企业做网站有用吗天涯中国今天最新军事新闻
🌈 嗨,我是青松,很高兴遇到你!
🌟 希望用我的经验,让每个人的AI学习之路走的更容易些~
🔥 专栏:大模型(LLMs)高频面题全面整理(★2025最新版★)
目录
一、Streamlit 简介
二、构建应用程序
三、添加检索问答
四、部署应用程序
正文涉及到的源文件可从如下路径获取:
- streamlit_app.py
我们对知识库和LLM已经有了基本的理解,现在是时候将它们巧妙地融合并打造成一个富有视觉效果的界面了。这样的界面不仅对操作更加便捷,还能便于与他人分享。
Streamlit 是一种快速便捷的方法,可以直接在 Python 中通过友好的 Web 界面演示机器学习模型。在本课程中,我们将学习如何使用它为生成式人工智能应用程序构建用户界面。在构建了机器学习模型后,如果你想构建一个 demo 给其他人看,也许是为了获得反馈并推动系统的改进,或者只是因为你觉得这个系统很酷,所以想演示一下:Streamlit 可以让您通过 Python 接口程序快速实现这一目标,而无需编写任何前端、网页或 JavaScript 代码。
一、Streamlit 简介
Streamlit 是一个用于快速创建数据应用程序的开源 Python 库。它的设计目标是让数据科学家能够轻松地将数据分析和机器学习模型转化为具有交互性的 Web 应用程序,而无需深入了解 Web 开发。和常规 Web 框架,如 Flask/Django 的不同之处在于,它不需要你去编写任何客户端代码(HTML/CSS/JS),只需要编写普通的 Python 模块,就可以在很短的时间内创建美观并具备高度交互性的界面,从而快速生成数据分析或者机器学习的结果;另一方面,和那些只能通过拖拽生成的工具也不同的是,你仍然具有对代码的完整控制权。
Streamlit 提供了一组简单而强大的基础模块,用于构建数据应用程序:
-
st.write():这是最基本的模块之一,用于在应用程序中呈现文本、图像、表格等内容。
-
st.title()、st.header()、st.subheader():这些模块用于添加标题、子标题和分组标题,以组织应用程序的布局。
-
st.text()、st.markdown():用于添加文本内容,支持 Markdown 语法。
-
st.image():用于添加图像到应用程序中。
-
st.dataframe():用于呈现 Pandas 数据框。
-
st.table():用于呈现简单的数据表格。
-
st.pyplot()、st.altair_chart()、st.plotly_chart():用于呈现 Matplotlib、Altair 或 Plotly 绘制的图表。
-
