网站开发与电子商务怎样通过阿里巴巴网站开发客户
1 Spark架构全景图
Apache Spark作为当今最流行的大数据处理框架之一,其卓越性能的背后是一套精心设计的分布式架构。理解Spark的架构组成和运行机制,对于性能调优和故障排查至关重要。
1.1 核心组件架构
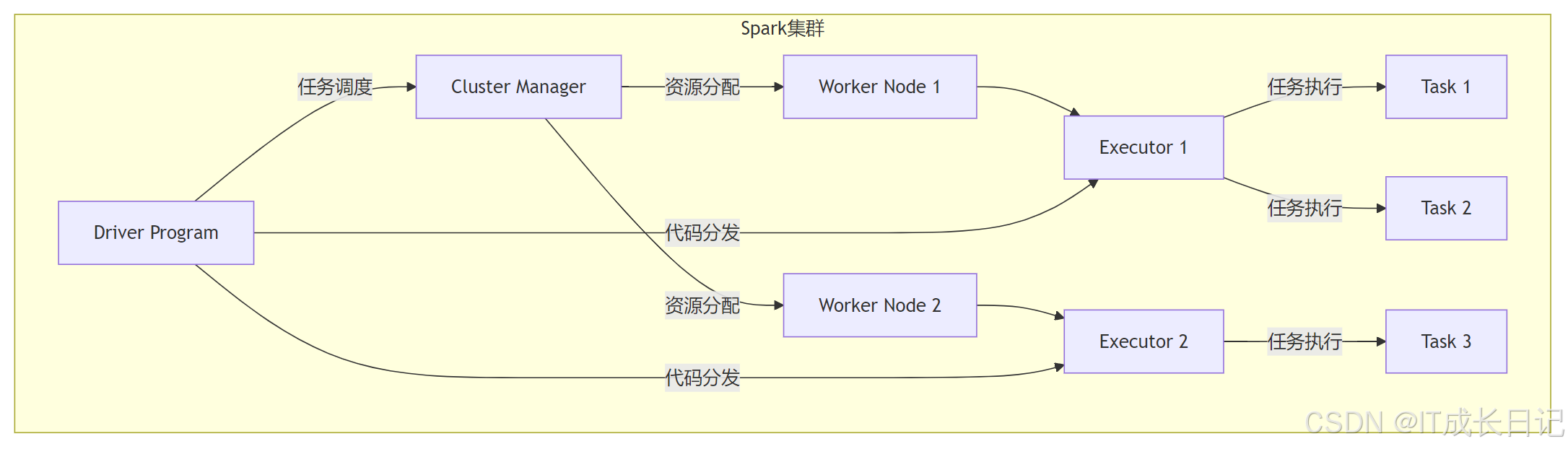
组件交互流程:
- Driver初始化:用户提交应用程序,启动Driver进程
- 资源申请:Driver通过Cluster Manager申请执行资源
- Executor启动:Worker节点上启动Executor进程
- 任务分配:Driver将任务序列化后发送给Executor
- 任务执行:Executor反序列化任务并执行,结果返回或写入存储
1.2 运行时数据流
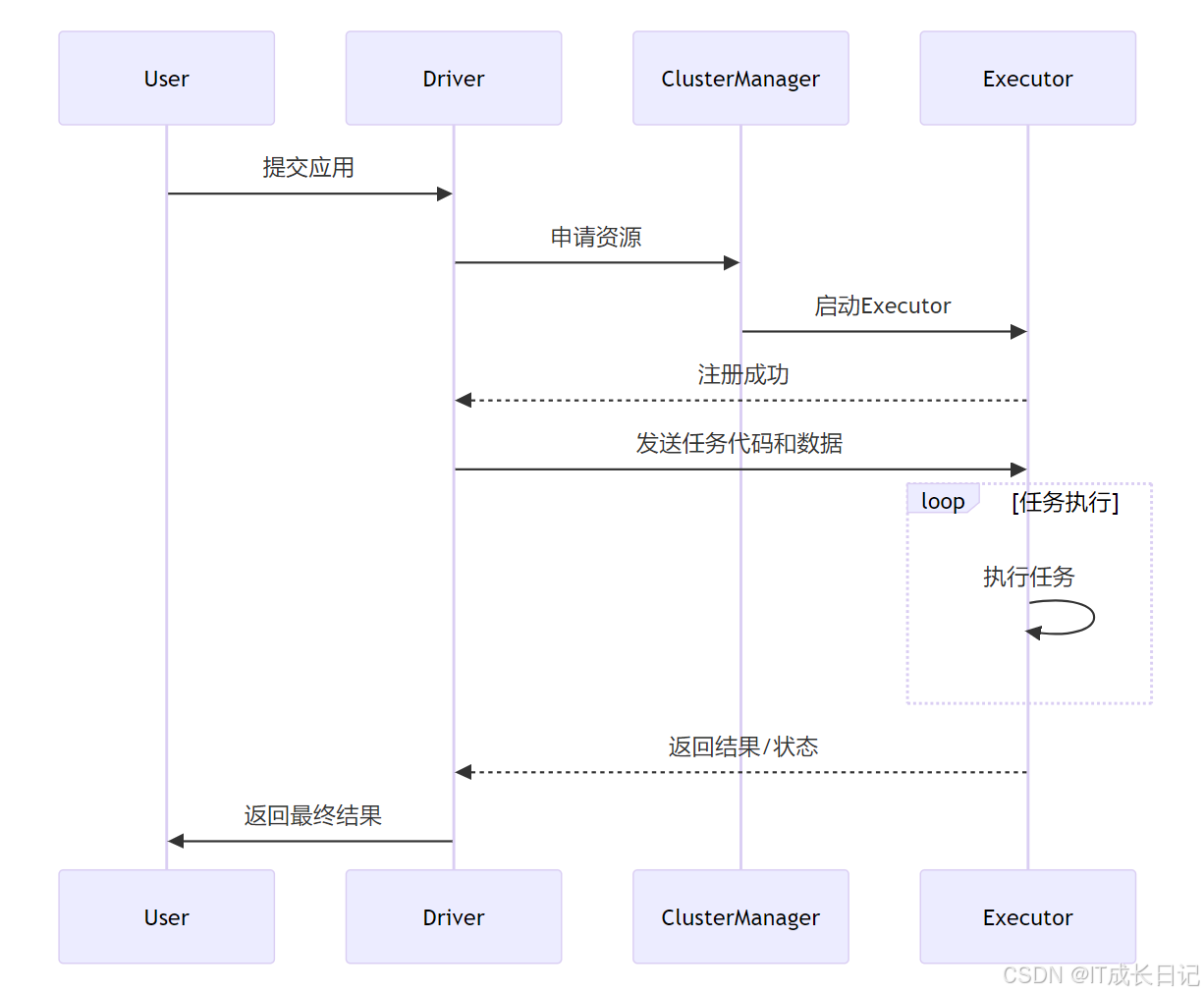
2 核心组件角色解析
