哪个网站下载软件最安全怎样在百度上建立网站
25年3月来自三星中国研发中心、中科院自动化所和北京智源的论文“TLA: Tactile-Language-Action Model for Contact-Rich Manipulation”。
视觉-语言模型已取得显著进展。然而,在语言条件下进行机器人操作以应对接触-密集型任务方面,仍未得到充分探索,尤其是在触觉感知方面。触觉-语言-动作 (TLA) 模型,通过跨模态语言基础有效地处理连续触觉反馈,从而能够在接触-密集型场景中实现稳健的策略生成。此外,构建一个包含 24000 对触觉动作指令数据的综合数据集,该数据集针对指尖销孔装配进行定制,为 TLA 的训练和评估提供必要的资源。结果表明,TLA 在有效动作生成和动作准确性方面显著优于传统的模仿学习方法(例如扩散策略),同时通过在以前未见过的装配间隙和销形上实现超过 85% 的成功率,表现出强大的泛化能力。
触觉感知对于接触-密集的机器人操作任务至关重要 [1]。例如,在精细装配任务中,机器人需要精确感知物体表面的细微变化 [2], [3]。触觉感知使机器人能够对其接触姿态进行细微调整,避免损坏或错位 [4]。这种精确的接触感知在许多复杂任务中都必不可少 [5]。先前的研究表明,整合触觉反馈可以显著增强操作技能的灵活性和鲁棒性 [6], [7],尤其是在处理复杂或不可预见的接触环境时,从而提高机器人的适应性。然而,当前的方法很大程度上依赖于在特定数据集上训练的专用模型 [8], [9],这些模型在泛化方面受到限制,无法与通用模型的能力相媲美 [10], [11]。
近年来,大语言模型在类人推理方面取得了重大突破 [12],其中视觉-语言-动作 (VLA) 模型的开发进展迅速 [13],[14]。通过跨模态语言基础,VLA 模型的表现优于传统的模仿学习方法,尤其是在跨不同机器人平台和任务设置的泛化方面。然而,目前大多数 VLA 模型主要侧重于视觉任务 [15],缺乏关键的触觉模态,这限制了它们在接触-丰富操作任务中的适用性 [16]。尽管最近有研究致力于将语言和触觉结合起来用于感知任务 [17],[18],[19],但这些研究依赖于排除机器人动作或将触觉作为补充模态的数据集 [20],这限制了它们在策略训练中的适用性,仅限于仅依赖感知或拾取放置的抓取任务。基于语言的触觉技能学习,面临的挑战包括:1)缺乏针对接触-密集型操作任务的专门触觉动作指令数据集;2)缺乏合适的触觉-语言-动作模型。