st.selectbox()、st.multiselect()、st.slider()、st.text_input():用于添加交互式小部件,允许用户在应用程序中进行选择、输入或滑动操作。
-
st.button()、st.checkbox()、st.radio():用于添加按钮、复选框和单选按钮,以触发特定的操作。
这些基础模块使得通过 Streamlit 能够轻松地构建交互式数据应用程序,并且在使用时可以根据需要进行组合和定制,更多内容请查看官方文档
二、构建应用程序
首先,创建一个新的 Python 文件并将其保存 streamlit_app.py在工作目录的根目录中
- 导入必要的 Python 库。
import streamlit as st
from langchain_openai import ChatOpenAICopy to clipboardErrorCopied- 创建应用程序的标题
st.title
st.title('🦜🔗 动手学大模型应用开发')Copy to clipboardErrorCopied- 添加一个文本输入框,供用户输入其 OpenAI API 密钥
openai_api_key = st.sidebar.text_input('OpenAI API Key', type='password')Copy to clipboardErrorCopied- 定义一个函数,使用用户密钥对 OpenAI API 进行身份验证、发送提示并获取 AI 生成的响应。该函数接受用户的提示作为参数,并使用
st.info来在蓝色框中显示 AI 生成的响应
def generate_response(input_text):llm = ChatOpenAI(temperature=0.7, openai_api_key=openai_api_key)st.info(llm(input_text))Copy to clipboardErrorCopied- 最后,使用
st.form()创建一个文本框(st.text_area())供用户输入。当用户单击Submit时,generate-response()将使用用户的输入作为参数来调用该函数
with st.form('my_form'):text = st.text_area('Enter text:', 'What are the three key pieces of advice for learning how to code?')submitted = st.form_submit_button('Submit')if not openai_api_key.startswith('sk-'):st.warning('Please enter your OpenAI API key!', icon='⚠')if submitted and openai_api_key.startswith('sk-'):generate_response(text)Copy to clipboardErrorCopied-
