中国建设监理协会网站投稿百度对wordpress
在本系列上篇内容中,我们详细介绍了如何使用亚马逊云科技Bedrock Agents和Knowledge Bases,结合检索增强生成(RAG)方法,开发一个可以查询文档和数据库的聊天机器人的整体解决方案架构。在本系列下篇中,我们会继续探索构建该方案的具体实操步骤。

Agent操作组
Agent操作组包含以下组件,大家需要在bedrock中进行相应的配置:
- OpenAPI Schema:定义操作组会调用的API语法结构。代理使用API架构中的结构定义来确定需要从客户那里收集哪些字段,以填充后端API请求所需的参数。
- Lambda函数:定义代理执行操作的业务逻辑。
在代理的每个操作组中,大家需要定义一个Lambda函数代码来定义业务逻辑,以执行操作组所需执行的任务,并自定义API响应的返回方式。大家可以根据用户输入中所包含的,和任务执行相关变量来定义Lambda函数逻辑,并将响应返回给代理。在本方案中,我们使用了亚马逊云科技Bedrock商的基础模型(FMs),将文本转换为符合指定约束条件的SQL查询。此过程可用于从Athena表中提取数据,从而有效地回答数据相关的查询。下图展示了我们通过AI创建生成的Athena表及查询例子。
