欧美网站设计欣赏win7系统做网站服务器
我在去年11月份写了pat入理解的上篇,主要介绍patch的原理和代码实现过程。文章发布后很多朋友催更下篇,其实一直在积累素材,因为介绍完原理和实现之后,下一步肯定是要考虑如何改进。在这之前,首先,我们接着上一篇的内容,实现了一个LSTM+patch的例子,结果表明加上Patch之后确实对LSTM在各指标和预测长度上均有明显的效果提升。然后,本篇文章还重点介绍了最近一段时间我读到的对patch的几种改进策略,以及自己的一些思考。
这里再挖个坑吧,下一篇我计划写一下如何在LSTM+Patch的基础上,通过傅立叶进行降噪,并探索实现动态切分patch的方法。欢迎关注~
实现LSTM+Patch
我的这份代码是在Are Transformers Effective for Time Series Forecasting? (AAAI 2023)这篇文章代码的基础上写的。主要在model文件夹添加了LSTM和patch_LSTM两个类,大家复制下面的代码,把文件放入到model文件夹即可运行。此外,为了简化,没有做patch切分时候的补齐。包括hidden_size等一些参数也是直接写到了模型里面,所以严格来说,代码并不是很规范,以实现效果为主。
01 LSTM 代码实现
下面是原始LSTM模型的代码实现,实现过程已经重复过多次,直接看代码,就不在展开细致讲解。
class Model(nn.Module):"""Just one Linear layer"""def __init__(self, configs):super(Model, self).__init__()self.seq_len = configs.seq_lenself.pred_len = configs.pred_lenself.hidden_size = 64self.num_layers = 2self.enc_in = configs.enc_inself.lstm = nn.LSTM(self.enc_in, self.hidden_size, self.num_layers, batch_first=True)self.fc = nn.Linear(self.hidden_size, self.pred_len)self.fc2 = nn.Linear(self.seq_len, self.enc_in)def forward(self, x):# x: [Batch, Input length, Channel]h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device) # 