网站建设 爱诚科技公司wordpress 鼠标跟随
1. 概念区分
1.1 预训练
预训练是大模型训练流程的初始阶段,模型通过在大规模语料库上学习,掌握基本的语法规则、逻辑推理能力以及常识知识。目标是使模型具备语言理解能力、逻辑推理能力以及常识知识,可以参考《GPT系列预训练模型原理讲解》、《从零构建基座大模型项目》。
1.2 监督微调
监督微调是对预训练模型的进一步优化,使其在特定领域(如对话和问答场景)中表现更佳。目标是提升模型在输出形式和内容上的表现。比如使模型能够专业地回答用户特定领域(如电商)的问题,可以参考《大模型微调之指令微调》、《LLaMA Factory微调ChatGLM-4-9B模型》。
1.3 偏好优化
监督微调后的模型可能会生成语法正确但不符合事实或人类价值观的回复。偏好优化(PO)是为了进一步提升模型的对话能力,并使其与人类价值观对齐。主要方法包括基于强化学习的 PPO(Proximal Policy Optimization)和直接优化语言模型的 DPO(Direct Preference Optimization)。DPO 采用隐式的强化学习范式,无需显性奖励模型,也不直接最大化奖励值,因此在训练过程中比 PPO 更加稳定,可以参考《大模型中的强化学习RLHF(PPO)、DPO(Direct Preference Optimization)等概念的理解与解析》。
1.4 直接偏好优化
DPO 模型由两个核心组件构成:
待训练的大型语言模型(LLM):这是需要优化的模型。
参考模型:用于防止模型偏离预期目标。参考模型是一个经过微调的大型语言模型,但其参数被冻结,不会在训练过程中更新。
训练数据格式:三元组(prompt,chosen(优质结果),rejected(劣质结果))。
损失函数:
DPO 的目标是使模型在优质结果上生成的概率高于参考模型,同时在劣质结果上生成的概率低于参考模型。损失函数公式如下:
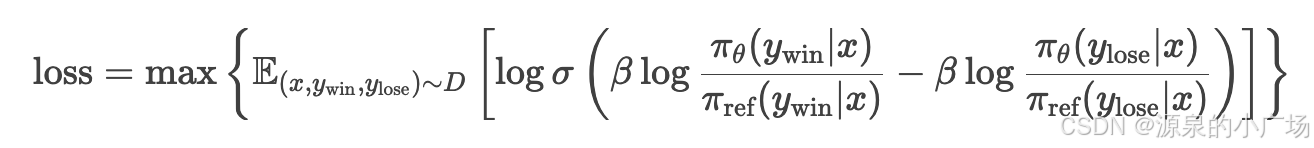
其中:
-
σ 是 Sigmoid 函数,用于将结果映射到 (0, 1) 范围内。
-
β 是一个超参数,通常取值在 0.1 到 0.5 之间,用于调整损失函数的敏感度。
1.5 参数高效微调技术
参数高效微调技术(PEFT)应用于微调大型预训练模型。其核心思想是在保持大部分模型参数不变的情况下,仅通过微调少量参数来实现高性能。由于需要更新的参数量较少,所需的数据和计算资源也相应减少,从而提高了微调效率。 LoRA 和 QLoRA 是两种高效微调技术,可以参考《大模型局限性之DeepSeek V3/R1的行业微调方案》:
1.5.1 LoRA(Low-Rank Adaptation)
