充:用最近邻的值填充缺失数据
8. 总结
K近邻算法是一种基础而强大的机器学习方法,虽然简单但在许多实际问题中表现良好。
理解KNN的工作原理有助于掌握更复杂的算法。
在实际应用中,需要注意数据预处理、距离度量的选择和K值的调优。
对于大规模数据,应考虑使用KD树或球树等优化方法提高效率。
随着数据维度的增加,KNN可能会遇到维度灾难问题,此时可以考虑与其他降维技术结合使用,或转向更复杂的模型。
尽管如此,KNN因其简单性和直观性,仍然是机器学习工具箱中的重要工具。