北京网站开发网站建设wordpress主题缓存
Task:
1.过拟合的判断:测试集和训练集同步打印指标
2.模型的保存和加载
a.仅保存权重
b.保存权重和模型
c.保存全部信息checkpoint,还包含训练状态
3.早停策略
1. 过拟合的判断:测试集和训练集同步打印指标
过拟合是指模型在训练数据上表现良好,但在未见过的新数据(测试数据)上表现较差。 判断过拟合的关键在于比较训练集和测试集的性能。
- 训练集指标: 准确率、损失等。 训练集指标通常会随着训练的进行而持续提高(准确率)或降低(损失)。
- 测试集指标: 准确率、损失等。 测试集指标一开始可能会随着训练的进行而提高,但当模型开始过拟合时,测试集指标会停止提高甚至开始下降。
判断标准:
- 训练集性能远好于测试集性能: 这是过拟合的典型迹象。
- 训练集损失持续下降,但测试集损失开始上升: 这表明模型正在记住训练数据,而不是学习泛化能力。
- 训练集准确率接近 100%,但测试集准确率较低: 也是过拟合的信号。
代码示例 (PyTorch):
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import numpy as np# 1. 创建一些模拟数据
np.random.seed(42)
X = np.random.rand(100, 10) # 100个样本,每个样本10个特征
y = np.random.randint(0, 2, 100) # 二分类问题# 将数据分成训练集和测试集
train_size = int(0.8 * len(X))
X_train, X_test = X[:train_size], X[train_size:]
y_train, y_test = y[:train_size], y[train_size:]# 转换为 PyTorch tensors
X_train = torch.tensor(X_train, dtype=torch.float32)
X_test = torch.tensor(X_test, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.long)
y_test = torch.tensor(y_test, dtype=torch.long)# 创建 DataLoader
train_dataset = TensorDataset(X_train, y_train)
test_dataset = TensorDataset(X_test, y_test)
train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=16, shuffle=False)# 2. 定义一个简单的模型
class SimpleNN(nn.Module):def __init__(self, input_size, hidden_size, num_classes):super(SimpleNN, self).__init__()self.fc1 = nn.Linear(input_size, hidden_size)self.relu = nn.ReLU()self.fc2 = nn.Linear(hidden_size, num_classes)def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return outinput_size = 10
hidden_size = 20
num_classes = 2
model = SimpleNN(input_size, hidden_size, num_classes)# 3. 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)# 4. 训练循环
num_epochs = 100
for epoch in range(num_epochs):# 训练model.train()train_loss = 0.0correct_train = 0total_train = 0for inputs, labels in train_loader:optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()train_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total_train += labels.size(0)correct_train += (predicted == labels).sum().item()train_accuracy = 100 * correct_train / total_traintrain_loss /= len(train_loader)# 评估model.eval()test_loss = 0.0correct_test = 0total_test = 0with torch.no_grad():for inputs, labels in test_loader:outputs = model(inputs)loss = criterion(outputs, labels)test_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total_test += labels.size(0)correct_test += (predicted == labels).sum().item()test_accuracy = 100 * correct_test / total_testtest_loss /= len(test_loader)# 打印指标print(f'Epoch [{epoch+1}/{num_epochs}], 'f'Train Loss: {train_loss:.4f}, Train Acc: {train_accuracy:.2f}%, 'f'Test Loss: {test_loss:.4f}, Test Acc: {test_accuracy:.2f}%')# 观察训练集和测试集的损失和准确率,判断是否过拟合。