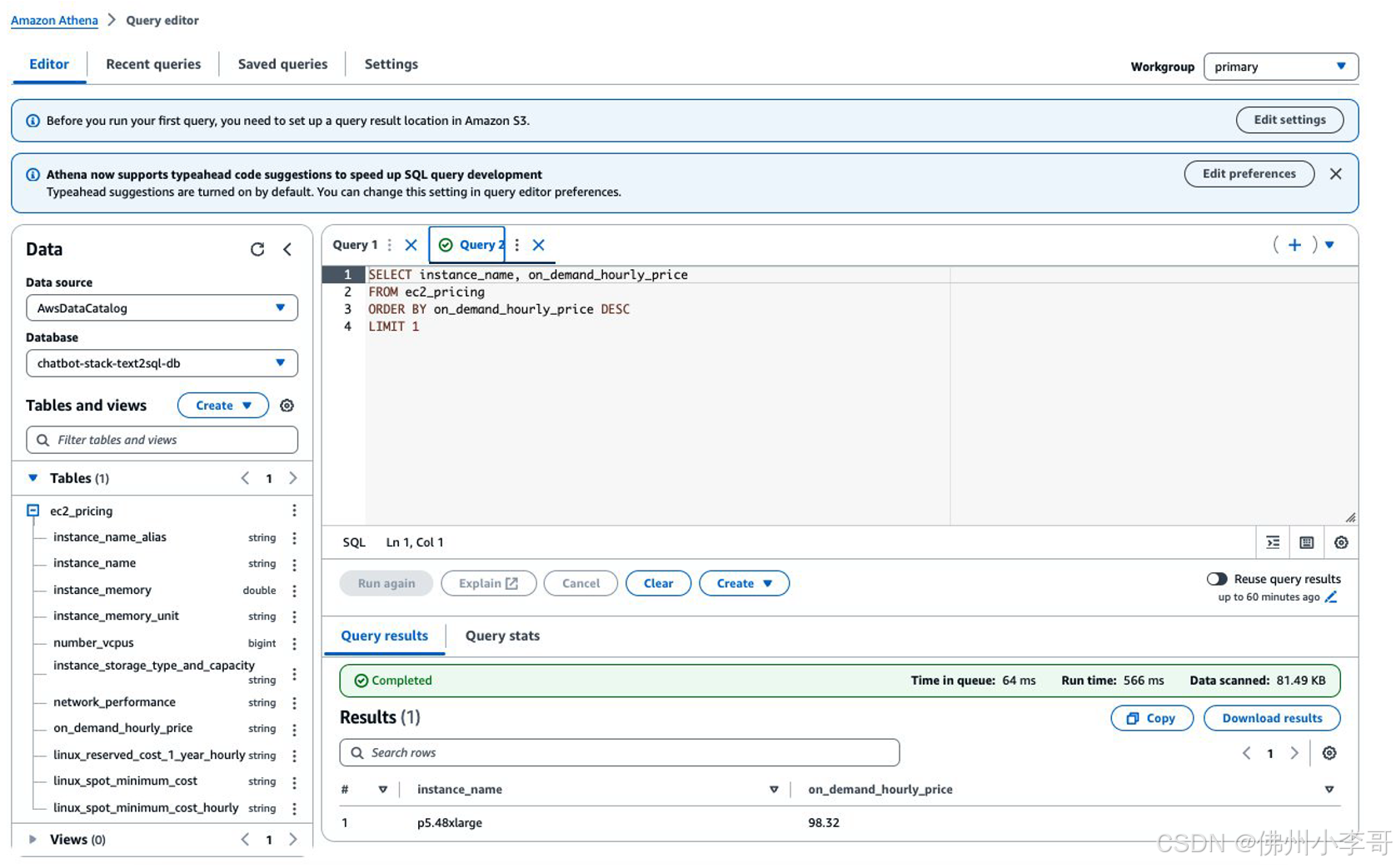
示例问题与回答
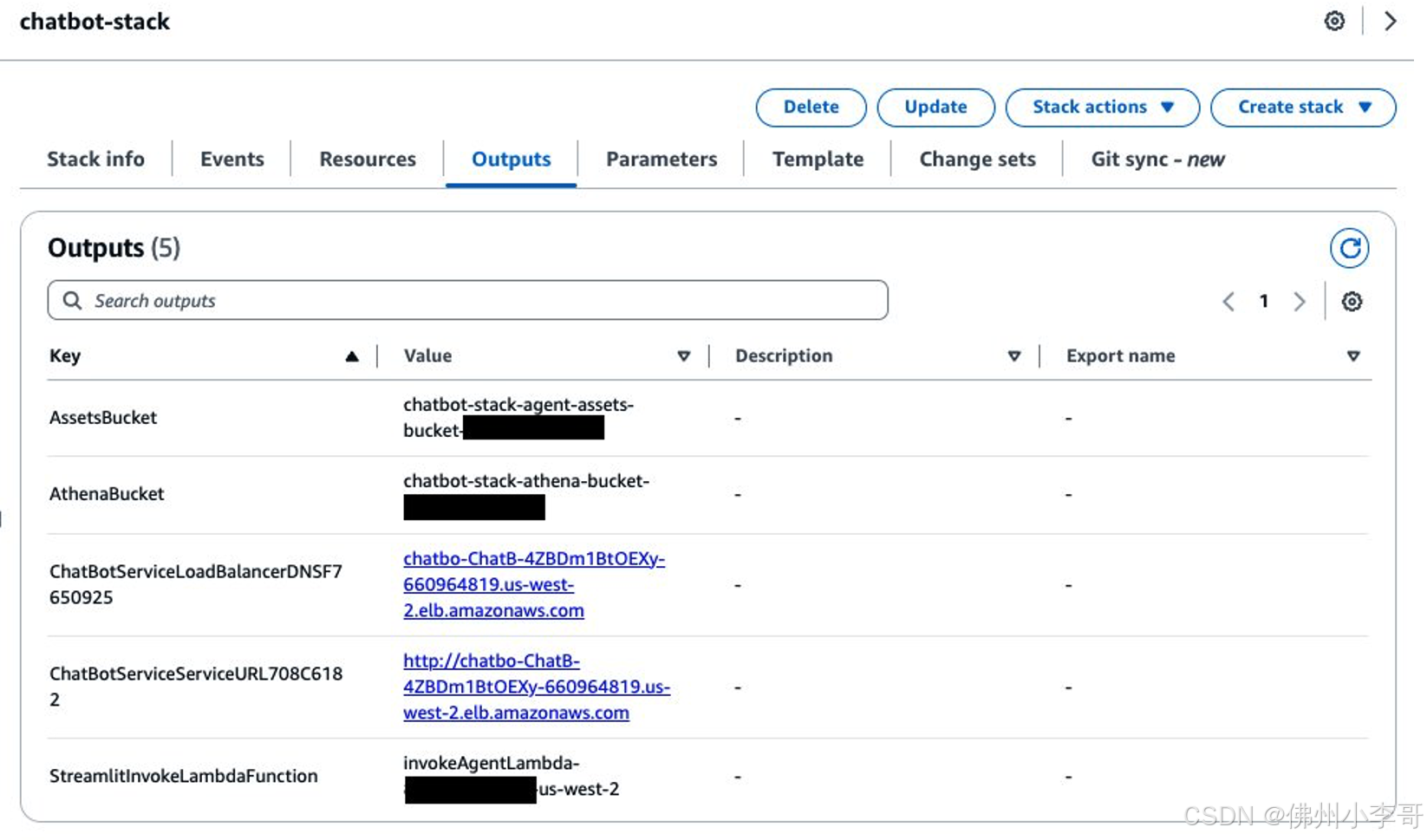
完成上篇中的亚马逊云科技CDK部署后,大家可以在Bedrock控制台或通过AWS CloudFormation控制台上的自动部署脚本输出的的Streamlit应用URL访问我们的代理,如下图所示。
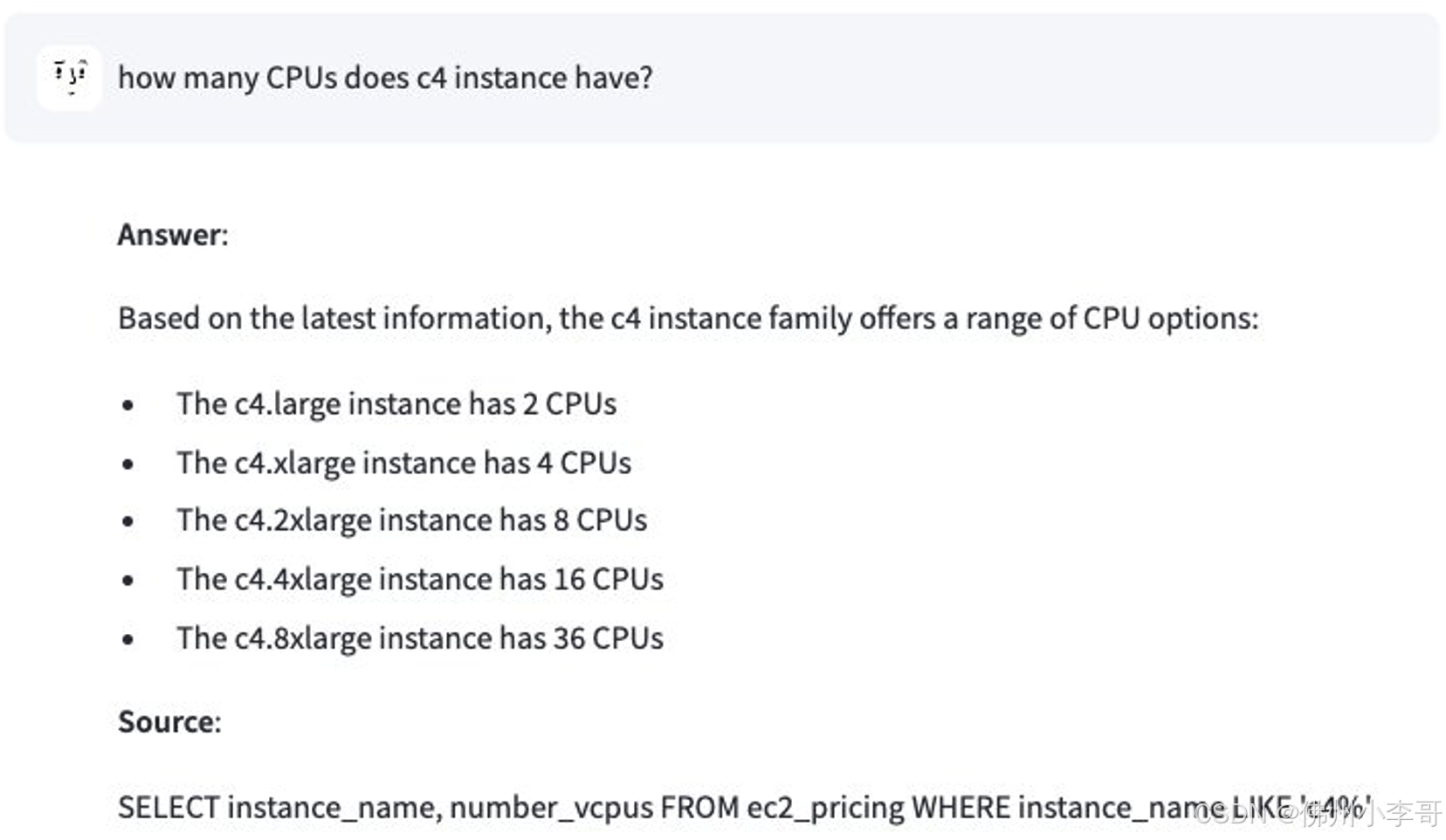
 在我们的聊天机器人UI中,大家还可以查看AI生成的回复的来源细节。如果答案来自知识库,则会显示相关文档的链接。如果答案来自Amazon EC2定价表,则会看到根据相关表转换成的SQL查询语句。此外聊天机器人还能多个数据源获取信息回答问题。以下截图展示了一些示例的问题,以及来源于不同的数据的回复。
在我们的聊天机器人UI中,大家还可以查看AI生成的回复的来源细节。如果答案来自知识库,则会显示相关文档的链接。如果答案来自Amazon EC2定价表,则会看到根据相关表转换成的SQL查询语句。此外聊天机器人还能多个数据源获取信息回答问题。以下截图展示了一些示例的问题,以及来源于不同的数据的回复。


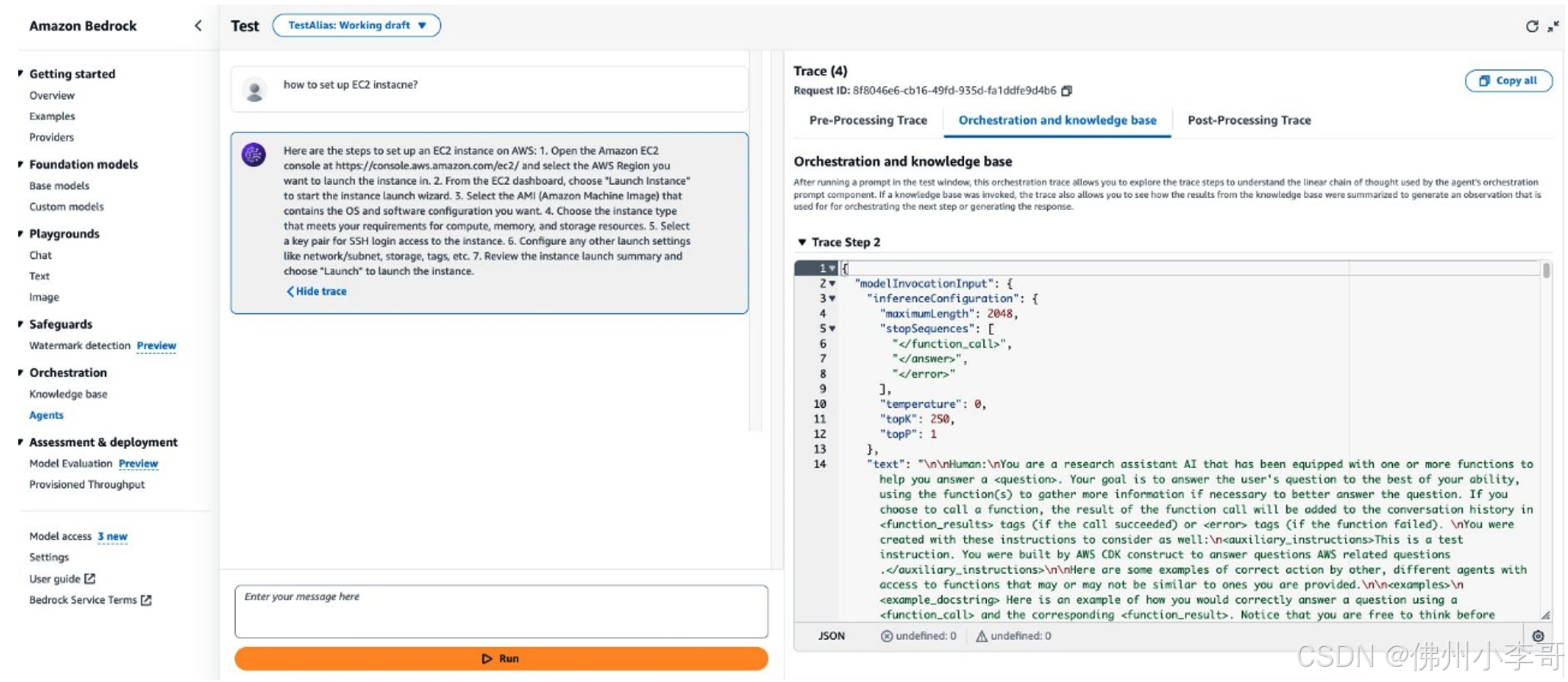