LoRA 技术通过在模型的参数矩阵(例如 m×n 维)旁新增一条旁路来实现微调。这条旁路由两个低秩矩阵(m×r 和 r×n 维,其中 r 远小于 m 和 n)相乘而成。在前向传播过程中,输入数据同时通过原始参数矩阵和 LoRA 旁路,输出结果相加。训练过程中,原始参数被冻结,仅对 LoRA 部分进行训练。由于 LoRA 部分由两个低秩矩阵构成,其参数量远小于原始矩阵,因此显著减少了训练的计算开销。
1.5.2 QLoRA(Quantized LoRA)
QLoRA 结合了模型量化和 LoRA 技术。除了引入 LoRA 旁路外,QLoRA 在加载时将大模型量化为 4bit 或 8bit。在实际计算时,这些量化的参数会被反量化为 16bit 进行处理。这种方法不仅优化了模型参数的存储需求,还在与 LoRA 相比时进一步降低了训练过程中的显存消耗。
2. 一些分享
2.1 增量预训练
数据量级与效果
通常情况下,纯文本数据量需达到 4GB 以上,模型才能较好地收敛,并带来显著的性能提升(4% 以上)。
在较小数据规模(600MB-1GB)下,使用较小的学习率(5e-7)仍然可以实现收敛,但效果提升相对有限(约 1%)。
模型收敛判断
如果 Loss 从初始值下降至 0.5 以下,表明模型学习到了“新知识”并实现收敛。
Loss 最终稳定在某个值,并且不再出现明显抖动,即可视为收敛。
不收敛的优化策略
数据清洗:排除无意义的换行符或符号,减少其对模型增量预训练的干扰。
数据筛选:基于知识有用性策略,采用 few-shot 方式输入大模型,评估其在业务测试数据上的提升情况。
超参数调整:尝试优化学习率、batch size 等参数。
数据扩充:
通过筛选领域相关关键词,混合通用数据以增加数据量。
利用大模型进行上采样,合成新数据以增强训练数据集。
2.2 SFT 微调
2.2.1 数据质量评价标准
标注数据质量评估主要从以下维度进行考量:
一致性
关注模型回答是否能准确理解问题意图,而非答案本身的正确性。
判断方法:
若用户阅读回复后,能清晰理解其意图,则满足一致性。
若用户阅读回复后,感到“回复与指令无关”或“未完全满足提问要求”,则不满足一致性。
除翻译场景外,若问题与回答的语言不一致,则不满足一致性。
若回答虽涵盖提问内容,但额外扩展了未提及的内容,可依据标注规则对得分进行扣减。
正确性
评估答案内容本身是否正确,不考虑提问内容。
判断方法:
若凭借常识可判断回答存在错误,则不满足正确性。
若能确定回答无任何事实性错误,则满足正确性。
若回答存在前后矛盾、逻辑不自洽,则不满足正确性。
有帮助性
站在用户角度评估答案是否具有实用价值。
判断方法:
若答案能够清晰、直接地解决用户问题,则满足有帮助性。
若答案虽然正确,但未能真正解决问题(如泛泛而谈的正确废话),则不满足有帮助性。
2.2.2 学习率
决定模型在每次迭代中参数更新的幅度。
较大学习率:加快训练速度,但可能导致参数更新过度,影响收敛。
较小学习率:提供稳定的收敛过程,但训练时间较长,可能陷入局部最优。
优化策略:使用 AdamW 优化器可有效缓解长期不收敛问题。
2.2.3 训练轮数