关键点:
- 在每个 epoch 结束后,同时打印训练集和测试集的损失和准确率。
- 观察这些指标的变化趋势。 如果训练集损失持续下降,但测试集损失开始上升,或者训练集准确率远高于测试集准确率,则表明模型正在过拟合。
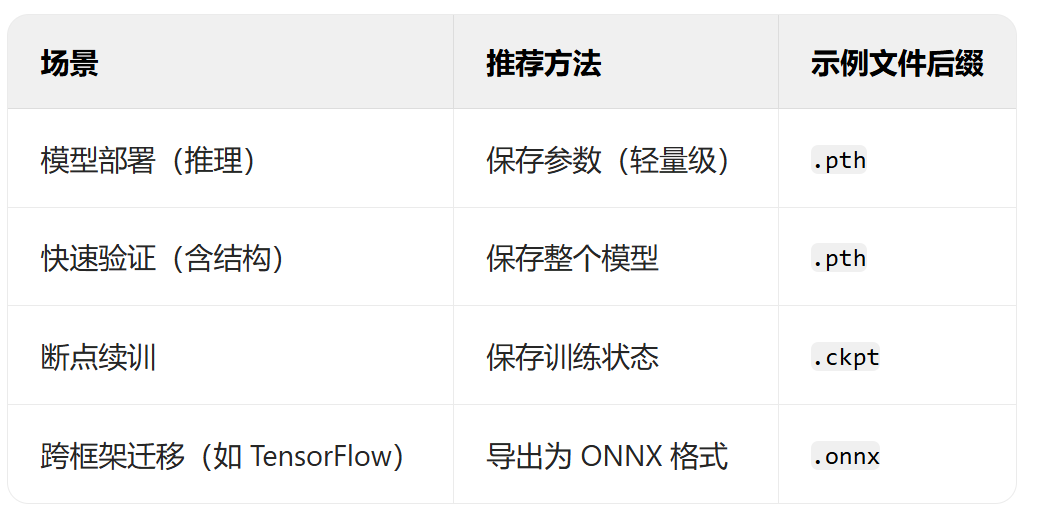
2. 模型的保存和加载
在 PyTorch 中,有几种保存和加载模型的方法:
a. 仅保存权重 (推荐):
这是最常见和推荐的方法。 它只保存模型的参数(权重和偏置),而不保存模型的结构。 这种方法更轻量级,更灵活,因为你可以将权重加载到任何具有相同结构的模型的实例中。
- 保存:
torch.save(model.state_dict(), 'model_weights.pth') - 加载:
- 首先,创建一个与保存时具有相同结构的模型的实例。
- 然后,使用
model.load_state_dict(torch.load('model_weights.pth'))加载权重。
# 保存权重
torch.save(model.state_dict(), 'model_weights.pth')# 加载权重
model = SimpleNN(input_size, hidden_size, num_classes) # 创建模型实例
model.load_state_dict(torch.load('model_weights.pth'))
model.eval() # 设置为评估模式
b. 保存权重和模型结构:
这种方法保存整个模型对象,包括模型的结构和权重。 它更简单,但不如仅保存权重灵活。
- 保存:
torch.save(model, 'model.pth') - 加载:
model = torch.load('model.pth')
# 保存整个模型
torch.save(model, 'model.pth')# 加载整个模型
model = torch.load('model.pth')
model.eval() # 设置为评估模式
c. 保存全部信息 (Checkpoint):
这种方法保存模型的全部信息,包括模型的结构、权重、优化器的状态、epoch 数等。 这对于恢复训练非常有用。
- 保存:
checkpoint = {'epoch': epoch,'model_state_dict': model.state_dict(),'optimizer_state_dict': optimizer.state_dict(),'loss': train_loss,
}
torch.save(checkpoint, 'checkpoint.pth')
- 加载:
checkpoint = torch.load('checkpoint.pth')
model = SimpleNN(input_size, hidden_size, num_classes)
optimizer = optim.Adam(model.parameters(), lr=0.01)model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']model.eval() # or model.train() depending on your needs
# - or -
model.train()3. 早停策略 (Early Stopping)
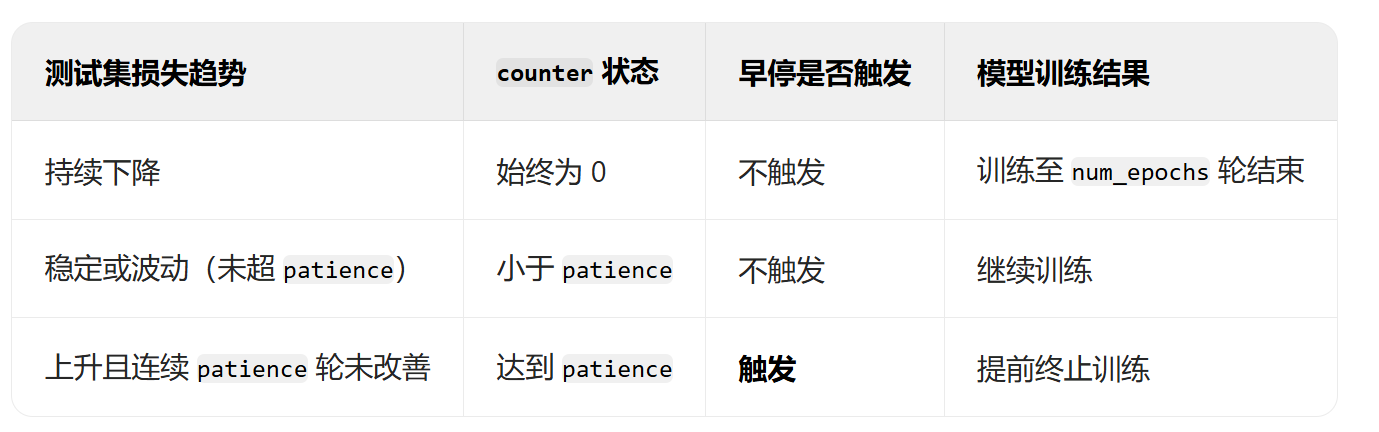
早停是一种正则化技术,用于防止过拟合。 它的基本思想是:在训练过程中,如果测试集上的性能在一定时间内没有提高,就提前停止训练。
实现步骤:
- 监控指标: 选择一个在测试集上监控的指标(例如,测试集损失或准确率)。
- 耐心 (Patience): 定义一个“耐心”值,表示在测试集指标没有提高的情况下,允许训练继续进行的 epoch 数。
- 最佳模型: 在训练过程中,保存测试集上性能最佳的模型。
- 停止训练: 如果测试集指标在“耐心”个 epoch 内没有提高,则停止训练,并加载保存的最佳模型。
代码示例 (PyTorch):
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import numpy as np# 1. 创建一些模拟数据
np.random.seed(42)
X = np.random.rand(100, 10) # 100个样本,每个样本10个特征
y = np.random.randint(0, 2, 100) # 二分类问题# 将数据分成训练集和测试集
train_size = int(0.8 * len(X))
X_train, X_test = X[:train_size], X[train_size:]
y_train, y_test = y[:train_size], y[train_size:]# 转换为 PyTorch tensors
X_train = torch.tensor(X_train, dtype=torch.float32)