2.1 Driver:大脑与指挥官
Driver的核心职责:
- 应用解析:将用户程序转换为DAG(有向无环图)
- 任务调度:将DAG分解为Stage和Task
- 资源协调:与Cluster Manager协商资源
- 状态监控:跟踪任务执行情况和Executor状态

核心概念:
- SparkContext:Spark功能的入口点,代表与Spark集群的连接
- DAGScheduler:将逻辑执行计划转换为物理执行计划,处理Stage划分
- TaskScheduler:将Task提交给Worker节点执行
2.2 Executor:分布式执行引擎
Executor的核心能力:
- 任务执行:执行Driver分配的Task
- 内存管理:提供内存缓存RDD和数据
- 磁盘IO:处理shuffle数据和溢出写入
- 心跳报告:定期向Driver发送心跳信号
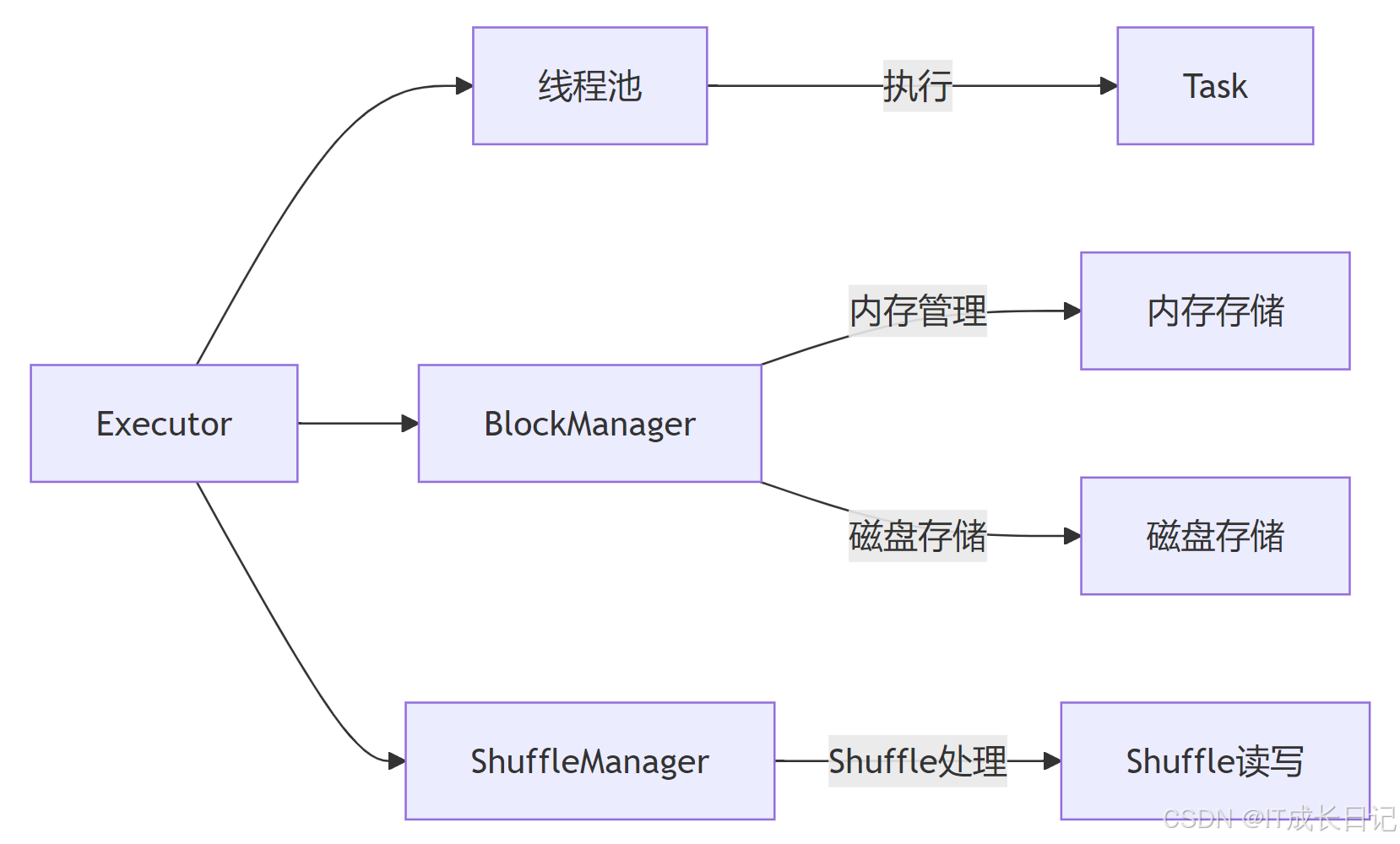
性能关键点:
- 线程池大小:由spark.executor.cores控制,决定并行Task数
- 内存分配:分为Execution内存(计算)和Storage内存(缓存)
- Shuffle优化:影响性能的关键操作,可通过spark.shuffle.*参数调优
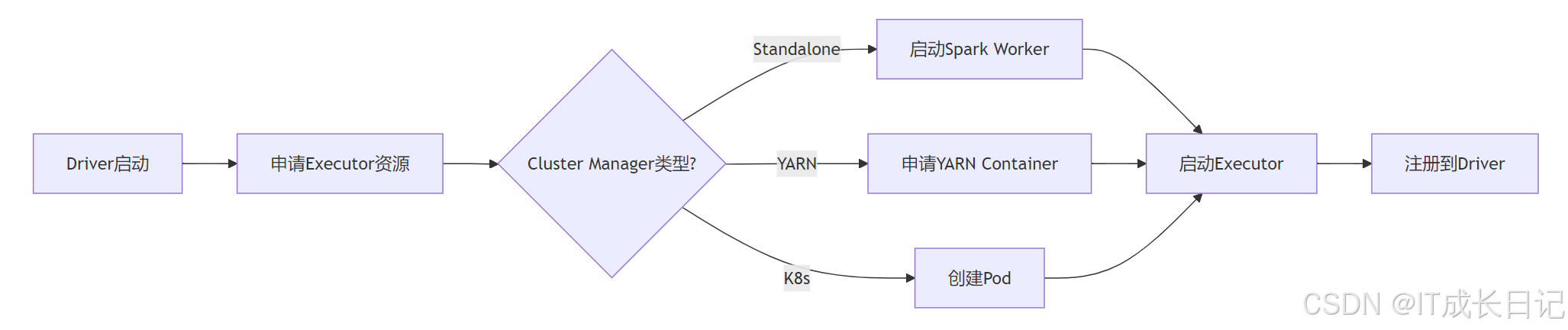
2.3 Cluster Manager:资源大管家
| 类型 | 特点 | 适用场景 |
| Standalone | Spark内置,简单轻量 | 测试/小规模生产环境 |
| YARN | 与Hadoop集成,资源利用率高 | Hadoop生态体系 |
| Mesos | 通用资源管理,细粒度分配 | 混合负载环境 |
| Kubernetes | 容器化部署,云原生支持 | 云环境/现代化架构 |
3 RDD:弹性分布式数据集