一个 epoch 代表对整个训练数据集的一次完整遍历。
推荐范围:2~10 轮。
样本量少:可增加 epoch 避免欠拟合。
样本量大:通常 2 轮即可,一般我选择3轮基本能出一个可以接受的效果。
调整策略:
学习率较小时,通常需要更多的 epochs。
通过观察验证集准确率变化,当其趋于稳定时可终止训练。
2.2.4 batchsize的影响
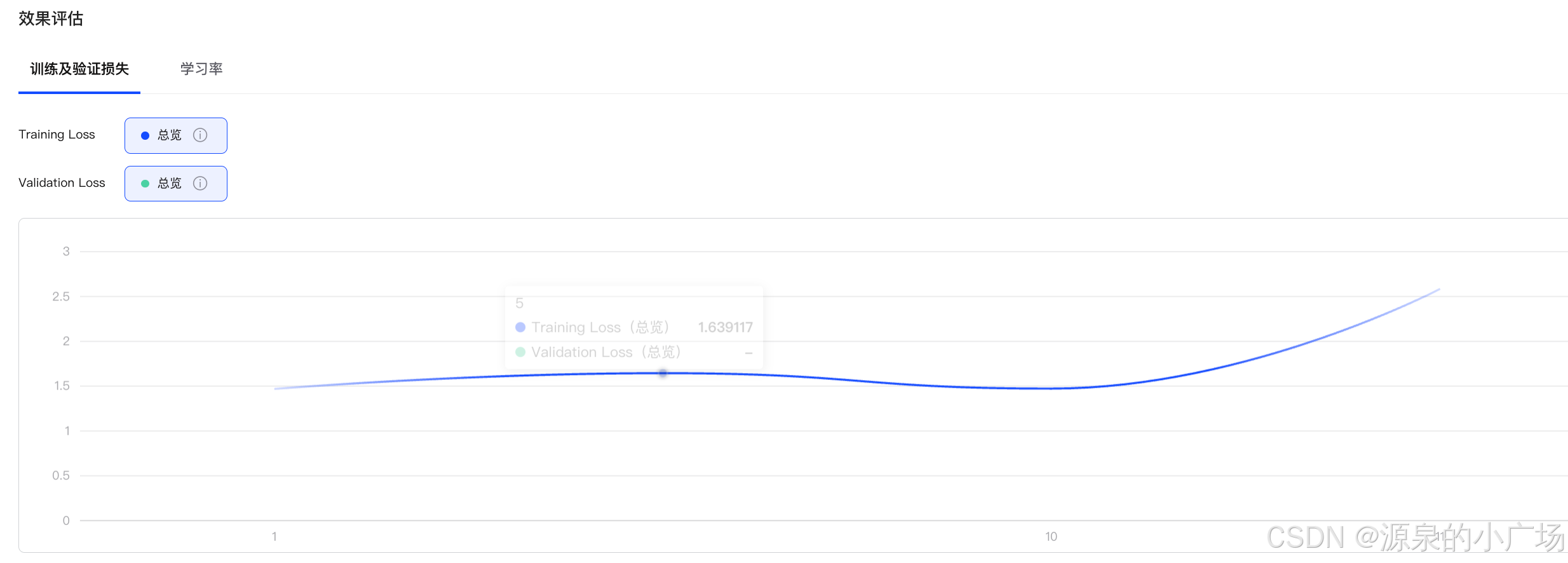
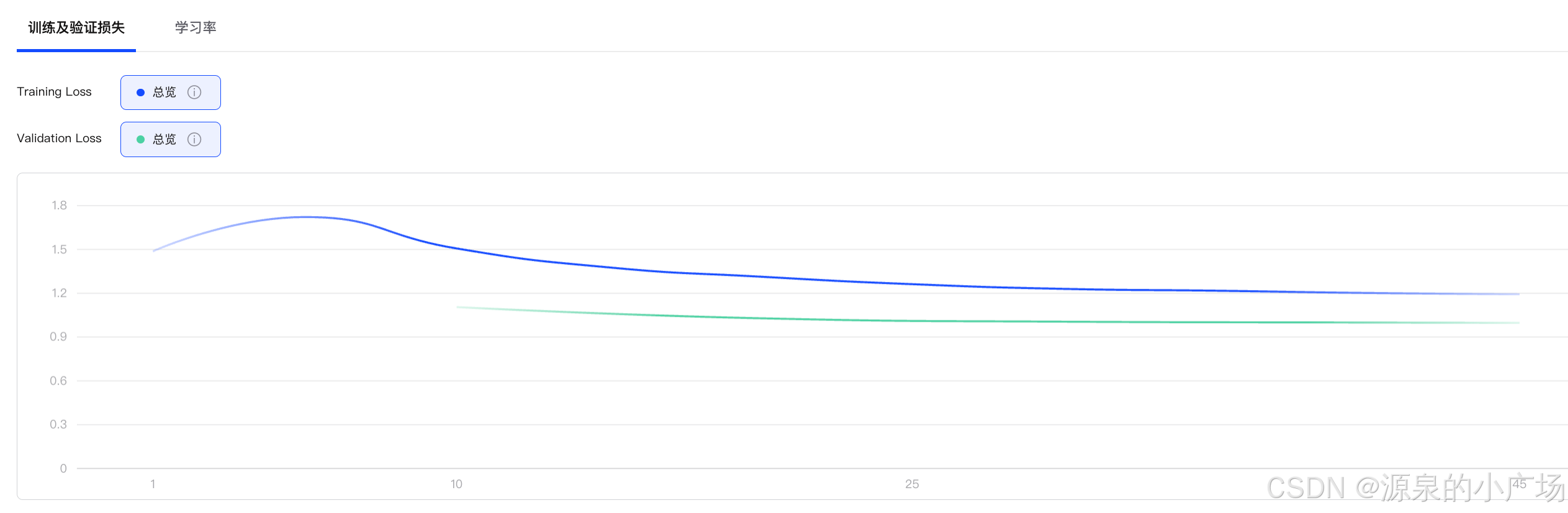
之前在做R1数据微调蒸馏实验《利用DeepSeek-R1数据微调蒸馏ChatGLM32B让大模型具备思考能力》,batchsize的设置存在一定的影响,因为采用的全参微调,并且epoch设置为3,迭代的轮次是比较少的,因此,如果batchsize设置为64时,训练的loss就训飞了,后来改成batchsize为16,训练能够收敛。
batchsize为64时:
batchsize调整为16时:
当然batchsize不能单独来对待,需要结合epoch、learning rate一起来设置。
Batch Size 与 Epoch 的协同影响:
在训练过程中,batch size 不能孤立调整,而需要与 epoch 结合考虑,特别是在 epoch 设定较少 时,batch size 过大会导致训练轮次不足,影响模型收敛。
1. Epoch 少时,Batch Size 过大会影响收敛
训练的总步数(iterations)由
total_steps = (数据量 / batch size) * epoch计算。若 epoch 设定较少(如 3),batch size 过大会减少总训练步数,使得模型尚未充分学习就结束训练,导致收敛不足。
适当 减小 batch size 可以增加训练轮次,使模型有更多机会学习数据模式,从而提高收敛效果。
2. 训练收敛性
较小 batch size(如 16):能使梯度更新更频繁,提升训练的有效轮次,有助于在少 epoch 情况下提高收敛程度。
较大 batch size(如 64):单次更新更稳定,但若 epoch 过少,训练可能尚未充分优化就终止,导致 loss 未能收敛。
3. 计算效率 vs. 模型效果
大 batch size 虽然可以提高单个 epoch 内的训练吞吐量,但如果 epoch 设定较少,容易导致过早终止训练,影响最终性能。
小 batch size 需要更多的梯度更新,训练时间可能增加,但在 epoch 受限的情况下更有利于最终收敛。
4. 调整策略
若 epoch 较少(如 3),推荐适当 降低 batch size(如 16),确保总训练步数足够,使模型能充分学习数据特征。
若 batch size 过大(如 64),可以 适当增加 epoch,避免模型因训练步数不足而未收敛。
3. 参考材料
【1】大语言模型微调指引