保存当前的文件
streamlit_app.py! -
返回计算机的终端以运行该应用程序
streamlit run streamlit_app.pyCopy to clipboardErrorCopied结果展示如下:
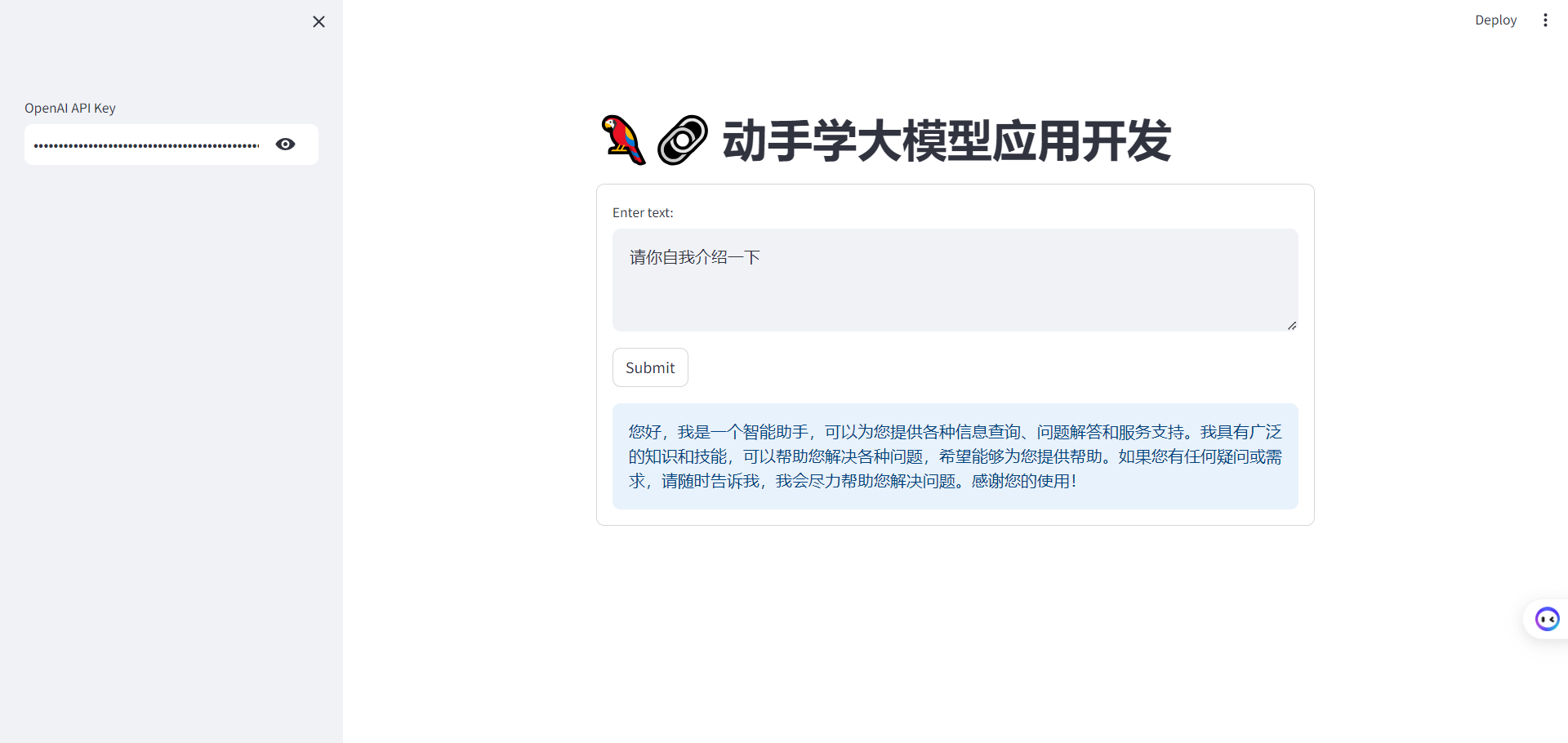
但是当前只能进行单轮对话,我们对上述做些修改,通过使用 st.session_state 来存储对话历史,可以在用户与应用程序交互时保留整个对话的上下文。
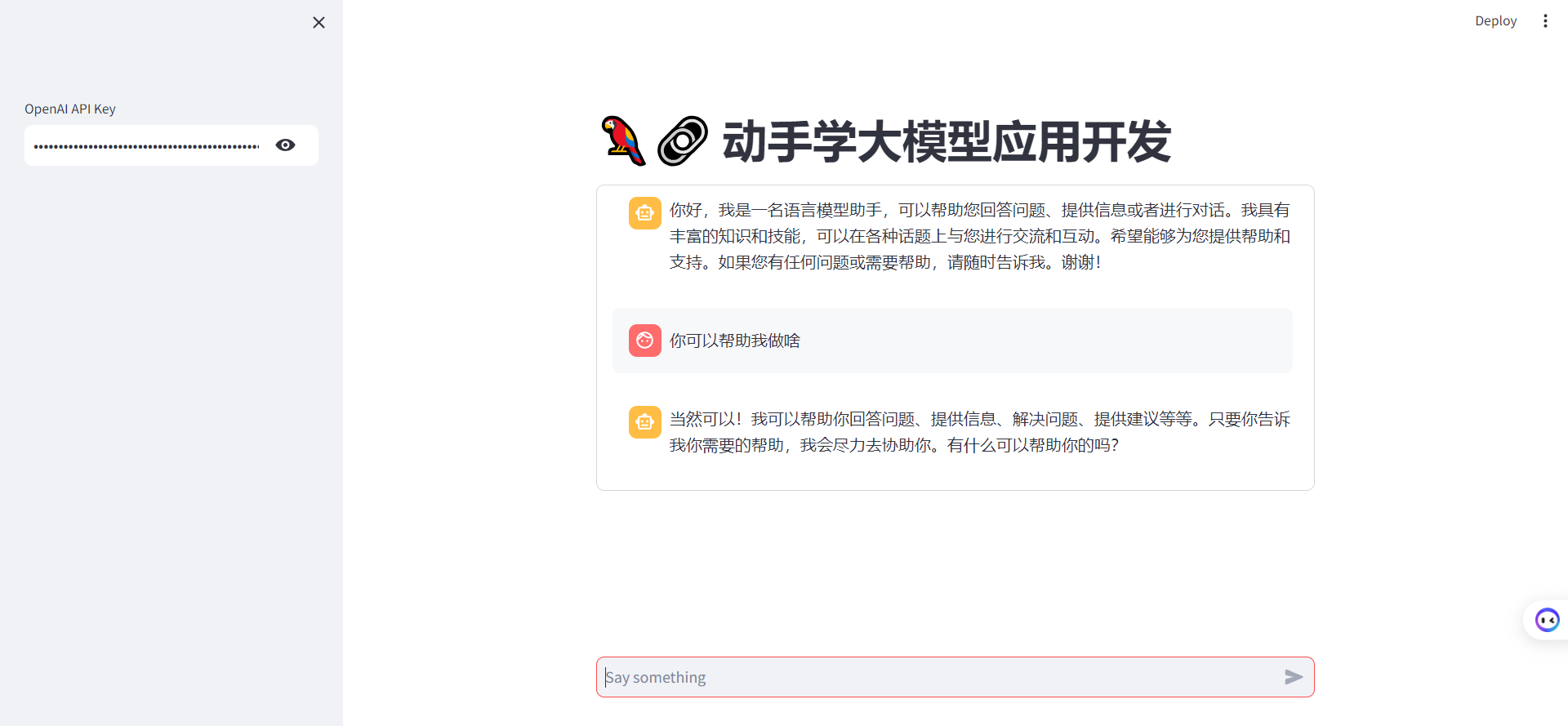
具体代码如下:
# Streamlit 应用程序界面
def main():st.title('🦜🔗 动手学大模型应用开发')openai_api_key = st.sidebar.text_input('OpenAI API Key', type='password')# 用于跟踪对话历史if 'messages' not in st.session_state:st.session_state.messages = []messages = st.container(height=300)if prompt := st.chat_input("Say something"):# 将用户输入添加到对话历史中st.session_state.messages.append({"role": "user", "text": prompt})# 调用 respond 函数获取回答answer = generate_response(prompt, openai_api_key)# 检查回答是否为 Noneif answer is not None:# 将LLM的回答添加到对话历史中st.session_state.messages.append({"role": "assistant", "text": answer})# 显示整个对话历史for message in st.session_state.messages:if message["role"] == "user":messages.chat_message("user").write(message["text"])elif message["role"] == "assistant":messages.chat_message("assistant").write(message["text"]) Copy to clipboardErrorCopied三、添加检索问答