初始化隐藏状态h0c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device) # 初始化记忆状态c0out, _ = self.lstm(x, (h0, c0)) # out:[bs,seq,hid]out = self.fc(out) # out:[bs,seq,pred_len]out = self.fc2(out.permute(0, 2, 1)) # out: [bs, pred_len, channel]return out # [Batch, Output length, Channel]02 LSTM+patch
下面是代码实现的LSTM+patch的实现过程。这里我设置了步长为12、切分长度也为12,这样相当于没有重复的切分。此外,为了简化很多超参数也没有特意调参寻优,我们还是把重点放到patch实现上,特别要关注数据维度的变化:
-
进入forward函数时x的维度: [Batch, seq_len, Channel]
-
置换后两个维度,并用unfold函数切分:[bs, ch, sql]=>[bs, ch, pum, plen],pnum是切分后块的数量。
-
之前讲过,放回到LSTM、Transformer时,数据还是要变回三维,因此这里我们把batch和channel合并到一起,数据维度变成了:[(bs*ch), pnum, plen]
-
此时已经可以放入到模型建模,LSTM输出结果的维度是:[(bs*ch), plen, hidden],然后我们通过线性层和reshape操作,把维度调整回[(bs,pred_len, ch]
代码如下,其实就是维度拆分、合并。另外欢迎大家纠错
class Model(nn.Module):"""Just one Linear layer"""def __init__(self, configs):super(Model, self).__init__()self.seq_len = configs.seq_len #336self.pred_len = configs.pred_lenself.hidden_size = 64self.num_layers = 2self.enc_in = configs.enc_in#patchself.plen = 12self.pnum = 28 # seq_len/plen# LSTM 这里 self.enc_in => self.pnumself.lstm = nn.LSTM(self.pnum, self.hidden_size, self.num_layers, batch_first=True)self.fc = nn.Linear(self.hidden_size, self.pnum)self.fc2 = nn.Linear(self.seq_len, self.pred_len)# self.fc3 = nn.Linear(self.seq_len, self.enc_in)def forward(self, x): # x: [Batch, seq_len, Channel]x_shape = x.size()# patchingif x.size(1) == self.seq_len: # 这里为了简单,就直接定义patch的切分步长为12,不重合,注意336恰好能整除12x = x.permute(0, 2, 1) # [bs, ch, sql]=>[16,21,336]x = x.unfold(dimension=-1, size=12, step=12) # [bs, ch, pum, plen]=>[16,21,28,12]x = torch.reshape(x,(x.shape[0]*x.shape[1], x.shape[2], x.shape[3])) # [(bs*ch), pnum, plen]=>[336,28,12] 相当于原来的[bs, ch, sql]x = x.permute(0, 2, 1)h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device) # 初始化隐藏状态h0c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device) # 初始化记忆状态c0out, _ = self.lstm(x, (h0, c0)) # out:[(bs*ch), plen, hidden]out = self.fc(out)out = torch.reshape(out, (x_shape[0], x_shape[1], -1)) # out: [bs, ch, ()]out = self.fc2(out.permute(0, 2, 1)) # out: []return out.permute(0, 2, 1) # [Batch, Output length, Channel]
下面是我跑的几组实验,验证了在不同的预测长度下,原始LSTM和Patch+LSTM的实验结果对比。首先大家能看到,添加Patch后,各项指标在不同的预测长度上提升都是非常明显的。其次,线性模型比LSTM效果好很多~
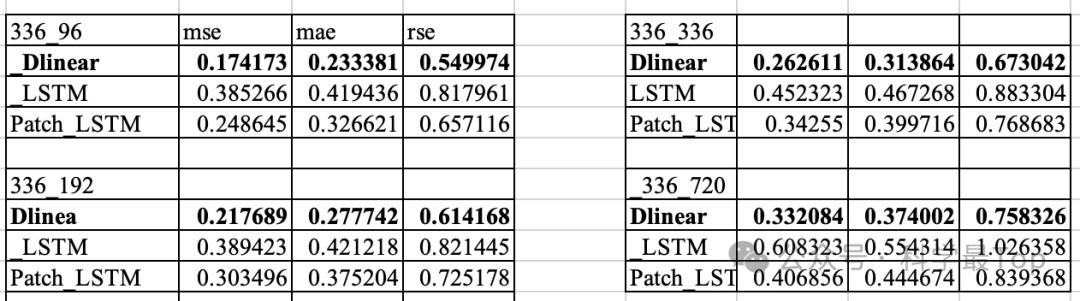
你肯定也能想到现在自己定义patch的长度为12,滑动步长为12,是没有依据的,没错!这些都是可以改进的地方。这就接到下文了,我们来阅读近期三篇对patch的一些改进工作。
原始Patch的不足