每个来自亚马逊云科技Bedrock代理的响应都会附带一个详细的AI输出执行轨迹(trace),用于展示代理在对话过程中执行的推理步骤。执行轨迹帮助大家了解代理的推理过程和如何得出最终的回答。我们在代理测试窗口中展示执行轨迹时,会出现一个窗口,显示对话过程中每个步骤的执行轨迹。大家可以实时查看代理的推理过程,每个步骤的轨迹可能属于以下类型:
- PreProcessingTrace - 记录预处理步骤的输入和输出,在此阶段代理会对用户输入进行上下文分析和分类,并判断输入是否有效。
- OrchestrationTrace - 记录代理执行步骤的输入和输出,此步骤中代理会解析输入、调用API、查询知识库,并返回输出,以继续编排任务工作流或响应用户。
- PostProcessingTrace - 记录后处理步骤的输入和输出,在此阶段代理会处理代理的最终输出,并确定如何返回响应给用户。
- FailureTrace - 记录某个步骤失败的原因。
自定义集成自己的数据集
为了将我们自己的数据集集成到本解决方案中,大家需要按照下方的结构化指南进行操作,并根据自己的需求进行调整。这些步骤旨在提供一个无缝、高效的集成流程,帮助大家顺利部署解决方案并使用自己的数据。本方案原始代码已上传到awslabs项目下的代码仓库:genai-bedrock-agent-chatbot. 大家需要先从Github上拉取该项目后,再执行下面的指南操作。