先将2.构建检索问答链部分的代码进行封装:
- get_vectordb函数返回C3部分持久化后的向量知识库
- get_chat_qa_chain函数返回调用带有历史记录的检索问答链后的结果
- get_qa_chain函数返回调用不带有历史记录的检索问答链后的结果
def get_vectordb():# 定义 Embeddingsembedding = ZhipuAIEmbeddings()# 向量数据库持久化路径persist_directory = '../C3 搭建知识库/data_base/vector_db/chroma'# 加载数据库vectordb = Chroma(persist_directory=persist_directory, # 允许我们将persist_directory目录保存到磁盘上embedding_function=embedding)return vectordb#带有历史记录的问答链
def get_chat_qa_chain(question:str,openai_api_key:str):vectordb = get_vectordb()llm = ChatOpenAI(model_name = "gpt-3.5-turbo", temperature = 0,openai_api_key = openai_api_key)memory = ConversationBufferMemory(memory_key="chat_history", # 与 prompt 的输入变量保持一致。return_messages=True # 将以消息列表的形式返回聊天记录,而不是单个字符串)retriever=vectordb.as_retriever()qa = ConversationalRetrievalChain.from_llm(llm,retriever=retriever,memory=memory)result = qa({"question": question})return result['answer']#不带历史记录的问答链
def get_qa_chain(question:str,openai_api_key:str):vectordb = get_vectordb()llm = ChatOpenAI(model_name = "gpt-3.5-turbo", temperature = 0,openai_api_key = openai_api_key)template = """使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答案。最多使用三句话。尽量使答案简明扼要。总是在回答的最后说“谢谢你的提问!”。