还是先回顾一下patch的具体操作,是把一条序列切分成片段,然后按照片段进行建模。好处在于:1、保留更长的前后信息;2、节约transformer计算成本。
那原始的patch是否有不足呢?有的,首先原始patch是对所有的数据集按照相同的片段长度进行切分。但实际情况是不同数据集的采样频率有巨大差距。如下图所示,像汇率数据集、疾病数据集、交通数据集的数据模式显然是不一样的,那么采样频率是分钟的和小时都用同样的长度切显然不合理。
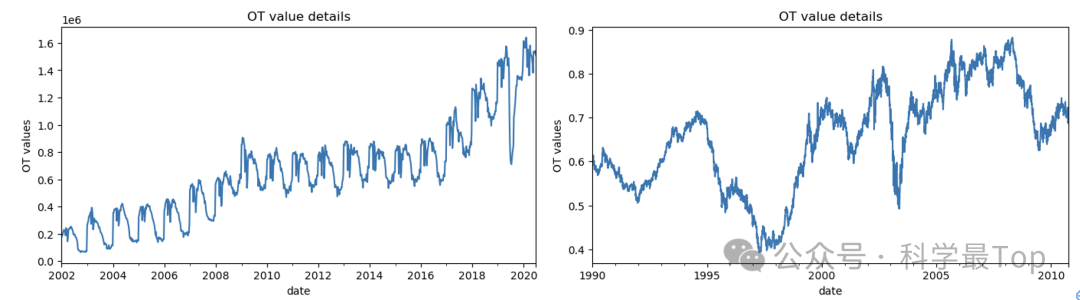
所以对patch的第一种改进策略就是:按照数据集的差异进行动态切分,学术一点的名字就是自适应切分🙂。
对Patch的改进
这里我挑选出三个比较有代表性的改进策略,分别是LPTM、PatchMLP、Medformer。这三个工作
都看到了原始Patch的不足,我们都做过论文解读,感兴趣的可以翻看之前的文章,这里我们逐一看一下他们是怎么做的。
01 LPTM
论文题目:Large Pre-trained time series models for cross-domain Time series analysis tasks(NIPS24)
论文思路如果用一句话来概括那就是暴力枚举,但GitHub代码我没跑通。主要还是学思路。
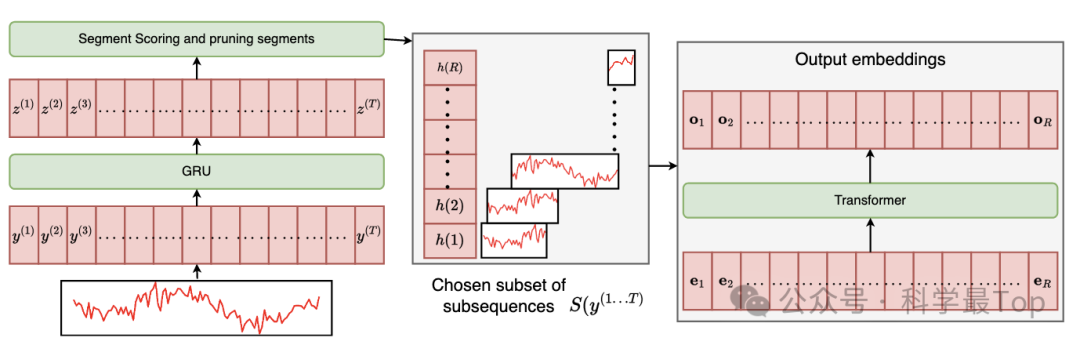

LPTM的patch切分可以分为四个步骤:首先是切分,通过双层循环,枚举从i到j的所有切分方式,切分完之后进行打分;然后,挑选以i为起点的所有片段中,得分最高的片段;这样做能保证序列是连续的,但带来一个问题,切分的片段大概率是有重复的。所以接着从上步得到的序列集合中,逐个剔除评分最低的片段,直到集合不连续。最后,通过注意力机制解决序列不连续的问题。
这里有个问题其实论文是有所回避的,模型变量间是否应该建模,既是通道独立还是通道依赖,这个问题在下一篇论文会给出一个方案。
02 PatchMLP
论文题目:Unlocking the Power of Patch: Patch-Based MLP for Long-Term Time Series Forecasting(AAAI25)

Patch+MLP这个思路估计很多人都想到过,但本文做了两点创新,其一是通过滑动平均来提取平滑分量和含有噪声的残差。请注意,无论是滑动平均还是傅立叶变换去噪声,很多论文的结果都表明去噪声确实是一种加点的方法,如果自己模型提点到了瓶颈,不妨试一下去噪声😊。