3.1 RDD核心抽象
RDD五大特性:
- 分区列表:数据分片的基本单位
- 计算函数:每个分区的转换逻辑
- 依赖关系:父RDD的引用
- 分区函数:决定数据如何分片
- 首选位置:数据本地性优化
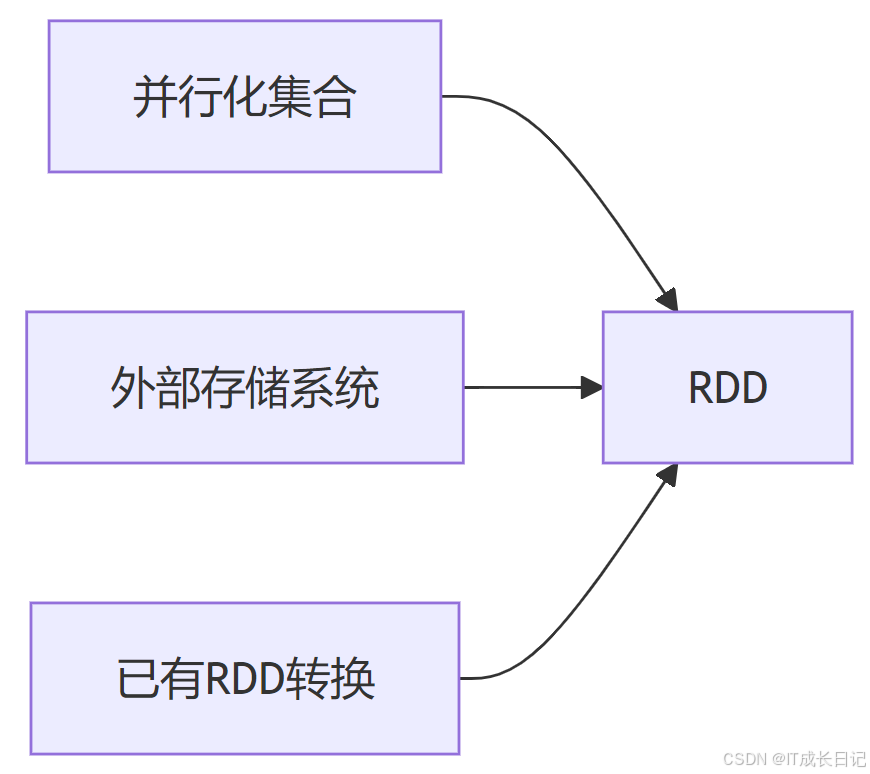
- RDD创建方式:
3.2 RDD容错机制
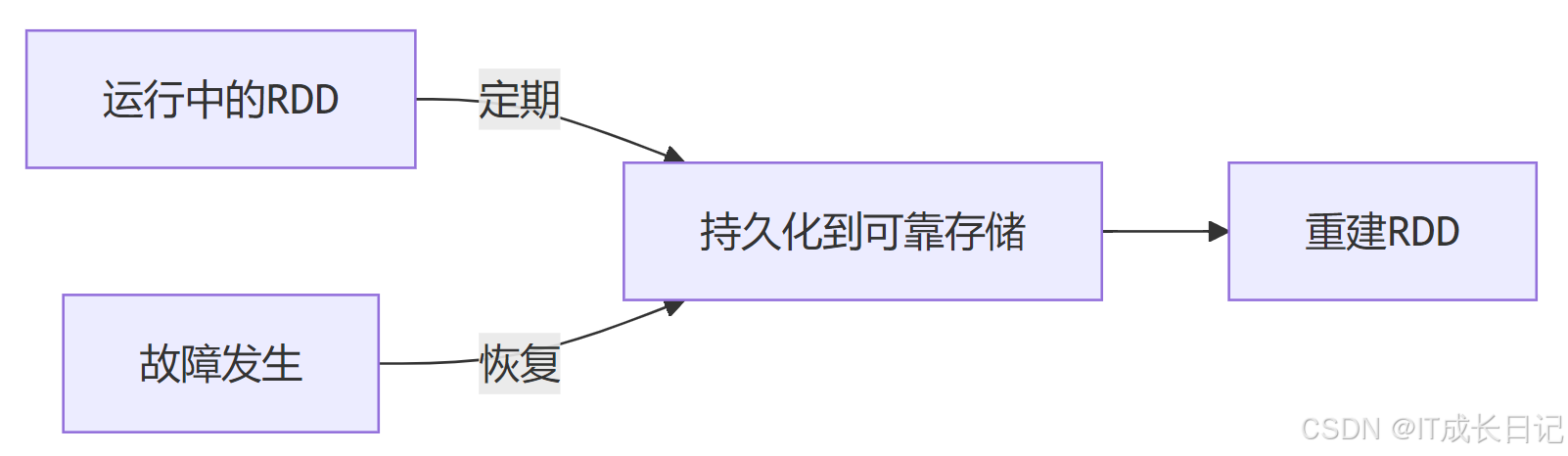
- 血统(Lineage)机制:

容错恢复过程:
- 记录血统:每个RDD记录其衍生过程
- 故障检测:Executor心跳丢失或任务失败
- 重新计算:根据血统从最近的检查点或原始数据重新计算
- 结果恢复:只重新计算丢失的分区
- 检查点(Checkpoint)机制:
- 检查点 vs 缓存:
| 特性 | 检查点 | 缓存 |
| 存储位置 | 可靠存储(HDFS) | 内存/磁盘 |