X_test = torch.tensor(X_test, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.long)
y_test = torch.tensor(y_test, dtype=torch.long)# 创建 DataLoader
train_dataset = TensorDataset(X_train, y_train)
test_dataset = TensorDataset(X_test, y_test)
train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=16, shuffle=False)# 2. 定义一个简单的模型
class SimpleNN(nn.Module):def __init__(self, input_size, hidden_size, num_classes):super(SimpleNN, self).__init__()self.fc1 = nn.Linear(input_size, hidden_size)self.relu = nn.ReLU()self.fc2 = nn.Linear(hidden_size, num_classes)def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return outinput_size = 10
hidden_size = 20
num_classes = 2
model = SimpleNN(input_size, hidden_size, num_classes)# 3. 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)# 4. 早停策略
patience = 10 # 如果10个epoch测试集损失没有下降,就停止训练
best_loss = np.inf # 初始最佳损失设置为无穷大
counter = 0 # 计数器,记录测试集损失没有下降的epoch数
best_model_state = None # 保存最佳模型的状态# 5. 训练循环
num_epochs = 100
for epoch in range(num_epochs):# 训练model.train()train_loss = 0.0correct_train = 0total_train = 0for inputs, labels in train_loader:optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()train_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total_train += labels.size(0)correct_train += (predicted == labels).sum().item()train_accuracy = 100 * correct_train / total_traintrain_loss /= len(train_loader)# 评估model.eval()test_loss = 0.0correct_test = 0total_test = 0with torch.no_grad():for inputs, labels in test_loader:outputs = model(inputs)loss = criterion(outputs, labels)test_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total_test += labels.size(0)correct_test += (predicted == labels).sum().item()test_accuracy = 100 * correct_test / total_testtest_loss /= len(test_loader)# 打印指标print(f'Epoch [{epoch+1}/{num_epochs}], 'f'Train Loss: {train_loss:.4f}, Train Acc: {train_accuracy:.2f}%, 'f'Test Loss: {test_loss:.4f}, Test Acc: {test_accuracy:.2f}%')# 早停逻辑if test_loss < best_loss:best_loss = test_losscounter = 0best_model_state = model.state_dict() # 保存最佳模型的状态else:counter += 1if counter >= patience:print("Early stopping!")model.load_state_dict(best_model_state) # 加载最佳模型breakprint(f"Best Test Loss: {best_loss:.4f}")
关键点:
patience:控制早停的敏感度。 较小的patience值会导致更早的停止,可能导致欠拟合。 较大的patience值允许训练继续进行更长时间,可能导致过拟合。best_loss:跟踪测试集上的最佳损失。counter:跟踪测试集损失没有下降的 epoch 数。- 在早停后,加载保存的最佳模型。
总结:
- 通过同步打印训练集和测试集的指标,可以有效地判断过拟合。
- 仅保存权重是保存模型的推荐方法,因为它更轻量级和灵活。
- 早停是一种有效的正则化技术,可以防止过拟合。