为了应对上述挑战,本文构建一个针对指尖触觉销孔装配场景的触觉动作指令数据集 [21]。其提出一种用于通才机器人策略学习的微调方法,称为触觉-语言-动作 (TLA) 模型,该方法表明跨模态微调能够通过语言落地获取泛化的触觉技能。所提出的 TLA 数据集和模型概览如图所示:
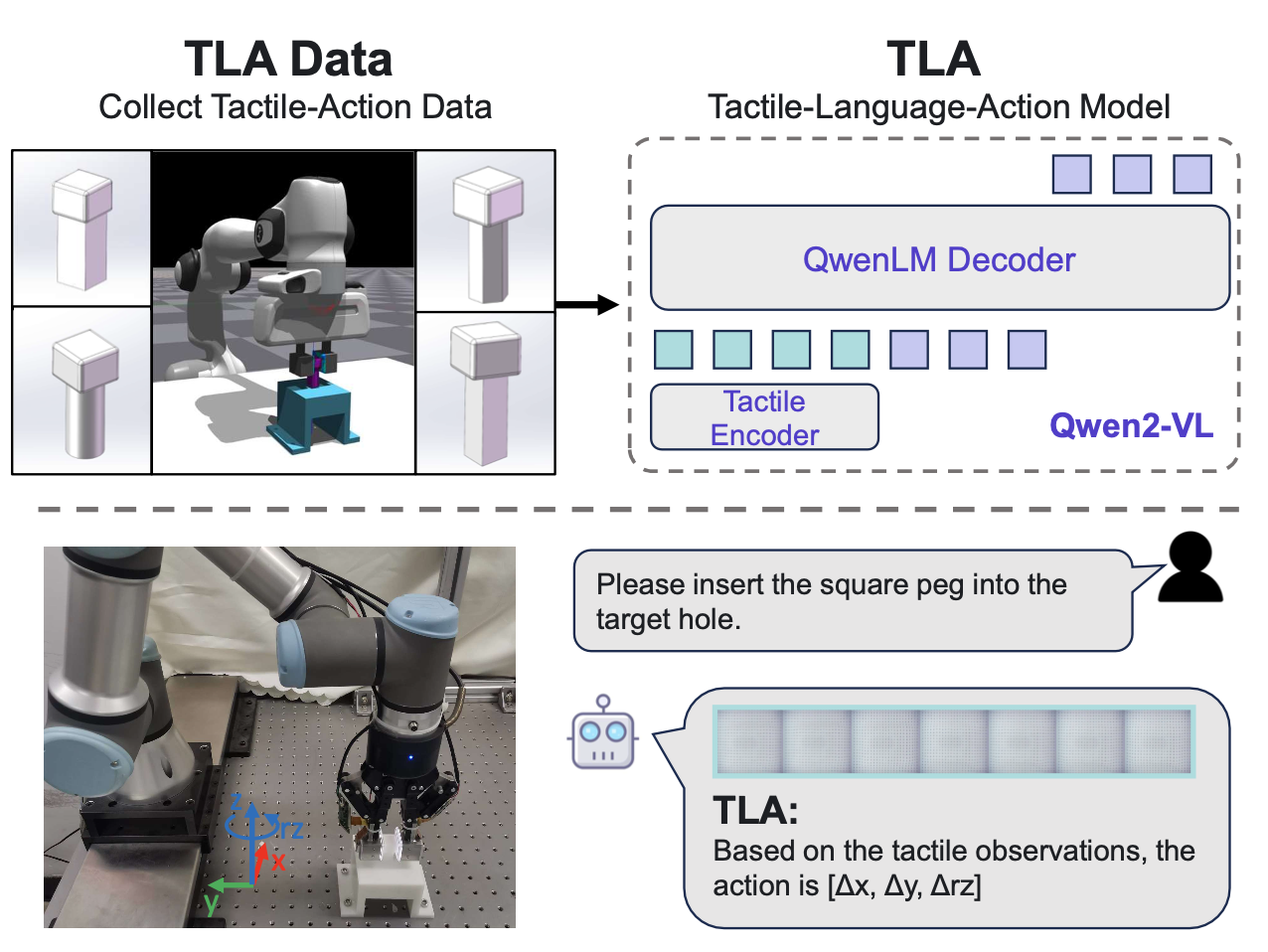
建立一个在钉孔装配过程中收集的触觉动作指令数据集。在此任务中,配备 GelStereo 2.0 视觉触觉传感器 [27] 的机器人,尝试基于指尖触觉感知和语言指令将钉子插入相应的孔中。为了高效地收集数据,在 NVIDIA Isaac Gym 中搭建此任务的模拟环境。基于有限元法 (FEM),使用 Flex 物理引擎模拟交互过程中视觉触觉传感器的变形。采用 [28] 中提出的触觉铭刻渲染方法来模拟触觉图像。为了缩小模拟与真实的差距,使用从真实传感器获取的触觉图像进行纹理映射,而不是手动设计的图案。通过这种方式,可以在插入尝试过程中获得高保真度的触觉图像。
钉孔任务的流程如下所述。夹持器首先抓住一个具有形状描述的钉子,并移动到相应孔的顶部,在 x 轴、y 轴和绕 z 轴的旋转上具有随机的 3-DOF 错位(用 rz 表示)。然后,夹持器向下移动尝试插入。如果在向下移动过程中钉子和孔发生碰撞,则认为此次尝试失败,夹持器抬起等待下一次尝试。碰撞期间的触觉图像序列被记录下来,以推断调整钉子姿态的机器人动作 (∆x, ∆y, ∆rz)。如果在夹持器向下移动到预定位置时未发生碰撞,则任务被视为成功。最大尝试次数为 15 次。否则,任务失败。
在模拟中,对这个钉入孔任务采用随机插入策略。对于每次尝试,都会保存触觉图像序列和钉孔姿态误差。然后,根据钉孔姿势误差 (e_x, e_y, e_rz) 创建动作标签 (∆xˆ, ∆yˆ, ∆rˆz)。
为了方便模型训练,收集的交互数据被转换为指令格式。<|im start|> 和 <|im end|> token 标记每轮对话的开始和结束。触觉图像则以 <|vision start|> 和 <|vision end|> 输入,分别表示视觉输入的开始和结束。文本指令定义任务,阐明挂钩类型和姿势要求。机器人在数据收集过程中的动作被保存为真值。如图展示 TLA 数据的示例:

触觉-语言-动作模型,如图所示。TLA 基于 Qwen2-VL [29] 构建,该模型包含用于编码视觉输入的视觉transformer (ViT) [30] 和用于理解多模态信息和生成文本的 Qwen2 语言模型 [31]。
