做租车行网站做公司网站需要多少钱
前言
笔者曾经开发过一个可以对笑话浏览、收藏、分类、编辑上传的小工具(笔者开发后台,另外一个朋友负责小程序前台开发),如今所租用的服务器到期了,特此记录一下。
数据层
部署数据库
# 拉取Mysql镜像
docker pull mysql:8.0.33# 运行Mysql容器
docker run -d --name mysql-container -p 33333:3306 -e MYSQL_ROOT_PASSWORD="root_password" mysql:8.0.33# 访问Mysql
mysql -h 127.0.0.1 -P 33333 -u root -p创建表结构
create table joke
(id int auto_increment primary key,joke_title varchar(32) null,joke_text varchar(1200) not null,joke_author varchar(30) default 'system' null,time_update datetime(6) null,open_flag int default 0 not null, // 是否公开joke_type varchar(20) null, // 笑话类型path_image varchar(255) null // 配图路径
);create table joke_user_like
(id int auto_increment primary key,user_id varchar(100) not null,user_like int not null, // "1"代表是用户喜欢的,"2"代表是不喜欢的time_update datetime(6) not null,joke_id int not null
);导入数据
1、从互联网上crawl 3000条笑话文本
2、将笑话导入进数据库
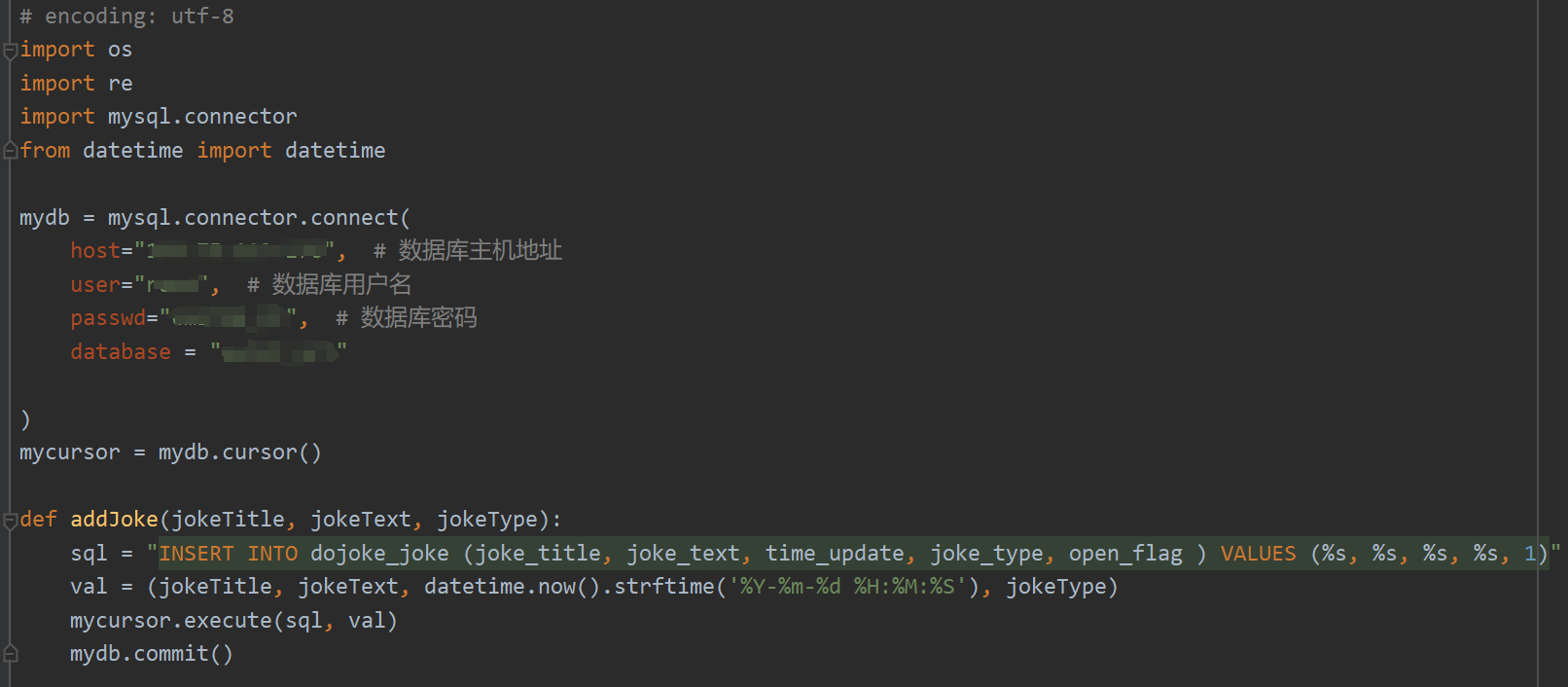
完成用户故事
随机返回一条笑话
用redis记录用户已经浏览过的笑话,用mysql记录用户“不喜欢”的。可选jokeId列表将剔除这两部分。
@api_view(['POST'])
def getOneJoke(request):return_data = {"state": 200, "message": "查询成功"}data = {}# 供随机抽取jokeId列表jokeIds = []try:data_json = loads(request.body)userId = data_json.get("userId", "")jokeType = data_json.get("jokeType", "")# 获得所有JokeIdglobal idList# 当浏览完全部笑话的时间,清空redis里的“已浏览”列表usedJokeList = redisJoke.lrange(userId, 0, -1)if len(idList) == len(usedJokeList):redisJoke.delete(userId)usedJokeList = np.array(usedJokeList).astype(dtype=int).tolist()#判断是否有携带笑话类型if jokeType == '':# 去除用户浏览过的笑话jokeIds = list(set(idList) - set(usedJokeList))else:jokeIds = jokeDao.getJokeIdsByType(jokeType)# 去除用户浏览过的笑话jokeIdsEx = list(set(jokeIds) - set(usedJokeList))if len(jokeIdsEx) > 0:jokeIds = jokeIdsEx# 去除用户不感兴趣的JokeIddisLikeList = jokeDao.getLikedJokeIds(userId, 2)jokeIds = list(set(jokeIds) - set(disLikeList))# 得到一个随机的JokeIdjokeId = random.sample(jokeIds, 1)oneJoke = jokeDao.getJokeById(jokeId[0])likeFlag = jokeDao.getLikeFlag(userId, jokeId[0])# 加入浏览记录redisJoke.rpush(userId, jokeId[0])data["jokeId"] = oneJoke.iddata["jokeTitle"] = oneJoke.joke_titledata["jokeText"] = oneJoke.joke_textdata["jokeImage"] = imageUtil.imageTobase64(oneJoke.path_image)data["likeFlag"] = likeFlagreturn_data["data"] = dataexcept Exception as e:print(e)print(sys._getframe().f_lineno, 'traceback.print_exc():', traceback.print_exc())return_data["state"] = 500return_data["message"] = "查询失败"return HttpResponse(dumps(return_data, ensure_ascii=False, default=lambda obj: obj.__dict__))实现分类选择
@api_view(['POST'])
def getJokeType(request):return_data = {"state": 200, "message": "查询成功"}data = []try:data = jokeDao.getJokeTypes()return_data["data"] = dataexcept Exception as e:print(e)print(sys._getframe().f_lineno, 'traceback.print_exc():', traceback.print_exc())traceback.print_exc()return_data["state"] = 500return_data["message"] = "查询失败"#logger.info("查询机器人失败,异常信息为" + str(e))return HttpResponse(dumps(return_data, ensure_ascii=False, default=lambda obj: obj.__dict__))def getJokeTypes():jokeTypeList = []jokeTypes = Joke.objects.values("joke_type").distinct()for jokeType in jokeTypes:jokeTypeList.append(jokeType["joke_type"])return jokeTypeList