| 血统 | 截断 | 保留完整血统 |
| 用途 | 容错恢复 | 性能优化 |
| 生命周期 | 应用结束仍存在 | 应用结束即删除 |
4 任务执行全流程
4.1 从代码到任务的旅程

- 关键阶段解析:
DAG构建:根据RDD的转换操作构建有向无环图Stage划分:以Shuffle为边界划分Stage
- 窄依赖:父RDD的每个分区最多被子RDD的一个分区使用
- 宽依赖:父RDD的每个分区被子RDD的多个分区使用
Task生成:每个Stage生成一组Task
- ShuffleMapTask:为Shuffle准备中间数据
- ResultTask:执行最终计算并输出结果
4.2 Shuffle机制详解

- Shuffle优化方向:
- 减少数据量:map-side聚合,filter提前
- 调整分区数:spark.sql.shuffle.partitions
- 内存优化:spark.shuffle.memoryFraction
- 文件合并:spark.shuffle.consolidateFiles
5 性能调优要点
5.1 资源分配黄金法则
配置建议:
- 内存:spark.executor.memory设为节点内存的75%左右
- 核数:每个Executor 3-5个核心,避免过多导致争抢
- 并行度:分区数应为集群总核数的2-3倍
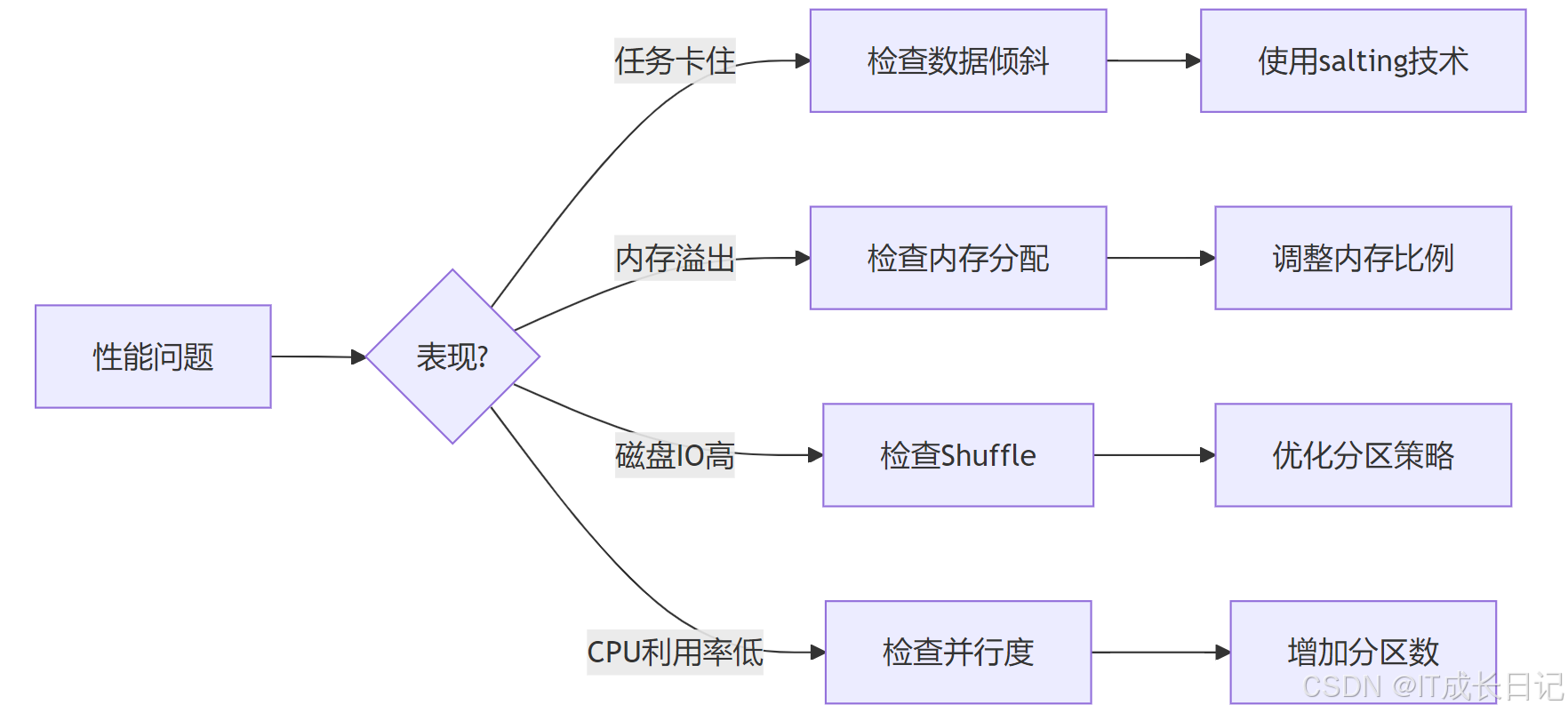
5.2 常见性能瓶颈诊断
6 总结
Spark架构的精妙之处在于其分层的设计理念和高效的执行模型。理解这些核心组件的协作机制,可以帮助我们:
- 合理设计应用:根据数据特性和计算需求选择适当的API
- 有效调优性能:针对瓶颈点进行精准优化
- 快速排查故障:根据错误现象定位问题组件
- 资源高效利用:最大化集群资源利用率
掌握Spark架构的内在原理,才能真正发挥这一强大框架的潜力,构建高效可靠的大数据应用。