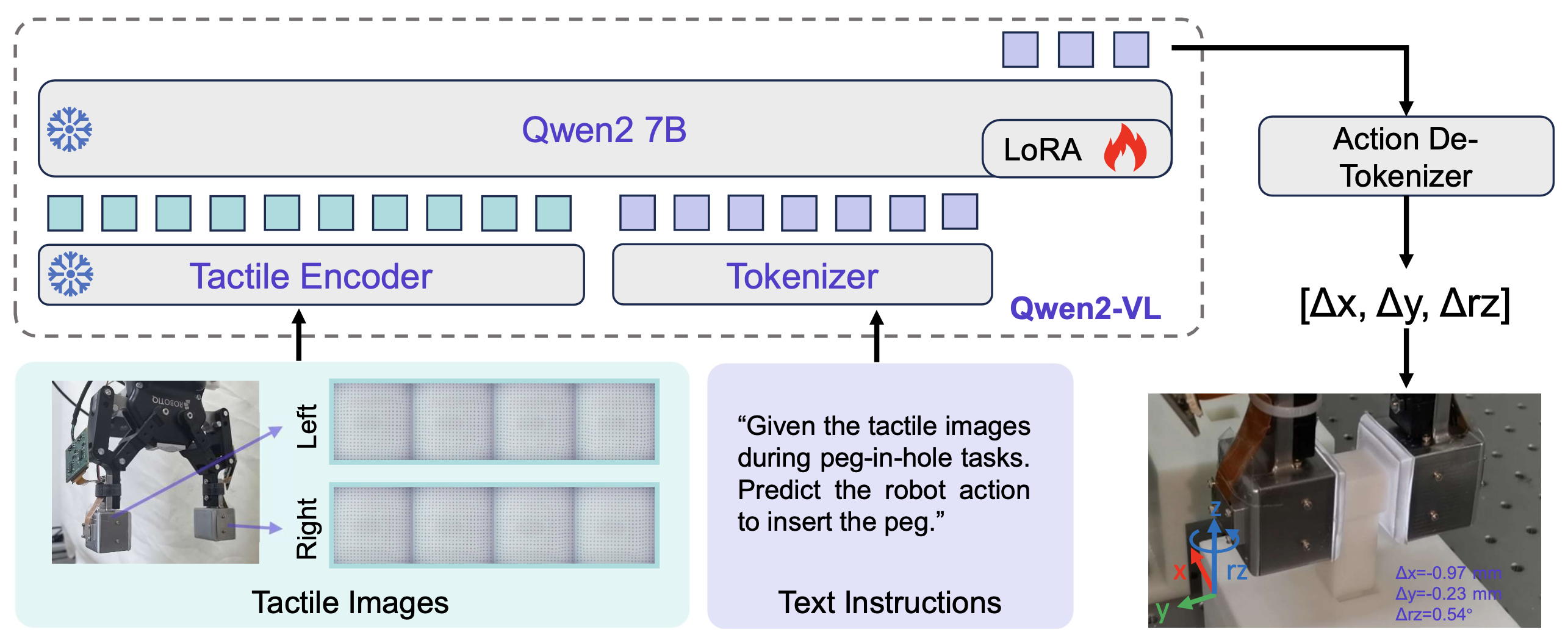
触觉编码器
如上文所述,视觉触觉传感器的触觉信息以图像的形式呈现。在机器人操作过程中,触觉图像会根据机器人夹持器的接触状态不断变化。因此,触觉编码器需要处理两个时间上对齐的图像序列。
触觉编码器的挑战在于从输入的触觉图像中提取时间变化。为了解决这个问题,将两个触觉图像序列合成为一个图像,将时间信息转换为空间信息,以便于基于视觉触觉的特征提取。具体而言,输入图像集表示为 I = {I_lt, I_rt; t = 0, 1, 2, 3},其中 I_lt 和 I_r^t 分别表示时间戳 t 时左右指尖的触觉图像。这八幅图像排列成 3×3 的网格,最后一个网格用白色图像填充,并调整为 616×616 的尺寸作为模型输入。
用 Qwen2-VL 的 ViT 作为触觉编码器,如上图所示。连接后的触觉图像经触觉编码器处理后,获得触觉特征。此外,还使用多层感知器 (MLP) 层将 2×2 范围内的触觉特征进一步压缩为单个 token。因此,对于输入的触觉图像 I,经过块大小为 14 的 ViT 后,可以获得 1936 个触觉 tokens。
使用语言模型进行动作预测
使用 Qwen2 语言模型预测机器人动作,如上图所示。语言模型的输入是触觉 token 和语言 token,它们分别由触觉编码器和 token 化器对原始多模态输入进行编码获得。Qwen2 7B 是 TLA 的骨干模型,并在 TLA 数据集上进行微调。
使用离散标记器对连续数字进行编码会影响模型在数字敏感任务中的表现 [32]。先前的研究 [13] 只是将最少使用的标记覆盖为“特殊标记”,并为每个标记分配 bin ID。与之前的方法不同,我们保留了数字编码方案,以确保在机器人操作任务中有效地利用训练前获得的数字知识。
然而,Qwen2 的 token 化器对数字进行单独编码。由于机器人动作数据中存在大量小数,这些冗余信息增加模型训练的难度。为此,通过按比例缩放所有动作并四舍五入为整数来简化真实动作。具体而言,处理过程计算为 A_gt = A_raw·s,其中 A_gt、A_raw、s 分别为真实动作、原始动作和缩放因子。
训练与推理
先前的研究表明,在训练期间冻结视觉编码器可以使 VLM 获得更好的性能 [29] [33]。因此,在微调期间冻结触觉编码器的参数。此外,使用低秩自适应 (LoRA) [34] 来有效地微调 Qwen2 7B 语言模型。真实动作被用作标签来计算下一个分词预测损失。