集成知识库数据
首先我们要准备需要的数据以供集成,我们进入assets/knowledgebase_data_source目录,并将数据集放置在该文件夹中。
如需调整配置,我们进入cdk.json 文件,并修改 context/config/paths/knowledgebase_file_name字段。此外还需要修改 context/config/bedrock_instructions/knowledgebase_instruction字段,以确保其能够准确反映我们刚添加的新数据集的上下文信息。
集成结构化数据
要组织结构化数据,请在assets/data_query_data_source/目录下创建一个子目录(例如 /tabular_data),然后将结构化数据集(支持格式包括CSV、JSON、ORC和Parquet)放入该子文件夹。之后进行配置和代码更新时,请进行以下更改:
- 更新
cdk.json文件中的context/config/paths/athena_table_data_prefix字段,以匹配新的数据路径。 - 修改
code/action-lambda/dynamic_examples.csv文件,加入新的文本到SQL转换示例,使其与新数据集匹配。 - 修改
code/action-lambda/prompt_templates.py文件,使其符合新表数据的属性。 - 修改
cdk.json文件中的context/config/bedrock_instructions/action_group_description字段,清晰描述用于操作我们自定义数据集的Lambda函数拥有的功能和用途。 - 在
assets/agent_api_schema/artifacts_schema.json文件中,记录Lambda函数中的新添加的功能。
其他通用更新
在cdk.json文件的context/config/bedrock_instructions/agent_instruction字段部分,提供对代理功能和设计目标的完整描述,以确保新集成的数据得到了合理的利用。
资源清理
当大家不需要使用该解决方案时,应该避免构建的云端代理产生额外费用时,我们可以通过两种方式删除相关资源:
- 在亚马逊云科技CloudFormation控制台删除该堆栈。
- 运行以下终端命令进行删除:
cdk destroy这样可以确保所有相关资源被彻底清理,避免不必要的费用浪费。