实现上传笑话
@api_view(['POST'])
def uploadOneJoke(request):return_data = {"state": 200, "message": "上传成功"}data = {}oneJoke = Joke()try:data_json = loads(request.body)jokeAuthor = data_json.get("userId", "")jokeTitle = data_json.get("jokeTitle", "")jokeText = data_json.get("jokeText", "")jokeImage = data_json.get("jokeImage", "")jokeImageType = data_json.get("jokeImageType", "jpg")if jokeImage != "":dirImage = os.path.join(IMAGE_PATH, jokeAuthor)pathImage = os.path.join(IMAGE_PATH, jokeAuthor, timeUtil.getCurrentTime() + "." + jokeImageType)dirImagePath = Path(dirImage)# 如果目录不存在,新建目录if dirImagePath.is_dir() == False:os.mkdir(dirImagePath)imageUtil.base64ToImage(pathImage, jokeImage)oneJoke.path_image = pathImage# 将笑话信息保存至数据库oneJoke.joke_author = jokeAuthoroneJoke.joke_title = jokeTitleoneJoke.joke_text = jokeTextret = jokeDao.addOneJoke(oneJoke)jokeId = ret.id# 上传的笑话自动加入已收藏jokeUserLike = JokeUserLike()jokeUserLike.user_id = jokeAuthorjokeUserLike.joke_id = jokeIdjokeUserLike.user_like = 1jokeUserLike.time_update = datetime.now().strftime('%Y-%m-%d %H:%M:%S')jokeDao.addLikedJoke(jokeUserLike)return_data["data"] = dataexcept Exception as e:print(e)return_data["state"] = 500return_data["message"] = "上传失败"# logger.info("查询机器人失败,异常信息为" + str(e))return HttpResponse(dumps(return_data, ensure_ascii=False, default=lambda obj: obj.__dict__))# 保存一个笑话
def addOneJoke(Joke):Joke.save()return Joke实现查看收藏列表
@api_view(['POST'])
def getLikedJoke(request):return_data = {"state": 200, "message": "查询成功"}data = []try:data_json = loads(request.body)userId = data_json.get("userId", "")likeFlag = data_json.get("likeFlag", "")page = data_json.get("page", 1)pageSize = data_json.get("pageSize", 10)# 得 已“喜欢”的jokeId列表jokeIdsUserLike = jokeDao.getLikedJokeIds(userId, int(likeFlag))#print(f"jokeIds: {jokeIdsUserLike}")try:paginator = Paginator(jokeIdsUserLike, pageSize)jokeIdsUserLike = paginator.page(page)except InvalidPage:jokeIdsUserLike = []# 得 已“喜欢”笑话内容for jokeId in jokeIdsUserLike:likedJokeDict = {}likedJoke = jokeDao.getJokeById(jokeId)likedJokeDict["jokeId"] = likedJoke.idlikedJokeDict["jokeTitle"] = likedJoke.joke_titlelikedJokeDict["jokeText"] = likedJoke.joke_textlikedJokeDict['jokeImage'] = imageUtil.imageTobase64(likedJoke.path_image)likeFlag = jokeDao.getLikeFlag(userId, jokeId)likedJokeDict["likeFlag"] = likeFlagdata.append(likedJokeDict)return_data["data"] = dataexcept Exception as e:traceback.print_exc()return_data["state"] = 500return_data["message"] = "查询失败"#logger.info("查询机器人失败,异常信息为" + str(e))return HttpResponse(dumps(return_data, ensure_ascii=False, default=lambda obj: obj.__dict__))