在推理过程中,TLA 根据输入的触觉观察和指令文本,依次预测机器人动作的概率分布。生成过程通过波束搜索进行,直至生成最终的 token。最后,Action-De-Tokenizer 将所有生成的概率根据词汇表映射到自然语言文本,并将其转换为机器人可执行的浮点数。
基线方法和TLA比较试验:
• 行为克隆 (BC) [35]:采用 ResNet-50 [36] 作为策略网络。该网络以触觉图像为输入,输出机器人动作,并采用监督学习的方式进行训练。
• 扩散策略 (DP) [37]:[37] 中的扩散策略利用条件去噪扩散过程来学习钉入孔装配策略。
• 单钉 TLA (SP-TLA):在方形钉插入数据集上训练的 TLA 模型。
• 多钉 TLA (MP-TLA):在方形和三角形钉插入数据集上训练的 TLA 模型。
实验设置。
单钉。从 TLA 数据集中选取 8k 的方形桩插入数据,用于比较 TLA 与基线方法的性能。具体而言,训练集和测试集分别拆分为 6k 和 2k。每个训练样本包含 8 张触觉图像,分别对应左右指尖,时长为 4。标签为机器人动作 (∆x, ∆y, ∆rz),分别表示水平方向的移动和绕 z 轴的旋转。TLA 模型在 8 块 Nvidia A6000 GPU 上训练 20 个 epoch。
多钉。选取 16,000 个方形和三角形桩样本进行训练,并进行等分。此外,收集 8,000 个样本进行评估:方形/三角形桩各 4,000 个,圆形/六边形桩各 4,000 个。输入、输出和指标与单桩任务一致。训练使用 8 块 Nvidia A6000 GPU,进行 10 个 epoch。
测试不同模型在两类销孔装配任务中的操作性能。首先,评估不同装配间隙下的模型性能,包括装配间隙分别为2.0 mm、1.6 mm和1.0 mm的方形销孔装配任务。然后,报告不同模型在方形、三角形、圆形和六边形销插入任务中的表现,所有装配间隙均设置为 2.0 mm。每个任务重复 50 次以计算最终结果。
在每个回合开始时,机器人已经用夹持器抓住钉子,并将末端执行器随机设置在靠近目标孔的起始位置。然后,机器人尝试第一次插入并获取触觉图像。随后,TLA 或其他模型根据触觉观察预测机器人的动作,并控制机器人再次插入。机器人持续尝试,直至插入成功或达到最大尝试次数 15。成功率和成功回合的平均步数用于评估所有模型的性能。