{context}问题: {question}"""QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],template=template)qa_chain = RetrievalQA.from_chain_type(llm,retriever=vectordb.as_retriever(),return_source_documents=True,chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})result = qa_chain({"query": question})return result["result"]Copy to clipboardErrorCopied然后,添加一个单选按钮部件st.radio,选择进行问答的模式:
- None:不使用检索问答的普通模式
- qa_chain:不带历史记录的检索问答模式
- chat_qa_chain:带历史记录的检索问答模式
selected_method = st.radio("你想选择哪种模式进行对话?",["None", "qa_chain", "chat_qa_chain"],captions = ["不使用检索问答的普通模式", "不带历史记录的检索问答模式", "带历史记录的检索问答模式"])Copy to clipboardErrorCopied最终的效果如下:
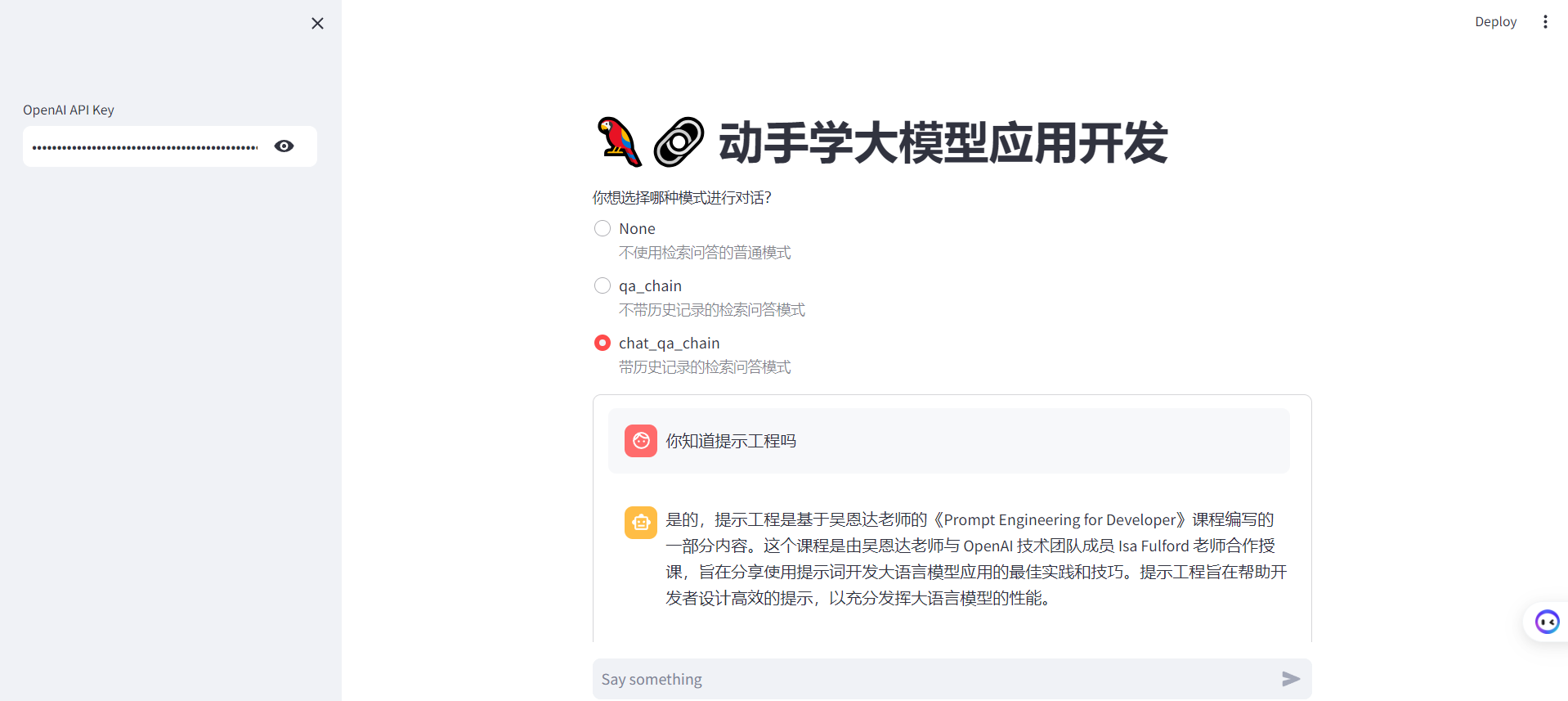
进入页面,首先先输入OPEN_API_KEY(默认),然后点击单选按钮选择进行问答的模式,最后在输入框输入你的问题,按下回车即可!
完整代码参考streamlit_app.py
四、部署应用程序
要将应用程序部署到 Streamlit Cloud,请执行以下步骤:
-
为应用程序创建 GitHub 存储库。您的存储库应包含两个文件:
your-repository/
├── streamlit_app.py
└── requirements.txt -
转到 Streamlit Community Cloud,单击工作区中的
New app按钮,然后指定存储库、分支和主文件路径。或者,您可以通过选择自定义子域来自定义应用程序的 URL -
点击
Deploy!按钮
您的应用程序现在将部署到 Streamlit Community Cloud,并且可以从世界各地访问! 🌎
我们的项目部署到这基本完成,为了方便进行演示进行了简化,还有很多可以进一步优化的地方,期待学习者们进行各种魔改!
优化方向:
- 界面中添加上传本地文档,建立向量数据库的功能
- 添加多种LLM 与 embedding方法选择的按钮
- 添加修改参数的按钮
- 更多......