其二就是多尺度、跨通道的patch切分和嵌入方法。对于特定的尺度 p∈P,时间序列首先被分割成非重叠的patch,每个patch的长度对应于 p。这种分割过程生成了patch序列 x_p∈R^(N×p),其中 N 是patch的数量。切分完成后,在进行线性嵌入,每个patch序列 x_p通过单层线性层进行嵌入,生成潜在向量 x_e∈R^(N×d),其中 d 是嵌入维度,不同尺度的patch可以有不同的嵌入维度。最后,展开这些潜在向量获得最终的嵌入向量 X∈R^(1×d_model) ,其中 d_model是输入模型的最终嵌入维度。以上策略允许模型在不同时间跨度上灵活学习代表性的特征,从而提高预测的准确性和模型的泛化能力。
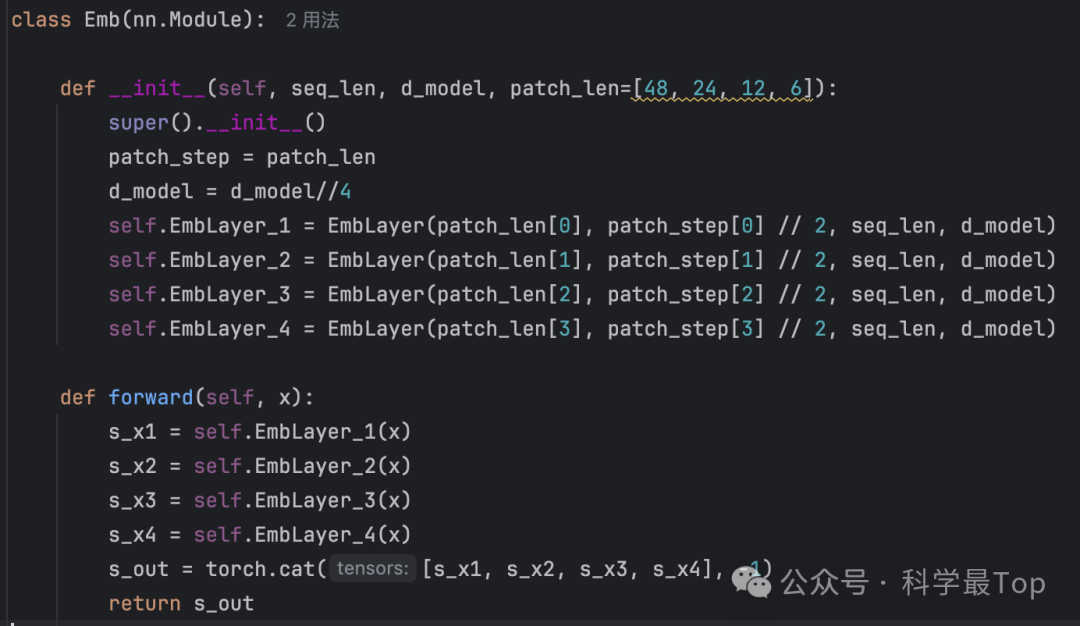
看核心代码,默认的尺度是[48,24,12,6],其实这个粒度的选择本身就有问题,枚举太暴力,但本文这样定义好像也没有依据。
03 Medformer
论文题目:Medformer: A Multi-Granularity Patching Transformer for Medical Time-Series Classification
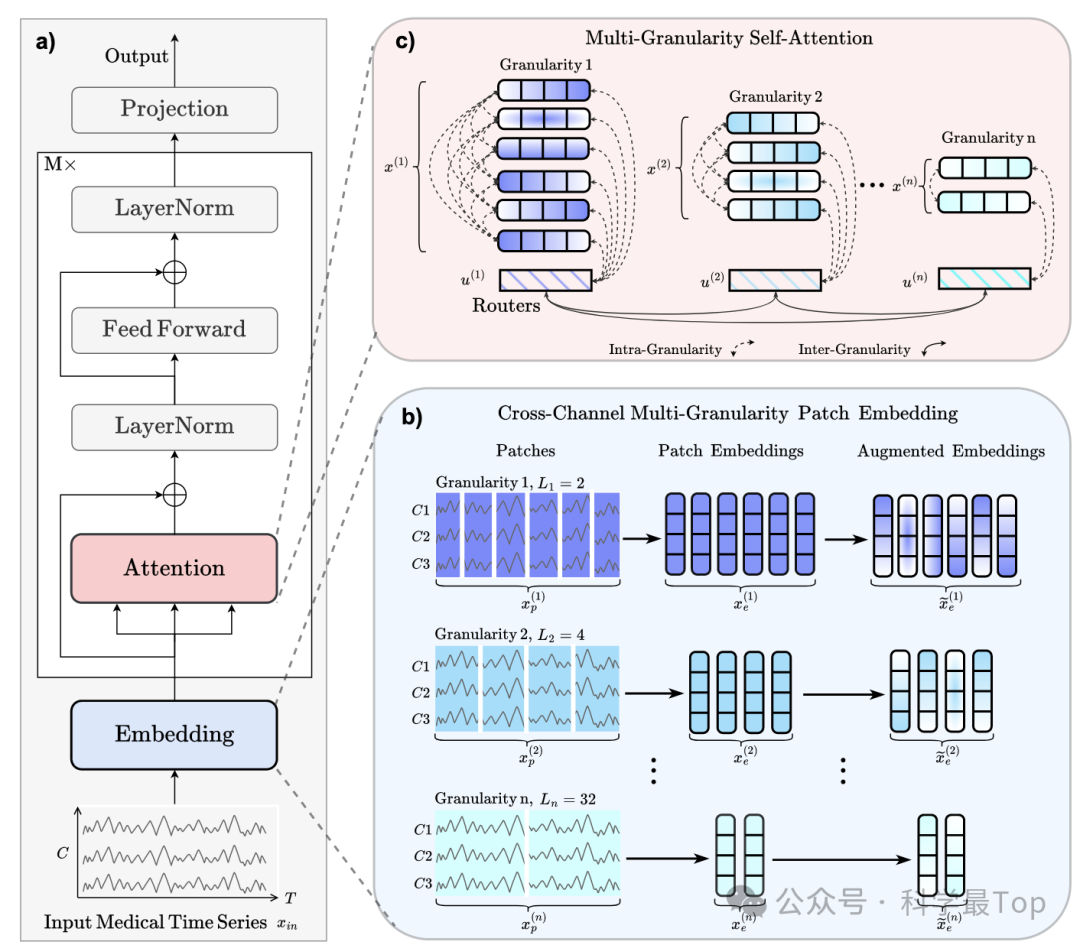
还是先看论文做patch的思路,大体来说就是跨通道多粒度patch切分,然后通过注意力机制融合。
首先,使用跨通道patch嵌入来有效捕捉多时间戳和跨通道特征。将多变量时间序列样本分割成多个跨通道的非重叠patch片段,这些patch被映射到潜在嵌入空间并进行数据增强。公式如下:
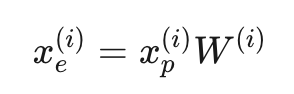
其实还是做线性投影,注意这里的最大的不同就是跨通道。
其次,采用多粒度patch嵌入而不是固定长度,使模型能够以不同尺度捕捉通道特征。每个patch长度代表一个独特的粒度,多粒度patch嵌入自动对应不同的采样频率,从而模拟不同的频带并捕捉特定频带的特征。
最后,引入了两级多粒度自注意力机制,分别进行粒内自注意力和粒间自注意力。粒内自注意力在同一粒度内捕捉特征,而粒间自注意力在不同粒度之间捕捉相关性。
不过简单翻看了代码,发现还是依赖于自定义的粒度。
个人理解
从Patch TST出来有快两年了,围绕patch的改进工作有很多,用一位好友的话说现在的改进与实现并不够“优雅”。你会发现实际上模型并不能做到自适应的进行patch切分。多数模型依赖于枚举、自定义的方式实现。因此作者认为围绕Patch的改进仍然有改进空间。挖个坑,下一篇准备在LSTM+Patch的基础上,通过傅立叶进行降噪,并探索实现动态切分patch的方法。欢迎关注~
欢迎大家加入科学最TOP的知识星球,星球创办初期价格最优惠,目前更新的LSTM入门的系列文章,适配入门学习,均提供完整代码!)

(后台回复“交流”加入讨论群,回复“资源”获取2024年度论文讲解合集)